

【AI论文】基于预训练数据的强化学习 - 指南
摘要一种用于优化大型语言模型的新型训练时扩展范式。与以往关键通过监督学习来扩展训练的方法不同,RLPT使策略能够自主探索有意义的轨迹,从而从预训练信息中学习,并经过强化学习(RL)提升其能力。现有的强化学习策略,如基于人类反馈的强化学习(RLHF)和具备可验证奖励的强化学习(RLVR),均依赖人工标注来构建奖励机制,而RLPT则通过直接从预训练信息中推导奖励信号,消除了这一依赖。具体而言,RLPT采用下一段文本推理目标,即奖励策略在给定前文语境的条件下,准确预测后续文本片段的能力。这种设定使得强化学习能够在预训练资料上进行扩展,鼓励模型在更广泛的语境中探索更丰富的轨迹,从而培养更具泛化能力的推理技能。在多个模型上进行的一般领域和数学推理基准测试中的广泛实验验证了RLPT的有效性。例如,将RLPT应用于Qwen3-4B-Base模型时,在MMLU、MMLU-Pro、GPQA-Diamond、KOR-Bench、AIME24和AIME25基准测试中,分别取得了3.0、5.1、8.1、6.0、6.6和5.3的绝对提升。实验结果进一步表明了其良好的扩展性,表明随着计算量的增加,模型性能有望持续提升。此外,RLPT还为扩展大型语言模型的推理边界、提升RLVR性能奠定了坚实基础。Huggingface链接:就是:计算资源呈指数级增长,而高质量文本数据的增长却有限,这种日益扩大的差距,如今已对大型语言模型(LLMs)的传统扩展方法构成了制约。为应对这一挑战,大家提出了基于预训练数据的强化学习(Reinforcement Learning on Pre-Training data,RLPT),这Paper page,论文链接:2509.19249
研究背景和目的
研究背景:
随着计算资源的指数级增长,大型语言模型(LLMs)在多个领域取得了显著的成功,包括对话助手、自主AI代理等。
然而,LLMs的性能提升主导依赖于计算资源和数据规模的同步扩展,这导致了基础设施需求的不断增加和推理成本的急剧上升。同时,高质量的网络语料库日益稀缺,进一步限制了LLMs的扩展。特别是在预训练阶段,现有的扩展方法重要依赖于监督学习,这限制了模型从预训练数据中学习复杂推理轨迹的能力。
在强化学习(RL)领域,RLHF(Reinforcement Learning from Human Feedback)和RLVR(Reinforcement Learning with Verifiable Rewards)等策略已被用于提升LLMs的性能,但这些方法严重依赖于人类标注来构建奖励信号,从而限制了其在预训练素材上的可扩展性。
因此,如何管用地利用大规模预训练材料,通过强化学习提升LLMs的推理能力,成为当前研究的重要挑战。
研究目的:
本研究旨在提出一种新的训练时扩展范式——预训练数据上的强化学习(RLPT),通过自主探索预训练数据中的有意义轨迹,提升LLMs的推理能力。
具体而言,RLPT旨在消除对人类标注的依赖,通过设计一种自监督的下一个片段推理目标,直接从预训练数据中推导出奖励信号,从而鼓励模型在更广泛的上下文中探索更丰富的轨迹,培养更通用的推理技能。本研究还希望依据广泛的实验验证RLPT的有效性,并分析其扩展行为,为未来LLMs的优化提供新的理论基础和实践指导。
研究方法
数据准备:
为了构建RLPT的训练语料库,研究团队从多个来源收集了大规模的网络文本数据,包括Wikipedia、arXiv和论坛数据等。
为了确保数据质量,研究团队实施了多阶段预处理流程,包括基于MinHash的近似去重、个人身份信息检测和污染去除等。此外,为了增强数据的多样性,研究还引入了高质量的QA素材,特别是针对数学推理任务的数据,以提升模型的推理能力。
模型训练:
RLPT的训练过程主要包括两个阶段:冷启动阶段和下一个片段推理阶段。
在冷启动阶段,研究团队使用指令跟随数据对基础模型进行了监督微调,以赋予模型主要的指令跟随能力。随后,在下一个片段推理阶段,模型被训练以预测给定上下文后的下一个文本片段,并通过语义一致性评估预测片段和真实片段之间的奖励。具体而言,研究提出了两种任务:自回归片段推理(ASR)和中间片段推理(MSR),并通过交错执行这两种任务来同时优化模型的自回归生成能力和上下文理解能力。
奖励模型:
为了评估预测片段和真实片段之间的语义一致性,研究团队采用了一个生成式奖励模型。
该模型通过比较预测片段和参考段落来评估其语义内容是否等效,同时允许语言变异。严格的奖励机制被放宽为前缀奖励,即只要预测片段构成参考内容的有效前缀,就分配一个奖励分数,这克服了不同信息含量的句子之间的差异问题,供应了更稳定的训练信号。
实验设置:
实验在Llama3和Qwen3模型系列上进行,冷启动阶段利用批量大小为1024、学习率为2×10-5的余弦调度器进行3个epoch的训练。[18]下一个片段推理阶段采用批量大小512、最大响应长度8192和恒定学习率1×10-6。每个提示采样8个输出,温度为1.0,并使用不带KL正则化的GRPO算法进行优化。
研究结果
性能提升:
RLPT在多个基准测试上显著提升了模型的性能。
例如,在Qwen3-4B-Base模型上,RLPT在MMLU、MMLU-Pro、GPQA-Diamond、KOR-Bench、AIME24和AIME25等基准测试上分别完成了3.0%、5.1%、8.1%、6.0%、6.6%和5.3%的绝对提升。这些结果表明,RLPT在提升模型推理能力方面具有显著效果。
数学推理任务:
在数学推理任务上,RLPT同样表现出色。在Qwen3-4B-Base模型上,RLPT在MATH-500、AMC23、Minerva Math和AIME等基准测试上,Pass@1和Pass@8指标均有显著提升。
专门是当RLPT作为RLVR的基础时,进一步提升了性能,表明RLPT为后续的RLVR训练提供了坚实的基础。
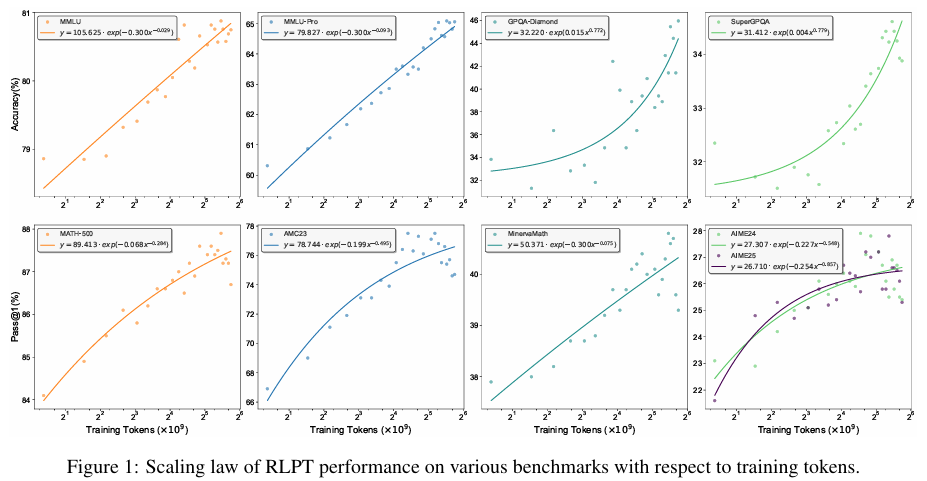
** scaling行为**:
研究还分析了RLPT的扩展行为,发现其性能随着训练token数量的增加而提升,表明增加计算量可能带来进一步的性能提升。这一发现支持了RLPT在更大计算量下继续提升性能的潜力。
定性分析:
通过对推理轨迹的定性分析,研究揭示了RLPT如何通过结构化的推理过程生成预测内容。模型在预测下一个片段时,首先抽象上下文以捕捉整体流程,随后确定后续步骤,制定候选延续方案,验证其合理性,并在必要时进行回溯,最终生成最终答案。
这一过程与LLMs在艰难障碍处理中展示的多步骤推理策略一致,进一步解释了RLPT的有效性。
研究局限
尽管RLPT在提升LLMs推理能力方面表现出色,但本研究仍存在一定局限性。最初,RLPT的性能高度依赖于预训练素材的质量和多样性。假如数据集中存在偏差或噪声,可能会影响模型的训练效果和泛化能力。其次,尽管自监督的下一个片段推理目标在一定程度上解除了奖励信号的获取问题,但语义一致性评估仍可能受到语言变异的影响,导致奖励信号的不稳定。
此外,本研究主要在现有模型上进行了验证,未来需要在更多模型和更大规模的数据集上进一步验证RLPT的有效性和鲁棒性。
未来研究方向
针对本研究的局限性,未来研究可以从以下几个方面展开:第一,可以探索更先进的内容预处理和增强途径,以提高预训练资料的质量和多样性。例如,结合半监督学习或自监督学习办法,利用未标注数据来增强模型的泛化能力。
其次,可以进一步优化奖励模型的设计,提高其对语义一致性的评估准确性,减少语言变异对奖励信号的影响。此外,未来研究还行探索RLPT在其他类型任务(如情感分析、文本摘要等)上的应用,以及在不同语言和文化背景下的有效性。
同时,未来研究还可以关注RLPT与其他扩展策略(如测试时扩展)的结合使用,以进一步提升LLMs的性能。
例如,可以将RLPT与链式推理(CoT)策略结合,通过延长推理链来产生最终答案之前的生成步骤,进一步提高模型的推理能力。此外,还可能探索RLPT在多语言和多模态任务上的应用,通过引入多语言数据和多模态信息来提高模型的适应性和泛化能力。
此外,未来研究还许可关注RLPT在实际应用中的部署和效果评估。例如,许可将RLPT训练的模型部署到云端或边缘设备上,并提供高效的API接口供开发者采用。同时,可以与行业合作伙伴合作,共同推动RLPT在实际场景中的应用和发展。通过实际应用和反馈,不断优化和改进RLPT方法,提高其在处理复杂任务时的性能和稳定性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号