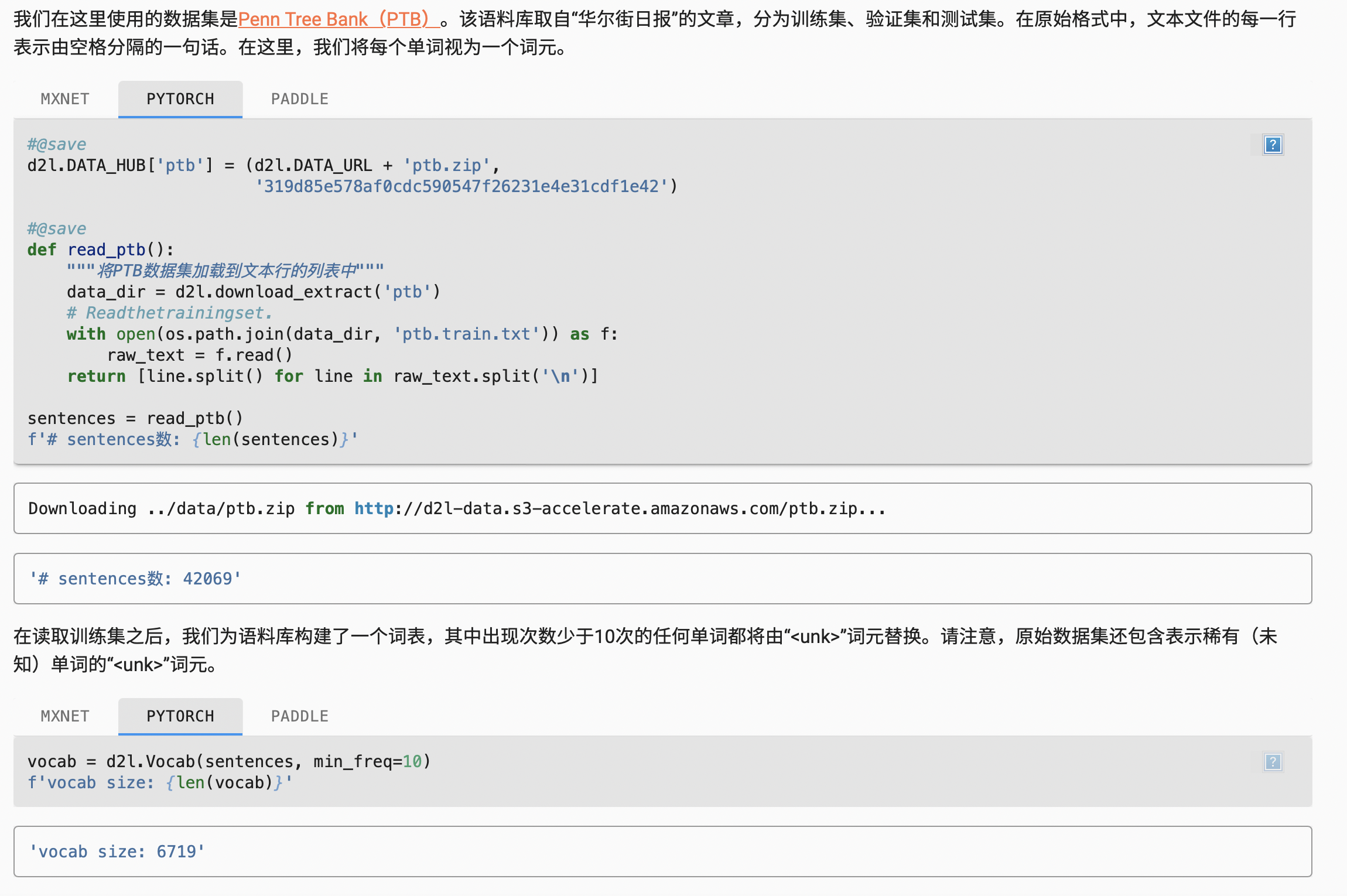
自然语言处理预训练——用于预训练词嵌入的数据集
读取数据集
下采样

提取中心词和上下文词
下面的get_centers_and_contexts函数从corpus中提取所有中心词及其上下文词。它随机采样1到max_window_size之间的整数作为上下文窗口。对于任一中心词,与其距离不超过采样上下文窗口大小的词为其上下文词。
#@save
def get_centers_and_contexts(corpus, max_window_size):
"""返回跳元模型中的中心词和上下文词"""
centers, contexts = [], []
for line in corpus:
# 要形成“中心词-上下文词”对,每个句子至少需要有2个词
if len(line) < 2:
continue
centers += line
for i in range(len(line)): # 上下文窗口中间i
window_size = random.randint(1, max_window_size)
indices = list(range(max(0, i - window_size),
min(len(line), i + 1 + window_size)))
# 从上下文词中排除中心词
indices.remove(i)
contexts.append([line[idx] for idx in indices])
return centers, contexts
小批量加载训练实例

整合代码(以PyTorch为例)
#@save
def load_data_ptb(batch_size, max_window_size, num_noise_words):
"""下载PTB数据集,然后将其加载到内存中"""
num_workers = d2l.get_dataloader_workers()
sentences = read_ptb()
vocab = d2l.Vocab(sentences, min_freq=10)
subsampled, counter = subsample(sentences, vocab)
corpus = [vocab[line] for line in subsampled]
all_centers, all_contexts = get_centers_and_contexts(
corpus, max_window_size)
all_negatives = get_negatives(
all_contexts, vocab, counter, num_noise_words)
class PTBDataset(torch.utils.data.Dataset):
def __init__(self, centers, contexts, negatives):
assert len(centers) == len(contexts) == len(negatives)
self.centers = centers
self.contexts = contexts
self.negatives = negatives
def __getitem__(self, index):
return (self.centers[index], self.contexts[index],
self.negatives[index])
def __len__(self):
return len(self.centers)
dataset = PTBDataset(all_centers, all_contexts, all_negatives)
data_iter = torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True,
collate_fn=batchify, num_workers=num_workers)
return data_iter, vocab
总结
-
高频词在训练中可能不是那么有用。我们可以对他们进行下采样,以便在训练中加快速度。
-
为了提高计算效率,我们以小批量方式加载样本。我们可以定义其他变量来区分填充标记和非填充标记,以及正例和负例。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号