

golang面经——基础相关 - 指南
一、面试题相关
1、相比较于其他语言, Go有什么优势或者特点?
分析:
这是一个开放性题目,言之有理即可,主要考察对go语言整体的一个理解和感受,看看对go语言了解是否全面,可以从语法层面,是否支持跨平台编译,以及对并发编程的支持方式以及协程支持等几个方面来分析
回答:
Go 允许跨平台编译,编译出来的是二进制的可执行文件,直接部署在对应系统上即可运行。
Go在语言层次上天生支持高并发,通过goroutine和channel实现。channel的理论依据是 CSP 并发模型,即所谓的 通过通信来共享内存; Go 在 runtime 运行时里实现了属于自己的调度机制: GMP,降低了内核态和用户态的切换成本。
Go的语法简单,代码风格比较统一。
2、go是面向对象的吗?
分析:
Go官网的回答中提到,Yes or No。也就是说Go不是面向对象语言,但也可以进行面向对象风格的编程,Go可以看作是一种泛化的面向对象,他不像Java那样那么规范,Go的对象没有层次结构,但也使得Go的对象比Java中的对象更轻量级。
没有层次结构指的是这意味着Go不支持传统面向对象意义上的继承,而是更喜欢专注于组合。但是我们可以使用接口、结构体和嵌入在Go中模拟继承。不过,以这种方式创建复杂的继承层次结构是非常笨拙的。
这里可以引发一下思考,不是说面向对象才是最优的代码结构和开发范式,各有优缺点。
回答:
我之前有阅读过Go官方QA文档,答案是Yes and No,也就是说Go不是面向对象语言,但也可以进行面向对象风格的编程,在Go里面,实现面向对象三大特性是这样的
封装:Go语言里面字段首字母大小写来决定字段是否可以被外包访问封装:在一个对象内部,某些方法和数据可以是私有的,不能被外界访问,封装为对象内部数据提供了不同级别的保护
继承:Go语言里面用组合结构体的方式 或 接口继承来实现继承:让某个类型的对象获得另一个类型的对象的属性。继承概念的实现方式有二类:实现继承与接口继承。
实现继承就是直接使用父类的属性和方法而无需额外编码的能力。接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力。
package main
import "fmt"
// 定义“父类”角色:Animal 结构体
type Animal struct {
Name string // 动物的名字
Age int // 动物的年龄
}
// Animal 的方法:吃饭
func (a *Animal) Eat() {
fmt.Printf("%s is eating...\n", a.Name)
}
// Animal 的方法:睡觉
func (a *Animal) Sleep() {
fmt.Printf("%s is sleeping...\n", a.Name)
}
// 定义“子类”角色:Dog 结构体,嵌入 Animal(匿名字段)
// 嵌入后,Dog 会“继承”Animal 的所有字段和方法
type Dog struct {
Animal // 嵌入 Animal 结构体(匿名字段)
Breed string // Dog 自己的字段:品种
}
// Dog 的方法:吠叫(扩展的新方法)
func (d *Dog) Bark() {
fmt.Printf("%s (a %s) is barking: Woof! Woof!\n", d.Name, d.Breed)
}
// Dog 重写 Animal 的 Eat 方法(类似“方法覆盖”)
func (d *Dog) Eat() {
// 可以先调用被嵌入类型的方法(类似“super”)
d.Animal.Eat()
// 再添加 Dog 特有的逻辑
fmt.Printf("%s (a %s) prefers bones!\n", d.Name, d.Breed)
}
func main() {
// 创建 Dog 实例
dog := Dog{
Animal: Animal{
Name: "Buddy",
Age: 3,
},
Breed: "Golden Retriever",
}
// 直接访问嵌入的 Animal 字段(无需显式通过 Animal 访问)
fmt.Printf("Dog's name: %s, Age: %d, Breed: %s\n", dog.Name, dog.Age, dog.Breed)
// 调用嵌入的 Animal 方法(Sleep 未被重写)
dog.Sleep() // 输出:Buddy is sleeping...
// 调用被 Dog 重写的 Eat 方法
dog.Eat()
// 输出:
// Buddy is eating...
// Buddy (a Golden Retriever) prefers bones!
// 调用 Dog 自己的方法
dog.Bark() // 输出:Buddy (a Golden Retriever) is barking: Woof! Woof!
}多态:Go语言中通过接口来实现多态,不同的类型实现对应接口,然后调用接口变量的方法,结果取决于接口存储的对应类型的方法。
多态指一个类实例的相同方法能有不同表现形式。多态机制可以让不同内部结构的对象共享相同的外部接口。这意味着,虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用。
package main
import "fmt"
// 1. 定义接口
type Animal interface {
Sound() string
}
// 2. 实现具体结构体
// 狗
type Dog struct{}
func (d Dog) Sound() string {
return "汪汪"
}
// 猫
type Cat struct{}
func (c Cat) Sound() string {
return "喵喵"
}
// 3. 多态使用
func MakeSound(animal Animal) {
fmt.Println(animal.Sound())
}
func main() {
dog := Dog{}
cat := Cat{}
// 同样的函数调用,不同的行为
MakeSound(dog) // 输出: 汪汪
MakeSound(cat) // 输出: 喵喵
// 也可以直接使用接口变量
var animal Animal
animal = dog
fmt.Println(animal.Sound()) // 输出: 汪汪
animal = cat
fmt.Println(animal.Sound()) // 输出: 喵喵
}
/*
汪汪
喵喵
汪汪
喵喵
*/3、golang 中 make 和 new 的区别?(基本必问)
分析:
考察go语言的基础,对象的创建方式,make和new都可以用来创建对象,但是make创建对象有一定的限制,回顾我们平常写代码的过程,只是针对某些特定的数据类型一般用make来创建,比如slice,map,还有channel,以及创建完之后,返回值是什么?回答的要点要突出创建对象的区别以及返回值类型。
回答:
make 只能用来分配及初始化类型为 slice、map、chan 的数据。new 可以分配任意类型的数据;new 分配返回的是指针,即类型 *Type。make 返回数据类型本身,即 Type;new 分配的空间被清零。make 分配空间后,会进行初始化;
4、数组和切片的区别(基本必问),切片怎么扩容
4.1 数组和切片的区别?
分析:
数组和切片在编程中都会用到,都是用来存储一组相同数据类型的内存连续的数据结构,主要区别在于长度是否固定且数据类型的性质,是否是引用数据类型,比如在做函数参数传递时,是否会影响到原数据(数组或切片),这就需要了解切片的底层实现,回顾下go语言切片的底层实现,切片的底层数据结构定义如下:
type slice struct {
array unsafe.Pointer
Len int
Cap int
}slice结构包含三个字段,array 类型为unsafe.Pointer,还有两个int类型的字段len和cap。
array:是一个指针变量,指向一块连续的内存空间,即底层数组结构。
len:当前切片中数据长度。
cap:切片的容量。
注意:cap是大于等于len的,当cap大于len的时候,说明切片未满,它们之间的元素并不属于当前切片。
回答:
数组是值类型,长度固定。作为参数传递时,会创建整个数组的副本,修改函数内的数组不会影响原数组.
切片是引用类型,长度不固定,可以动态扩容。作为参数传递时,传递的是引用,修改函数内的切片会影响原切片(底层数组相同)
4.2 切片怎么扩容?
分析:
这个问题其实是对上个问题的补充提问,因为切片的长度不固定,可以动态扩容,所以需要了解其具体的扩容策略是怎样的,这里回答的要点是需要区分go的版本,在go1.17之前和之后扩容策略是不一样的
回答:
1.17及以前,
1)如果期望容量大于当前容量的两倍就会使用期望容量;
2)如果当前切片的容量小于 1024 就会将容量翻倍;
3)如果当前切片的容量大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量。
1.18之后,
1)如果期望容量大于当前容量的两倍,使用期望容量;
2)如果当前切片的容量小于 256就会按容量前的容量翻倍;
3)否则按照公式:新容量=老容量+(老容量+3*256)/4 循环计算,直至预估容量>=期望容量。
长度: 1 | 新容量: 1 | 扩容倍数: 1.00x
长度: 2 | 新容量: 2 | 扩容倍数: 2.00x # 1→2 (2倍)
长度: 3 | 新容量: 4 | 扩容倍数: 2.00x # 2→4 (2倍)
长度: 5 | 新容量: 8 | 扩容倍数: 2.00x # 4→8 (2倍)
长度: 9 | 新容量: 16 | 扩容倍数: 2.00x # 8→16 (2倍)
长度: 17 | 新容量: 32 | 扩容倍数: 2.00x # 16→32 (2倍)
长度: 33 | 新容量: 64 | 扩容倍数: 2.00x # 32→64 (2倍)
长度: 65 | 新容量: 128 | 扩容倍数: 2.00x # 64→128 (2倍)
长度: 129 | 新容量: 256 | 扩容倍数: 2.00x # 128→256 (2倍)
长度: 257 | 新容量: 512 | 扩容倍数: 2.00x # 256→512 (2倍)
长度: 513 | 新容量: 848 | 扩容倍数: 1.66x # 512→848 (1.66倍,因为 >256)
长度: 849 | 新容量: 1280 | 扩容倍数: 1.51x # 848→1280
长度: 1281 | 新容量: 1792 | 扩容倍数: 1.40x # 1280→1792
长度: 1793 | 新容量: 2560 | 扩容倍数: 1.43x # 1792→2560扩容策略特点
小切片激进扩容:容量 < 256 时直接翻倍,减少频繁扩容
大切片保守扩容:容量 ≥ 256 时使用公式 oldCap + (oldCap+3*256)/4,避免内存浪费
内存对齐优化:最终容量对齐到 Size Class,提高内存利用率
避免过度分配:当一次追加大量元素时,会直接扩容到所需容量
性能建议
预分配容量:如果知道最终大小,使用 make([]T, 0, n) 预分配
避免小增量追加:批量追加比单次追加更高效
大切片谨慎操作:大切片扩容可能触发 GC 和内存复制
5.for i,v:= range 切片,v地址会变化吗?
分析:
for range是面试中经常会出现的一个问题,用于考察面试者语言基础是否扎实。主要会考察写代码时经常遇到的的一些坑,这里就要对for range整个语法糖有一个深层次的了解,for range在遍历的时候,其实它的底层实现是这样的,会对原切片做一次拷贝,确定其值和长度,遍历数组中每个元素的时候都把这个值赋给同一个临时变量,所以每次遍历拿到的是同一个地址,但是值不同。
回答:
地址不会发生变化,但是该地址的值是变化的,每遍历到一个元素,就把该元素值就会写到该地址。
PS:在最新版本Go 1.22中,v的地址会变化的,也就是不再共享变量了,知道这点的话,在面试定要提出来,展示自己的技术面广
追加一个思考题
for range 循环遍历 slice 有什么问题? 如果对slice用for range遍历,遍历过程中追加元素会不会遍历到?
答:
不会,for range本质上会先获取切片的长度(len),然后按照这个初始长度进行迭代,不会随着切片后续的长度变化而动态调整遍历范围。
6、go defer,多个 defer 的顺序,defer 在什么时机会修改返回值?(defer 和return) defer 的执行顺序。
分析:
关于go语言中的defer,需要明确defer的作用和执行机制,一般用defer来做什么,优势在什么地方,defer在函数返回前执行过程又是怎样的?在回答的时候要突出顺序是LIFO这个特性,接着可以简单介绍下defer底层实现是怎么实现的
可以回顾defer的底层实现:在当前函数return的时候,依次从defer函数在注册的时候,创建的 defer结构会依次插入到 defer链表的表头,defer链表的表头取出_defer结构执行里面的fn函数,所以执行顺序是LIFO。
回答:
defer的执行顺序类似于栈,是后进先出,先调用的defer语句后执行。
6.1 defer和return的执行顺序
分析
defer在return的时候有机会修改返回值,return的过程可以被分解为以下三步:
1.设置返回值;2.执行defer语句;3.将结果返回。
回答:
可以使用
6.2 defer在什么时机会修改返回值?
可以在defer函数中修改命名的返回值,进行修改返回值
package main
import "fmt"
func namedReturn() (result int) {
defer func() {
result = 100 // 可以修改命名返回值
}()
return 50 // 这里的 return 会先执行,但 defer 还会修改 result
}
func main() {
fmt.Println(namedReturn()) // 输出: 100
}6.3 recover的说明和总结
recover 是一个内置函数,用于捕获程序中的 panic(可以理解为 “程序崩溃信号”),防止程序直接退出。其核心特性如下:
生效条件:recover 必须在 defer 修饰的函数中调用才有效;
作用范围:只能捕获当前 goroutine 中的 panic,无法跨 goroutine 捕获;
返回值:若捕获到 panic,返回 panic 的值(通常是错误信息);若没有 panic,返回 nil。
package main
import "fmt"
func riskyOperation() {
// 用defer注册一个函数,内部调用recover捕获panic
defer func() {
if err := recover(); err != nil {
// 捕获到panic,打印错误信息(避免程序崩溃)
fmt.Println("捕获到异常:", err)
}
}()
fmt.Println("执行危险操作...")
// 模拟一个异常(如数组越界、空指针等)
panic("操作失败:数据格式错误")
// 以下代码不会执行(panic后流程被中断)
fmt.Println("危险操作完成")
}
func main() {
riskyOperation()
fmt.Println("程序继续执行(未崩溃)")
}
/*
执行危险操作...
捕获到异常:操作失败:数据格式错误
程序继续执行(未崩溃)
*/recover 只能捕获当前 goroutine 的 panic,子协程的 panic 无法被父协程的 recover 捕获:
package main
import (
"fmt"
"time"
)
func main() {
// 父协程的defer无法捕获子协程的panic
defer func() {
if err := recover(); err != nil {
fmt.Println("父协程捕获到异常:", err)
}
}()
// 启动子协程
go func() {
fmt.Println("子协程执行中...")
panic("子协程出错:内存溢出") // 子协程触发panic
}()
time.Sleep(1 * time.Second) // 等待子协程执行
fmt.Println("父协程结束")
}
/*
子协程执行中...
panic: 子协程出错:内存溢出
goroutine 6 [running]:
main.main.func2()
.../main.go:17 +0x65
created by main.main
.../main.go:15 +0x85
exit status 2
*/1.用recover捕获异常时,只能捕获当前goroutine的panic,不能捕获其他goroutine发生的panic。
2.一个recover只能捕获一次panic,且一一对应。
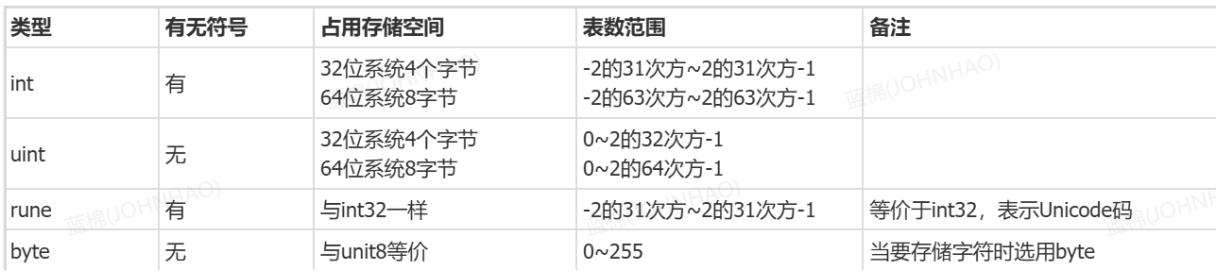
7. uint 类型溢出
分析:
关于整形溢出主要是考察go语言基本数据类型的大小范围是否了解,以及各种数据类型的占用和空间大小,下表整理了go语言基本数据类型的大小范围,溢出主要是关注无符号整数的溢出。
8.介绍 rune 类型
分析:
主要考察对go语言基本数据类型有没有细致的了解,rune类型是go语言一种特殊的数据类型,回答的时候重点要突出rune类型具体在底层对应什么数据类型(int32),以及它的作用是用作处理字符的。
uint8 类型,或者叫 byte 型,代表了 ASCII 码的一个字符。
rune 类型,代表一个 UTF-8 字符,当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型。rune类型等价于 int32 类型。
回答:
rune类型是 Go 语言的一种特殊数字类型。在builtin/builtin.go文件中,它的定义:type rune = int32;官方对它的解释是:rune是类型int32的别名,在所有方面都等价于它,用来区分字符值跟整数值。使用单引号定义,返回采用 UTF-8 编码的 Unicode 码点。Go 语言通过rune处理中文,支持国际化多语言。
package main
import "fmt"
func main() {
// 1. rune用于表示Unicode字符(码点)
s := "你好,世界 "
for i, r := range s { // range遍历字符串时,返回的r是rune类型(Unicode码点)
fmt.Printf("索引%d: rune=%q(码点值:%d)\n", i, r, r)
}
// 2. int32用于普通整数
var num int32 = 100
fmt.Println("int32数值:", num+200) // 常规整数运算
// 显式转换后可比较
fmt.Println(r == rune(i)) // true(将int32转为rune)
fmt.Println(int32(r) == i) // true(将rune转为int32)
}
/*
索引0: rune='你'(码点值:20320)
索引3: rune='好'(码点值:22909)
索引6: rune=','(码点值:65292)
索引9: rune='世'(码点值:19990)
索引12: rune='界'(码点值:30028)
索引15: rune=' '(码点值:32)
索引16: rune=''(码点值:127757)
int32数值: 300
true
true
*/9.Go中两个Nil可能不相等吗?
分析:
两个数据要进行比较,首先得明白数据类型,对于两个nil的比较同样如此,这里主要得注意interface类型,因为interface类型是类型T和值V二者的综合,只有在类型T和值V都相等的情况下,两个interface才会相等接口(interface) 是对非接口值(例如指针,struct等)的封装,内部实现包含 2 个字段,类型丅和 值 V。一个接口等于 nil,当且仅当丅和V处于 unset 状态(T=nil,V is unset)两个接口值比较时,会先比较T,再比较 V。接口值与非接口值比较时,会先将非接口值尝试转换为接口值,再比较。
回答:
Go中两个Ni可能不相等,当一个接口类型的变量为nil和一个非接口类型的变量也为nil的时候,虽然两者都为nil但是却不相等。
10. golang 中解析 tag 是怎么实现的?反射原理是什么?(问的很少,但是代码中用的多)
10.1 解析 tag
分析:
首先要明白,tag是什么以及tag的规则,go语言中的tag就是就是结构体中的各个字段的一个标签Tag 本身是一个字符串,它是 以空格分隔的 key:value 对。
key:必须是非空字符串,不能包含控制字符、空格、引号、冒号;
value:以双引号标记的字符串;
注意:冒号前后不能有空格。
回答:
Go 中解析的 tag 是通过反射实现的。
package main
import (
"fmt"
"reflect"
)
// 定义一个带有tag的结构体(模拟用户信息)
type User struct {
Name string `json:"username" db:"user_name" comment:"用户姓名"`
Age int `json:"age" db:"user_age" comment:"用户年龄"`
Email string `json:"-" db:"user_email" comment:"用户邮箱(序列化时忽略)"` // json:"-" 表示序列化时忽略该字段
}
// 解析结构体的tag并打印
func parseStructTag(s interface{}) {
// 获取结构体的反射类型(需先判断是否为结构体)
t := reflect.TypeOf(s)
if t.Kind() != reflect.Struct {
fmt.Println("输入不是结构体")
return
}
// 遍历结构体的所有字段
fmt.Printf("结构体字段Tag解析结果:\n")
for i := 0; i < t.NumField(); i++ {
field := t.Field(i) // 获取第i个字段
fieldName := field.Name // 字段名(如Name、Age)
// 获取各tag的值
jsonTag := field.Tag.Get("json") // 获取json标签
dbTag := field.Tag.Get("db") // 获取db标签
commentTag := field.Tag.Get("comment") // 获取comment标签
// 打印结果
fmt.Printf("字段名:%s\n", fieldName)
fmt.Printf(" json标签:%q\n", jsonTag)
fmt.Printf(" db标签:%q\n", dbTag)
fmt.Printf(" comment标签:%q\n\n", commentTag)
}
}
func main() {
var user User
parseStructTag(user) // 解析User结构体的tag
}10.2 反射的实现原理
分析:
主要考察反射的实现机制,即获取数据的动态类型和动态值,联想一下我们学习的知识,在哪一节讲过动态类型和动态值,就是interface,所以这题回答的关键点就是要点出interface,然后介绍下,interface的底层实现。
回答:
反射是指计算机程序在运行时(Run time)可以访问、检测和修改它本身状态或行为的一种能力Go语言反射是通过接口来实现的,通过隐式转换,普通的类型被转换成interface类型,这个过程涉及到类型转换的过程,首先从Golang类型转为interface类型,再从interface类型转换成反射类型,再从反射类型得到想的类型和值的信息。
11.go struct 能不能比较?
分析:
主要考察对qo语言基本数据类型的掌握程度,其实本质就是考察哪些数据结构不能比较,哪些可以比较,在go语言中,回答的时候,要明确可比较的范围,很明显,两个不同类型的数据类型不能进行比较,struct包含不可比较的字段也是不可比较的。
回答:
1.对于不同类型的struct无法进行比较;而同一个struct的两个实例可比较也不可比较。
2.在Go中,Slice、map、func无法比较,当一个struct的成员是这三种类型中的任意一个,就无法进行比较。反之,struct是可以进行比较的。
12.结构体打印时,% 和 %+v 的区别?
回答:
%v 输出结构体各成员的值;
%+v 输出结构体各成员的名称和值;
%#v 输出结构体名称和结构体各成员的名称和值。
package main
import "fmt"
// 定义一个示例结构体
type Person struct {
Name string
Age int
City string
}
func main() {
// 创建结构体实例
p := Person{
Name: "Alice",
Age: 30,
City: "Shanghai",
}
// 分别使用三种格式化动词打印
fmt.Println("使用%v打印:")
fmt.Printf("%v\n\n", p)
fmt.Println("使用%+v打印:")
fmt.Printf("%+v\n\n", p)
fmt.Println("使用%#v打印:")
fmt.Printf("%#v\n", p)
}
/*
使用%v打印:
{Alice 30 Shanghai}
使用%+v打印:
{Name:Alice Age:30 City:Shanghai}
使用%#v打印:
main.Person{Name:"Alice", Age:30, City:"Shanghai"}
*/13.空 struct{} 占用空间么?空 struct{}有什么用途?
空 struct{} 占用空间么?
回答:
空结构体 struct{} 实例不占据任何的内存空间。如果空 struct 是别的 struct 末尾的字段则会占空间。
空 struct{}有什么用途?
分析:
不占用内存的struct有什么用处?正因为不占用内存,所以空struct被广泛作为各种场景下的占位符使用。
1)将 map 作为集合(Set)使用时,可以将值类型定义为空结构体,仅作为占位符使用即可。
package main
import "fmt"
// 定义一个字符串集合(Set)
type StringSet map[string]struct{}
// 添加元素到集合
func (s StringSet) Add(v string) {
s[v] = struct{}{} // 用空结构体作为值,不占内存
}
// 判断元素是否在集合中
func (s StringSet) Contains(v string) bool {
_, exists := s[v]
return exists
}
func main() {
set := make(StringSet)
set.Add("apple")
set.Add("banana")
set.Add("apple") // 重复添加,不会生效
fmt.Println("集合大小:", len(set)) // 输出:2(去重)
fmt.Println("是否包含banana:", set.Contains("banana")) // 输出:true
fmt.Println("是否包含orange:", set.Contains("orange")) // 输出:false
}
/*
集合大小: 2
是否包含banana: true
是否包含orange: false
*/2)不发送数据的信道(channel):
使用 channel 不需要发送任何的数据,只用来通知子协程(goroutine)执行任务,或只用来控制协程并发度。
package main
import (
"fmt"
"time"
)
func worker(id int, done chan struct{}) {
fmt.Printf("工人%d: 开始工作\n", id)
time.Sleep(time.Second) // 模拟工作耗时
fmt.Printf("工人%d: 工作完成\n", id)
done <- struct{}{} // 发送完成信号(无需传递数据)
}
func main() {
done := make(chan struct{}) // 用于传递完成信号的channel
// 启动3个工人
for i := 1; i <= 3; i++ {
go worker(i, done)
}
// 等待所有工人完成(接收3个信号)
for i := 1; i <= 3; i++ {
<-done
}
fmt.Println("所有工作已完成")
}
/*
工人3: 开始工作
工人1: 开始工作
工人2: 开始工作
工人2: 工作完成
工人3: 工作完成
工人1: 工作完成
所有工作已完成
*/3)用作接口的实现,结构体只包含方法,不包含任何的字段。
package main
import "fmt"
// 定义一个空接口
type Doer interface {
Do()
}
// 用空结构体实现Doer接口
type SimpleDoer struct{}
func (d SimpleDoer) Do() {
fmt.Println("执行Do操作")
}
func main() {
var doer Doer = SimpleDoer{}
doer.Do() // 输出:执行Do操作
}15.go中"_"下划线的作用分析
下划线在go语言中可以出现在不同的位置,可以在import中,也可以在代码中出现,在不同的场合其作用是不一样的,在回答的时候要凸显出在不同场景下,回答全面
1.import中的下滑线:
又称空白导入,其作用如下:
1)执行包的初始化函数
强制触发目标包的 init() 函数,该函数会在程序启动时自动执行(在 main() 之前)。
2)注册机制
常用于数据库驱动、图像解码器等需要向全局注册表注册自己的场景。
3)避免编译错误
解决 "imported but not used" 编译错误,表明导入是有意为之(即使未显式使用包)。
4)副作用驱动
依赖包的初始化逻辑(如全局变量初始化、资源注册等)作为副作用生效。
import (
"database/sql"
_ "github.com/go-sql-driver/mysql" // 空白导入 MySQL 驱动
)
func main() {
// 驱动在 init() 中注册:sql.Register("mysql", ...)
db, err := sql.Open("mysql", "user:password@/dbname")
// ... 操作数据库
}说明:mysql 包的 init() 函数会调用 sql.Register() 将自己注册到 Go 的 SQL 系统。
2.下划线在代码中:
作用是:下划线在代码中是忽略这个变量。
也可以理解为占位符,那个位置上本应该赋某个值,但是我们不需要这个值,所以就把该值给下划线,意思是丢掉不要,这样编译器可以更好的优化,任何类型的单个值都可以丢给下划线。如果方法返回两个值,只想要其中的一个结果,那另一个就用占位。
回答:
1) import中的下滑线用于执行导入包下的所有init函数;
2) 代码体中的下划线用于忽略返回值。
16.Go 闭包
分析:
主要考察对go语言对匿名函数的支持,回答的时候点出匿名函数关键字即可,面试中不常见。
回答:
1.匿名函数也可以被称为闭包;
2.闭包实际上就是匿名函数 + 引用环境(捕获的变量);
a.在《深度探索Go语言》一书中提到,从语义角度来讲,闭包捕获变量并不是要复制一个副本,变量无论被捕获与否都应该是唯一的,所谓捕获只是编译器为闭包函数访问外部环境中的变量搭建了一个桥梁。这个桥梁可以复制变量的值,也可以存储变量的地址。只有在变量的值不会再改变的前提下,才可以复制变量的值,否则就会出现不一致错误
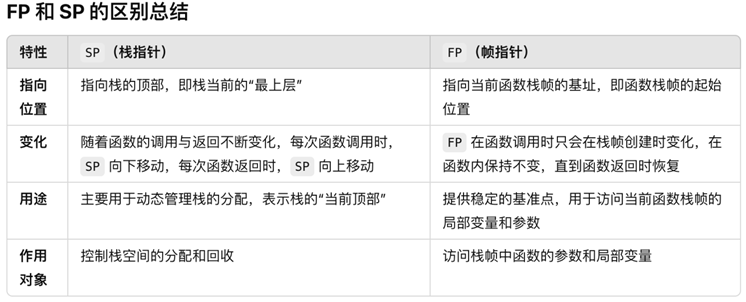
17.Go 多返回值怎么实现的?
分析:
主要考察go语言中对函数栈帧的了解程度,要清楚go语言中函数调用过程中,函数栈帧是怎样保存各个寄存器值的,以及栈帧的布局是怎样的,回答这个问题要突出go语言函数调用是通过fp寄存器+offset来实现的。
回答:
Go函数传参是通过fp+offset来实现的,而多个返回值也是通过fp+offset存储在调用函数的栈帧中。
18.Go 语言中不能比较的类型如何比较是否相等?
分析:
这个题目主要考察对reflect.DeepEqual的了解,因为基本类型都可以用==来比较,但是涉及到像不能比较的类型,比如slice,map怎么比较,所以再回答的时候要点出关键字reflect.DeepEqual
回答:
1.像 string,int,float interface 等可以通过 reflect.DeepEqual 和等于号进行比较;
2.像 slice,struct,map 则一般使用 reflect.DeepEqual 来检测是否相等。
举例使用reflect.DeepEqual的用法:
import (
"fmt"
"reflect"
)
type Address struct {
City string
Street string
}
type User struct {
ID int
Name string
Address Address
}
func main() {
u1 := User{1, "Alice", Address{"Beijing", "Main St"}}
u2 := User{1, "Alice", Address{"Beijing", "Main St"}}
u3 := User{1, "Bob", Address{"Shanghai", "Nanjing Rd"}}
fmt.Println(reflect.DeepEqual(u1, u2)) // true
fmt.Println(reflect.DeepEqual(u1, u3)) // false
m1 := map[string]int{"a": 1, "b": 2}
m2 := map[string]int{"b": 2, "a": 1}
m3 := map[string]int{"a": 1, "b": 3}
fmt.Println(reflect.DeepEqual(m1, m2)) // true(键值对相同)
fmt.Println(reflect.DeepEqual(m1, m3)) // false(值不同)
fmt.Println(reflect.DeepEqual(42, 42)) // true
fmt.Println(reflect.DeepEqual("Go", "Go")) // true
fmt.Println(reflect.DeepEqual(3.14, 3.140)) // true (浮点数精度)
fmt.Println(reflect.DeepEqual([]int{1,2}, []int{1})) // false
}19.Go 中init 函数的特征?
分析:
主要考察go语言的初始化过程,初始化过程中分为全局变量,init函数,在初始化过程中主要是要明确他们的初始化顺序,所以回答要点要突出各个包下的全局变量,init函数,它们的执行顺序。
回答:
执行顺序的优先级:
全局变量初始化 → 导入包的init() → 当前包的init() → main()
多个init的情况:
1) 文件内部:从上到下依次执行init函数
2)同一个包内有多个文件:导入包后会按照包内的文件名的排序(a.go在b.go前面)查找文件并执行init函数。
3)多个包,并且存在嵌套导入的情况,会按照包导入的顺序,深度优先去调用包中的init函数
比如:有3个包,我们的文件导入了A,B,但是在A中导入了C,这样我们init函数的调用顺序是
main → 导入 A → A导入C → C的init → A的init → 导入 B → B的init
20.Go 中uintptr 和 unsafe.Pointer 的区别?
分析:
考察对go语言中指针的了解,go语言中指针分为普通指针类型unsafe.Pointer,uintptr(本质不是指针,下面会进行说明)。三者的功能各不相同:
- *类型:普通指针类型,用于传递对象地址,不能进行指针运算;
- unsafe.Pointer:通用指针类型,用于转换不同类型的指针,不能进行指针运算,不能读取内存存储的值(必须转换到某一类型的普通指针)。
- uintptr:用于指针运算,GC 不把 uintptr 当指针,uintptr 无法持有对象。uintptr 类型的目标会被回收。
在回答unsafe.Pointer和uintptr的区别时,重点突出指针运算上。unsafe.Pointer用于指针类型转换,不能参与运算,而uintptr 可以运算。
回答:
1.unsafe.Pointer 是通用指针类型,它不能参与计算,任何类型的指针都可以转化成unsafe.Pointer。unsafe.Pointer 可以转化成任何类型的指针
当我们想让普通指针类型之间进行转换的时候,就需要unsafe.Pointer作为中间指针。
2.uintptr 可以转换为 unsafe.Pointer。unsafe.Pointer 可以转换为 uintptr。uintptr 是指针运算的工具,但是它不能持有指针对象(意思就是它跟指针对象不能互相转换),unsafe.Pointer 是指针对象进行运算(也就是uintptr)的桥梁。
a.很多人都认为uintptr是个指针,其实不然。不要对这个名字感到疑惑,它只不过是个uint,大小与当前平台的指针宽度一致。因为unsafe.Pointer可以跟uintptr互相转换,所以Go语言中可以把指针转换为uintptr进行数值运算,然后转换回原类型,以此来模拟C语言中的指针运算。
b.Unsafe.Pointer类似于C语言中的void类型指针,虽然未指定元素类型,但是本身类型就是个指针。
二、知识点总结
1、常见的数据结构
(1)常见的数据类型

数组(Array)
- 特点:长度固定的同类型元素集合,值类型(赋值时复制整个数组)。
- 用途:存储长度已知且固定的数据。
// 定义长度为3的int数组
var arr [3]int = [3]int{1, 2, 3}
fmt.Println(arr[0]) // 访问元素:1切片(Slice)
- 特点:动态长度的同类型元素集合,引用类型(底层指向数组),支持动态扩容。
- 用途:最常用的序列类型,替代动态数组。
// 定义切片(长度3,容量5)
s := make([]int, 3, 5)
s = append(s, 4, 5) // 追加元素,长度变为5
fmt.Println(s) // [0 0 0 4 5]映射(Map)
- 特点:键值对集合(哈希表实现),无序,引用类型,键必须是可比较类型。
- 用途:快速查找(O (1) 复杂度)、存储关联数据。
// 定义string到int的映射
m := map[string]int{
"apple": 5,
"banana": 3,
}
fmt.Println(m["apple"]) // 访问值:5
m["orange"] = 2 // 添加键值对结构体(Struct)
- 特点:自定义复合类型,可包含多个不同类型的字段,用于封装数据。
- 用途:表示实体(如用户、订单等),存储结构化数据。
// 定义用户结构体
type User struct {
Name string
Age int
ID string
}
u := User{Name: "Alice", Age: 30}
fmt.Println(u.Name) // 访问字段:Alice指针(Pointer)
- 特点:存储变量内存地址的类型,引用类型,可通过
*访问目标值,&获取地址。 - 用途:传递大型数据时避免复制,修改函数外部变量。
x := 10
p := &x // p是指向x的指针
*p = 20 // 通过指针修改x的值
fmt.Println(x) // 输出:20通道(Channel)
- 特点:用于 goroutine 之间通信的管道,可带缓冲或无缓冲,引用类型。
- 用途:并发控制、数据同步、消息传递。
// 创建无缓冲通道
ch := make(chan int)
go func() {
ch <- 100 // 发送数据到通道
}()
v := <-ch // 从通道接收数据
fmt.Println(v) // 输出:100接口(Interface)
- 特点:定义方法集合的抽象类型,无需显式实现(隐式匹配方法集)。
- 用途:实现多态、抽象封装、解耦代码。
// 定义接口
type Shape interface {
Area() float64
}
// 圆实现Shape接口
type Circle struct {
Radius float64
}
func (c Circle) Area() float64 {
return 3.14 * c.Radius * c.Radius
}
func main() {
var s Shape = Circle{Radius: 2}
fmt.Println(s.Area()) // 输出:12.56
}注意:golang中没有set类型,通过map可以实现set类型。使用
map[interface{}]struct{} 实现一个set。它将map的k作为set的v,map的v弃用以struct{}占用
package main
import "fmt"
// Set 结构体,使用map存储元素
type Set struct {
elements map[interface{}]struct{} // 键为集合元素,值为占位的空结构体
}
// NewSet 创建一个新的Set
func NewSet() *Set {
return &Set{
elements: make(map[interface{}]struct{}),
}
}
// Add 向集合中添加元素
func (s *Set) Add(element interface{}) {
s.elements[element] = struct{}{} // 利用map键的唯一性实现去重
}
// Remove 从集合中移除元素
func (s *Set) Remove(element interface{}) {
delete(s.elements, element)
}
// Contains 判断元素是否在集合中
func (s *Set) Contains(element interface{}) bool {
_, exists := s.elements[element]
return exists
}
// Size 返回集合中元素的数量
func (s *Set) Size() int {
return len(s.elements)
}
// Clear 清空集合
func (s *Set) Clear() {
s.elements = make(map[interface{}]struct{})
}
// Elements 返回集合中所有元素
func (s *Set) Elements() []interface{} {
elements := make([]interface{}, 0, s.Size())
for elem := range s.elements {
elements = append(elements, elem)
}
return elements
}
func main() {
// 创建一个新集合
set := NewSet()
// 添加元素
set.Add("apple")
set.Add(100)
set.Add(true)
set.Add("apple") // 重复添加,不会生效
// 查看集合元素
fmt.Println("集合元素:", set.Elements()) // 输出包含 apple、100、true(顺序不固定)
fmt.Println("集合大小:", set.Size()) // 输出:3
// 判断元素是否存在
fmt.Println("是否包含100:", set.Contains(100)) // 输出:true
fmt.Println("是否包含banana:", set.Contains("banana")) // 输出:false
// 移除元素
set.Remove(100)
fmt.Println("移除100后元素:", set.Elements()) // 输出包含 apple、true
fmt.Println("移除后大小:", set.Size()) // 输出:2
// 清空集合
set.Clear()
fmt.Println("清空后大小:", set.Size()) // 输出:0
}2、interface总结
接口是 Go 语言中实现多态和抽象的核心机制,提供了一种定义对象行为的契约式编程模型。
2.1 接口定义
接口定义了一组方法签名(方法名、参数和返回值类型),但不包含具体实现:
// 定义接口
type Shape interface {
Area() float64
Perimeter() float64
}2.2 接口实现
类型隐式实现接口 - 只需实现接口中的所有方法:
package main
import (
"fmt"
"math"
)
// 定义Shape接口
type Shape interface {
Area() float64
Perimeter() float64
}
// 矩形类型实现Shape接口
type Rectangle struct {
Width, Height float64
}
func (r Rectangle) Area() float64 {
return r.Width * r.Height
}
func (r Rectangle) Perimeter() float64 {
return 2 * (r.Width + r.Height)
}
// 圆形类型实现Shape接口
type Circle struct {
Radius float64
}
func (c Circle) Area() float64 {
return math.Pi * c.Radius * c.Radius
}
func (c Circle) Perimeter() float64 {
return 2 * math.Pi * c.Radius
}
// 使用接口的函数
func printShapeInfo(s Shape) {
fmt.Printf("类型: %T, 面积: %.2f, 周长: %.2f\n", s, s.Area(), s.Perimeter())
}
func main() {
// 创建矩形实例
rect := Rectangle{Width: 5, Height: 3}
fmt.Println("=== 矩形 ===")
fmt.Printf("宽度: %.2f, 高度: %.2f\n", rect.Width, rect.Height)
fmt.Printf("面积: %.2f\n", rect.Area())
fmt.Printf("周长: %.2f\n", rect.Perimeter())
// 创建圆形实例
circle := Circle{Radius: 4}
fmt.Println("\n=== 圆形 ===")
fmt.Printf("半径: %.2f\n", circle.Radius)
fmt.Printf("面积: %.2f\n", circle.Area())
fmt.Printf("周长: %.2f\n", circle.Perimeter())
// 使用接口多态
fmt.Println("\n=== 接口多态 ===")
printShapeInfo(rect)
printShapeInfo(circle)
// 将不同形状放入同一个切片
fmt.Println("\n=== 形状集合 ===")
shapes := []Shape{
Rectangle{Width: 3, Height: 4},
Circle{Radius: 5},
Rectangle{Width: 6, Height: 2},
}
for i, shape := range shapes {
fmt.Printf("形状 #%d: 类型=%T, 面积=%.2f\n", i+1, shape, shape.Area())
}
}注意:在 Go 语言中,当一个类型要实现某个接口时,必须实现该接口中定义的所有方法。这是 Go 接口设计的核心原则之一,称为"完全实现"规则。
package main
import "fmt"
// 定义接口
type Shape interface {
Area() float64
Perimeter() float64
}
// 只实现部分方法 - 将导致编译错误
type IncompleteShape struct{}
func (s IncompleteShape) Area() float64 {
return 0
}
// 缺少 Perimeter() 方法实现
func main() {
// 编译错误: IncompleteShape 未实现 Shape 接口(缺少 Perimeter 方法)
var s Shape = IncompleteShape{}
fmt.Println(s)
}2.3 接口使用
1) 多态调用
func PrintShapeDetails(s Shape) {
fmt.Printf("面积: %.2f, 周长: %.2f\n", s.Area(), s.Perimeter())
}
func main() {
rect := Rectangle{Width: 5, Height: 3}
circle := Circle{Radius: 4}
// 相同接口,不同行为
PrintShapeDetails(rect) // 面积: 15.00, 周长: 16.00
PrintShapeDetails(circle) // 面积: 50.27, 周长: 25.13
}2) 空接口 (interface{})
空接口没有任何方法声明,可以接受任何类型的值:
func PrintAnything(v interface{}) {
fmt.Printf("值: %v, 类型: %T\n", v, v)
}
func main() {
PrintAnything(42) // 值: 42, 类型: int
PrintAnything("hello") // 值: hello, 类型: string
PrintAnything([]int{1,2,3}) // 值: [1 2 3], 类型: []int
}3) 类型断言
检查接口值的实际类型并提取:
func processValue(v interface{}) {
// 类型断言
if s, ok := v.(string); ok {
fmt.Println("字符串:", strings.ToUpper(s))
} else if i, ok := v.(int); ok {
fmt.Println("整数:", i*2)
} else {
fmt.Println("未知类型")
}
// 类型开关
switch val := v.(type) {
case string:
fmt.Printf("字符串长度: %d\n", len(val))
case int:
fmt.Printf("平方值: %d\n", val*val)
default:
fmt.Printf("不支持的类型: %T\n", val)
}
}4) 接口嵌套
组合多个接口创建新接口:
package main
import (
"fmt"
)
// 定义基础接口
type Logger interface {
Log(message string)
}
type Shaper interface {
Area() float64
}
// 组合接口
type LoggableShape interface {
Logger
Shaper
}
// 定义矩形类型
type Rectangle struct {
Width, Height float64
}
// 实现Shaper接口
func (r Rectangle) Area() float64 {
return r.Width * r.Height
}
// 实现组合接口的类型
type LoggableRectangle struct {
Rectangle
}
// 实现Logger接口
func (lr LoggableRectangle) Log(message string) {
fmt.Printf("[LOG] %s: 尺寸 %.2fx%.2f\n", message, lr.Width, lr.Height)
}
// 处理LoggableShape的函数
func ProcessLoggableShape(ls LoggableShape) {
ls.Log("处理形状")
fmt.Println("面积:", ls.Area())
}
func main() {
// 创建LoggableRectangle实例
lr := LoggableRectangle{
Rectangle: Rectangle{
Width: 3,
Height: 4,
},
}
// 调用处理函数
ProcessLoggableShape(lr)
}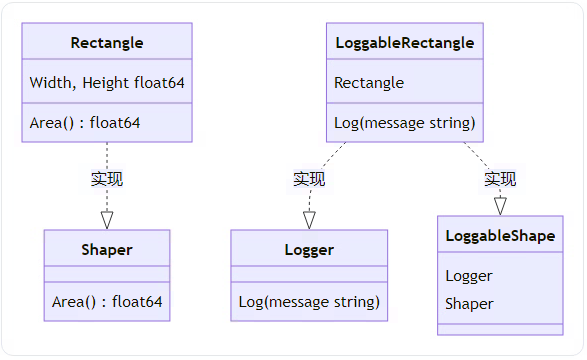
在上面的代码中,我们想编译成功,必须要将Logger和Shaper中的方法实现,Rectangle实现了Area,LoggableRectangle中实现了Logger,LoggableRectangle中又包含了Rectangle,所以通过多态LoggableRectangle作为入参赋给LoggableShape接口,并且可以直接调用。
5) 接口值内部结构
接口值包含两部分:
动态类型:实际值的类型
动态值:实际存储的值
var s Shape
fmt.Println(s == nil) // true,类型和值都为nil
s = Rectangle{5, 3}
fmt.Printf("类型: %T, 值: %v\n", s, s) // main.Rectangle, {5 3}2.4 高级用法
1)接口作为接收者
package main
import "fmt"
// 定义基础接口
type StringProcessor interface {
Process() string
}
// 定义装饰器类型(实现接口增强)
type EnhancedStringProcessor struct {
StringProcessor
}
// 为装饰器类型添加增强方法
func (esp EnhancedStringProcessor) EnhancedProcess() string {
return "✨" + esp.Process() + "✨"
}
// 具体实现类型
type SimpleString string
func (ss SimpleString) Process() string {
return string(ss)
}
func main() {
// 创建基础实现
base := SimpleString("hello")
// 包装为增强处理器
var proc StringProcessor = base
enhanced := EnhancedStringProcessor{proc}
fmt.Println(enhanced.EnhancedProcess()) // ✨hello✨
// 直接使用增强功能
fmt.Println(EnhancedStringProcessor{base}.EnhancedProcess()) // ✨hello✨
}需要注意的是:
在 Go 语言中,不能直接在接口类型上定义实现方法。以下是错误代码:
type StringProcessor interface {
Process() string
}
// 这是无效的语法 - Go 不允许在接口上定义方法实现
func (sp StringProcessor) EnhancedProcess() string {
return "✨" + sp.Process() + "✨"
}2)空接口与JSON处理
func parseJSON(data []byte) (interface{}, error) {
var result interface{}
if err := json.Unmarshal(data, &result); err != nil {
return nil, err
}
return result, nil
}
func main() {
jsonData := []byte(`{"name":"Alice","age":30,"hobbies":["reading","coding"]}`)
result, _ := parseJSON(jsonData)
// 类型断言处理
if m, ok := result.(map[string]interface{}); ok {
for k, v := range m {
fmt.Printf("%s: ", k)
switch val := v.(type) {
case string:
fmt.Println(val)
case float64:
fmt.Println(int(val))
case []interface{}:
fmt.Println(strings.Join(func() []string {
var s []string
for _, item := range val {
s = append(s, fmt.Sprint(item))
}
return s
}(), ", "))
}
}
}
}3)接口与测试模拟
// 数据库接口
type Database interface {
GetUser(id int) (string, error)
}
// 真实实现
type RealDB struct{}
func (db RealDB) GetUser(id int) (string, error) {
// 实际数据库查询
return "Real User", nil
}
// 测试实现
type MockDB struct{}
func (db MockDB) GetUser(id int) (string, error) {
return "Mock User", nil
}
// 业务逻辑
func GetUserName(db Database, id int) string {
name, _ := db.GetUser(id)
return name
}
func main() {
// 生产环境
fmt.Println(GetUserName(RealDB{}, 1)) // Real User
// 测试环境
fmt.Println(GetUserName(MockDB{}, 1)) // Mock User
}2.5 接口设计最佳实践
1)接口越小越好
// 推荐:单一职责
type Reader interface {
Read(p []byte) (n int, err error)
}
// 不推荐:包含过多方法
type FileHandler interface {
Open() error
Read() ([]byte, error)
Write([]byte) error
Close() error
}2)使用组合而非继承
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
// 组合接口
type ReadWriter interface {
Reader
Writer
}3)避免不必要的空接口
// 不推荐
func Process(data interface{}) {}
// 推荐:定义具体接口
type Processor interface {
ProcessData()
}
func Process(p Processor) {}4)接口命名规范
单方法接口:方法名 + "er"(如 Reader, Writer)
多方法接口:描述性名词(如 Shape, Database)
2.6 常见错误
1)空接口误用
// 错误:无法直接操作空接口值
func add(a, b interface{}) interface{} {
return a + b // 编译错误
}
// 正确:类型断言
func add(a, b interface{}) interface{} {
switch a := a.(type) {
case int:
return a + b.(int)
case float64:
return a + b.(float64)
default:
panic("不支持的类型")
}
}2)nil接口值
var s Shape
s.Perimeter() // 运行时panic: nil pointer dereference3)接口污染
// 避免在API中暴露不必要的接口
// 应该返回具体类型而非接口
func NewRectangle() Rectangle { ... }
// 而不是
func NewRectangle() Shape { ... }Go 的接口设计实现了 "鸭子类型":如果它走起来像鸭子,叫起来像鸭子,那么它就是鸭子。这种设计提供了极大的灵活性,是 Go 语言强大并发模型和标准库设计的基础。
3、什么是CSP模式 和 GMP调度模式
3.1 CSP模式
CSP 是一种基于 “通信” 的并发理论
核心思想:
- “通过通信共享内存,而非通过共享内存通信”传统并发模型(如 Java)多依赖共享内存 + 锁机制实现协作,而 CSP 强调:
- 1)并发实体(如 Go 中的 goroutine)是独立的 sequential processes(顺序进程),各自执行自己的逻辑;
- 2)实体间通过 **“通道(channel)”** 传递消息来协作,而非直接操作共享内存。
Go 中的 CSP 体现:
- Goroutine:轻量级线程(并发实体),对应 CSP 中的 “process”;
- Channel:用于 goroutine 之间通信的管道,对应 CSP 中的 “channel”;
- 避免共享状态:通过 channel 传递数据,减少锁的使用(但 Go 并不禁止共享内存,只是推荐通信方式)。
3.2 GMP调度模式
GMP 是 Go 语言实现 goroutine 调度的具体机制,是 Go 运行时(runtime)管理 goroutine 的核心,其中 G、M、P 分别代表三种关键组件:
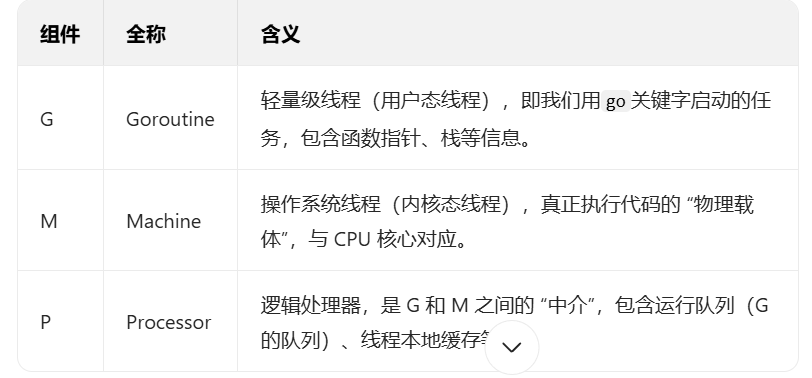
CSP 与 GMP 的关系
- CSP 是 “思想”:定义了 goroutine 通过 channel 通信的并发范式;
- GMP 是 “实现”:负责高效地调度 goroutine 在操作系统线程上运行,让 CSP 的思想得以落地。
简单说:CSP 告诉我们 “goroutine 应该如何协作”,GMP 告诉我们 “goroutine 如何被高效执行”。
4、golang中闭包的总结
闭包(Closure)是 Go 语言中的核心特性,指函数与其引用环境(外部变量)的组合。闭包允许函数访问并操作其声明作用域之外的变量,即使外部函数已执行完毕。
核心特性
1)捕获变量:内部函数可访问外部函数的局部变量
2)状态保持:闭包内的变量状态在多次调用间持续存在
3)延迟绑定:闭包在调用时才访问变量的当前值
4)内存逃逸:被闭包引用的变量会从栈逃逸到堆上
基本实例(最常见的用返回值使用):
package main
import "fmt"
func counter() func() int {
count := 0 // 被闭包捕获的变量
return func() int {
count++ // 修改外部变量
return count
}
}
func main() {
c := counter() // 创建闭包
fmt.Println(c()) // 1(首次调用)
fmt.Println(c()) // 2(状态保留)
fmt.Println(c()) // 3
newC := counter() // 新闭包实例
fmt.Println(newC()) // 1(独立状态)
}闭包作为参数使用:
// 数据处理流水线
func process(data []int, fn func(int) int) []int {
result := make([]int, len(data))
for i, v := range data {
result[i] = fn(v) // 调用传入的闭包
}
return result
}
func main() {
data := []int{1, 2, 3}
// 场景1:平方计算(闭包作为参数)
squared := process(data, func(x int) int {
return x * x
})
// 场景2:增量加密(捕获外部变量)
key := 10
encrypted := process(data, func(x int) int {
return x + key // 闭包捕获外部key变量
})
}立即调用
func main() {
// 立即执行闭包:初始化配置
config := func() map[string]string {
env := os.Getenv("APP_ENV")
return map[string]string{
"env": env,
"logLevel": "debug",
}
}() // 立即执行
fmt.Println(config["env"]) // 输出环境变量
}结构体中的使用
type Counter struct {
count int
}
func (c *Counter) Incrementer() func() int {
return func() int {
c.count++ // 闭包捕获结构体字段
return c.count
}
}
func main() {
c := &Counter{}
inc := c.Incrementer()
fmt.Println(inc()) // 1
fmt.Println(inc()) // 2
}闭包和匿名函数的区别:
核心结论:所有闭包都是匿名函数,但并非所有匿名函数都是闭包。闭包的本质是捕获了外部变量的匿名函数。
匿名函数如下:
func main() {
// 纯匿名函数(无状态)
sum := func(a, b int) int {
return a + b // 仅使用参数
}
fmt.Println(sum(3, 5)) // 8
}没有捕获外部变量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号