

分布式专题——10.4 ShardingSphere-Proxy服务端分库分表 - 实践
1 为什么要有服务端分库分表?
ShardingSphere-Proxy 是 ShardingSphere 提供的服务端分库分表工具,定位是“透明化的数据库代理”。
它模拟 MySQL 或 PostgreSQL 的数据库服务,应用程序(Application)只需像访问单个数据库一样访问 ShardingSphere-Proxy;
实际的分库分表逻辑,由 ShardingSphere-Proxy 在代理层完成,对应用程序完全透明;
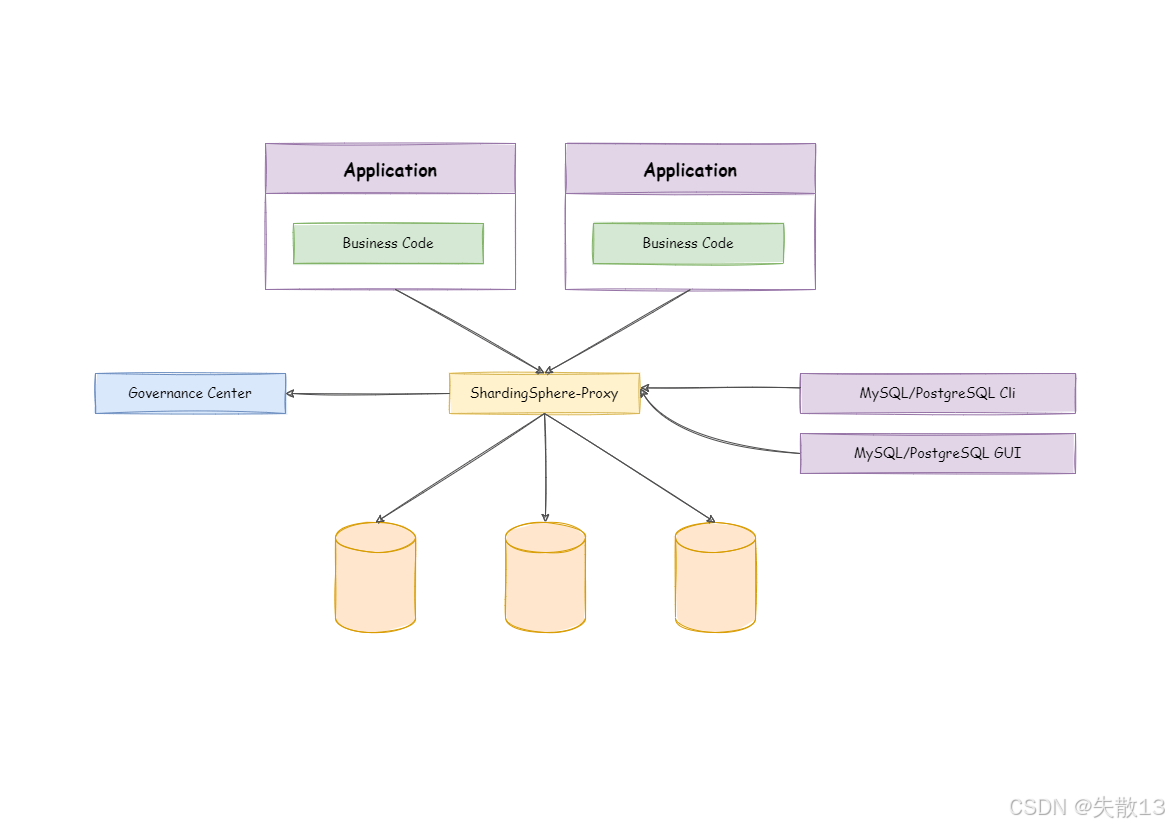
ShardingSphere-JDBC 已经能实现分库分表,为什么还需要 ShardingSphere-Proxy?
对 ORM 框架更友好
ShardingSphere-JDBC 的问题:需要在业务代码中直接写分库分表逻辑(比如代码里写:数据该路由到哪个库/表)。如果项目用了 ORM 框架(如 MyBatis、Hibernate),这种代码侵入式的逻辑容易和 ORM 冲突;
ShardingSphere-Proxy 的解决:作为第三方服务端代理,分库分表逻辑在代理层(ShardingSphere-Proxy)处理,应用程序完全不用关心。应用只需按访问单库的方式写代码,无缝对接 ORM 框架;
对 DBA(数据库管理员)更友好
ShardingSphere-JDBC 的问题:DBA 要管理分库分表后的数据库,得先了解 ShardingSphere 的专属功能和 API,学习成本高;
ShardingSphere-Proxy 的解决:对 DBA 完全透明。DBA 可以直接操作原始数据库(像平时管理 MySQL/PostgreSQL 一样),无需了解 ShardingSphere 的技术细节,简化了 DBA 的工作;
避免业务代码侵入分库分表逻辑
ShardingSphere-JDBC 的问题:分库分表的规则配置(比如“按用户 ID 分库”的规则)要写在业务代码里,会让业务代码变得臃肿。如果规则变更(比如从“按用户 ID 分”改成“按订单 ID 分”),要修改大量业务代码,维护成本高;
ShardingSphere-Proxy 的解决:通过外部配置文件管理分库分表规则,业务代码完全不用关心这些逻辑。规则变更时,只需改配置,不影响业务代码;
实现“无中心化”数据治理
ShardingSphere-JDBC 的局限:多数据源的治理(比如跨库监控、报警、统一管理)难以统一;
ShardingSphere-Proxy 的解决:多个数据源可以注册到同一个 ShardingSphere-Proxy 代理服务中。基于代理,能实现跨数据源的数据治理(比如统一监控、报警、数据管理),特别适合大规模微服务系统的运维。
2 基本使用
2.1 部署 ShardingSphere-Proxy
下载并解压(注意不要有中文,此处选择的版本:Apache Archive Distribution Directory);
ShardingSphere-Proxy 是一个典型的 Java 应用程序,解压后目录结构如下:

解压完成后,如果要连接 MySQL 数据库,那么需要手动将 JDBC 的驱动包
mysql-connector-java-8.0.20.jar复制到 ShardingSphere-Proxy 的lib目录下(ShardingSphere-Proxy 默认只附带了 PostgreSQL 的 JDBC 驱动包,没有包含 MySQL 的 JDBC 驱动包);打开
conf目录,在这个目录下就有 ShardingSphere-Proxy 的所有配置文件(不同版本的会不一样):
打开
server.yaml,把其中的rules部分和props部分的注释取消:rules: # 权限控制规则配置 - !AUTHORITY users: # 定义用户权限:root用户可从任何主机(%)访问,拥有root角色;sharding用户可从任何主机访问,拥有sharding角色 - root@%:root - sharding@:sharding provider: # 权限提供者类型:ALL_PERMITTED表示允许所有操作(无权限限制) type: ALL_PERMITTED # 事务管理配置 - !TRANSACTION # 默认事务类型:XA分布式事务 defaultType: XA # 事务管理器提供者:Atomikos(一种XA事务管理器实现) providerType: Atomikos # SQL解析器配置 - !SQL_PARSER # 启用SQL注释解析功能 sqlCommentParseEnabled: true sqlStatementCache: # SQL语句缓存初始容量 initialCapacity: 2000 # SQL语句缓存最大容量 maximumSize: 65535 parseTreeCache: # 解析树缓存初始容量 initialCapacity: 128 # 解析树缓存最大容量 maximumSize: 1024 # 属性配置 props: # 每个查询允许的最大连接数 max-connections-size-per-query: 1 # 内核线程池大小(默认无限制) kernel-executor-size: 16 # 代理前端刷新阈值(网络数据包刷新条件) proxy-frontend-flush-threshold: 128 # 是否启用Hint功能(强制路由提示) proxy-hint-enabled: false # 是否在日志中显示SQL语句 sql-show: false # 是否启用表元数据一致性检查 check-table-metadata-enabled: false # 代理后端查询获取大小:-1表示使用不同JDBC驱动程序的最小值 proxy-backend-query-fetch-size: -1 # 代理前端执行线程数:0表示由Netty自动决定 proxy-frontend-executor-size: # 代理后端执行模式:OLAP(联机分析处理)或OLTP(联机事务处理) proxy-backend-executor-suitable: OLAP # 代理前端最大连接数:0或负数表示无限制 proxy-frontend-max-connections: 0 # SQL联邦查询类型:NONE(禁用),ORIGINAL(原始),ADVANCED(高级) sql-federation-type: NONE # 代理后端驱动类型:JDBC(标准)或ExperimentalVertx(实验性Vert.x) proxy-backend-driver-type: JDBC # 默认MySQL版本号(当缺少schema信息时使用) proxy-mysql-default-version: 8.0.20 # 代理服务默认端口 proxy-default-port: 3307 # Netty网络连接后备队列长度 proxy-netty-backlog: 1024- 注意:为了与 MySQL JDBC 的驱动包
mysql-connector-java-8.0.20.jar兼容,将proxy-mysql-default-version修改为8.0.20;
- 注意:为了与 MySQL JDBC 的驱动包
启动:
然后就可以使用 MySQL 的客户端(比如 DataGrip)去连接 ShardingSphere-Proxy 了,且可以像用 MySQL 一样去使用 ShardingSphere-Proxy:
mysql> show databases; +--------------------+ | schema_name | +--------------------+ | shardingsphere | | information_schema | | performance_schema | | mysql | | sys | +--------------------+ 5 rows in set (0.01 sec) mysql> use shardingsphere Database changed mysql> show tables; +---------------------------+------------+ | Tables_in_shardingsphere | Table_type | +---------------------------+------------+ | sharding_table_statistics | BASE TABLE | +---------------------------+------------+ 1 row in set (0.01 sec) mysql> select * from sharding_table_statistics; Empty set (1.25 sec)不过要注意,此时 ShardingSphere-Proxy 只是一个虚拟库,所以并不能像 MySQL 一样去随意建表或修改数据,比如下面就建表失败:
mysql> CREATE TABLE test (id varchar(255) NOT NULL); Query OK, 0 rows affected (0.00 sec) mysql> select * from test; 30000 - Unknown exception: At line 0, column 0: Object 'test' not found mysql> show tables; +---------------------------+------------+ | Tables_in_shardingsphere | Table_type | +---------------------------+------------+ | sharding_table_statistics | BASE TABLE | +---------------------------+------------+ 1 row in set (0.01 sec)
2.2 常用的分库分表配置策略
打开
config-sharding.yaml,配置逻辑表course:# 逻辑数据库名称(客户端连接时使用的虚拟数据库名) databaseName: sharding_db # 数据源配置(定义实际的后端数据库连接) dataSources: # 第一个数据源,命名为m0 m0: # MySQL数据库连接URL,指向192.168.65.212服务器的3306端口,数据库名为shardingdb1 url: jdbc:mysql://192.168.65.212:3306/shardingdb1?serverTimezone=UTC&useSSL=false username: root password: root # 连接超时时间(毫秒) connectionTimeoutMilliseconds: 30000 # 连接空闲超时时间(毫秒) idleTimeoutMilliseconds: 60000 # 连接最大生命周期(毫秒) maxLifetimeMilliseconds: 1800000 # 连接池最大大小 maxPoolSize: 50 # 连接池最小大小 minPoolSize: 1 # 第二个数据源,命名为m1 m1: url: jdbc:mysql://192.168.65.212:3306/shardingdb2?serverTimezone=UTC&useSSL=false username: root password: root connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 minPoolSize: 1 # 分片规则配置 rules: - !SHARDING # 分片规则标识 tables: # 配置course表的分片规则 course: # 实际数据节点:分布在m0和m1数据库的course_1和course_2表中 actualDataNodes: m${0..1 }.course_${1..2 } # 数据库分片策略 databaseStrategy: standard: # 标准分片策略 shardingColumn: cid # 分片列(根据此字段的值决定数据路由到哪个数据库) shardingAlgorithmName: course_db_alg # 使用的分片算法名称 # 表分片策略 tableStrategy: standard: # 标准分片策略 shardingColumn: cid # 分片列(根据此字段的值决定数据路由到哪个表) shardingAlgorithmName: course_tbl_alg # 使用的分片算法名称 # 主键生成策略 keyGenerateStrategy: column: cid # 需要生成主键的列名 keyGeneratorName: alg_snowflake # 使用的主键生成器名称 # 分片算法定义 shardingAlgorithms: # 数据库分片算法:取模算法 course_db_alg: type: MOD # 取模分片算法 props: sharding-count: 2 # 分片数量(2个数据库) # 表分片算法:行表达式算法 course_tbl_alg: type: INLINE # 行表达式分片算法 props: # 算法表达式:根据cid字段的值取模2再加1,得到表后缀(1或2) algorithm-expression: course_${cid%2+1 } # 主键生成器定义 keyGenerators: # 雪花算法生成器,用于生成分布式唯一ID alg_snowflake: type: SNOWFLAKE # 使用雪花算法重新启动 ShardingSphere-Proxy 服务:
mysql> show databases; +--------------------+ | schema_name | +--------------------+ | information_schema | | performance_schema | | sys | | shardingsphere | | sharding_db | | mysql | +--------------------+ 6 rows in set (0.02 sec) mysql> use sharding_db; Database changed mysql> show tables; +-----------------------+------------+ | Tables_in_sharding_db | Table_type | +-----------------------+------------+ | course | BASE TABLE | | user_2 | BASE TABLE | | user | BASE TABLE | | user_1 | BASE TABLE | +-----------------------+------------+ 4 rows in set (0.02 sec) mysql> select * from course; +---------------------+-------+---------+---------+ | cid | cname | user_id | cstatus | +---------------------+-------+---------+---------+ | 1017125767709982720 | java | 1001 | 1 | | 1017125769383510016 | java | 1001 | 1 | mysql> select * from course_1; +---------------------+-------+---------+---------+ | cid | cname | user_id | cstatus | +---------------------+-------+---------+---------+ | 1017125767709982720 | java | 1001 | 1 | | 1017125769383510016 | java | 1001 | 1 |- 可以看到多了一个
sharding_db库。
- 可以看到多了一个
3 ShardingSphere-Proxy 中的分布式事务机制
3.1 为什么需要分布式事务?
在
2.1 部署 ShardingSphere-Proxy中配置server.yaml时,有一个TRANSACTION配置项:rules: - !TRANSACTION defaultType: XA providerType: Atomikos为什么 ShardingSphere-Proxy 需要分布式事务?
ShardingSphere(尤其是 ShardingSphere-Proxy)要操作分布式的数据库集群(多个库、多个节点)。而数据库的本地事务只能保证单个数据库内的事务安全,无法覆盖跨多个数据库的场景;
因此,必须引入分布式事务管理机制,才能保证 ShardingSphere-Proxy 中 SQL 执行的原子性。开启分布式事务后,开发者不用再手动考虑跨库 SQL 的事务问题。
3.2 什么是 XA 事务?
XA 是由 X/Open Group 组织定义的分布式事务标准,主流关系型数据库(如 MySQL、Oracle 等)都实现了 XA 协议(比如 MySQL 5.0.3+ 的 InnoDB 引擎支持 XA);
XA 事务的核心是两阶段提交(2PC),通过**准备(Prepare)和提交(Commit)**两个阶段,保证跨多个数据库的事务一致性;
XA 分布式事务操作示例:
-- 1. 开启XA事务,'test'是事务标识符(XID),将事务状态设置为ACTIVE(活跃) -- 事务标识符用于在分布式环境中唯一标识一个事务 XA START 'test'; -- 2. 在ACTIVE状态的XA事务中执行业务SQL语句 -- 这些操作是事务的一部分,但尚未最终提交 INSERT INTO dict VALUES(1, 't', 'test'); -- 3. 结束XA事务,将事务状态从ACTIVE改为IDLE(空闲) -- 表示事务内的所有操作已完成,准备进入准备阶段 XA END 'test'; -- 4. 准备提交事务,将事务状态从IDLE改为PREPARED(已准备) -- 此阶段事务管理器会确保所有资源管理器都已准备好提交 XA PREPARE 'test'; -- 5. 列出所有处于PREPARED状态的XA事务 -- 返回的信息包含:gtrid(全局事务ID)、bqual(分支限定符)、formatID(格式ID)和data(数据) XA RECOVER; -- 6. 提交已准备的XA事务,使所有更改永久生效 -- 这是两阶段提交的第二阶段(提交阶段) XA COMMIT 'test'; -- 6. 替代方案:回滚已准备的XA事务,撤销所有更改 -- 在PREPARED状态下也可以选择回滚而不是提交 XA ROLLBACK 'test'; -- 注意:也可以使用单条命令直接提交,将预备和提交合并操作 -- XA COMMIT 'test' ONE PHASE;ShardingSphere 集成了多个 XA 实现框架(Atomikos、Bitronix、Narayana)。在 ShardingSphere-Proxy 中,默认只集成了 Atomikos(所以配置里
providerType: Atomikos)。
3.3 实战理解 XA 事务
引入 Maven 依赖:
<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-transaction-xa-core</artifactId> <version>5.2.1</version> <exclusions> <exclusion> <artifactId>transactions-jdbc</artifactId> <groupId>com.atomikos</groupId> </exclusion> <exclusion> <artifactId>transactions-jta</artifactId> <groupId>com.atomikos</groupId> </exclusion> </exclusions> </dependency> <!-- 版本滞后了 --> <dependency> <artifactId>transactions-jdbc</artifactId> <groupId>com.atomikos</groupId> <version>5.0.8</version> </dependency> <dependency> <artifactId>transactions-jta</artifactId> <groupId>com.atomikos</groupId> <version>5.0.8</version> </dependency> <!-- 使用XA事务时,可以引入其他几种事务管理器 --> <!-- <dependency>--> <!-- <groupId>org.apache.shardingsphere</groupId>--> <!-- <artifactId>shardingsphere-transaction-xa-bitronix</artifactId>--> <!-- <version>5.2.1</version>--> <!-- </dependency>--> <!-- <dependency>--> <!-- <groupId>org.apache.shardingsphere</groupId>--> <!-- <artifactId>shardingsphere-transaction-xa-narayana</artifactId>--> <!-- <version>5.2.1</version>--> <!-- </dependency>-->配置事务管理器:
@Configuration @EnableTransactionManagement public class TransactionConfiguration { @Bean public PlatformTransactionManager txManager(final DataSource dataSource) { return new DataSourceTransactionManager(dataSource); } }测试案例:
public class MySQLXAConnectionTest { public static void main(String[] args) throws SQLException { // 是否打印XA相关命令,用于调试目的 boolean logXaCommands = true; // ============== 初始化阶段:建立数据库连接 ============== // 获取第一个数据库连接(资源管理器RM1) Connection conn1 = DriverManager.getConnection("jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC", "root", "root"); // 创建XA连接包装器,用于支持分布式事务 XAConnection xaConn1 = new MysqlXAConnection((com.mysql.cj.jdbc.JdbcConnection) conn1, logXaCommands); // 获取XA资源接口,用于控制分布式事务 XAResource rm1 = xaConn1.getXAResource(); // 获取第二个数据库连接(资源管理器RM2) Connection conn2 = DriverManager.getConnection("jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC", "root", "root"); // 创建第二个XA连接包装器 XAConnection xaConn2 = new MysqlXAConnection((com.mysql.cj.jdbc.JdbcConnection) conn2, logXaCommands); // 获取第二个XA资源接口 XAResource rm2 = xaConn2.getXAResource(); // 生成全局事务ID(GTrid,是全局事务标识符,在整个事务生命周期中唯一) byte[] gtrid = "g12345".getBytes(); int formatId = 1; // 格式标识符,通常为1,表示标准XID格式 try { // ============== 分别执行RM1和RM2上的事务分支 ==================== // 为第一个资源管理器生成分支事务ID(BQual) byte[] bqual1 = "b00001".getBytes(); // 创建完整的事务ID(XID),包含全局ID和分支ID Xid xid1 = new MysqlXid(gtrid, bqual1, formatId); // 开始第一个分支事务,TMNOFLAGS表示新建一个事务(不是加入或恢复现有事务) rm1.start(xid1, XAResource.TMNOFLAGS); // 在第一个分支事务中执行SQL操作 PreparedStatement ps1 = conn1.prepareStatement("INSERT INTO `dict` VALUES (1, 'T', '测试1');"); ps1.execute(); // 结束第一个分支事务,TMSUCCESS表示事务执行成功 rm1.end(xid1, XAResource.TMSUCCESS); // 为第二个资源管理器生成分支事务ID byte[] bqual2 = "b00002".getBytes(); // 创建第二个事务ID Xid xid2 = new MysqlXid(gtrid, bqual2, formatId); // 开始第二个分支事务 rm2.start(xid2, XAResource.TMNOFLAGS); // 在第二个分支事务中执行SQL操作 PreparedStatement ps2 = conn2.prepareStatement("INSERT INTO `dict` VALUES (2, 'F', '测试2');"); ps2.execute(); // 结束第二个分支事务 rm2.end(xid2, XAResource.TMSUCCESS); // =================== 两阶段提交流程 ============================ // 第一阶段:准备阶段 - 询问所有资源管理器是否准备好提交事务 int rm1_prepare = rm1.prepare(xid1); int rm2_prepare = rm2.prepare(xid2); // 第二阶段:提交阶段 - 根据准备阶段的结果决定提交或回滚 boolean onePhase = false; // 设置为false表示使用标准的两阶段提交 // 检查所有资源管理器是否都准备成功 if (rm1_prepare == XAResource.XA_OK && rm2_prepare == XAResource.XA_OK ) { // 所有分支都准备成功,提交所有事务 rm1.commit(xid1, onePhase); rm2.commit(xid2, onePhase); } else { // 如果有任何一个分支准备失败,回滚所有事务 rm1.rollback(xid1); rm2.rollback(xid2); } } catch (XAException e) { // 处理XA异常,打印异常信息 e.printStackTrace(); } } }XA标准规范了事务XID的格式,它由三个部分组成:
gtrid [, bqual [, formatID ]],具体含义如下:gtrid(全局事务标识符):
- global transaction identifier,是用于标识一个全局事务的唯一值 。在分布式事务场景下,多个数据库节点参与同一个事务,通过这个全局事务标识符可以将这些操作关联到一起,明确它们属于同一个事务;
- 比如在一个涉及电商系统多个数据库(订单库、库存库、支付库)的分布式事务中,通过相同的gtrid就能确认这些数据库上的操作都属于同一次购物流程对应的事务;
bqual(分支限定符):
- branch qualifier ,用来进一步限定事务分支。如果没有提供,会使用默认值即一个空字符串;
- 例如,在一个分布式事务中有多个数据库节点,每个节点上的操作可以看作事务的一个分支,bqual 就可以用来区分和标识这些不同的分支,以便更精确地管理事务在各个节点上的执行情况;
formatID(格式标识符):
- 是一个数字,用于标记gtrid和bqual值的格式,是一个正整数,最小为0,默认值是1 ;
- 它主要用于在不同的系统或数据库之间进行交互时,明确全局事务标识符和分支限定符的格式规则,以确保各方能够正确解析和处理事务标识信息。
使用XA事务时的注意事项
无法自动提交:与本地事务在满足一定条件下可以自动提交不同,XA事务需要开发者显式地调用提交指令(如
XA COMMIT) 。这就要求开发者在编写代码时,要准确把控事务提交的时机,避免因疏忽未提交事务而导致数据不一致等问题。例如在编写一个涉及多个数据库操作的业务逻辑时,开发者需要在所有操作都成功执行后,手动调用提交语句来完成事务,否则事务会一直处于未提交状态;效率低下:XA事务执行效率远低于本地事务,通常耗时能达到本地事务的10倍。这是因为在XA事务中,全局事务的状态都需要持久化,涉及到多个数据库节点之间的协调和通信,比如在两阶段提交过程中,准备阶段各个节点要记录事务状态等信息,提交阶段又需要进行多次确认和交互,这些额外的操作增加了系统开销,降低了事务处理的速度。这就意味着在对性能要求极高的场景中,使用XA事务可能并不合适,需要谨慎评估;
故障隔离困难:在XA事务提交前如果出现故障(如某个数据库节点宕机、网络中断等),很难将问题隔离开 。由于XA事务涉及多个数据库节点的协同工作,一个节点出现故障可能会影响到整个事务的执行,而且故障排查和恢复相对复杂。例如在一个跨地域的分布式数据库系统中,如果某个地区的数据库节点在XA事务准备阶段出现故障,不仅要处理该节点自身的数据恢复问题,还要协调其他节点来处理事务状态,以保证整个系统的数据一致性。
3.4 如何在 ShardingSphere-Proxy 中使用其他事务管理器?
ShardingSphere-Proxy 支持多种分布式事务管理器(如 Atomikos、Narayana、Bitronix)。默认集成的是 Atomikos,若要改用其它两种事务管理器,需手动配置;
具体操作(以 Narayana 为例)
添加 Narayana 的依赖包:
- 将 Narayana 事务集成的 Jar 包(如
shardingsphere-transaction-xa-narayana-5.2.1.jar),放到 ShardingSphere-Proxy 的lib目录下; - 该 Jar 包可通过 Maven 依赖下载(需要在项目的 Maven 配置中引入对应依赖,构建后获取 Jar 包);
- 将 Narayana 事务集成的 Jar 包(如
在
server.yaml的rules部分,将事务的providerType配置为Narayana。配置示例:rules: - !TRANSACTION defaultType: XA providerType: Narayana
注意事项:ShardingSphere 版本更新快,部分依赖可能未及时维护,存在组件版本冲突的风险。使用前需确认依赖包与 ShardingSphere-Proxy 版本的兼容性。
4 ShardingSphere-Proxy 集群化部署
4.1 ShardingSphere-Proxy 的运行模式
在
server.yaml文件中,有一段被注释的mode配置。这段配置的作用是指定 ShardingSphere 的运行模式,决定 ShardingSphere 如何管理复杂的配置信息:#mode: # type: Cluster # repository: # type: ZooKeeper # props: # namespace: governance_ds # server-lists: localhost:2181 # retryIntervalMilliseconds: 500 # timeToLiveSeconds: 60 # maxRetries: 3 # operationTimeoutMilliseconds: 500ShardingSphere 支持 Standalone(独立模式) 和 Cluster(集群模式) 两种运行模式,核心差异如下:
Standalone(独立模式)
ShardingSphere 不需要考虑其他实例的影响,直接在内存中管理核心配置规则;
是 ShardingSphere 默认的运行模式,配置简单,无需依赖第三方组件。
适用场景:小型项目,或对性能要求较高的场景(因为没有额外的配置同步开销)。通常配合 ShardingJDBC 使用(ShardingJDBC 是客户端分库分表,更侧重性能);
Cluster(集群模式)
ShardingSphere 不仅要管理自身配置,还要与集群中其他实例同步配置规则。因此需要引入第三方配置中心(如 Zookeeper、etcd、Nacos 等)来实现配置同步;
推荐的配置中心:在分库分表场景下,配置信息变动少、访问频率低,因此基于 CP 架构的 Zookeeper 最推荐(CP 架构保证数据一致性,适合配置这类强一致需求的场景);
优先级:如果应用本地和 Zookeeper 都有配置,ShardingSphere 以 Zookeeper 中的配置为准(保证集群配置统一);
适用场景:大规模集群环境,需要多实例协同工作,通常配合 ShardingSphere-Proxy 使用;
模式选择建议
Standalone:小型项目、性能敏感场景 → 配合 ShardingJDBC;
Cluster:大规模集群环境 → 配合 ShardingSphere-Proxy,且推荐用 Zookeeper 作为配置中心。
4.2 使用 Zookeeper 进行集群部署
接下来基于 Zookeeper 部署一下 ShardingSphere-Proxy 集群;
首先在本地部署一个 Zookeeper,然后将
server.yaml中的mode部分解除注释:# ShardingSphere 运行模式配置 mode: # 运行模式类型:Cluster 表示集群模式(支持多个Proxy实例组成集群) type: Cluster # 集群元数据存储仓库配置 repository: # 仓库类型:ZooKeeper(使用ZooKeeper作为分布式协调服务) type: ZooKeeper # ZooKeeper连接配置属性 props: # ZooKeeper命名空间:用于在ZooKeeper中隔离不同环境的配置 namespace: governance_ds # ZooKeeper服务器地址列表:支持多个服务器地址,用逗号分隔 server-lists: 192.168.65.212:2181 # 重试间隔时间(毫秒):连接失败后重试的等待时间 retryIntervalMilliseconds: 500 # 节点存活时间(秒):在ZooKeeper中创建的临时节点的存活时间 timeToLiveSeconds: 60 # 最大重试次数:连接ZooKeeper失败时的最大重试次数 maxRetries: 3 # 操作超时时间(毫秒):ZooKeeper操作(如创建、读取节点)的超时时间 operationTimeoutMilliseconds: 500启动 ShardingSphere-Proxy 服务,在 Zookeeper 注册中心可以看到 ShardingSphere 集群模式下的节点结构如下:
# ShardingSphere 集群模式下的 ZooKeeper 节点结构详解 # 根命名空间(用于环境隔离,避免不同环境配置相互干扰) namespace: governance_ds # 全局配置节点 ├── rules # 存储全局规则配置(如分片规则、加密规则等) ├── props # 存储全局属性配置(如SQL显示开关、执行模式等) # 元数据管理节点 ├── metadata # 元数据配置根目录 │ ├── ${databaseName } # 逻辑数据库名称(如:sharding_db) │ │ ├── schemas # 逻辑Schema列表 │ │ │ ├── ${schemaName } # 逻辑Schema名称 │ │ │ │ ├── tables # 表结构配置 │ │ │ │ │ ├── ${tableName } # 具体表的结构定义 │ │ │ │ │ └── ... # 其他表 │ │ │ │ └── views # 视图结构配置 │ │ │ │ ├── ${viewName } # 具体视图的定义 │ │ │ │ └── ... # 其他视图 │ │ │ └── ... # 其他Schema │ │ └── versions # 元数据版本管理 │ │ ├── ${versionNumber } # 具体版本号(如:v1, v2) │ │ │ ├── dataSources # 该版本的数据源配置 │ │ │ └── rules # 该版本的规则配置 │ │ ├── active_version # 当前激活的元数据版本号 │ │ └── ... # 其他版本 # 计算节点管理(Proxy和JDBC实例管理) ├── nodes │ ├── compute_nodes # 计算节点管理根目录 │ │ ├── online # 在线实例列表 │ │ │ ├── proxy # Proxy模式实例 │ │ │ │ ├── UUID # 每个Proxy实例的唯一标识(如:生成的实际UUID) │ │ │ │ └── ... # 其他Proxy实例 │ │ │ └── jdbc # JDBC模式实例 │ │ │ ├── UUID # 每个JDBC实例的唯一标识 │ │ │ └── ... # 其他JDBC实例 │ │ ├── status # 实例状态信息 │ │ │ ├── UUID # 具体实例的状态数据 │ │ │ └── ... # 其他实例状态 │ │ ├── worker_id # 工作节点ID分配 │ │ │ ├── UUID # 实例分配的工作ID │ │ │ └── ... # 其他实例的工作ID │ │ ├── process_trigger # 进程触发管理 │ │ │ ├── process_list_id:UUID # 进程列表与实例的关联 │ │ │ └── ... # 其他进程触发信息 │ │ └── labels # 实例标签管理 │ │ ├── UUID # 具体实例的标签配置 │ │ └── ... # 其他实例标签 # 存储节点管理(实际数据源管理) │ └── storage_nodes # 存储节点管理根目录 │ ├── ${databaseName.groupName.ds } # 数据源节点命名格式:逻辑库名.组名.数据源名 │ └── ${databaseName.groupName.ds } # 另一个数据源节点server.yaml中的rules部分同2.1 部署 ShardingSphere-Proxy;分库分表配置同
2.2 常用的分库分表配置策略。
4.3 统一 JDBC 和 Proxy 配置信息
- ShardingSphere-JDBC 也能像 ShardingSphere-Proxy 一样,通过 Zookeeper 同步配置信息,从而实现两者配置的统一管理(减少配置分散,便于集群化维护)。
4.3.1 通过注册中心同步配置
在
application.properties中,删除之前 ShardingSphere-JDBC 相关的分库分表规则等配置,只配置Zookeeper 的连接和集群模式。示例配置:# 指定运行模式为“集群模式(Cluster)” spring.shardingsphere.mode.type=Cluster # 指定配置中心类型为 Zookeeper spring.shardingsphere.mode.repository.type=Zookeeper # Zookeeper 的命名空间(用于隔离不同配置,自定义即可) spring.shardingsphere.mode.repository.props.namespace=governance_ds # Zookeeper 的地址和端口 spring.shardingsphere.mode.repository.props.server-lists=localhost:2181 # 重试间隔(毫秒) spring.shardingsphere.mode.repository.props.retryIntervalMilliseconds=600 # 存活时间(秒) spring.shardingsphere.mode.repository.props.timeToLiveSeconds=60 # 最大重试次数 spring.shardingsphere.mode.repository.props.maxRetries=3 # 操作超时时间(毫秒) spring.shardingsphere.mode.repository.props.operationTimeoutMilliseconds=500配置完成后,可继续验证对表(如
course表)的分库分表操作,此时 ShardingSphere-JDBC 会从 Zookeeper 中拉取配置信息来执行分库分表逻辑;注意:
- 如果在 ShardingSphere-JDBC 中读取配置中心(Zookeeper)的配置,需要用
spring.shardingsphere.database.name指定对应的虚拟库; - 若不配置该参数,默认值为
logic_db; - 这个虚拟库是 ShardingSphere 中逻辑上的数据库概念,用于统一管理分库分表后的逻辑结构。
- 如果在 ShardingSphere-JDBC 中读取配置中心(Zookeeper)的配置,需要用
4.3.2 使用ShardingSphere-Proxy提供的JDBC驱动读取配置文件
ShardingSphere 过去是通过兼容 MySQL 或 PostgreSQL 服务的方式,提供分库分表功能:
应用端需要用 MySQL/PostgreSQL 的 JDBC 驱动,去访问 ShardingSphere 封装的数据源(
ShardingSphereDataSource);这种方式相当于模拟成 MySQL/PostgreSQL 数据库,让应用无感知地使用分库分表能力,但依赖的是第三方数据库的 JDBC 驱动;
在当前版本中,ShardingSphere 直接提供了自己的 JDBC 驱动:
这意味着应用可以不再依赖 MySQL/PostgreSQL 的 JDBC 驱动,直接用 ShardingSphere 专属的驱动来连接和操作数据;
优势是更原生、更直接地支持 ShardingSphere 的特性(分库分表、分布式事务等),减少对第三方驱动的依赖,也能更灵活地扩展功能;
比如在 ShardingSphere-JDBC 中,可在类路径(classpath)下增加
config.yaml文件,将之前 ShardingSphere-Proxy中的关键配置整合到这个文件中。这样 ShardingSphere-JDBC 就能通过自身的 JDBC 驱动,读取config.yaml里的配置(分库分表规则、数据源等),实现和 ShardingSphere-Proxy 类似的分库分表逻辑:rules: - !AUTHORITY users: - root@%:root - sharding@:sharding provider: type: ALL_PERMITTED - !TRANSACTION defaultType: XA providerType: Atomikos - !SQL_PARSER sqlCommentParseEnabled: true sqlStatementCache: initialCapacity: 2000 maximumSize: 65535 parseTreeCache: initialCapacity: 128 maximumSize: 1024 - !SHARDING tables: course: actualDataNodes: m${0..1 }.course_${1..2 } databaseStrategy: standard: shardingColumn: cid shardingAlgorithmName: course_db_alg tableStrategy: standard: shardingColumn: cid shardingAlgorithmName: course_tbl_alg keyGenerateStrategy: column: cid keyGeneratorName: alg_snowflake shardingAlgorithms: course_db_alg: type: MOD props: sharding-count: 2 course_tbl_alg: type: INLINE props: algorithm-expression: course_$-> {cid%2+1 } keyGenerators: alg_snowflake: type: SNOWFLAKE props: max-connections-size-per-query: 1 kernel-executor-size: 16 proxy-frontend-flush-threshold: 128 proxy-hint-enabled: false sql-show: false check-table-metadata-enabled: false proxy-backend-query-fetch-size: -1 proxy-frontend-executor-size: 0 proxy-backend-executor-suitable: OLAP proxy-frontend-max-connections: 0 sql-federation-type: NONE proxy-backend-driver-type: JDBC proxy-mysql-default-version: 8.0.20 proxy-default-port: 3307 proxy-netty-backlog: 1024 databaseName: sharding_db dataSources: m0: dataSourceClassName: com.zaxxer.hikari.HikariDataSource url: jdbc:mysql://127.0.0.1:3306/coursedb?serverTimezone=UTC&useSSL=false username: root password: root connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 minPoolSize: 1 m1: dataSourceClassName: com.zaxxer.hikari.HikariDataSource url: jdbc:mysql://127.0.0.1:3306/coursedb2?serverTimezone=UTC&useSSL=false username: root password: root connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 minPoolSize: 1然后,可以直接用 JDBC 的方式访问带有分库分表的虚拟库:
public class ShardingJDBCDriverTest { @Test public void test() throws ClassNotFoundException, SQLException { // 定义ShardingSphere JDBC驱动类全限定名 // 这是ShardingSphere提供的专用JDBC驱动,用于拦截和路由SQL请求 String jdbcDriver = "org.apache.shardingsphere.driver.ShardingSphereDriver"; // JDBC连接URL,指定使用ShardingSphere驱动和配置文件路径 // classpath:config.yaml 表示配置文件位于类路径下的config.yaml文件 String jdbcUrl = "jdbc:shardingsphere:classpath:config.yaml"; // 要执行的SQL查询语句 // 这里查询的是逻辑数据库sharding_db中的course表 // ShardingSphere会根据配置将查询路由到实际的物理表 String sql = "select * from sharding_db.course"; // 加载ShardingSphere JDBC驱动类 // 这是使用JDBC驱动的标准方式,驱动会自动注册到DriverManager Class.forName(jdbcDriver); // 使用try-with-resources语句确保连接正确关闭 try(Connection connection = DriverManager.getConnection(jdbcUrl); ) { // 创建Statement对象用于执行SQL语句 Statement statement = connection.createStatement(); // 执行SQL查询并返回ResultSet结果集 // ShardingSphere会在此处拦截SQL,根据分片规则路由到正确的数据节点 ResultSet resultSet = statement.executeQuery(sql); // 遍历结果集,处理查询结果 while (resultSet.next()){ // 从结果集中获取cid字段的值并输出 // ShardingSphere会自动合并来自多个分片的结果 System.out.println("course cid= "+resultSet.getLong("cid")); } // try-with-resources会自动关闭statement和resultSet } // try-with-resources会自动关闭connection,释放数据库连接资源 } }官方的说明是 ShardingSphereDriver 读取
config.yaml时, 这个config.yaml配置信息与 ShardingSphere-Proxy 中的配置文件完全是相同的,甚至可以直接将 ShardingSphere-Proxy 中的配置文件拿过来用。但是从目前版本来看,还是有不少小问题的,静待后续版本跟踪吧;到这里,对于之前讲解过的 ShardingSphere 的混合架构,有没有更新的了解?
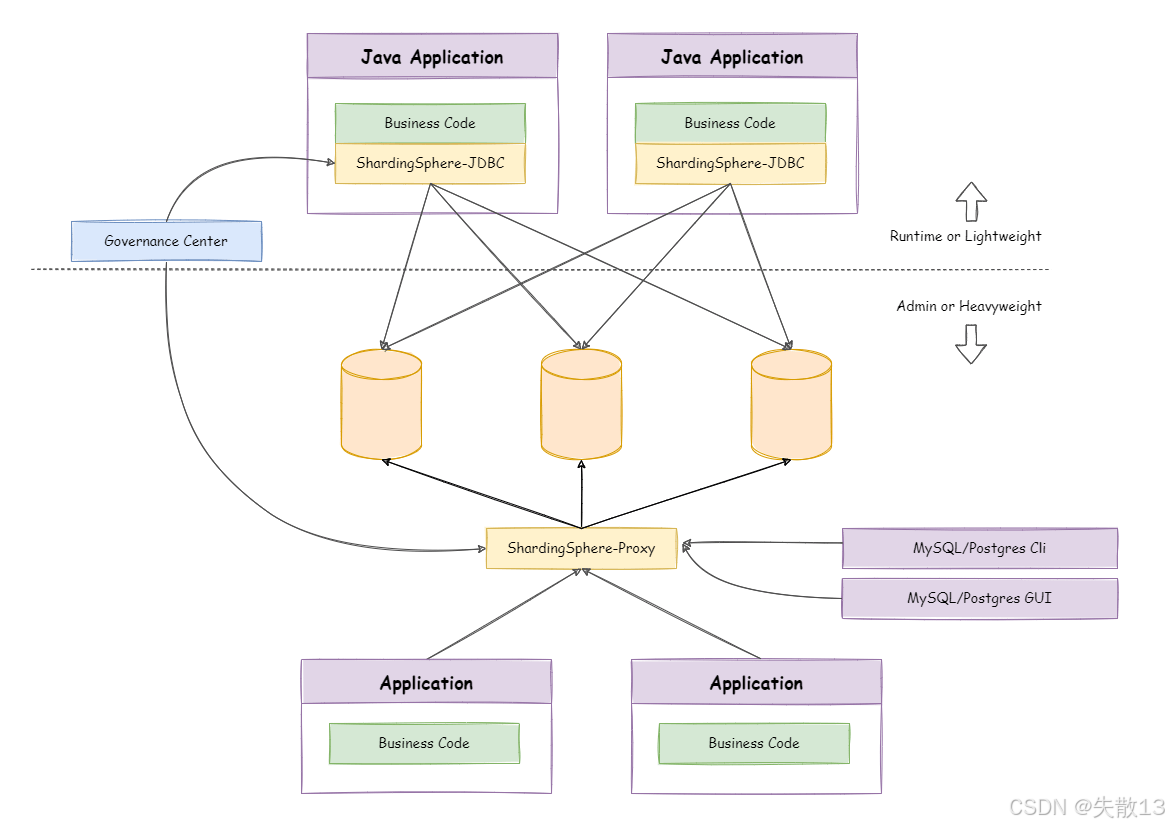
5 ShardingSphere-Proxy功能扩展
ShardingSphere-Proxy 支持通过 SPI(Service Provider Interface)机制 进行自定义扩展,只要将自定义的扩展功能(如自定义算法、策略等)按照 SPI 规范打成 Jar 包,放入 ShardingSphere-Proxy 的
lib目录,就能被 ShardingSphere-Proxy 加载并使用;以自定义主键生成器为例:
- 实现
KeyGeneratorAlgorithm接口,用于生成自定义格式的主键; - 生成主键时,结合当前时间戳(格式化为
yyyyMMddHHmmssSSS)和自增原子变量,保证主键的唯一性和有序性;
public class MyKeyGeneratorAlgorithm implements KeyGeneratorAlgorithm { private AtomicLong atom = new AtomicLong(0); private Properties props; @Override public Comparable< ?> generateKey() { LocalDateTime ldt = LocalDateTime.now(); // 格式化时间为 “年月日时分秒毫秒” 格式 String timestamp = DateTimeFormatter.ofPattern("yyyyMMddHHmmssSSS").format(ldt); // 结合自增数生成主键(时间戳 + 自增数) return Long.parseLong(timestamp + atom.incrementAndGet()); } @Override public Properties getProps() { return this.props; } @Override public String getType() { // 自定义算法的类型标识,配置时会用到 return "MYKEY"; } @Override public void init(Properties props) { this.props = props; } }- 实现
要将自定义类和对应的 SPI 文件打成 Jar 包,需在
pom.xml中配置maven-jar-plugin:- 指定要打包的自定义类(
com/your/package/algorithm/**)和 SPI 配置文件(META-INF/services/*),生成包含扩展功能的 Jar 包;
<build> <plugins> <!-- 将 SPI 扩展功能单独打成 Jar 包 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>3.2.0</version> <executions> <execution> <id>shardingJDBDemo</id> <phase>package</phase> <goals> <goal>jar</goal> </goals> <configuration> <classifier>spi-extention</classifier> <includes> <!-- 包含自定义算法的包路径 --> <include>com/your/package/algorithm/**</include> <!-- 包含 SPI 配置文件(META-INF/services/ 下的文件) --> <include>META-INF/services/*</include> </includes> </configuration> </execution> </executions> </plugin> </plugins> </build>- 指定要打包的自定义类(
将打包好的 Jar 包,放入 ShardingProxy 的
lib目录。之后在 ShardingProxy 的配置中,就可以像使用内置组件一样,引用这个自定义的主键生成算法(如配置keyGeneratorName: MYKEY)。
6 分库分表数据迁移方案
分库分表场景下,数据迁移面临两大难题:
海量数据迁移难度大:旧项目无分库分表,或需调整分片规则时,数据量庞大,迁移工程浩大;
业务无感知难度高:迁移过程中要保证业务正常运行,不能因迁移导致服务中断;
为平衡数据迁移和业务连续性(在数据转移的过程中,保证不影响业务正常进行),采用冷热数据分离迁移:
冷数据:
- 即历史存量数据(数据量大,无法一次性迁移);
- 策略:通过定时任务逐步迁移,减少对业务的瞬间压力;
热数据:
- 即业务实时产生的新数据;
- 策略:保证双写(同时写入旧库和新库),确保迁移过程中数据实时同步,业务不受影响;
基于 ShardingSphere 的迁移方案
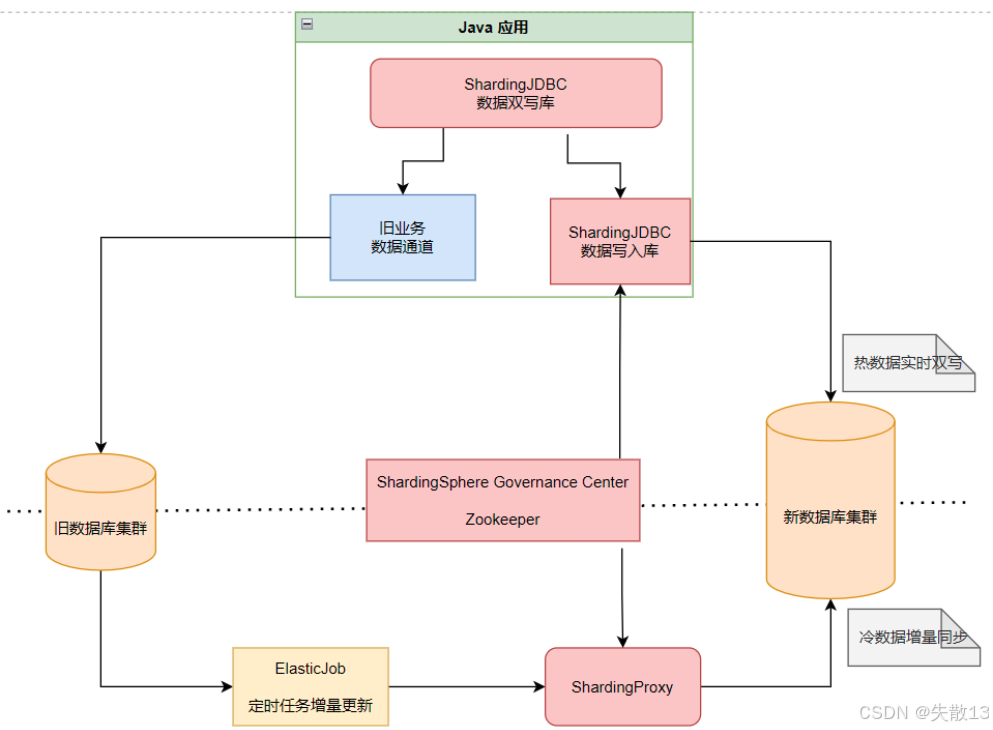
热数据双写(ShardingJDBC 数据双写库)
核心逻辑:用
ShardingSphereDataSource替换旧的DataSource,配置双写规则(核心业务表同时写入旧库和新库);实现方式:在 ShardingJDBC 双写库中,针对需迁移的核心表配置分片规则,通过定制分片算法实现一份数据写两份库;
新库分片写入(ShardingJDBC 数据写入库)
核心逻辑:针对新数据库集群,配置专门的 ShardingJDBC 写入库,完整实现新的分片规则(即分库分表的最终逻辑);
关联方式:将这个写入库配置到之前的双写库中,保证新数据按新规则写入新库;
冷数据增量迁移(定时任务 + ShardingProxy)
冷数据特点:量大、迁移慢,需分批增量迁移;
实现方式:
- 用
ElasticJob等定时任务框架,分批读取旧库冷数据,按新分片规则写入新库; - 借助
ShardingProxy服务,简化新库的分片逻辑(定时任务只需从旧库读、往新库写,分片规则由 ShardingProxy 统一管理); - 规则同步:通过
ShardingSphere Governance Center(如 Zookeeper),保证 ShardingProxy 和 ShardingJDBC 写入库的分片规则一致;
- 用
迁移完成后切换
核心逻辑:冷数据迁移完成后,删除双写库和旧库依赖,只保留 ShardingJDBC 写入库(新库的分片逻辑);
业务影响:应用层只需访问一个
DataSource(底层由 ShardingSphere 切换为新库逻辑),业务代码几乎无需修改;
注意:迁移过程中,需梳理业务 SQL,确保 SQL 符合 ShardingSphere(尤其是 ShardingSphere-JDBC)的支持范围,避免使用不兼容的 SQL 语法导致迁移或业务异常。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号