RDD编程求最高分
一.问题
假设已知spark课程的学生成绩如下:
('stu01',90)
('stu02',91)
('stu03',88)
('stu04',96)
('stu05',98)
('stu06',95)
编程spark程序求解:
1、最高分的学生和分数;
2、这门课程的平均分。
二.思路
编程spark程序求解:
1、最高分的学生和分数;
首先使用spark提供的parallelize函数从集合中创建RDD,
然后使用rdd中的reduce函数(函数功能:将RDD中元素两两传递给输入函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个值为止。),代码为:
val result = rdd.reduce((x,y) => (if(x._2 < y._2) y else x))
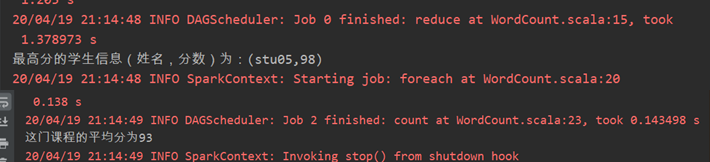
得到了最高分的学生信息(姓名,分数)。
2、这门课程的平均分
思路:平均分=分数和/人数
分数和:使用累加器累加这些学生的分数获得,即emptyLineCount.value,其代码为:
val emptyLineCount: LongAccumulator = sc.longAccumulator
rdd.foreach(s => if (s._2 != 0) emptyLineCount.add(s._2))
人数:使用rdd.count()获得rdd的元素个数,也即学生的个数
平均分:val avg = emptyLineCount.value/rdd.count()
三.程序
1 package com.bigdata.spark 2 import org.apache.spark.{SparkConf, SparkContext} 3 import org.apache.spark.util.LongAccumulator 4 object WordCount { 5 def main(args: Array[String]): Unit = { 6 // 1. 创建 SparkConf对象, 并设置 App名字 7 val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("StuScore") 8 // 2. 创建SparkContext对象 9 val sc = new SparkContext(conf) 10 11 val rdd = sc.parallelize(Array[(String,Int)](("stu01",90),("stu02",91),("stu03",88), ("stu04",96), ("stu05",98), ("stu06",95))) 12 13 //val result1 = rdd.map(x => x._2).max 14 //val result2 = rdd.reduce((x,y) => ("result",(if(x._2 < y._2) y._2 else x._2))) 15 val result = rdd.reduce((x,y) => (if(x._2 < y._2) y else x)) 16 println("最高分的学生信息(姓名,分数)为:"+result) 17 18 //使用累加器累加这些学生的分数emptyLineCount.value 19 val emptyLineCount: LongAccumulator = sc.longAccumulator 20 rdd.foreach(s => if (s._2 != 0) emptyLineCount.add(s._2)) 21 //rdd.count()获得学生的个数--也即rdd的元素个数 22 //println(rdd.count()) 23 val avg = emptyLineCount.value/rdd.count() 24 println("这门课程的平均分为"+avg) 25 } 26 27 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号