

Video-XL-Pro论文阅读 - 指南

1.摘要
background
现有的token压缩技术没有质量标准评估其有效性,且不考虑不同视频的信息强度差距采用固定压缩比
innovation
1.可学习的重构式Token压缩 (Reconstructive Compression of Tokens, ReCoT):论文提出了一个基于自监督学习的可学习模块ReCoT,它能生成既全面又紧凑的视频Token。该技巧的优越之处在于,它通过重构任务来保证压缩后Token的质量,确保关键信息得以保留。
动态Token合成器 (Dynamic Token Synthesizer, DTS):作为ReCoT的关键组件,DTS能够从静态图像Token中学习时空关系,捕捉视频的动态信息,生成更富含运动特征的伪视频Token。
语义引导的掩码 (Semantic-Guided Masking, SGM):SGM能够自适应地识别并掩盖视频中的冗余视觉Token(如静止的背景),从而引导DTS在重构学习中更专注于重要的、信息密集的区域,提高了训练效率和效果。
2.高效的训练和推理策略:
视频数据集剪枝 (Video Dataset Pruning):提出了一种根据帧间相似性过滤冗余或低信息量视频的策略,确保模型在训练时接触到更多样化、信息丰富的样本,提升了微调效率和泛化能力。
查询感知选择器 (Query-aware Selector):设计了一个简单的选择器,它能够根据用户输入的文本查询,精确定位并选择与查询最相关的视频Token。这使得模型在处理超长视频时,能将有限的上下文窗口聚焦于最关键的信息上。
2. 方法 Method
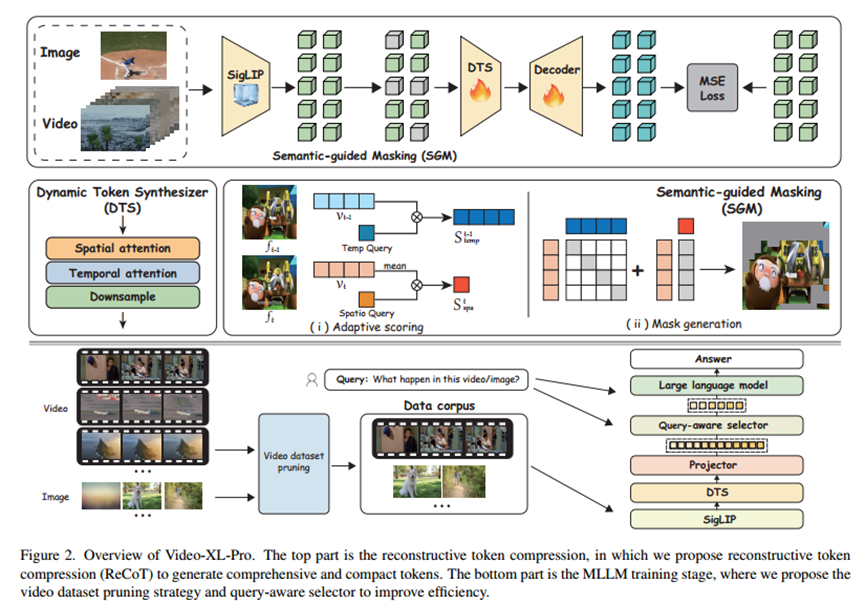
1.重建token压缩
动态token分析(DTS):
令牌合成模块位于SigLIP之后,提供两个关键功能:(i)总结冗余标记和(ii)从视频中捕获动态运动。具体地说,训练器由时空注意力块和3D卷积层构成,使其能够沿着时间维度将SigLIP从四个帧输出的令牌合并为沿着单个帧的令牌。
语义引导掩码(SGM):
自适应地掩蔽视频和图像中的冗余特征,从而指导训练器进行有效的重建训练。Temp Query与前一帧的标记相乘以获得Vt-1,而Spatio Query与当前帧的标记的语义平均值相乘以获得Vt。随后,Vt-1和Vt用于计算与当前帧的标记的注意力。最终,将两组注意力得分相加,得到最终的token得分。如算法1所示,在token得分的指导下,我们在训练过程中随机屏蔽低得分token,从而引导模型关注视频中的关键区域。

2.MLLM训练
Query-aware Selector:
使用LLM对输入文本查询进行编码,并将其传递到可训练的MLP层,以启用视觉标记计算注意力分数。遵循QueryAware的策略,我们利用这些注意力分数来指导视觉标记的选择,确保输入标记长度保持在LLM的允许范围内,同时过滤掉与当前查询无关的标记。查询感知的查询器会随机丢弃5%到30%的标记。然而,在推理过程中,只有当输入上下文长度超过LLM的限制时,选择器才会被激活。
Video Dataset Pruning:
首先,我们根据任务类型将所有视频数据划分为不同的子集,包括视频字幕,多项选择题回答和开放式问题回答。接下来,对于每个视频样本,该算法对20帧视频进行均匀采样,利用SigLIP算法计算帧内余弦相似度,并根据预定义的阈值,对每个子集进行压缩,过滤掉语义冗余度高的视频,最后保留具有信息强度的高质量视频,以提高训练效率
采用可变采样(最大360帧)来增强模型对长视频的泛化能力。
3. 实验 Experimental Results
实验数据集:
预训练/微调素材:使用了包括 LLaVA-OneVision, LAION-2M, NExT-QA, CinePile 在内的多种图文和视频数据集。
评测基准 (Benchmarks):在多个主流的长视频理解基准上进行了评测,包括MLVU, Video-MME, VNBench, LongVideoBench, TempCompass, 以及用于时间定位的V-STaR 和 Charades-STA。
主要实验结论:
主流基准性能对比:
实验目的:验证Video-XL-Pro相较于其他SOTA模型的综合性能。
结论:在只有3B参数的情况下,Video-XL-Pro在MLVU、Video-MME等多个基准上全面超越了大多数7B参数的开源模型,甚至在某些指标上超过了GPT-40等专有模型,展示了其卓越的性能和效率。
超长视频处理能力 (Needle-in-a-Haystack):
实验目的:测试模型处理极端长度视频的能力极限。
结论:Video-XL-Pro能够处理超过8000帧的视频输入,并以接近99%的准确率找到其中隐藏的关键信息,而其他模型(如LongVA)在处理少于400帧时已出现性能下降,或因计算成本而无法处理超过1000帧的视频。
时间定位能力:
实验目的:评估模型在视频中理解和定位特定时间点的能力。
结论:在V-STaR和Charades-STA任务上,Video-XL-Pro的表现远超之前的7B模型,证明其生成的紧凑Token保留了精确的时间信息。
消融实验:
DTS模块有效性:验证DTS模块是否能有效捕捉动态信息。结论是,加入了DTS后,即使Token被压缩了4倍,模型在视频分类任务上的性能也优于原始的SigLIP编码器,证明DTS成功地学习了时空特征。
SGM模块有效性,使用SGM的模型性能优于使用随机掩码的模型,说明SGM能管用引导模型关注关键区域。就是:比较语义引导掩码(SGM)与随机掩码的效果。结论
数据集剪枝有效性:验证内容剪枝策略的效果。结论是,使用10万条经过剪枝策略处理的内容进行训练,其效果与使用20万条随机挑选的信息相当,证明该策略能有效提升内容质量和训练效率。
4. 总结 Conclusion
提出了一种新颖且高效的就是这篇论文的核心贡献重构式Token压缩手段 (ReCoT),并基于此构建了Video-XL-Pro模型。该技巧通过自监督学习的方式,在大幅压缩视觉Token数量的同时,高质量地保留了视频的关键时空信息。这使得一个仅有3B参数的小模型,能够在极具挑战性的超长视频理解任务上,实现超越更大模型的性能,并显著提升了训练和推理的效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号