机器学习——注意力汇聚:Nadaraya-Watson 核回归
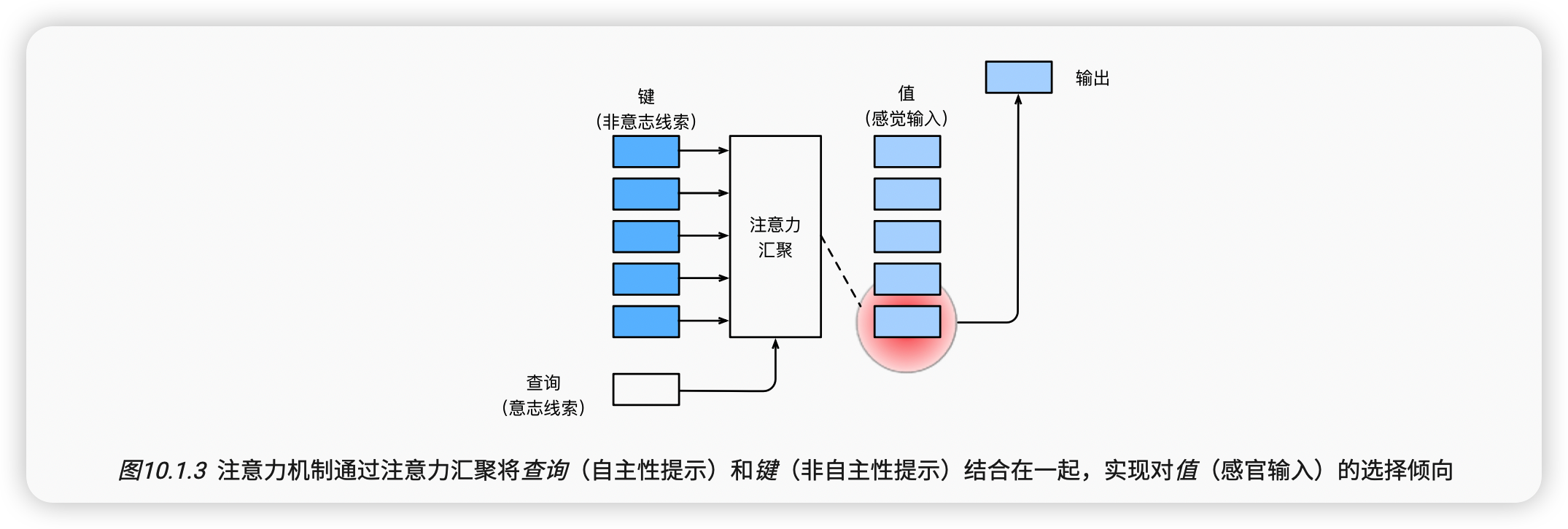
上节介绍了框架下的注意力机制的主要成分 图10.1.3: 查询(自主提示)和键(非自主提示)之间的交互形成了注意力汇聚; 注意力汇聚有选择地聚合了值(感官输入)以生成最终的输出。 本节将介绍注意力汇聚的更多细节, 以便从宏观上了解注意力机制在实践中的运作方式。 具体来说,1964年提出的Nadaraya-Watson核回归模型 是一个简单但完整的例子,可以用于演示具有注意力机制的机器学习。
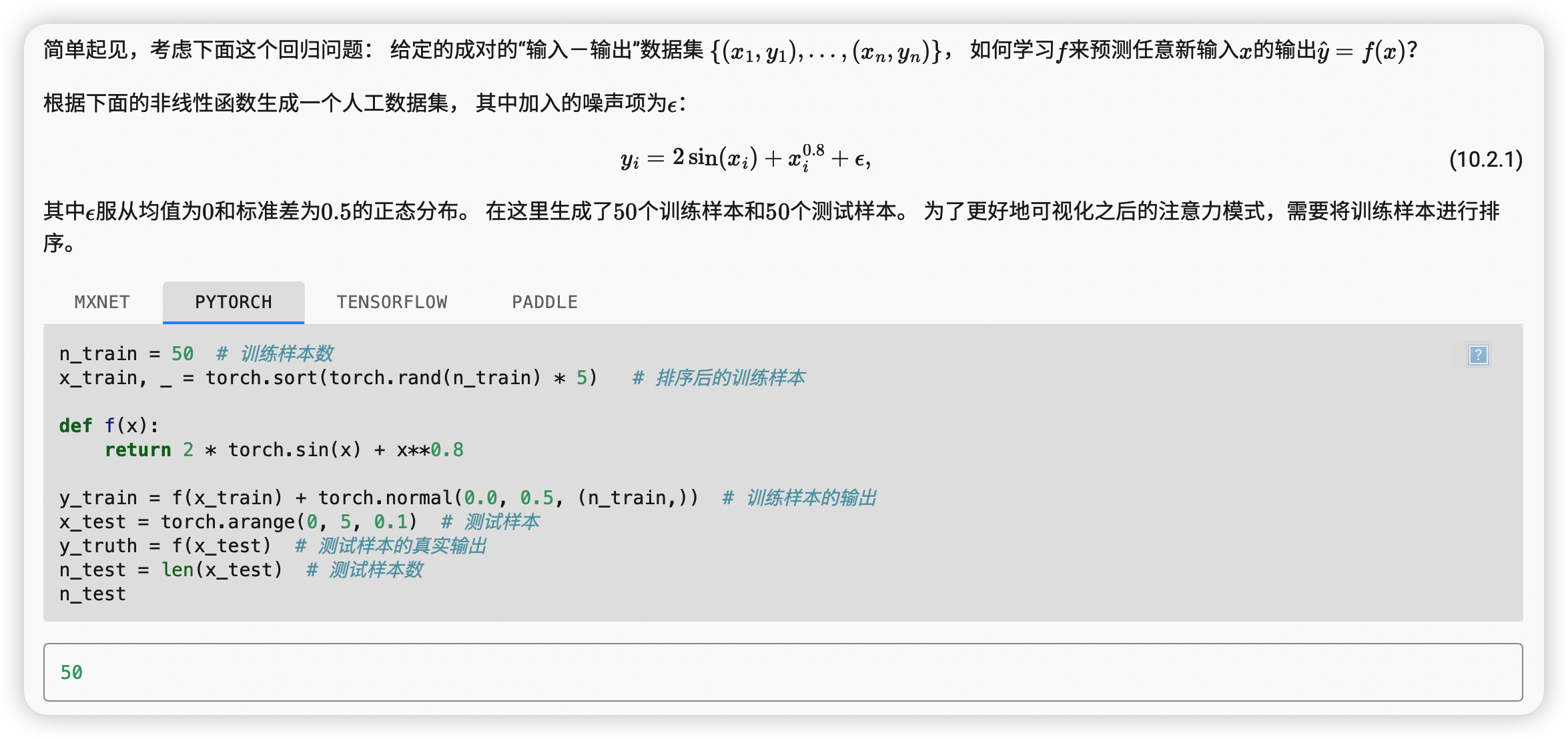
生成数据集

平均汇聚
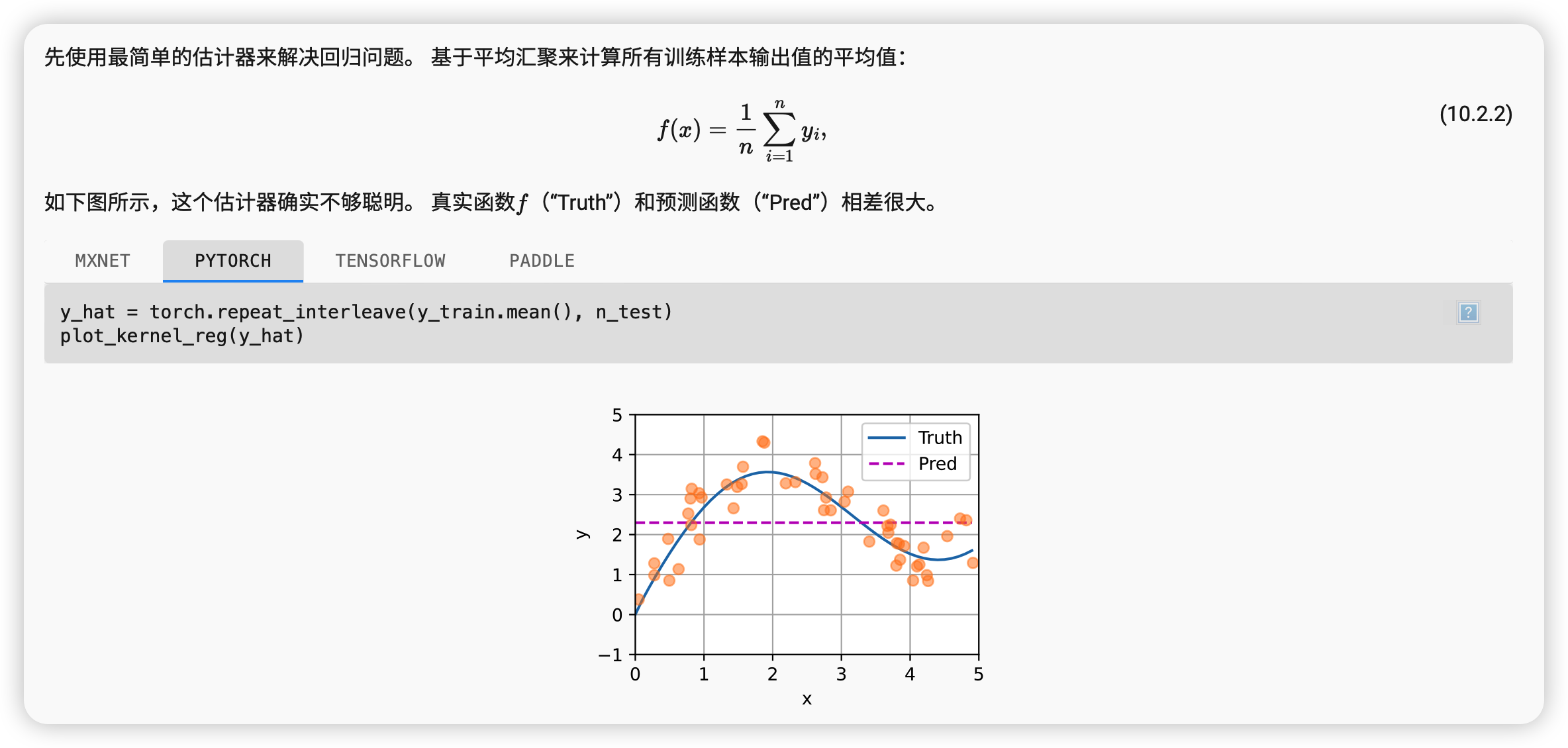
显然,平均汇聚忽略了输入xi。
非参数注意力汇聚

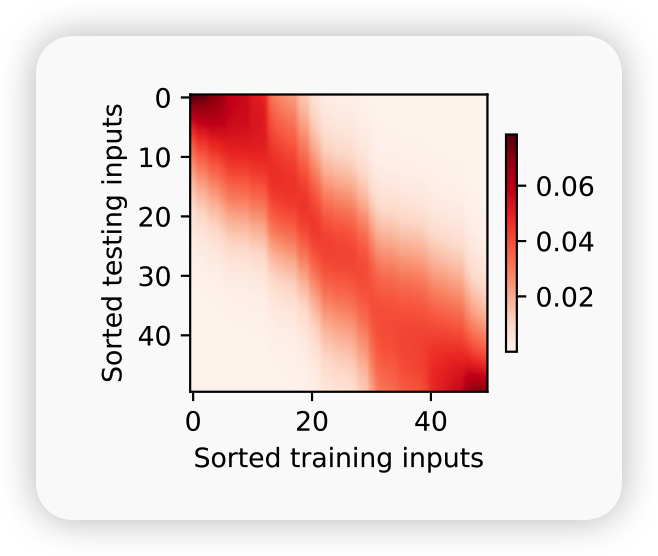
现在来观察注意力的权重。 这里测试数据的输入相当于查询,而训练数据的输入相当于键。 因为两个输入都是经过排序的,因此由观察可知“查询-键”对越接近, 注意力汇聚的注意力权重就越高。
带参数注意力汇聚

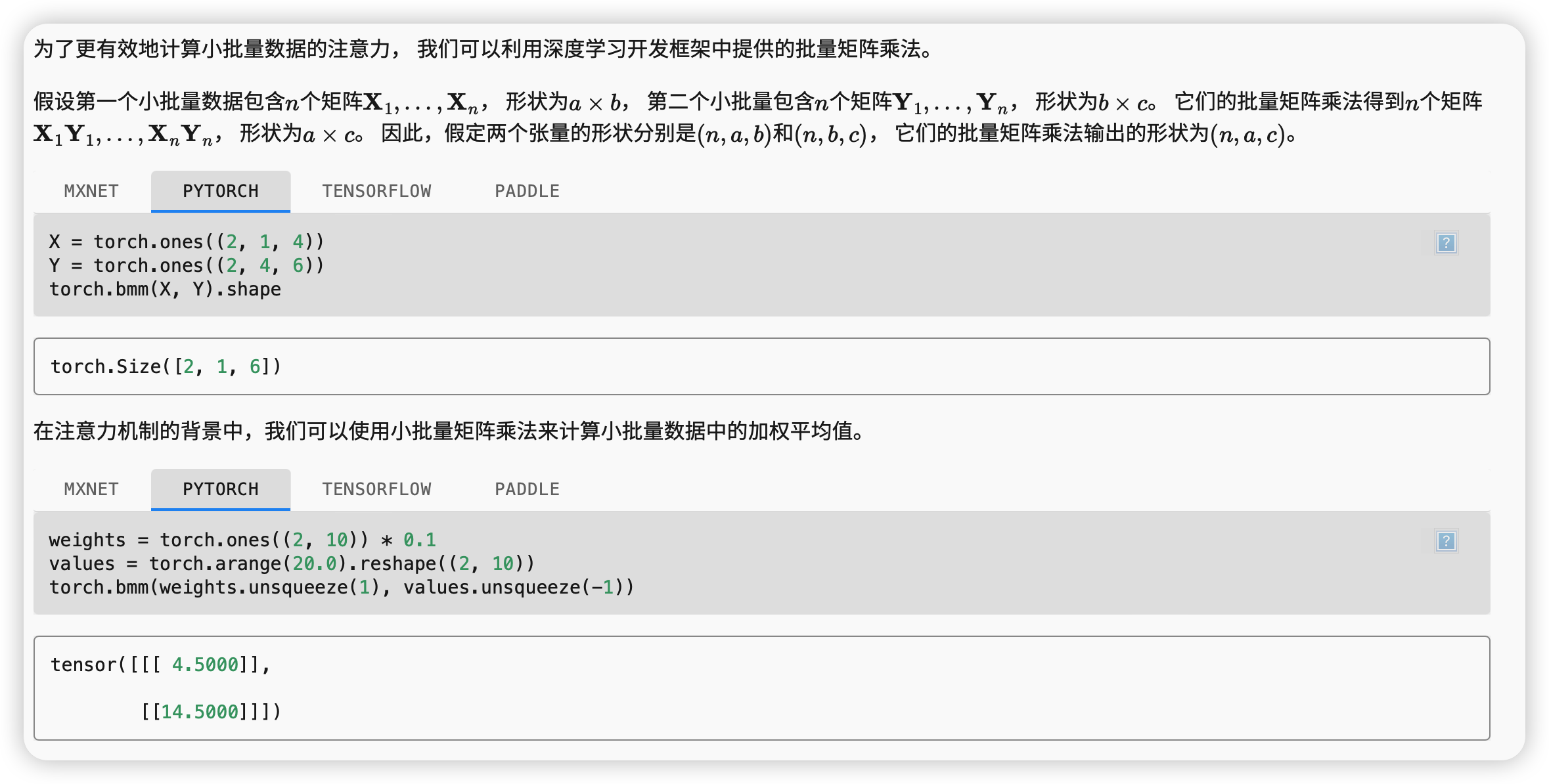
批量矩阵乘法
定义模型
基于 (10.2.7)中的 带参数的注意力汇聚,使用小批量矩阵乘法, 定义Nadaraya-Watson核回归的带参数版本为:
class NWKernelRegression(nn.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand((1,), requires_grad=True))
def forward(self, queries, keys, values):
# queries和attention_weights的形状为(查询个数,“键-值”对个数)
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
self.attention_weights = nn.functional.softmax(
-((queries - keys) * self.w)**2 / 2, dim=1)
# values的形状为(查询个数,“键-值”对个数)
return torch.bmm(self.attention_weights.unsqueeze(1),
values.unsqueeze(-1)).reshape(-1)
总结
-
Nadaraya-Watson核回归是具有注意力机制的机器学习范例。
-
Nadaraya-Watson核回归的注意力汇聚是对训练数据中输出的加权平均。从注意力的角度来看,分配给每个值的注意力权重取决于将值所对应的键和查询作为输入的函数。
-
注意力汇聚可以分为非参数型和带参数型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号