spark sql 分析天气数据实验数据集
问题
数据集:spark分析天气数据实验数据集
实践内容:1、找出每个月的最高温;2、自定义聚合函数,求某一观测点所有温度的平均值。
要求:运用spark SQL完成实践内容。
注释:avgTemperature与maxTemperature文件夹存储的是数据结果
TemperatureAvgFunction程序功能:自定义聚合函数
SparkSqlTemperature程序功能:实现两个功能
一.程序代码
1. 自定义聚合函数


package bigdata.spark.sql
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, LongType, StructType}
class TemperatureAvgFunction extends UserDefinedAggregateFunction {
// 函数输入的数据结构
def inputSchema: StructType = {
new StructType().add("temperature", LongType)
}
// 计算时的数据结构(缓冲区的计算结构)
def bufferSchema: StructType = {
new StructType().add("sum", LongType).add("count", LongType)
}
// 数据计算完毕之后的结构(函数返回数据类型)
def dataType: DataType = DoubleType
// 稳定性
def deterministic: Boolean = true
// 当前计算之前缓冲区的初始化(就是sum和count初始化是什么值)
// 不考虑类型,只考虑结构
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L // 0代表第一个sum 初始化为0
buffer(1) = 0L // 1代表第二个count 初始化为0
}
// 根据查询结构更新缓冲区数据
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
// 将多个节点的缓冲区合并
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
// sum=缓冲区第一个位置的sum加上缓冲区第二个位置的sum
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
// count
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// 计算最终结果
def evaluate(buffer: Row): Any = {
buffer.getLong(0).toDouble / buffer.getLong(1)
}
}
2.在Scala程序中实现功能要求
package bigdata.spark.sql
import org.apache.spark.{SparkConf, SparkContext, sql}
import org.apache.spark.sql.{RowFactory, SaveMode, SparkSession}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
object SparkSqlTemperature {
def main(args: Array[String]): Unit = {
//SQL编程入口
val spark: SparkSession = SparkSession
.builder()
.appName("SparkSqlTemperature")
.master("local")
.getOrCreate()
val sc = spark.sparkContext
//对数据的处理
val data: RDD[String] = sc.textFile("E:\\cndcdata.txt")
val data1 = data.filter(line => {
var Temperature = 0
if (line.charAt(88) == '+'){
Temperature = line.substring(89, 92).toInt
} else {
Temperature = line.substring(88, 92).toInt
}
//Temperature是9999为异常数据,排除,数据过滤
Temperature != 9999
})
.map(line => {
val year_month = line.substring(15, 21)
var date = line.substring(15, 23)
var Temperature = line.substring(87, 92).toInt
(date,year_month,Temperature)
}
)
var data2 = data1.map(x => (x._2, x._3))
//问题1、找出每个月的最高温
val df1 = spark.createDataFrame(data2).toDF("year_month","Temperature")
df1.createOrReplaceTempView("Temperature_Max")
var df0 = spark.sql("select year_month,max(Temperature) as MaxTemperature from Temperature_Max group by year_month order by year_month")
//将dataframe数据保存到文件中
df0.coalesce(1).write.option("header", "true").csv("maxtemperature")
//问题2、自定义聚合函数,求某一观测点所有温度的平均值
var data3 = data1.map(x => (x._1, x._3))
val df2 = spark.createDataFrame(data3).toDF("date","Temperature")
df2.createOrReplaceTempView("temperature")
//生成自定义聚合函数
val udaf = new TemperatureAvgFunction
//注册自定义聚合函数
spark.udf.register("AvgFunction",udaf)
var df3 = spark.sql("select date,AvgFunction(Temperature) as avg_Temperature from temperature group by date")
//将dataframe数据保存到文件中
df3.coalesce(1).write.option("header", "true").csv("avgtemperature")
// 释放资源
spark.stop()
}
// 屏蔽不必要的日志显示终端上
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
}
二.程序结果
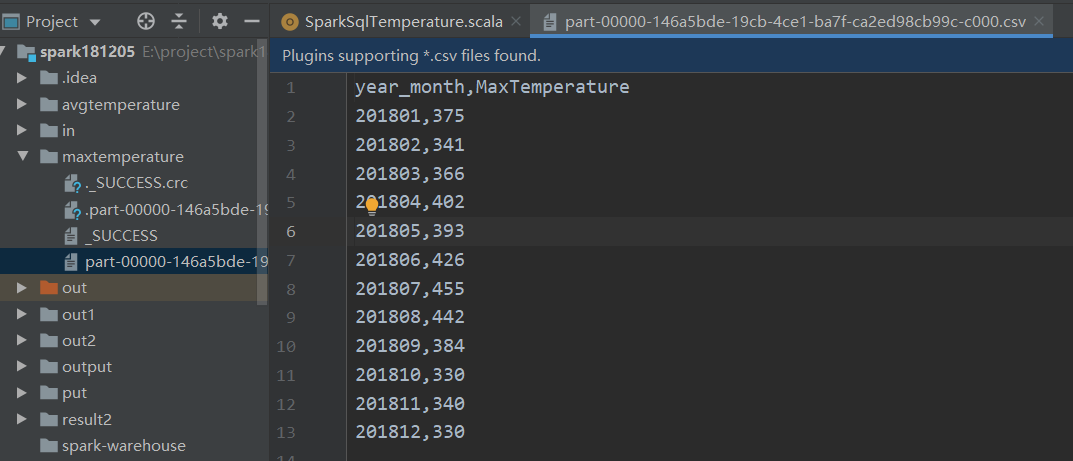
问题1、找出每个月的最高温,将结果dataframe数据都存进maxtemperature文件中
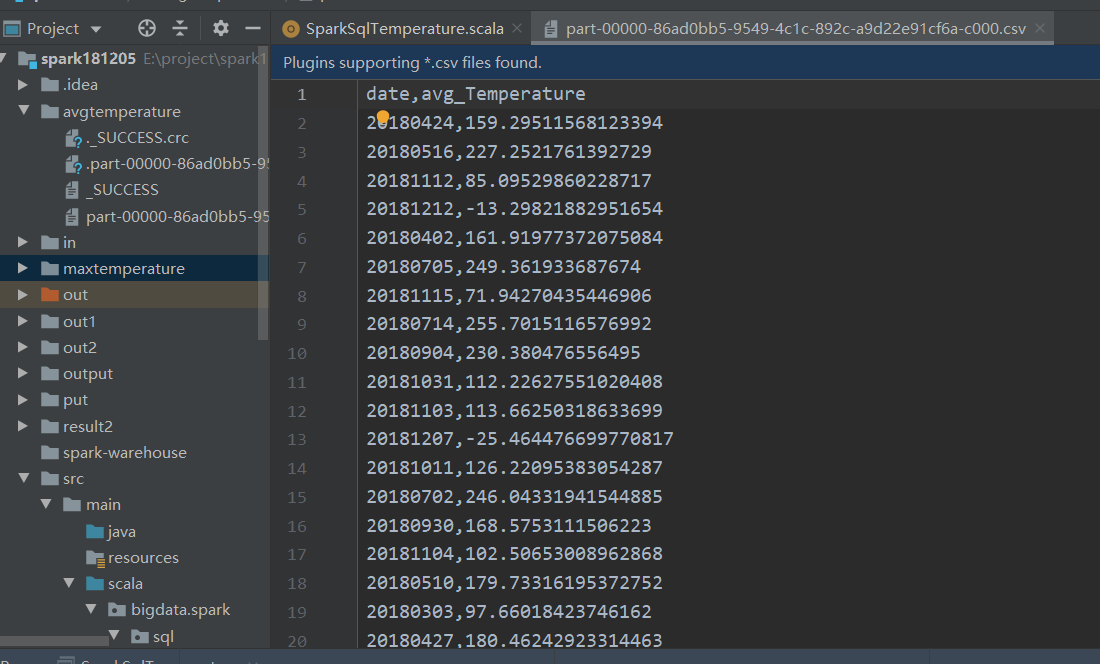
问题2、自定义聚合函数,求某一观测点所有温度的平均值,将结果dataframe数据都存进avgtemperature文件中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号