
day 43
今日内容
1.视图
2.事务
3.SQL注入问题
4.存储过程
首先回顾一下昨天所学
子查询:
in (select a where 字段名 in select b)
exists(判断后面语句执行结果是否为True 为True执行外层语句 False不执行外层语句)
正则表达式匹配
因为MySQL自身模糊查找只支持_和%查询
关键字 regexp用于正则表达式匹配
用户管理
GRANT all |权限管理 ON 数据库名.数据表名|*.* TO 用户名@"主机地址";
pymysql 模块使用
执行步骤:
1.连接数据库 conn = pymysql.Connect()
2.cursor = conn.cursor()获取游标
3.执行增删改查 cursor.execute(SQL语句)
4.获取执行结果或查询结果 fetchone #获取一条执行结果 fetchmany(指定获取执行结果数)#指定获取执行结果数 fetchall #获取所有执行结果
1.视图
视图是什么?
本质是一张虚拟表(他的数据来自select语句)
有什么用?
原表安全
功能一:隐藏部分数据 开放指定数据
功能二:因为视图可以将查询结果保存特性,我们可以用视图,来达到减少书写SQL的次数的目的
如何使用:
示例:
create view person_刘 as select * from emp where name = "刘备"; #创建视图
select * from person_刘;
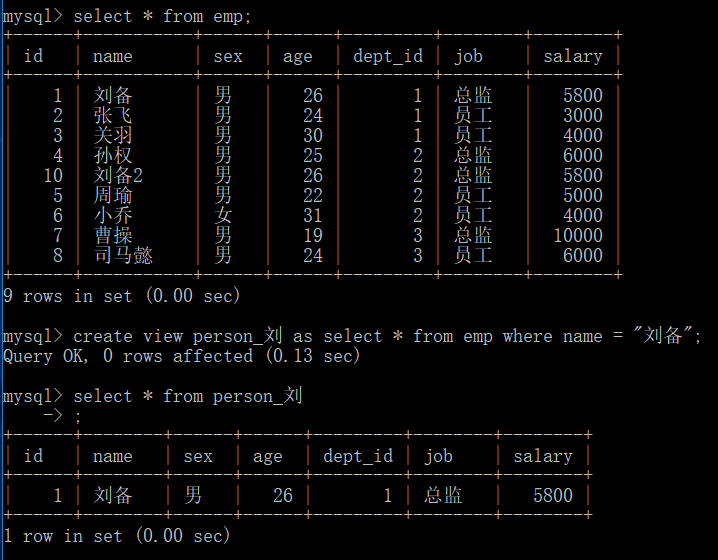
特点:
1.每次对视图进行的查询,其实都是再次执行了 as 后面的查询语句
2.可以对视图进行修改,修改会同步到原表
3.视图是永久存储的,存储的不是数据,而是一条 as sql 语句
2.事务
生活中的事务,我们可以理解为事情
一件事情要完成,通常需要分成多个步骤才能完成
在MySQL中事务是什么?
是一组MySQL语句的集合
事务的特性:
1.原子性
事务是一个整体,不可分割
2.隔离性
事务的隔离级别
1.读未提交(脏读,不可重复读,幻读)
2.读已提交(不可重复读,幻读)
3.可重复读(幻读)
4.可串行化(串行执行)
脏读:读取到另一个事务未提交的数据
不可重复读:两次对同一条记录查询结果不一致(一个事务在查询,另一个事务在更新)
幻读:对同一个表中的查询结果数量不一致(一个事物在查询,另一个事务在添加或删除)
3.一致性
当事务执行后 所有数据都是完整的(外键约束、非空约束)
4.持久性
一旦事务被提交,数据就会被永久保存
MySQL这个客户端默认开启自动提交,一条SQL语句就是一个单独的事务
pymysql默认是不自动提交,需要手动commit (默认开启了事务)
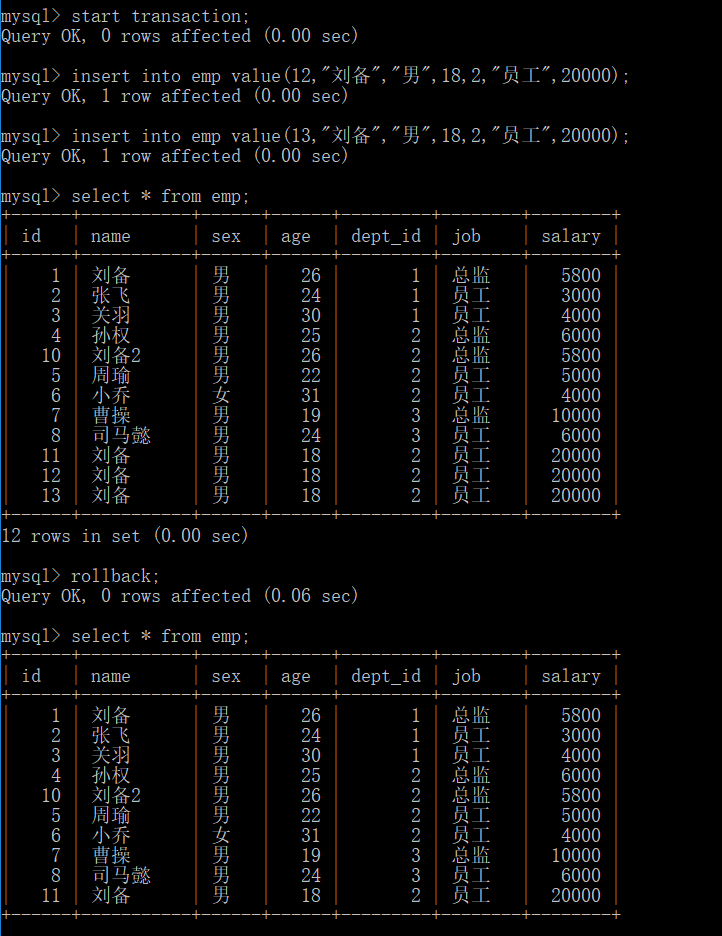
为事务创建保存点,保存点就像游戏中的记录,你可以回滚到指定的一个点
savepoint piont_name;
回滚至一个保存点
rollback to piont_name;
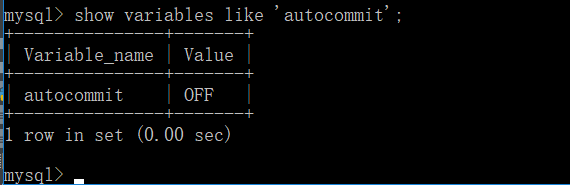
查看自己MySQL的自动提交状态
show variables like "autocommit";
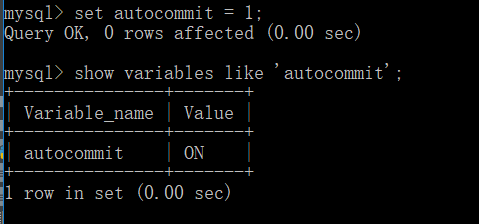
修改MySQL的自动提交状态
set autocommit = 1|0;(打开|关闭)
示例:开启一个事务,修改数据后然后rollback
3.SQL注入问题
通过在输入是输入一些sql语句导致数据流失如输入“--”注释后面的代码,导致不用输入name 直接可以查询成功,
为了预防这种操作,我们需要将输入写进cursor.execute(输入语句)因为这个pymysql这个方法内部已经帮我们做好了过滤
import pymysql
conn = pymysql.Connect(
host = "localhost",
user = "root",
password = "123456",
database = "mydb2",
port = 3306,
charset = 'utf8'
)
cursor = conn.cursor(pymysql.cursors.DictCursor)
sql = "select * from emp where id = '%s' and name = '%s'"%(input("id:"),input("name:"))
print(sql)
res = cursor.execute(sql)
if res:
print('查询成功')
print(res)
else:
print('查询失败')
cursor.close()
conn.close()
4.存储过程
存储过程是什么?
可以理解为MySQL的编程语言
作用:可以将你的程序业务逻辑,放到MySQL中来处理(这样可以降低网络访问次数,从而提高你的程序效率)
既然如此,能不能把所有的与数据存储有关的业务逻辑全部放到MySQL中?
理论上,技术层面上是可以的,但是,对于公司而言需要再请一个MySQL开发者,对于你个人来说,也提高了沟通成本
三种开发的模式
对于同样一个业务,你可以放到python,也可以放到MySQL中
区别:
1.应用程序(处理逻辑)
需要手动编写SQL语句
优点:执行效率高
缺点:开发效率低
2.MySQL(处理逻辑)
特点:应用程序开发者不需要手动编写SQL语句(MySQL开发者来编写)
优点:应用程序开发效率高
缺点:执行效率略低,沟通成本增高
3.使用ORM(object relation map)对象关系映射
自动帮你生成对应的SQL语句
优点:开发效率高
缺点:执行效率低
存储过程就相当于python中的一个函数
简单来说,学习存储过程就是学习如何使用MySQL编写一个函数
语法:
create procedure 过程名称 (in | out | inout , 参数名称,数据类型)
begin
具体的SQL代码
end
参数前面需要指定参数的作用
in 表示该参数用于传入
out 表示返回数据
inout 可传入 也可返回
参数类型是MySQL的数据类型
注:在存储过程中,需要是用分号来结束一行,但是分号有特殊含义
要将原始的结束符,修改为其他符号
delimiter // #结束符更改为//
delimiter ; (记得要将结束符改回来)
案例一
begin
select a + b ;
end//
create procedure add_d(in a int,in b int,out su)
begin
set @su = a+b;
end //

 浙公网安备 33010602011771号
浙公网安备 33010602011771号