

爬取程序客栈数据,分许爬取数据并把数据可视化
一、主题式网络爬虫设计方案
1.主题式网络爬虫名称(“”程序客栈“”数据 网站:http://rank.chinaz.com/www.proginn.com)
2.主题式网络爬虫爬取的内容与数据特征分析
爬取网站的"关键字","整体指数","PC指数","移动指数","百度排名","收录量","网页标题"
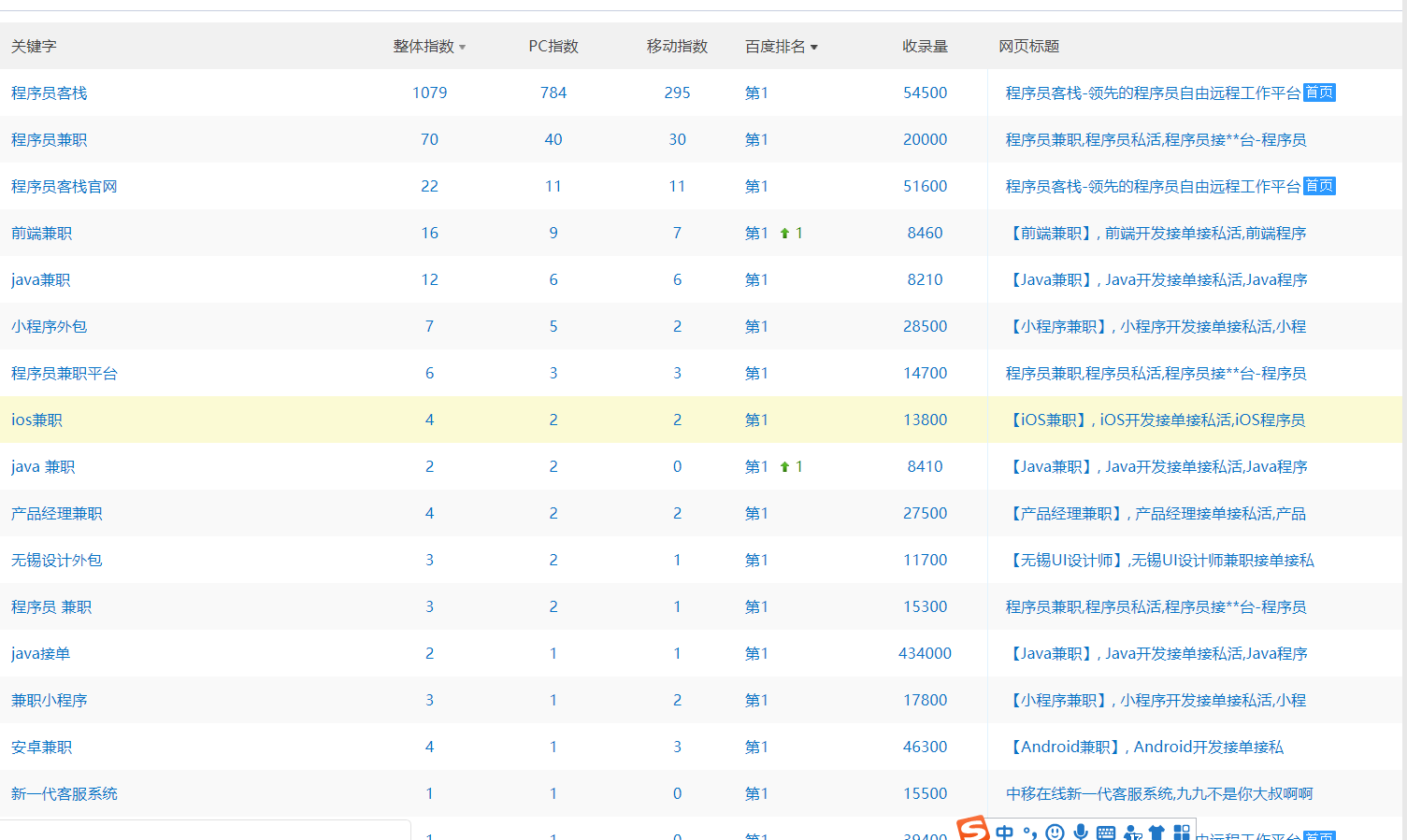
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
设计爬取网站的函数,创建程序框架,各函数之间需要有紧密联系,让程序看起来清楚明白。
多用try——except函数让程序出错是反馈信息,不会直接退出程序







二、主题页面的结构特征分析
1.主题页面的结构与特征分析
2.Htmls页面解析

3.节点(标签)查找方法与遍历方法
发现我们需要的数据都放在div下的class="w25-0 tl pl10 pr pbimg showt"
class="w8-0"
class="R-home-w"
的标签下,我们设计程序遍历它
三、网络爬虫程序设计
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from scipy.optimize import leastsq
import requests
from bs4 import BeautifulSoup
import pandas as pd
import csv
import jieba
import wordcloud
#分析网站结构
def analyticaldata(soup):
#显示完整网页结构
print(soup.prettify())
#查看网站所有的子节点
print("网站a的子节点:",soup.a.children)
#查看网站所有的父节点
print("网站a的父节点:",soup.a.parent)
#查看所有div下的信息
print("网站div下的信息:",soup.select("div"))
#查看所有标题信息
print("网站所有的标题:",soup.select("title"))
#数据采集
def Samplecollection(suop,keyword,title,all):
try:
for i in suop.find_all(class_="w25-0 tl pl10 pr pbimg showt"):
keyword.append(i.get_text().strip())
for k in suop.find_all(class_="w8-0"):
all.append(k.get_text().strip())
for g in suop.find_all(class_="R-home-w"):
title.append(g.get_text().strip())
except:
print("数据无法采集")
#把采集的信息保存到文本
def text(fi,keyword,title):
#遍历“关键字”和“网页标题”并写入列表中
for j in keyword:
fi.write("".join(j)+"\n")
for o in title:
fi.write("".join(o)+"\n")
#关闭文件
fi.close()
#把数据做成CSV文件
def csv_f(xls,s):
#把文件转换成二维表
data=np.array(s.T)
#把二维表写入CSV文件中
writer=csv.writer(xls)
for i in data:
writer.writerow(i)
#关闭文件
xls.close()
#数据清洗
def Datacleaning(clear):
#查看文件
print(clear)
#发现和网页标题、百度排名跟我们要分析的数据无关
try:
#把百度排名行删除
clear.drop(["百度排名"],axis=1,inplace=True)
#把网页标题行删除
clear.drop(["网页标题"],axis=1,inplace=True)
#再次查看文件
print(clear)
except:
print("没有删除无效行")
try:
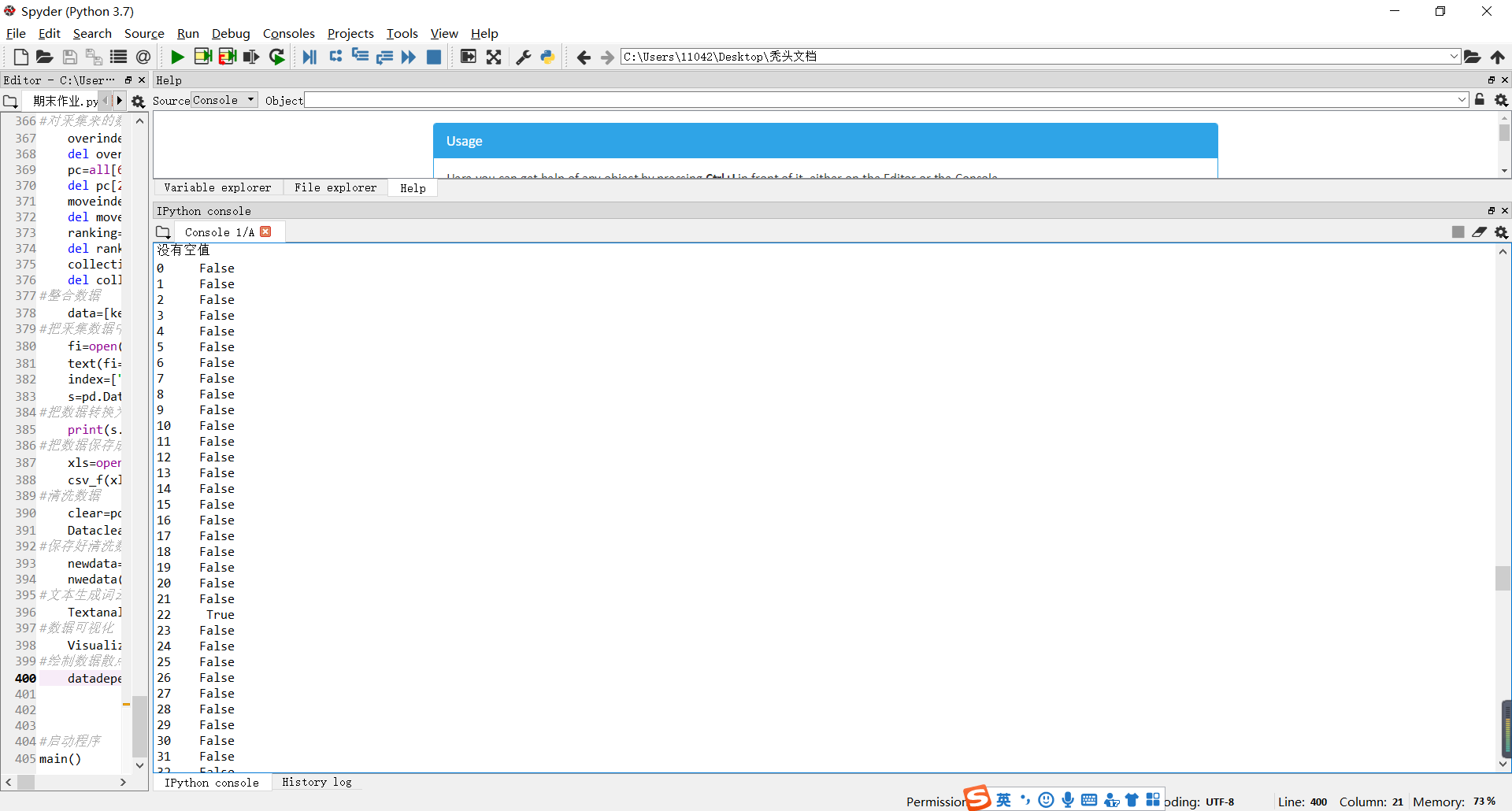
#查找是否有空值
print(clear.isnull().value_counts())
#把空值都变为零
clear.fillna(0)
except:
print("没有空值")
try:
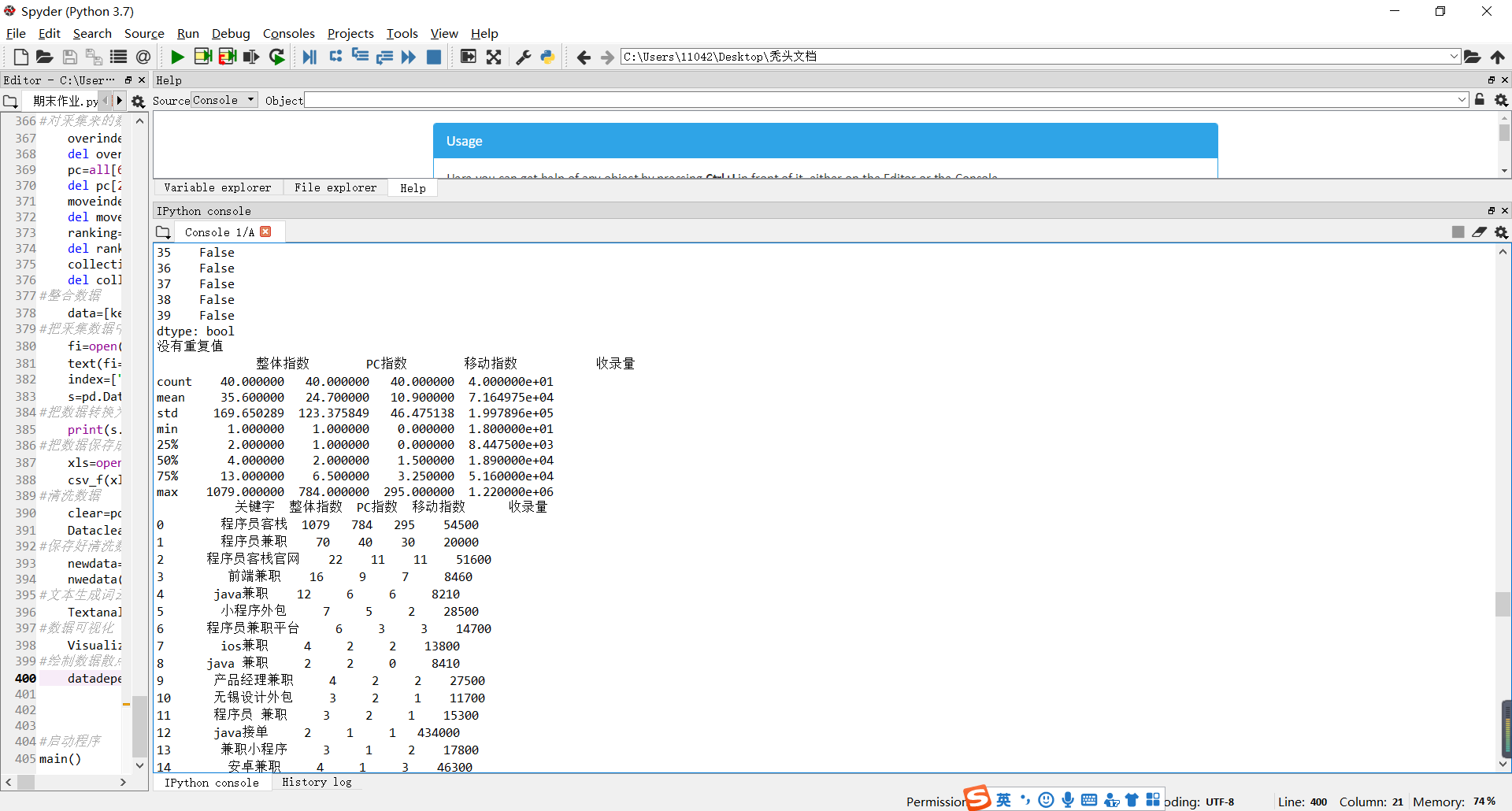
#查看重复值
print(clear.duplicated())
#删除重复值
clear.drop_duolicated()
except:
print("没有重复值")
try:
#查看异常值
print(clear.describe())
except:
print("无法查看异常值")
print(clear)
#把清洗好的数据保存
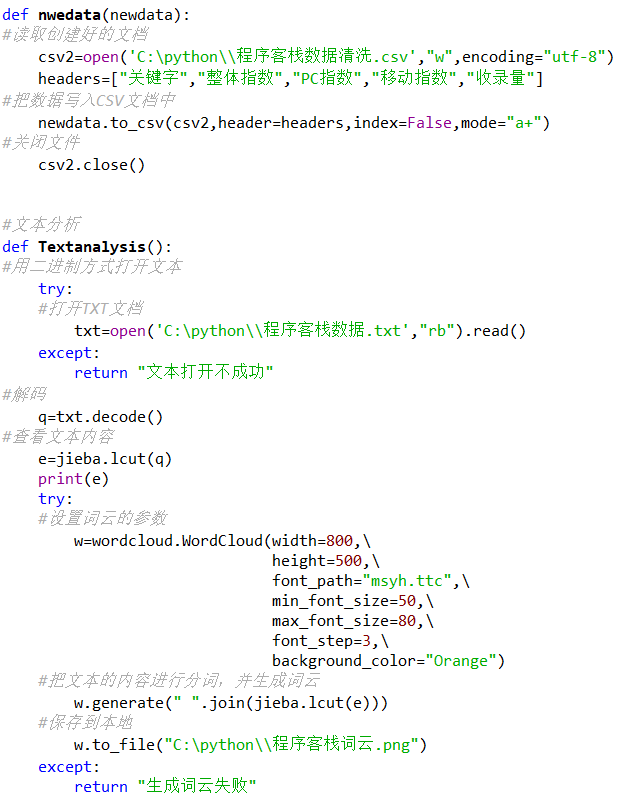
def nwedata(newdata):
#读取创建好的文档
csv2=open('C:\python\\程序客栈数据清洗.csv',"w",encoding="utf-8")
headers=["关键字","整体指数","PC指数","移动指数","收录量"]
#把数据写入CSV文档中
newdata.to_csv(csv2,header=headers,index=False,mode="a+")
#关闭文件
csv2.close()
#文本分析
def Textanalysis():
#用二进制方式打开文本
try:
#打开TXT文档
txt=open('C:\python\\程序客栈数据.txt',"rb").read()
except:
return "文本打开不成功"
#解码
q=txt.decode()
#查看文本内容
e=jieba.lcut(q)
print(e)
try:
#设置词云的参数
w=wordcloud.WordCloud(width=800,\
height=500,\
font_path="msyh.ttc",\
min_font_size=50,\
max_font_size=80,\
font_step=3,\
background_color="Orange")
#把文本的内容进行分词,并生成词云
w.generate(" ".join(jieba.lcut(e)))
#保存到本地
w.to_file("C:\python\\程序客栈词云.png")
except:
return "生成词云失败"
#数据分析与可视化
def Visualization():
Visualdata=pd.read_csv('C:\python\\程序客栈数据清洗.csv')
#读取数据
X=np.array(Visualdata.loc[:,"收录量"])
X.sort()
Y=np.array(Visualdata.loc[:,"整体指数"])
Y.sort()
Y2=np.array(Visualdata.loc[:,"移动指数"])
Y2.sort()
Y3=np.array(Visualdata.loc[:,"PC指数"])
Y3.sort()
#开始把数据可视化
#绘制“收录量”和“整体指数”的折线图和柱状图
try:
plt.figure(figsize=(15,6))
plt.subplot(2,2,1)
plt.xlabel("收录量")
plt.ylabel("整体指数")
plt.title("收录量跟整体指数的关系")
plt.plot(X,Y,\
color="orange",\
lw=3,\
marker="o",\
mfc="orange")
plt.bar(X,Y,\
color="blue")
plt.show()
except:
return "数据可视化失败"
#绘制“收录量”和“移动指数”的折线图和柱状图
try:
plt.subplot(2,2,2)
plt.xlabel("收录量")
plt.ylabel("移动指数")
plt.title("收录量跟移动指数的关系")
plt.plot(X,Y2,\
color="r",\
lw=3,\
marker="o",\
mfc="r")
plt.bar(X,Y2,\
color="c")
plt.show()
except:
return "数据可视化失败"
#绘制“收录量”和“PC指数”的折线图和柱状图
try:
plt.subplot(2,1,2)
plt.xlabel("收录量")
plt.ylabel("PC指数")
plt.title("收录量跟PC指数的关系")
plt.plot(X,Y3,\
color="g",\
lw=3,\
marker="o",\
mfc="g")
plt.bar(X,Y3,\
color="brown")
plt.legend()
plt.show()
except:
return "数据可视化失败"
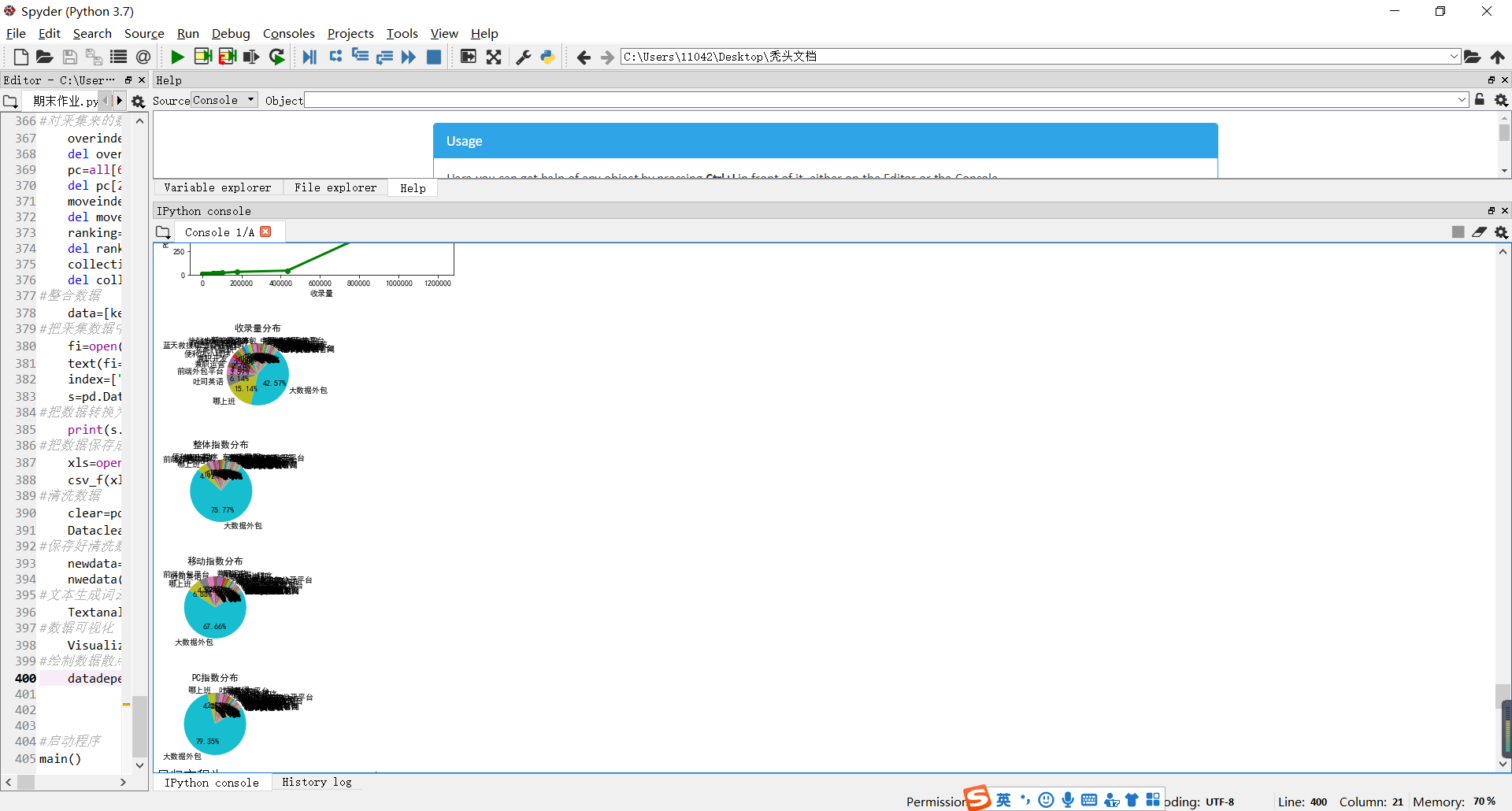
#把收录量可视化,查看每一个关键字占的百分比
try:
plt.subplot(2,2,1)
labels=Visualdata.loc[:,"关键字"]
plt.pie(X,\
labels=labels,\
startangle=50,\
autopct='%.2f%%')
plt.title("收录量分布")
plt.show()
except:
return "无法生成饼图"
#把整体指数可视化,查看每一个关键字占的百分比
try:
plt.subplot(2,2,2)
labels=Visualdata.loc[:,"关键字"]
plt.pie(Y,\
labels=labels,\
startangle=50,\
autopct='%.2f%%')
plt.title("整体指数分布")
plt.show()
except:
return "无法生成饼图"
#把移动指数可视化,查看每一个关键字占的百分比
try:
plt.subplot(2,1,1)
labels=Visualdata.loc[:,"关键字"]
plt.pie(Y2,\
labels=labels,\
startangle=30,\
autopct='%.2f%%')
plt.title("移动指数分布")
plt.show()
except:
return "无法生成饼图"
#把PC指数可视化,查看每一个关键字占的百分比
try:
plt.subplot(2,2,1)
labels=Visualdata.loc[:,"关键字"]
plt.pie(Y3,\
labels=labels,\
startangle=30,\
autopct='%.2f%%')
plt.title("PC指数分布")
plt.show()
except:
return "无法生成饼图"
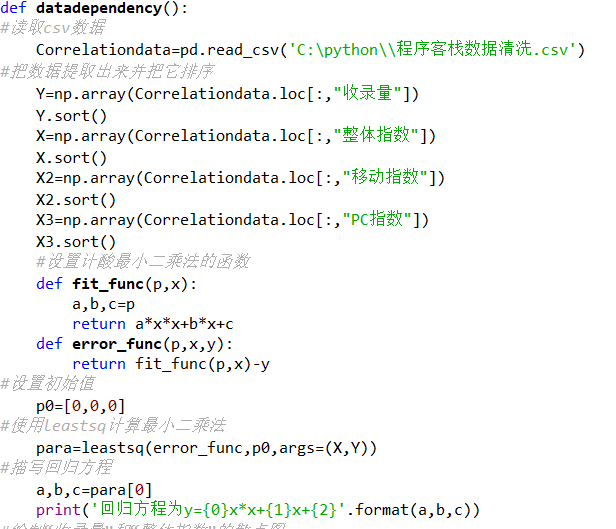
#数据相关性
def datadependency():
#读取csv数据
Correlationdata=pd.read_csv('C:\python\\程序客栈数据清洗.csv')
#把数据提取出来并把它排序
Y=np.array(Correlationdata.loc[:,"收录量"])
Y.sort()
X=np.array(Correlationdata.loc[:,"整体指数"])
X.sort()
X2=np.array(Correlationdata.loc[:,"移动指数"])
X2.sort()
X3=np.array(Correlationdata.loc[:,"PC指数"])
X3.sort()
#设置计酸最小二乘法的函数
def fit_func(p,x):
a,b,c=p
return a*x*x+b*x+c
def error_func(p,x,y):
return fit_func(p,x)-y
#设置初始值
p0=[0,0,0]
#使用leastsq计算最小二乘法
para=leastsq(error_func,p0,args=(X,Y))
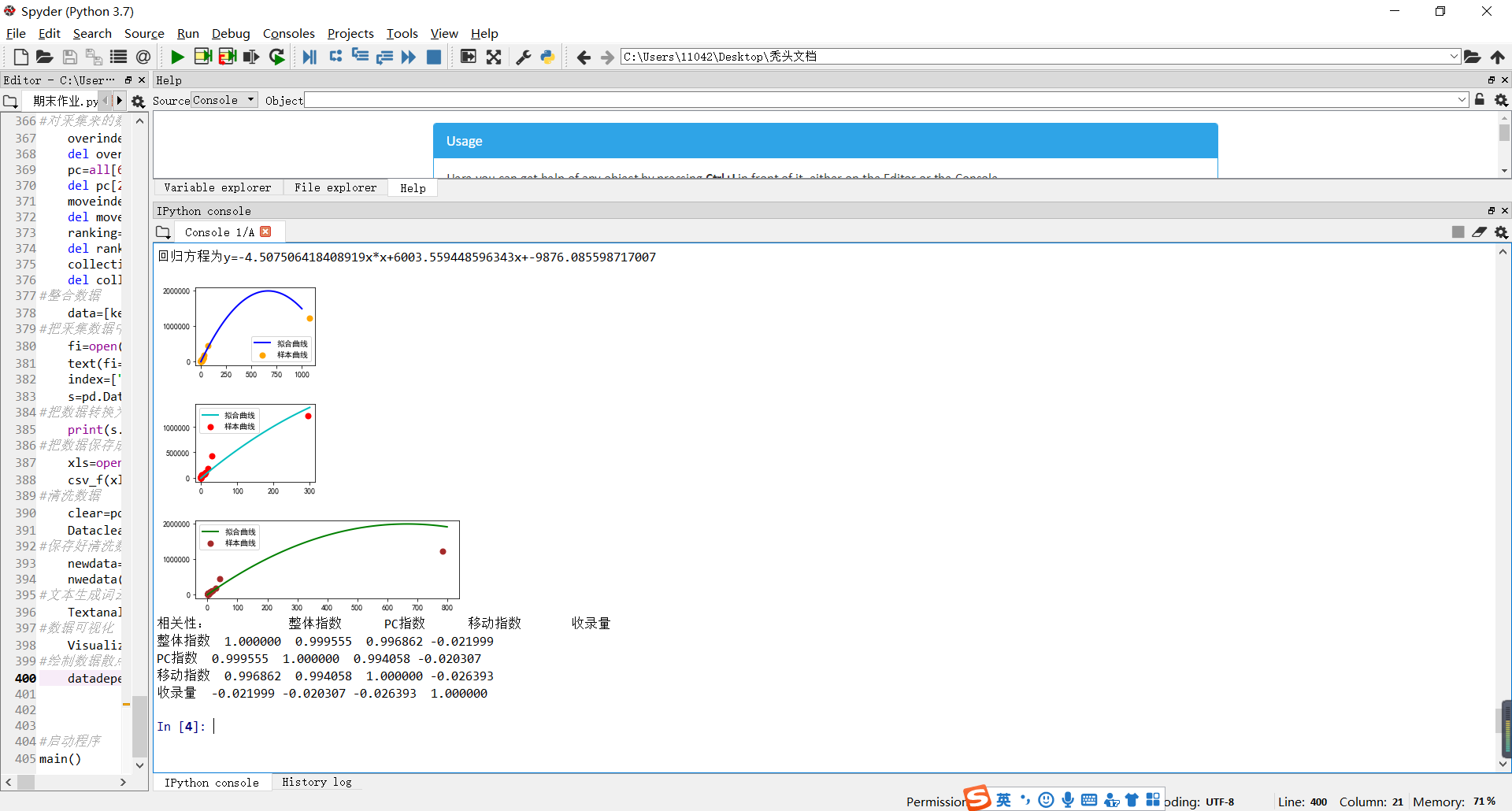
#描写回归方程
a,b,c=para[0]
print('回归方程为y={0}x*x+{1}x+{2}'.format(a,b,c))
#绘制“收录量”和“整体指数”的散点图
try:
plt.subplot(2,2,1)
plt.scatter(X,Y,\
color="orange",\
label="样本曲线",\
lw=2)
X1=np.linspace(0,1000,100)
Y1=a*X1*X1+b*X1+c
plt.plot(X1,Y1,\
color="blue",\
lw=2,\
label="拟合曲线")
plt.legend()
plt.show()
except:
return "生成散点图失败"
#绘制“收录量”和”移动指数“的散点图
try:
plt.subplot(2,2,2)
plt.scatter(X2,Y,\
color="r",\
label="样本曲线",\
lw=2)
X1=np.linspace(0,300,80)
Y1=a*X1*X1+b*X1+c
plt.plot(X1,Y1,\
color="c",\
lw=2,\
label="拟合曲线")
plt.legend()
plt.show()
except:
return "生成散点图失败"
#绘制“收录量”和“PC指数”的散点图
try:
plt.subplot(2,1,2)
plt.scatter(X3,Y,\
color="brown",\
label="样本曲线",\
lw=2)
X1=np.linspace(0,800,100)
Y1=a*X1*X1+b*X1+c
plt.plot(X1,Y1,\
color="g",\
lw=2,\
label="拟合曲线")
plt.legend()
plt.show()
except:
return "生成散点图失败"
#使用coor函数计算数据相关性
try:
Correlation=Correlationdata.corr()
print("相关性:",Correlation)
except:
return "无法显示相关性"
#主程序
def main():
#设置matplotilb参数
plt.rcParams['axes.unicode_minus']=False
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
mpl.rcParams["font.sans-serif"]=["SimHei"]
mpl.rcParams["axes.unicode_minus"]=False
#爬取深度为2
deth=2
#建立空列表
all=[]
keyword=[]
title=[]
for i in range(deth):
#设计一个爬取网站
url="http://rank.chinaz.com/www.proginn.com-0--0-"+str(i+1)
#获取网站
html=requests.get(url).text
#把网站编程HTMLL结构
soup=BeautifulSoup(html,"lxml")
#分析网站的结构
Structure=analyticaldata(soup)
#采集网站数据信息
Samplecollection(suop=soup,keyword=keyword,title=title,all=all)
#对采集来的数据线进行处理
overindex=all[5::5]
del overindex[20]
pc=all[6::5]
del pc[20]
moveindex=all[7::5]
del moveindex[20]
ranking=all[8::5]
del ranking[20]
collection=all[9::5]
del collection[20]
#整合数据
data=[keyword,overindex,pc,moveindex,ranking,collection,title]
#把采集数据中的“关键字”和“网页标题”保存到text文本中
fi=open('C:\python\\程序客栈数据.txt',"w",encoding="utf-8")
text(fi=fi,keyword=keyword,title=title)
index=["关键字","整体指数","PC指数","移动指数","百度排名","收录量","网页标题"]
s=pd.DataFrame(data,index)
#把数据转换为二维列表表示出来
print(s.T)
#把数据保存成为csv文件
xls=open('C:\python\\程序客栈数据.csv',"w",encoding="utf-8")
csv_f(xls=xls,s=s)
#清洗数据
clear=pd.read_csv("C:\python\\程序客栈数据.csv",names=["关键字","整体指数","PC指数","移动指数","百度排名","收录量","网页标题"])
Datacleaning(clear=clear)
#保存好清洗数据
newdata=clear
nwedata(newdata=newdata)
#文本生成词云
Textanalysis()
#数据可视化
Visualization()
#绘制数据散点图、回归方程和数据相关性
datadependency()
#启动程序
main()
词云展示


爬取来的数据保存到csv文件
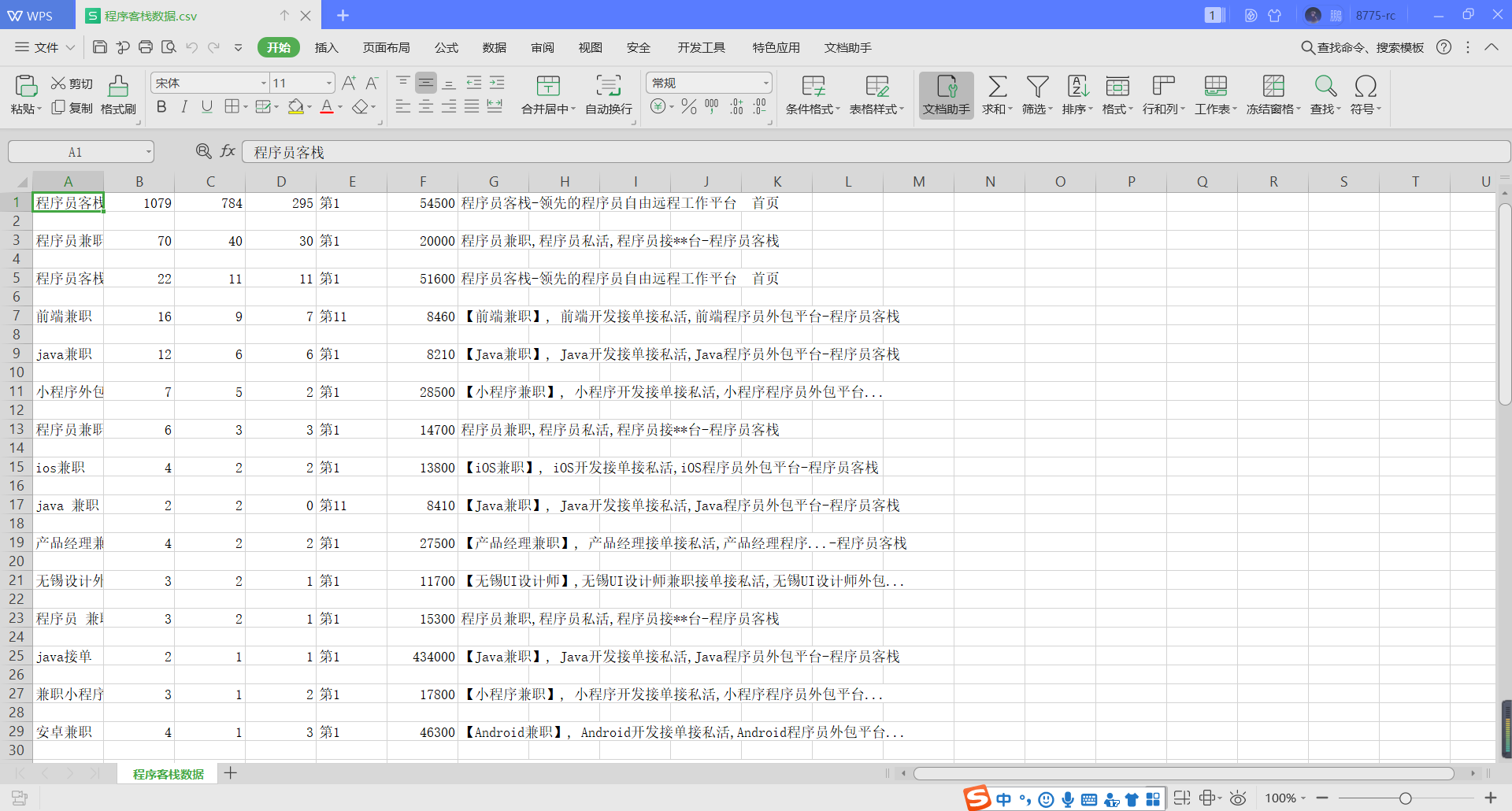
把关键字和网页标题写入txt文档
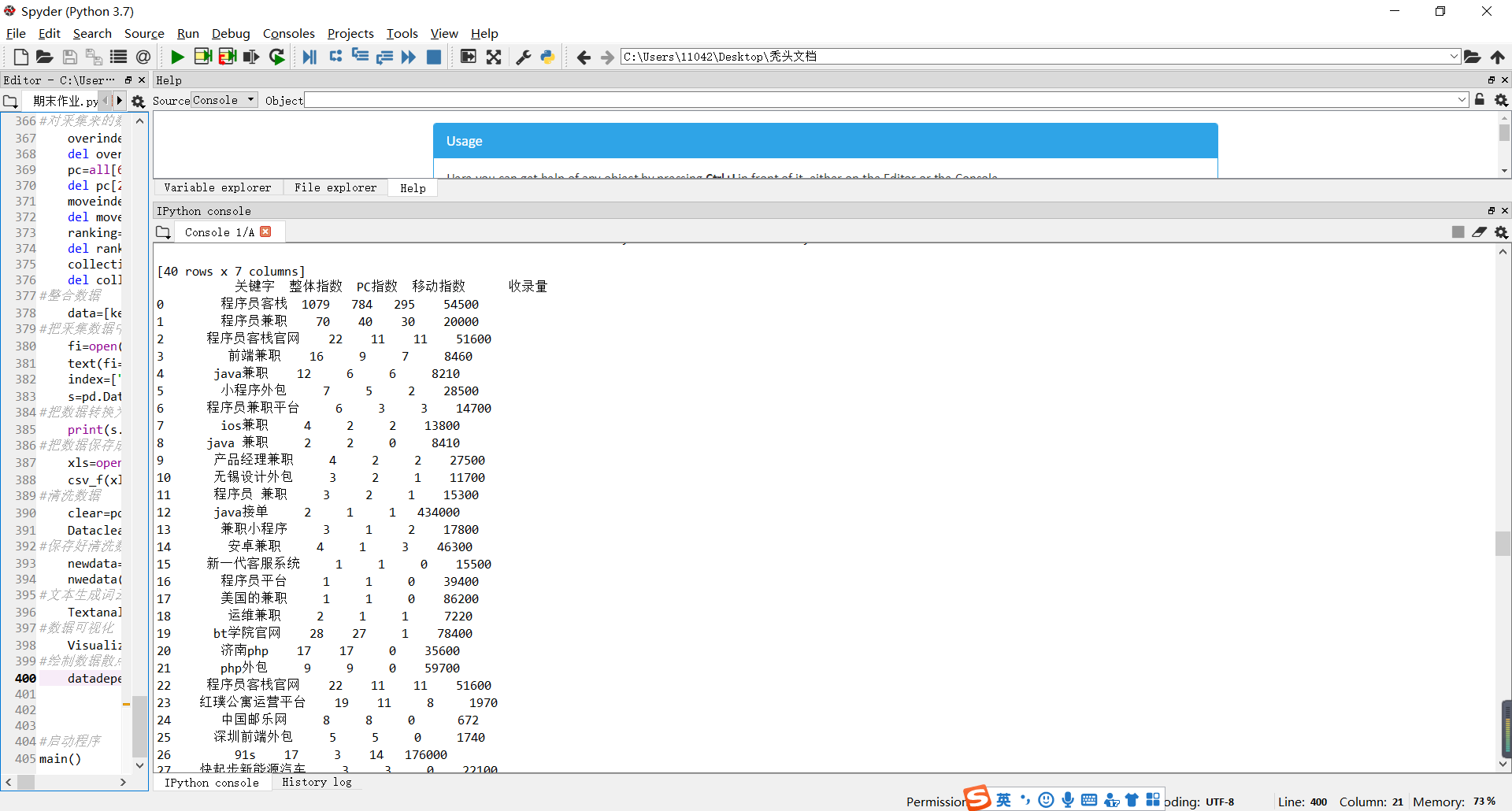
清洗好的数据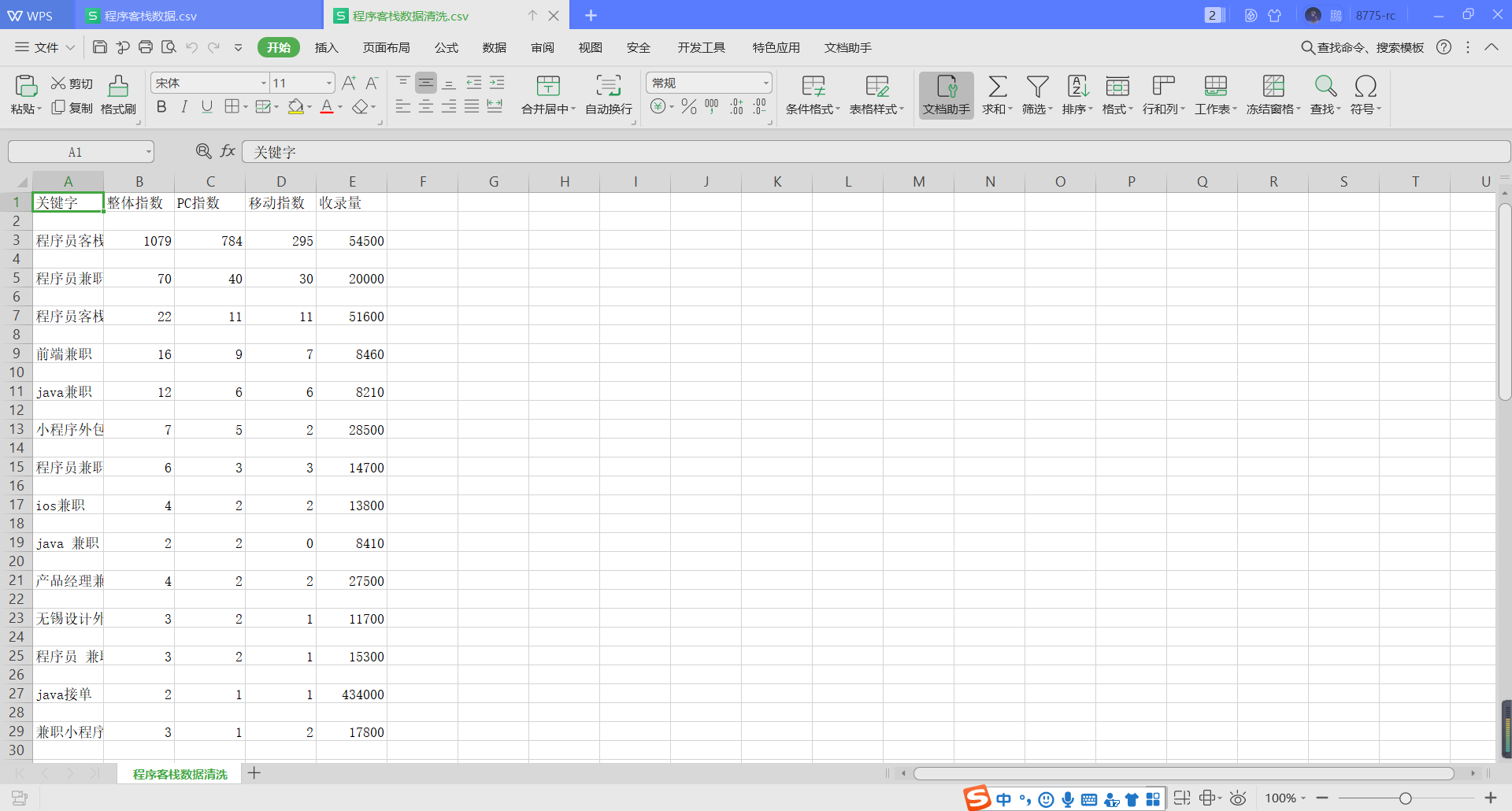
四、结论
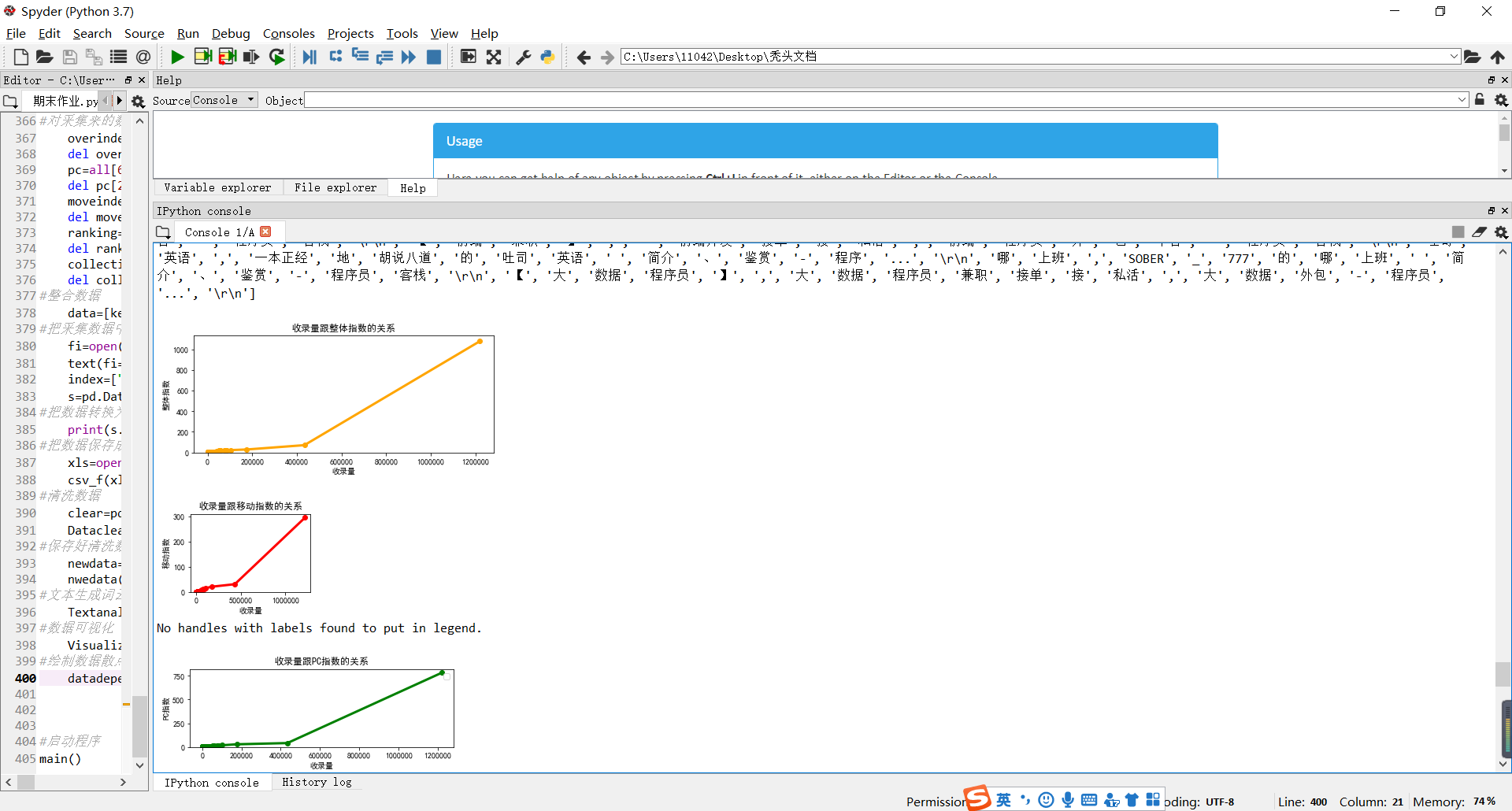
发现收录量跟其他的数据是呈现一个上升的趋势的,在绘制图形的时候需要整理好数据,这样才可以绘制出正确的图示
设计程序时遇到的问题可以通过百度搜索自我查找解决错误,发现写不出程序时先跳出框架,写下一个函数内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号