RDD算子实践
一.map算子
作用:
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成。源码中 map 算子相当于初始化一个 RDD,新RDD 叫做 MappedRDD(this, sc.clean(f))。
实践:
创建一个1-5数组的RDD,将所有元素*2形成新的RDD
object RDD_Operator { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("StuScore") val sc = new SparkContext(conf) //map算子 var listRDD: RDD[Int] = sc.makeRDD(1 to 5) //var mapRDD : RDD[Int] = listRDD.map(x=>x*2) var mapRDD : RDD[Int] = listRDD.map(_*2) mapRDD.collect().foreach(println) } }

实践:
创建一个string的集合的RDD,对所有元素加一个前缀"str_"
object RDD_Operator { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("StuScore") val sc = new SparkContext(conf) //map算子 val array1 = List("spark","hadoop","hello") var listRDD: RDD[String] = sc.makeRDD(array1) var mapRDD : RDD[String] = listRDD.map("str_"+_) mapRDD.collect().foreach(println) } }

二. mapPartitions算子
作用:
类似于map,可能会出现内存溢出,但效率优于map,减少了发送到执行器执行交互次数,而且独立地在RDD的每一个分区上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]。假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区。在函数中通过这个分区整体的迭代器对整个分区的元素进行操作。
实践:
创建一个1-5数组的RDD,将所有元素*2形成新的RDD
//mapPartitions算子 var listRDD1: RDD[Int] = sc.makeRDD(1 to 5) var mapPartitionsRDD: RDD[Int] = listRDD1.mapPartitions(datas=>{ datas.map(data=>data*2) }) mapPartitionsRDD.collect().foreach(println)

三. mapPartitionsWithIndex算子
作用:
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U];
实践:
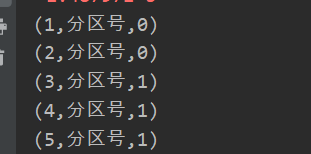
创建一个RDD,使每个元素跟所在分区形成一个元组组成一个新的RDD
//mapPartitionsWithIndex算子 var listRDD1: RDD[Int] = sc.makeRDD(1 to 5,2) //makeRDD第二个参数是定义的分区数目 val tupleRDD: RDD[(Int,String)] =listRDD1.mapPartitionsWithIndex{ case(num,datas)=>{ datas.map((_,"分区号,"+num)) //得到 每一条数据,"分区号",分区号 } } tupleRDD.collect().foreach(println)
四. flatMap算子
作用:
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
实践:
将集合拆成一个个元素
//flatMap算子 var listRDD1: RDD[List[Int]] = sc.makeRDD(Array(List(1,2),List(3,4))) var flatMapRDD: RDD[Int] = listRDD1.flatMap(datas=>datas) flatMapRDD.collect().foreach(println)

五. glom算子
作用:
将每一个分区形成一个数组,形成新的RDD类型时RDD[Array[T]]
实践:
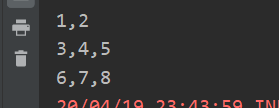
创建一个3个分区的RDD,并将每个分区的数据放到一个数组
//glom算子 var listRDD1: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6,7,8),3) var glomRDD: RDD[Array[Int]] =listRDD1.glom() glomRDD.collect().foreach(array=>{ println(array.mkString(",")) })
六. groupBy算子
作用:
分组,按照传入函数的返回值进行分组。将相同的key对应的值放入一个迭代器
实践:
创建一个RDD,按照元素模以2的值进行分组。
//groupBy算子 var listRDD1: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6,7,8)) //分组后的数据形成了对偶元组(K-V),k表示分组的key,v表示分组的数据集合,就是这里的[(Int,Iterable[Int])] var groupByRDD: RDD[(Int,Iterable[Int])] =listRDD1.groupBy(i=>i%2) groupByRDD.collect().foreach(println)

七. filter算子
作用:
过滤。返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成。
实践:
需求:过滤出一个新RDD(元素值都为偶数)
//filter算子 var listRDD1: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6,7,8)) var filterRDD: RDD[Int] = listRDD1.filter(x=>x%2==0) filterRDD.collect().foreach(println)

八. sortBy算子
作用:使用func先对数据进行处理,按照处理后的数据比较结果排序,默认为正序。
可对键值对数据进行value排序
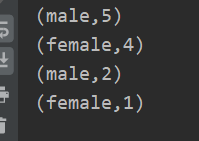
案例:
//sortBy算子 val rdd=sc.parallelize(List(("female",1),("male",5),("female",4),("male",2))) val reduce=rdd.sortBy(_._2,false).collect.foreach(println)
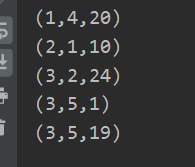
全排序
先对第一个元素进行比较,若相同比较第二个元素,若一二个元素都相同比较第三个元素
//全排序 先对第一个元素进行比较,若相同比较第二个元素,若一二个元素都相同比较第三个元素 val rdd1=sc.parallelize(List((2,1,10),(3,5,19),(3,5,1),(1,4,20),(3,2,24))) var r2=rdd1.collect.sorted.foreach(println)
案例:
创建一个RDD,按照3的余数进行排序
//sortBy算子 var listRDD1: RDD[Int] = sc.makeRDD(List(5,8,1,6)) var sortByRDD: RDD[Int] = listRDD1.sortBy(x=>x%3) //按照3的余数排序 sortByRDD.collect().foreach(println)
九. partitionBy算子
作用:
对pairRDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区, 否则会生成ShuffleRDD,即会产生shuffle过程。
案例:
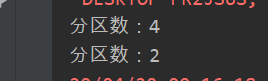
创建一个4个分区的RDD,对其重新分区为两个分区
//partitionBy算子 val rdd = sc.parallelize(Array((1,"aaa"),(2,"bbb"),(3,"ccc"),(4,"ddd")),4) println("分区数:"+rdd.partitions.size) var rdd2 = rdd.partitionBy(new org.apache.spark.HashPartitioner(2)) println("分区数:"+rdd2.partitions.size)
十. groupByKey算子
作用:groupByKey也是对每个key进行操作,但只生成一个sequence。
案例:
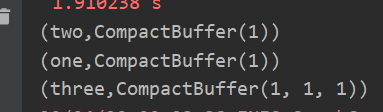
创建一个pairRDD,将相同key对应值聚合到一个sequence中,并计算相同key对应值的相加结果。
//groupByKey算子 val words=Array("one","two","three","three","three" ) val wordPairRDD=sc.parallelize(words).map(word=>(word,1)) val group=wordPairRDD.groupByKey()//将相同key对应值聚合到一个sequence中 group.collect.foreach(println)//直接打印 group.map(t=>(t._1,t._2.sum)).collect.foreach(println)//聚合

十一. reduceByKey算子
作用:在一个(Key,Value)的RDD上调用,返回一个(Key,Value)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。
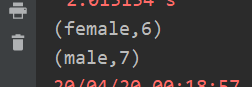
案例:创建一个pairRDD,计算相同key对应值的相加结果
//reduceByKey算子 val rdd=sc.parallelize(List(("female",1),("male",5),("female",5),("male",2))) val reduce=rdd.reduceByKey((x,y)=>x+y) reduce.collect.foreach(println)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号