

深入解析:机器学习:欠拟合、过拟合、正则化
一、欠拟合
欠拟合:一个假设 在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据 ,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
欠拟合代码实现:
例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error # 计算均方误差
from sklearn.model_selection import train_test_split
def dm01_欠拟合():
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化 线性回归模型.
estimator = LinearRegression()
# 3. 训练模型
X = x.reshape(-1, 1)
estimator.fit(X, y)
# 4. 模型预测.
y_predict = estimator.predict(X)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
plt.plot(x, y_predict, color='r') # 折线图(预测值, 拟合回归线)
plt.show() # 具体的绘图
if __name__ == '__main__':
dm01_欠拟合()运行结果: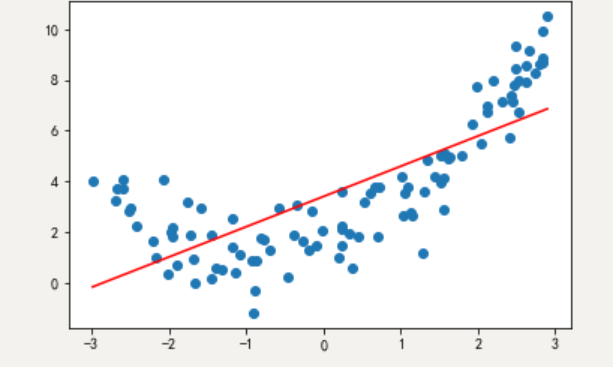
二、过拟合
过拟合:一个假设 在训练数据上能够获得比其他假设更好的拟合, 但是在测试数据集上却不能很好地拟合数据 (体现在准确率下降),此时认为这个假设出现了过拟合的现象。
过拟合代码实现:
例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error # 计算均方误差
from sklearn.model_selection import train_test_split
def dm03_过拟合():
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化 线性回归模型.
estimator = LinearRegression()
# 3. 训练模型
X = x.reshape(-1, 1)
# hstack() 函数用于将多个数组在行上堆叠起来, 即: 数据增加高次项.
X3 = np.hstack([X, X**2, X**3, X**4, X**5, X**6, X**7, X**8, X**9, X**10])
estimator.fit(X3, y)
# 4. 模型预测.
y_predict = estimator.predict(X3)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
# sort() 该函数直接返回一个排序后的新数组。
# numpy.argsort() 该函数返回的是数组值从小到大排序时对应的索引值
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r') # 折线图(预测值, 拟合回归线)
plt.show() # 具体的绘图
if __name__ == '__main__':
dm03_过拟合()运行结果: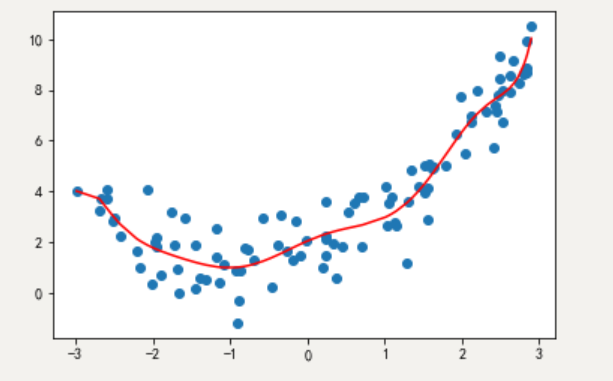
三、拟合问题原因及解决办法
1.欠拟合产生原因: 学习到数据的特征过少。
解决办法:
1)添加其他特征项,有时出现欠拟合是因为特征项不够导致的,可以添加其他特征项来解决。
2)添加多项式特征,模型过于简单时的常用套路,例如将线性模型通过添加二次项或三次项使模型泛化能力更强。
2.过拟合产生原因: 原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾所有测试样本。
解决办法:
1)重新清洗数据,导致过拟合的一个原因有可能是数据不纯,如果出现了过拟合就需要重新清洗数据。
2)增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小。
3)正则化
4)减少特征维度。
四、正则化:尽量减少高次幂特征的影响

(一)L1正则化
LASSO回归: from sklearn.linear_model import Lasso
代码如下:
from sklearn.linear_model import Lasso # L1正则
from sklearn.linear_model import Ridge # 岭回归 L2正则
def dm04_模型过拟合_L1正则化():
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化L1正则化模型, 做实验: alpha惩罚力度越来越大, k值越来越小.
estimator = Lasso(alpha=0.005)
# 3. 训练模型
X = x.reshape(-1, 1)
# hstack() 函数用于将多个数组在行上堆叠起来, 即: 数据增加高次项.
X3 = np.hstack([X, X**2, X**3, X**4, X**5, X**6, X**7, X**8, X**9, X**10])
estimator.fit(X3, y)
print(f'权重: {estimator.coef_}')
# 4. 模型预测.
y_predict = estimator.predict(X3)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
# sort() 该函数直接返回一个排序后的新数组。
# numpy.argsort() 该函数返回的是数组值从小到大排序时对应的索引值
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r') # 折线图(预测值, 拟合回归线)
plt.show() # 具体的绘图
if __name__ == '__main__':
dm04_模型过拟合_L1正则化()(二)L2正则化
Ridge回归: from sklearn.linear_model import Ridge
代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression, Lasso, Ridge
from sklearn.metrics import mean_squared_error # 计算均方误差
from sklearn.model_selection import train_test_split
def dm05_模型过拟合_L2正则化():
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化L2正则化模型, 做实验: alpha惩罚力度越来越大, k值越来越小.
estimator = Ridge(alpha=0.005)
# 3. 训练模型
X = x.reshape(-1, 1)
# hstack() 函数用于将多个数组在行上堆叠起来, 即: 数据增加高次项.
X3 = np.hstack([X, X**2, X**3, X**4, X**5, X**6, X**7, X**8, X**9, X**10])
estimator.fit(X3, y)
print(f'权重: {estimator.coef_}')
# 4. 模型预测.
y_predict = estimator.predict(X3)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
# sort() 该函数直接返回一个排序后的新数组。
# numpy.argsort() 该函数返回的是数组值从小到大排序时对应的索引值
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r') # 折线图(预测值, 拟合回归线)
plt.show() # 具体的绘图
if __name__ == '__main__':
# dm04_模型过拟合_L1正则化()
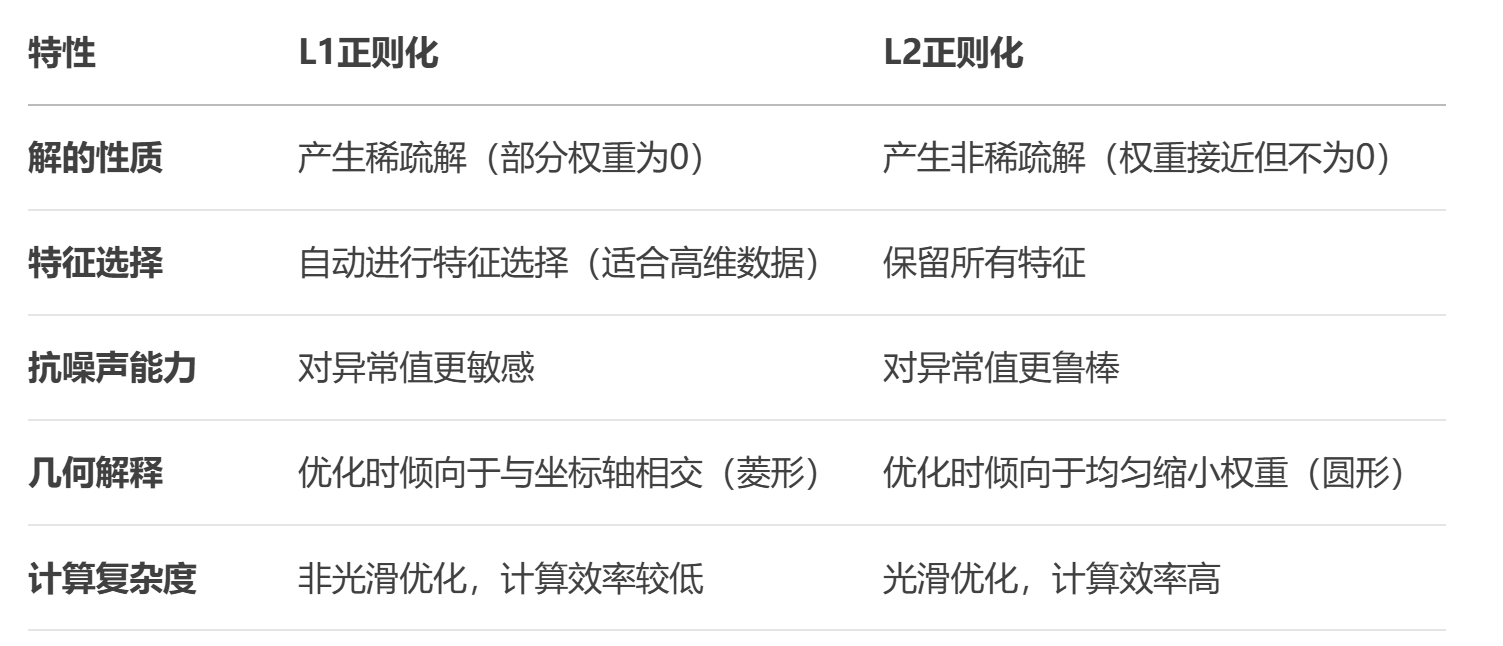
dm05_模型过拟合_L2正则化()(三)L1正则化与L2正则化的对比
五、正好拟合代码(附赠)
例:
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
def dm02_模型ok():
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化 线性回归模型.
estimator = LinearRegression()
# 3. 训练模型
X = x.reshape(-1, 1)
X2 = np.hstack([X, X ** 2])
estimator.fit(X2, y)
# 4. 模型预测.
y_predict = estimator.predict(X2)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
# sort() 该函数直接返回一个排序后的新数组。
# numpy.argsort() 该函数返回的是数组值从小到大排序时对应的索引值
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r') # 折线图(预测值, 拟合回归线)
# plt.plot(x, y_predict)
plt.show() # 具体的绘图运行结果: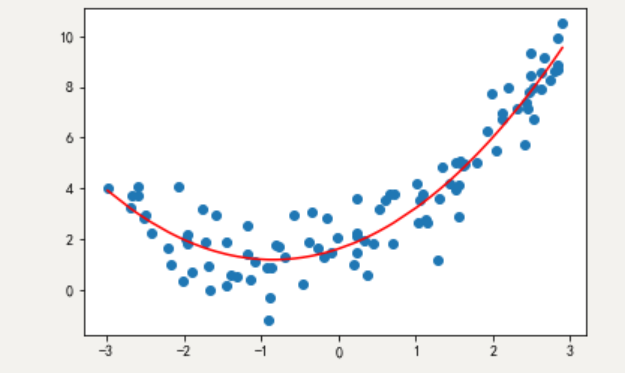
今天的分享到此结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号