


Python基础篇(格式化输出,运算符,编码):
格式化输出:
格式:print ( " 内容%s" %(变量))
字符类型:
%s 替换字符串
%d 替换整体数字
%f替换浮点型
------------ info of Alex Li ----------- ------------ info of %s -----------
Name : Alex Li Name : %s
Age : 22 Age :%d
job : Teacher job : %s
Hobbie: girl Hobbie: %s
------------- end ----------------- ------------- end ----------------- ame = input("Name:")age = input("Age:"job = input("Job:")hobby = input("Hobbie:")
info = '''
------------ info of %s ----------- #这里的每个%s就是一个占位符,本行的代表 后面拓号里的 name
Name : %s #代表 name
Age : %s #代表 age
job : %s #代表 job
Hobbie: %s #代表 hobbie
------------- end -----------------
''' % (name, name, age, job, hobbie) # 这行的 % 号就是 把前面的字符串 与拓号 后面的 变量 关联起来
print(info)
%s就是代表字符串占位符,除此之外%d是数字的占位符,如果你把age换成%d,也就是代表你只可以使用数字来表示,这时对应的数据
必须是数字(int)类型,否则数据会报错.使用时需要进行类型转换int(str)或者str(int)
我叫xxx, 今年xx岁了,我们已经学习了2%的python基础了 这里的问题出在哪里呢? 没错2%, 在字符串中如果使用了%s这样的占位符.
那么所有的%都将变成占位符. 我们的2%也变成了占 位符. 而"%的"是不存在的, 这里我们需要使用%%来表示字符串中的%.
注意: 如果你的字符串中没有使用过%s,%d站位. 那么不需要考虑这么多. 该%就%.没毛病老铁.
print("我叫%s, 今年22岁了, 学习python2%%了" % '王尼玛')#有占位符
print("我叫王尼玛, 今年22岁, 已经凉凉了100%了") # 没有占位符
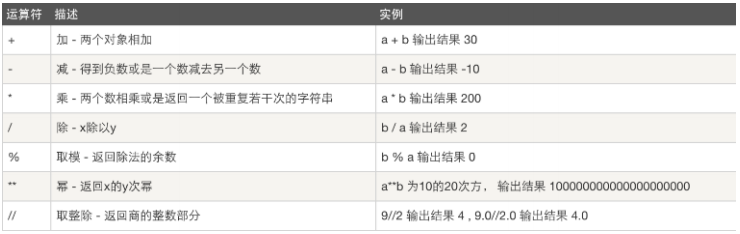
基本运算符
计算机可以进行的运算有很多种,可不知加减乘除这么简单,
运算的种类:
算数运算:
假设 a=10 b=20
![]()
比较运算:
假设a=10 b=20
![]()

逻辑运算:
![]()

针对逻辑运算的进一步研究:
1.在没有()的情况下not优先级高于and,and优先级高于or,既优先级关系为()-->not-->and--or,同一优先级从左往右算
()>not>and>or
1)、6 or 2 > 1 6
例子:
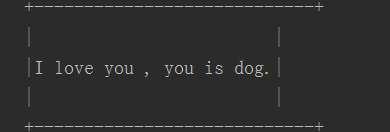
sentence = input("please sentence:") #输入句子 screen_width = 80 #输出屏幕宽度为80 text_width = len(sentence) #输出内容的宽度 box_width = text_width + 6 #句子两边的宽度 left_margin = (screen_width - box_width) // 2 print() print(" "* left_margin + "+" + "-" * int(box_width - 2) + "+") print(" "* left_margin + "|" + " " * text_width + "|") print(" "* left_margin + "|" + sentence + "|") print(" "* left_margin + "|" + " " * text_width + "|") print(" "* left_margin + "+" + "-" * int(box_width -2) + "+")
结果:
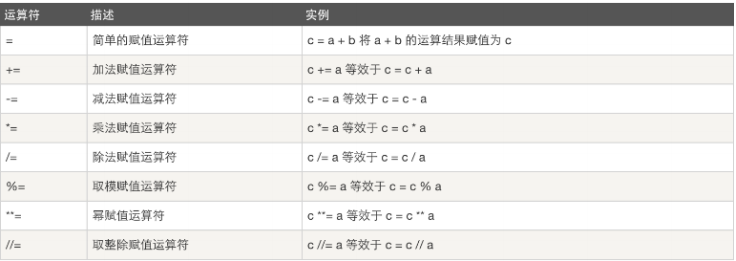
赋值运算:
假设 a=10 b=20
![]()
成员运算:
身份运算:
位运算:
编码问题
python2解释器在加载.py文件中的代码时,会对内容进行编码(默认ascill),而python3对内容进行编码的默认为utf-8
计算机:
早起计算机是美国发明的.普及率不高,一般只是在美国使用,所以最早的编码结构就是按照美国人的习惯来编码的.
对数字+字母+特殊符号一共也没有多少所以就形成了最早的编码ascill码.直到今天ascill依然深深的影响着我们
ascill是基于拉丁字母的一套编码系统,主要用于显示现代英语和其他欧语言,其最多只能使用8为表示(一个字节)既2**8 =256,
所以ascill码最多只能表示256个字符
随着计算机的发展. 以及普及率的提高. 流行到欧洲和亚洲. 这时ASCII码就不合适了. 比如: 中文汉字有几万个.
而 ASCII最多也就256个位置. 所以ASCII不行了. 怎么办呢? 这时, 不同的国家就提出了不同的编码用来适用于各自的语言环境.
比如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等. 这时各个国家都可以使用计算机了. GBK, 国标码占用2个字节.
对应ASCII码 GBK直接兼容. 因为计算机底层是用英文写的. 你不支持英文肯定不 行.
而英文已经使用了ASCII码. 所以GBK要兼容ASCII. 这里GBK国标码. 前面的ASCII码部分. 由于使用两个字节.
所以对于ASCII码而言. 前9位都是0
字母A:0100 0001 # ASCII 字母A:0000 0000 0100 0001 # 国标码
国标码的弊端: 只能中国用. 日本就垮了. 所以国标码不满足我们的使用. 这时提出了一个万国码Unicode.
unicode一开始设计是每个字符两个字节. 设计完了. 发现我大中国汉字依然无法进行编码.
只能进行扩充. 扩充 成32位也就是4个字节. 这回够了. 但是. 问题来了. 中国字9万多.
而unicode可以表示40多亿. 根本用不了. 太浪 费了. 于是乎, 就提出了新的UTF编码.可变长度编码 UTF-8: 每个字符最少占8位.
每个字符占用的字节数不定.根据文字内容进行具体编码. 比如. 英文. 就一个字节就 够了. 汉字占3个字节. 这时即满足了中文.
也满足了节约. 也是目前使用频率最高的一种编码 UTF-16: 每个字符最少占16位. GBK: 每个字符占2个字节, 16位
单位转换:
8bit = 1byte
1024byte = 1kb
1024kb = 1mb
1024mb = 1g
1024gb = 1t
1024gt = 1pt
1024pt = 1et
1024et = 1zt
1024zt = 1yt
1024yt = 1nt
1024nt = 1dt
常用到tb就够了
1.python2中默认使用的是ASCLL码,里边有英文,大写字母,小写字母,数字,一些特殊字符,没有中文.
8个01代码,8个bit,1个byte
2.GBK:中文国标码, 里边包含了ASCII编码和中文常用编码. 16个bit, 2个byte
3.UNICODE: 万国码, 里面包含了全世界所有国家文字的编码. 32个bit, 4个byte, 包含了 ASCII
4.UTF-8: 可变长度的万国码. 是unicode的一种实现. 最小字符占8位
1.英文: 8bit 1byte
2.欧洲⽂字:16bit 2byte
3.中⽂:24bit 3byte
综上, 除了ASCII码以外, 其他信息不能直接转换
在python3的内存中. 在程序运序阶段. 使用的是unicode编码. 因为unicode是万国码. 什么内容都可以进行显示
那么在数据传输和存储的时候由于unicode比较浪费空间和资源. 需要把 unicode转存成UTF-8或者GBK进⾏存储. 怎么转换呢.
在python中可以把文字信息进行编码. 编码之后的内容就可以进行传输了. 编码之后的数据是bytes类型的数据.其实啊.
还是原来的 数据只是经过编码之后表现形式发生了改变而已.
byte的表现形式:
1.英文 b'alex' 英文的表现形式和字符串没什么两样
2.中文 b'\xe4\xb8\xad' 这是一个汉字的UTF-8的bytes表现形式
字符串在传输时转化成bytes=> encode(字符集)来完成
s = "alex" print(s.encode("utf-8")) # 将字符串编码成UTF-8 print(s.encode("GBK")) # 将字符串编码成GBK 结果: b'alex' b'alex' s = "中" print(s.encode("UTF-8")) # 中文编码成UTF-8 print(s.encode("GBK")) # 中文编码成GBK 结果: b'\xe4\xb8\xad' b'\xd6\xd0'
记住: 英文编码之后的结果和源字符串一致. 中文编码之后的结果根据编码的不同. 编码结果 也不同. 我们能看到. 一个中文的UTF-8编码是3个字节.
一个GBK的中文编码是2个字节.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号