第二次结对作业
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE1/homework/11250 |
|---|---|
| 作业目标 | 爬取云班课堂经验值,完成经验值排序,算出平均经验值,最低经验值,最高经验值 |
| 作业源代码 | https://gitee.com/ye-dehui/pair |
| 队员1 | 211806357 |
| 队员2 | 211806401 |
1.结对的总结!
叶:
通过上一次的合作,我们已经有了一定的默契,感觉这次完成作业的效率比上次更高效,更迅速,意见想法也基本吻合,没有太大的偏差!并且我对网络爬取数据更加掌握了,熟悉了其操作的思路及流程!编写代码上也更加流畅,对之前对数组的越界,正则表达式一些不熟练的地方也完全掌握!我的伙伴宋也很棒,他的细心,善于发现漏洞,让我们非常快速的找到代码上的缺点,然后一起攻克它!还能快速找到解决问题的方法。我感觉我和他的默契度在不断的上升!
宋:
又一次的结对,让我收获良多。首先对代码的巩固以及提高都有很大的帮助!我的代码基础相对我的伙伴比较薄弱,通过这次作业,我们的互相指出不足,尤其是我,这让我受益匪浅!对爬取网络数据的知识更加了解,并且回顾了之前不太懂的地方,来弄懂它,弄明白他!我对我的伙伴叶是非常的满意,很有耐心,对自己不懂得地方,他会来帮助我,来给我讲解!我认为他的自主学习能力是一级棒的!很是善于高效的解决不明白的问题!对编程也具有很大的热情!是一个积极向上的好伙伴!

2.编码总结
| 代码行数 | 312 |
|---|---|
| 需求分析时间 | 5min |
| 编码时间 | 5h |
3.思路分析及编码过程
第一步:
.建立主测试类、学生类、连接网页专用的network。
.学生类应该包括有参和无参构造方法,基本的get/set方法。

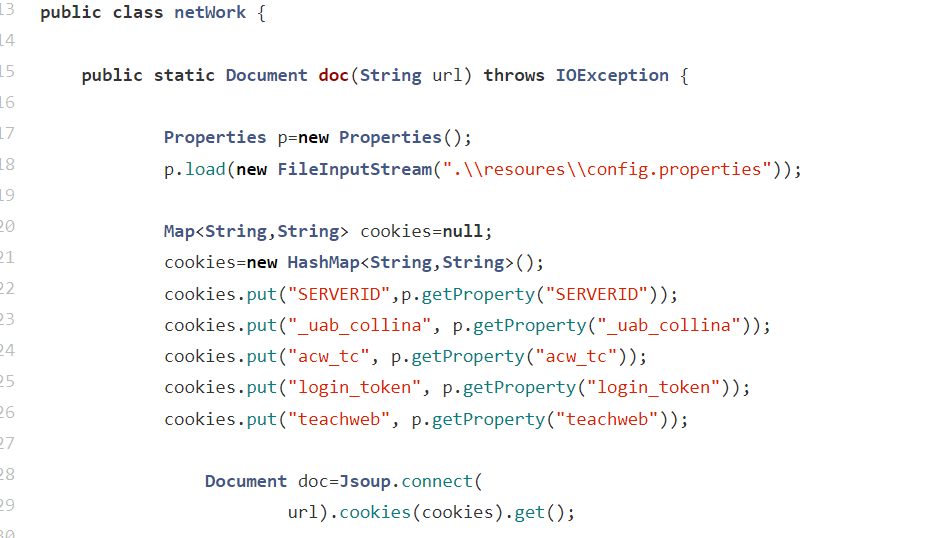
.netWork类需要相关配置文件config.properties以获取用班课在浏览器中的URL以及cookies。

第二步:
.即可获取我网页中HTML的内容了,通过Document类中的方法,Document类中的方法其实就是js 中的DOM。
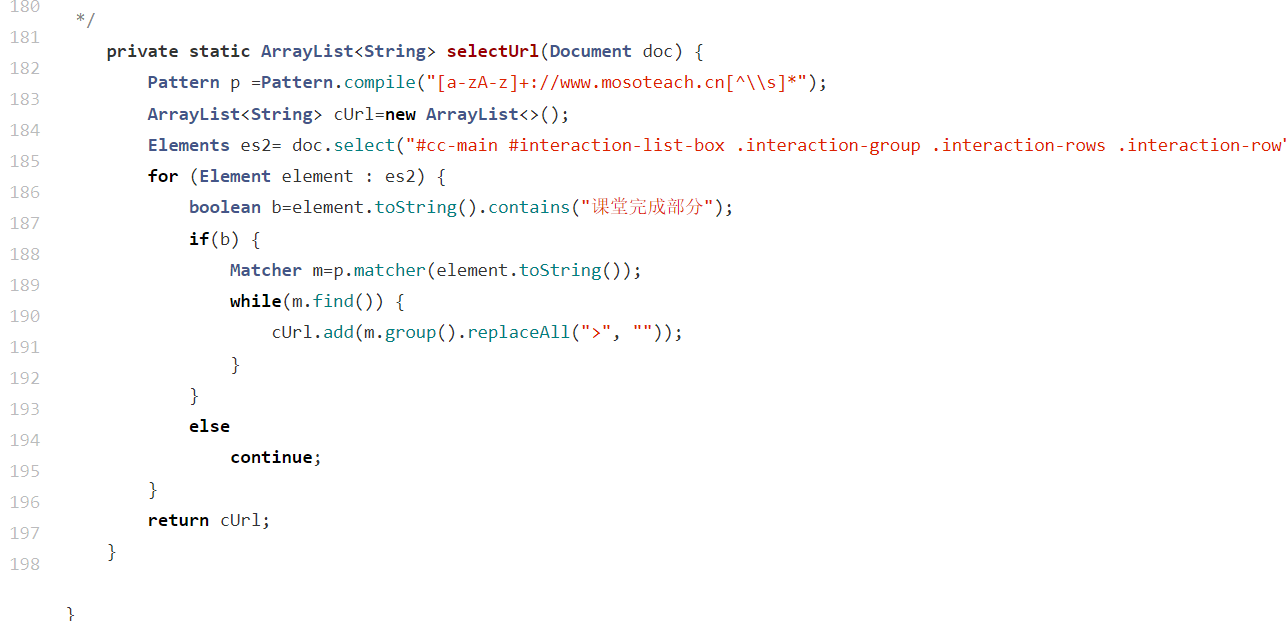
.接下来就是要得到自己想要的网页内容,通过正则表达式将网页中的内容再分割,最终是要得到活动名为课堂完成部分的URL,将所需的URL添加入名为cURL的ArrayList集合中。
第三步:
.通过上一步已得到14个URL

.通过foreach遍历为每一个网页的信息进行整合即重复第二步,但是这次要获取到学生姓名学号以及经验值,其中还有创建学生对象,将14个网页信息重复遍历将所有创建的学生对象添加到学生的集合中

第四步:
.将拿到的学生类用hashmap去重用List的comparator排序

第五步:
.将排序好的集合元素用bufferedwrite及IO流进行输出到文本文件中

完成:
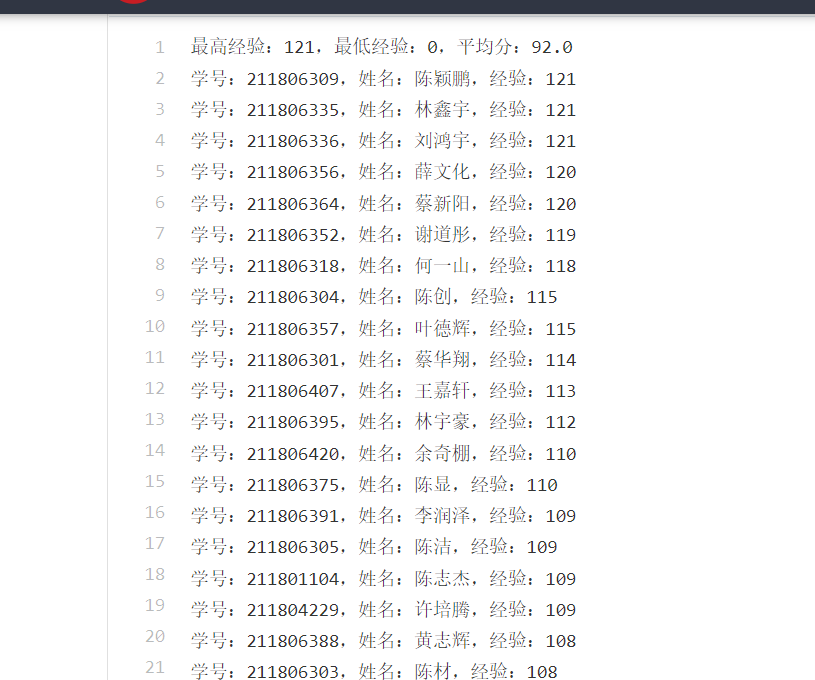
4.编程过程中的难点
正则表达式,数组的越界用易出错,感觉经验还是太少了,掌控不太好,多联系下理解就更深了!
5.参考文献
. https://blog.csdn.net/xHibiki/article/details/82938480


 浙公网安备 33010602011771号
浙公网安备 33010602011771号