NLP中的图结构
文本序列的结构信息
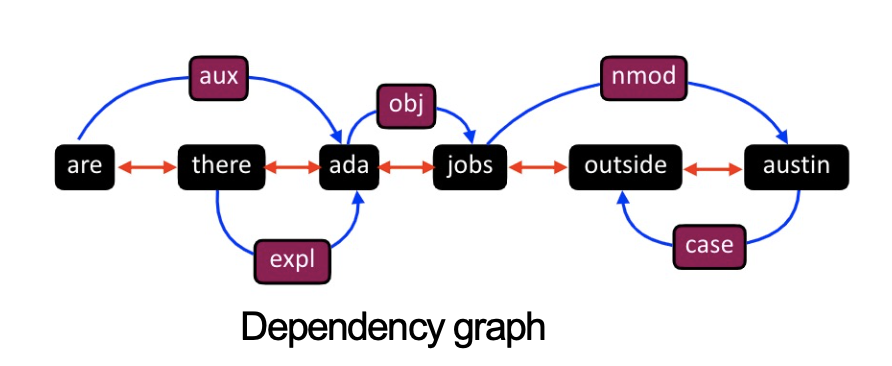
syntactic parsing trees like dependency
可将每个词看成一个结点,边为依赖解析标记,每个词有词性标记
用于机器翻译
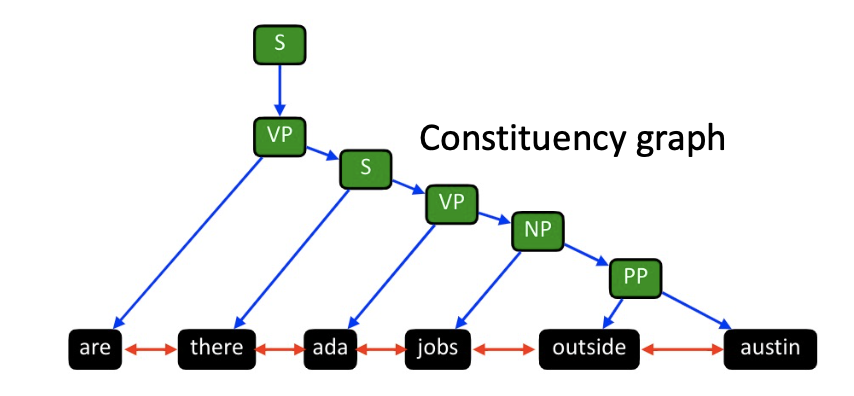
constituency parsing trees
文本序列的语义信息
semantic parsing graphs
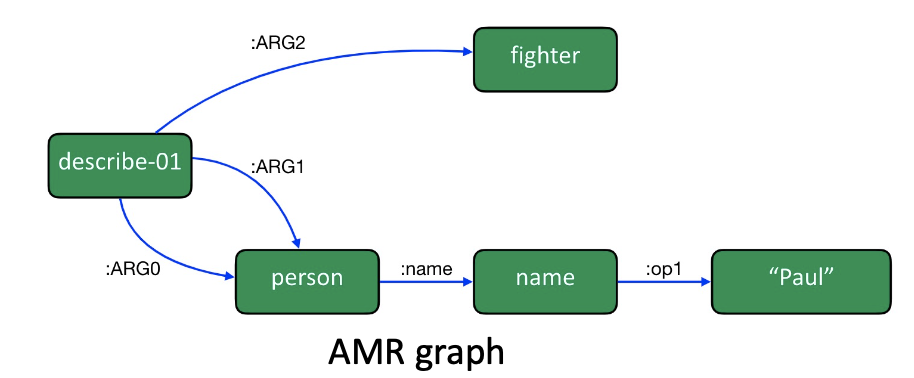
Abstract Meaning Representation graphs
Information Extraction graphs
知识图谱
每个结点是一个实体,边描述它们之间的关系
用于问答
基于统计信息的图
GNN和NLP的相关应用
文本分类
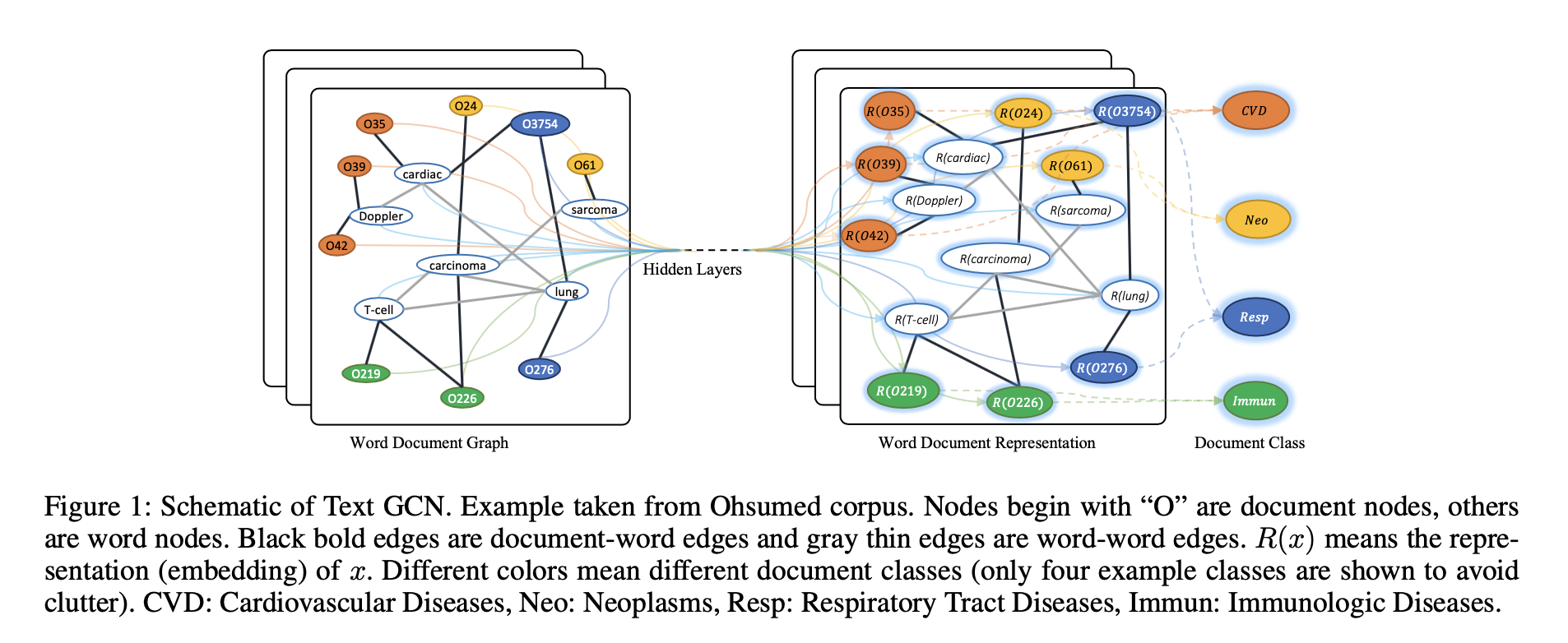
TextGCN[1]
异质文本图:词结点和文档结点(|V|是文档数+词汇数);如下图所示
设置特征矩阵X=I
文档-词边(权重为TF-IDF)
词-词边(整个语料库;显式建模全局词共现): 在语料库中的所有文档上使用固定大小的滑动窗口来获得共现统计量;使用point-wise mutual information (PMI)(衡量词之间的联系)
边权重如上图确定,其中#W(i)是语料库中包含词i的滑动窗口数,#W(i,j)是语料库中同时包含词i和j的滑动窗口数,#W是语料库中的滑动窗口数;正PMI值表明词之间高的语义关联,而负的表明几乎没有关联,因此只考虑正的值
应用两层GCN,即\(Z = softmax(\tilde{A} ReLU(\tilde{A}XW_0)W_1)\)
损失函数被定义为交叉熵损失,即\(L=-\sum_{d\in \mathcal{Y}_D}\sum_{f=1}^FY_{df}lnZ_{df}\) ,其中\(\mathcal{Y}_D\) 是有标记的文档索引集,F是输出特征维度,等于类别数
两层GCN允许消息在最多两跳远的结点之间传递,因此尽管图中没有文档-文档的直接连边,两层GCN仍允许它们之间进行信息交互
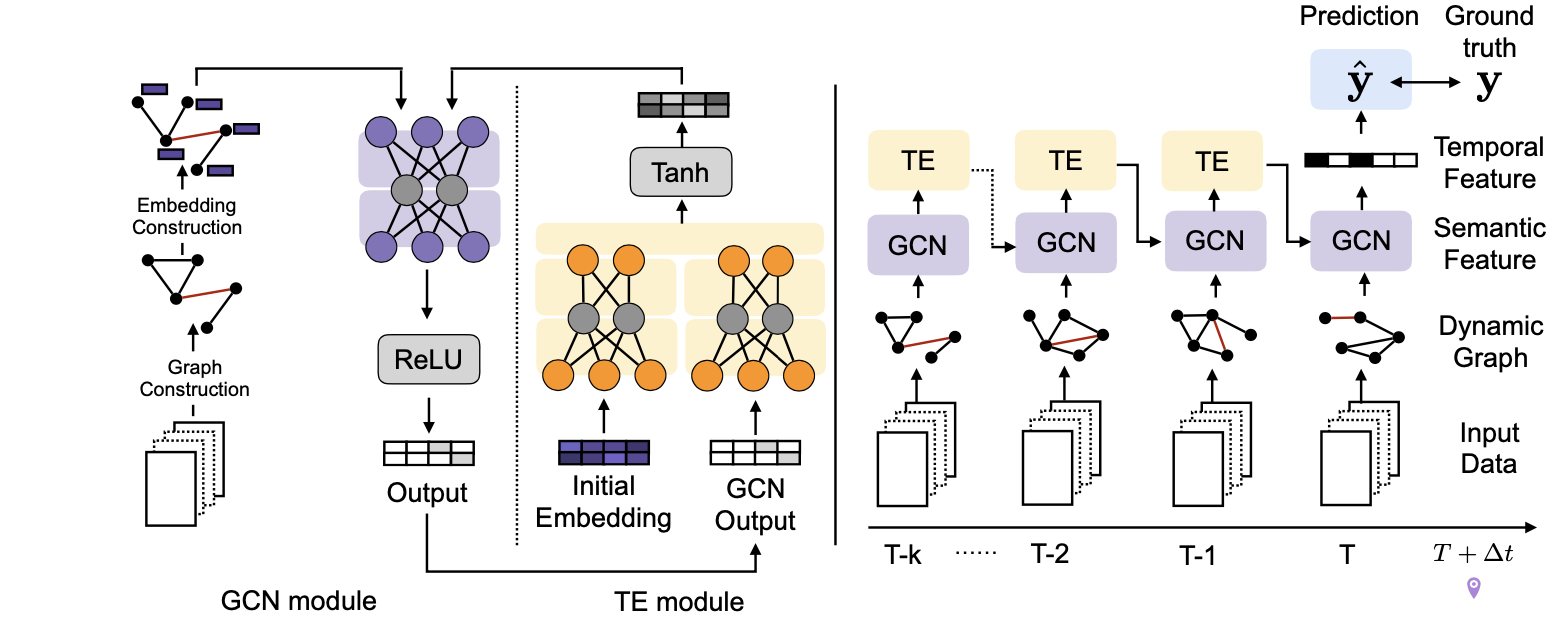
DynamicGCN[2]
借助上下文信息(文本数据)预测社会事件->建模动态上下文图来预测社会事件/未来事件
上下文结构和形成的不确定性
高维特征
特征随时间的调整
研究社会事件建模中的图表示:GNN
社会事件的发生是由于实体之间逐渐变化的互动;词袋和分布式表示仅关注文本的语义表示
使用GCN来预测未来事件
从历史事件文档中抽取和学习图表示
利用隐含词图特征来预测未来事件是否发生,将动态图序列看作是事件上下文
给定历史输入X(事件相关文章),使用结点嵌入将输入数据编码成一系列图(每个结点是一个词);基于图序列发展一个GCN模型来预测某种类型事件的发生y
\(x_{c,t}=\{\text{docs in days }t-1\to t-k\}\) ,c是城市;\(y_{c,t}=1\) 表明day t发生目标事件,\(y_{c,t}=0\) 则没有发生动态图的构建:抽取n个关键词(消除常见和不常见的词),创建多个词关系图(\(A_{t-k},...,A_{t-1},A_k\in R^{n\times n}\) ),其中边基于词共现
使用PMI(基于文档的逐点互信息)来计算两词之间的权重: \(PMI_t(i,j)=log\frac{d(i,j)}{d(i)d(j)/D}\) ,其中分母表示i,j都出现的文章数,D表示文章总数,d(i),d(j)分别表示i,j分别出现的文章数。因此\(A_t[i,j]=\begin{cases}
PMI_t(i,j), PMI_t(i,j)>0 \\
0, otherwise \\
\end{cases}\)
特征表示:将词i建模成一个实值向量\(h_i\in R^F\) (使用词嵌入作为初始特征)
模型框架如下图:
输入层:\([A_{t-k},...,A_{t-1}]\)
基于动态GCN的网络编码:动态GCN层同时处理t时刻的邻接矩阵和特征映射;每个时刻,图结点使用当前时刻其局部邻居信息来学习向量表示,邻居嵌入由上个时刻更新,即\(H_{t+1}=ReLU(\hat{A}_t\tilde{H}_tW^{(t)}+b^{(t)})\) ,其中\(\tilde{H}_t\) 由TE层给出
时序编码(TE)特征:\(H_0\in R^{n\times F^{(0)}}\) 是预训练的语义嵌入,当t>0时使用TE层来重新编码特征,包括每个结点的语义信息和学习到的GCN特征。\(H_p^{(t)}=H_tW_p^{(t)}+b_p^{(t)}\) ,\(H_e^{(t)}=H_0W_e^{(t)}+b_e^{(t)}\) ,\(\tilde{H}_t=tanh([H_p^{(t)}||H_e^{(t)}])\) ,\(||\) 表示连接,\(W_p^{(t)}\in R^{F^{(t)}\times \alpha}\) ,\(W_e^{(t)}\in R^{F\times (F^{(t)}-\alpha)}\)
遮蔽非线性变换层:将最后一层的输出特征维度设为1,可得到图结点的标量表示,即\(H_T\in R^{n\times 1}\) ;将\(H_T\) 通过一个遮蔽0 padding层来获得一个遮蔽特征向量(长度为整个词汇表大小):\(z_T=\text{zero_padding}(H_T^T)\) ,\(\hat{y}=\sigma(z_Tw_m^T+b_m)\)
优化:比较预测值和ground truth,优化二元交叉熵损失:\(L=-\sum yln\hat{y}\)
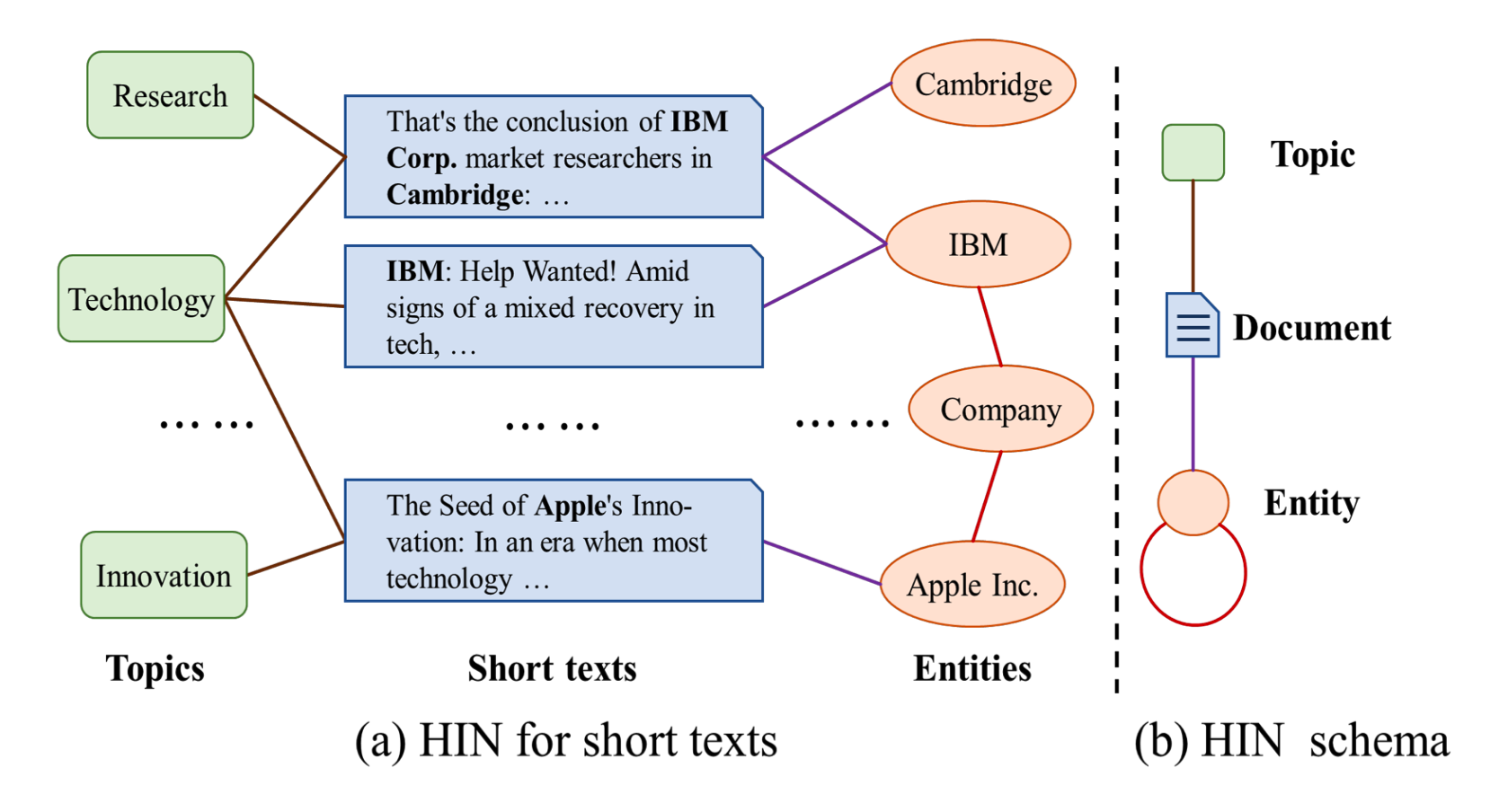
HGAT[4]
异质图上的半监督短文本分类
利用有限的标记数据和大量无标记数据
为减轻短文本的稀疏(丰富短文本的语义),先提出一个灵活的HIN(异质信息网络)框架来建模短文本,可包含额外信息和捕获短文本和添加信息的关系;如下图所示
考虑两类额外的信息:主题和实体;\(\mathcal{G}=(\mathcal{V},\mathcal{E})\) ,结点为短文本\(D=\{d_1,...,d_m\}\) 、主题\(T=\{t_1,...,t_K\}\) 和实体\(E=\{e_1,...,e_n\}\) ,即\(\mathcal{V}=D\cup T\cup E\)
使用LDA来挖掘隐含主题:每个主题\(t_i=(\theta_1,...,\theta_w)\) (w表示词汇大小)由词上的概率分布表示;为每个文档分配概率最高的P个主题;若存在分配关系,则文档-主题边建立
识别文档中的实体;使用实体链接工具TAGME;若文档包含实体则文档-实体边建立;将实体当成词,使用word2vec2学习实体嵌入
考虑实体间的关系;若两个实体的相似性分数(余弦相似度,基于嵌入计算)高于某个预定义的阈值\(\delta\) ,则建立实体-实体边
然后提出模型HGAT(异质图注意力网络),获得HIN的嵌入,基于双层注意力机制;考虑了不同类型信息的异质性(使用异质图卷积);注意力机制可学习不同结点的重要性(降低噪声信息的权重)和不同结点类型的重要性
异质图卷积:结点特征矩阵\(X\in R^{|\mathcal{V}|\times q}\) ,其中文档结点以TF-IDF向量作为特征向量,主题结点以词分布作为特征向量,实体结点以其嵌入和TF-IDF向量(Wikipedia的描述文本)的拼接作为特征向量,具有不同的特征空间
\(H^{(l+1)}=\sigma(\sum_{\tau\in \Gamma}\tilde{A}_{\tau}·H_{\tau}^{(l)}·W_{\tau}^{(l)})\) ,\(\tilde{A}_{\tau}\in R^{|\mathcal{V}|\times |\mathcal{V}_{\tau}|}\)
双层注意力机制:包含结点级别和类级别
类级别注意力:学习不同类型邻居结点的权重;将类型\(\tau\) 的嵌入表示成\(\tau\) 类型邻居结点特征的和,即\(h_{\tau}=\sum_{v^{'}}\tilde{A}_{vv^{'}}h_{v^{'}}\) ,然后基于当前结点嵌入\(h_v\) 和类型嵌入\(\tau\) 计算类级别注意力分数,即\(a_{\tau}=\text{Leaky ReLU}(\mu_{\tau}^{T}·[h_v||h_{\tau}])\) ,其中\(\mu_{\tau}\) 是类型\(\tau\) 的注意力向量;然后在所有类型上归一化注意力分数得到类级别注意力权重\(\alpha_{\tau}=\frac{exp(a_{\tau})}{\sum_{\tau^{'}\in \Gamma}exp(a_{\tau^{'}})}\)
结点级别注意力:捕获不同邻居结点的重要性;基于结点嵌入\(h_v,h_{v^{'}}\) 和类级别注意力权重\(\alpha_{\tau^{'}}\) 计算结点级别注意力:\(b_{vv^{'}}=\sigma(\nu^T·\alpha_{\tau^{'}}[h_v||h_{v^{'}}])\) ,其中\(\nu\) 是注意力向量;然后归一化结点级别注意力分数:\(\beta_{vv^{'}}=\frac{exp(b_{vv^{'}})}{\sum_{i\in N_{v}}exp(b_{vi})}\)
包含类级别和结点级别注意力的异质图卷积:\(H^{(l+1)}=\sigma(\sum_{\tau\in \Gamma}\mathcal{B}_{\tau}·H_{\tau}^{(l)}·W_{\tau}^{(l)})\) ,其中\(\mathcal{B}_{\tau}\) 表示注意力矩阵,其元素为\(\beta_{vv^{'}}\)
模型训练:\(Z = softmax(H^{(L)})\)
交叉熵损失:\(L=-\sum_{i\in D_{train}}\sum_{j=1}^CY_{ij}·lnZ_{ij}+\eta||\Theta||_2\) ,其中C是类别数,\(D_{train}\) 是短文本索引集,\(\Theta\) 是模型参数
短文本分类:标注数据少,人力成本高;语义稀疏,缺乏上下文
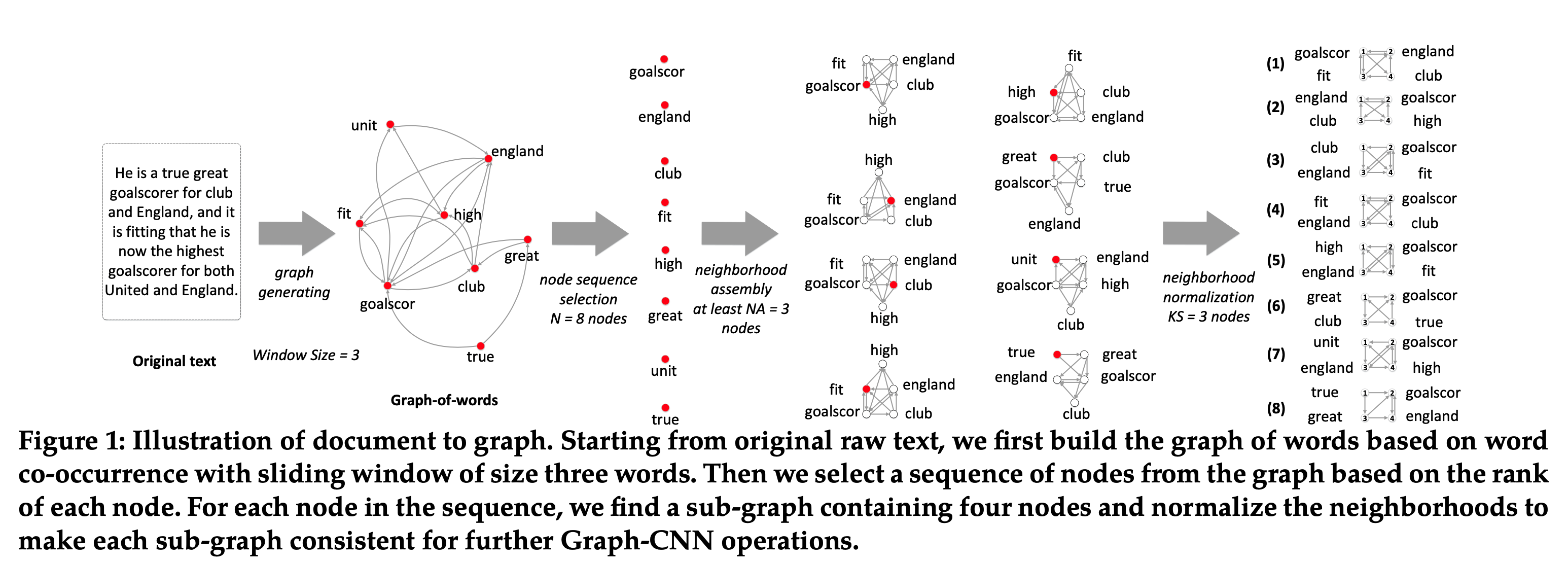
Graph-CNN[3]
将文档处理成图
将标签集定义为\(L=\{l_i|i=1,2,...,K\}\) ,K是标签数;由于是层级分类,标签有父子关系,因此将标签\(l_i^{(j)}(j=1,...,K_i)\) 表示成\(l_i\) 的孩子,其中\(K_i\) 为\(l_i\) 的孩子数;将训练集记作\(D=\{d_s,T_s\}_{s=1}^M\) ,其中M是实例数,\(d_s\) 是一个文档,\(T_s\) 是\(d_s\) 的标签集,且\(T_s\subseteq L\)
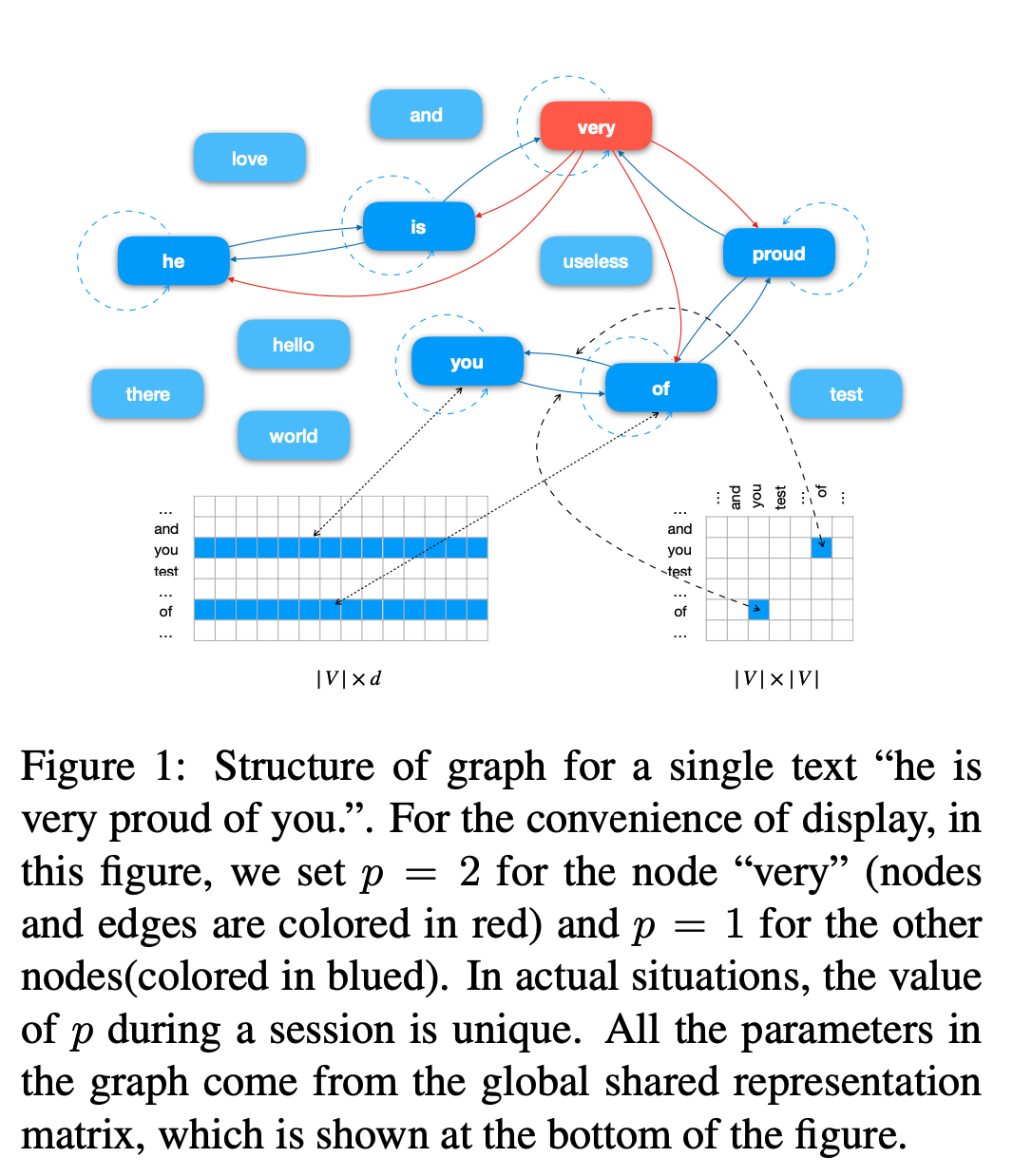
词共现图:将每个文档分成句子,然后再使用CoreNLP工具分成tokens,同时也使用CoreNLP获得每个token的stem;为了移除噪声,先移除由RCV1-v2提供的停用词,然后使用固定大小的滑动窗口计算词共现;如下图所示
在词共现图的子图上应用卷积mask;从词共现图上挖掘的n-grams的组合可以合成低级别语义,如子主题;通过进一步对卷积的输出进行卷积,可获得高级别语义,如超主题
需要选择和归一化所有潜在子图
对图中所有结点基于度排序,如果度相同,则按出现的次数,如果出现的次数相同,则按共现的次数;然后挑选N个最重要的结点(会影响主题分类);使用BFS算法来对每一个被选择的结点扩充它的子图;设置最小子图尺寸为g,若子图小于g,则继续扩充;这样会得到N个子图,每个都至少包含g个结点
子图归一化:需要为卷积mask获得结点顺序;结点的标记需要使得卷积在所有子图和文档上一致;一个最优的标记如下定义:假设图\(G\) 和\(G^{'}\) 都由g个结点,给定图\(G\) 的标记为s,可创建邻接矩阵\(A^s(G)\) ,那么最有标记则定义为\(s^{*}=argmin_{s}E[D_A(A^s(G),A^s(G^{'}))-D_G(G,G^{'})]\) ,其中\(D_A(·,·)\) 衡量两个矩阵的距离,如\(||A-A^{'}||_{L_1}\) ,\(D_G(·,·)\) 衡量两个图的距离,如图的编辑距离;但这样的标记是NP-hard,因此采用另外的标记方法。从根开始,即触发子图的结点,先遵循BFS使用深度来排序结点,若在同一深度则用度来排序,若度也相同,则用其他因子来打破深度,如上一步使用的边;这一步之后则每个子图都有g个结点
使用词嵌入作为输入
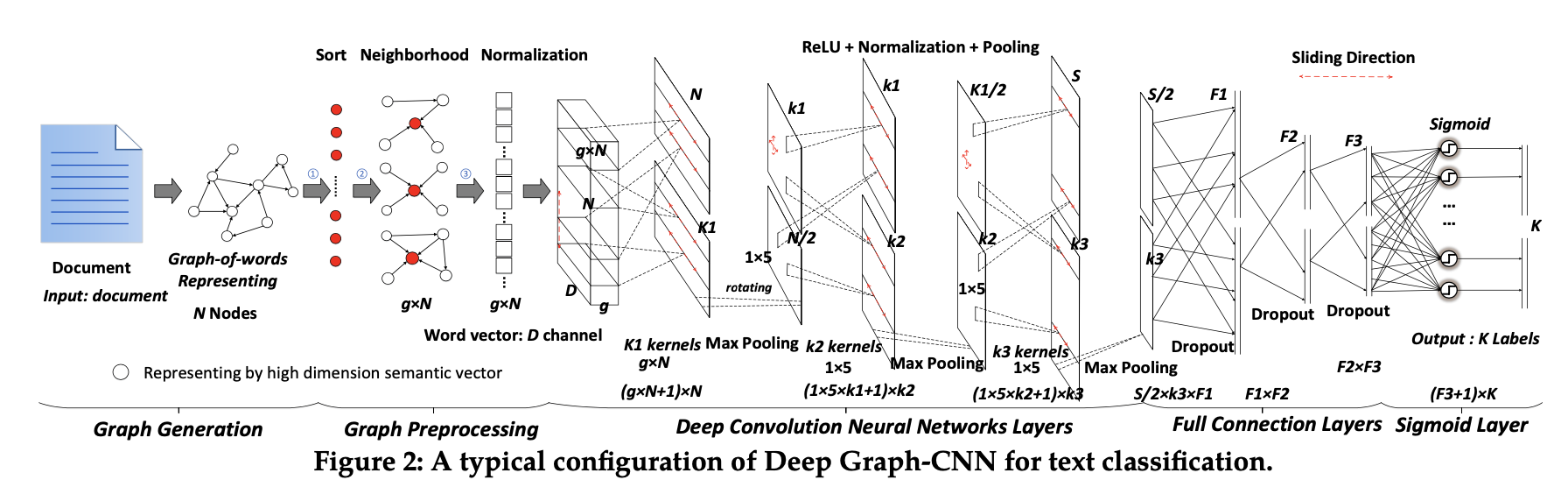
层级正则深度Graph-CNN,如下图所示:
第一个卷积层以\(N\times g\times D\) 为输入,N是被选择和归一化的子图数,g是感受野的大小,D是词嵌入维数;核尺寸为\(g\times D\) ,使用\(k_1\) 个核,可得到\(N\times k_1\) 矩阵
然后使用最大池化层,可得到\(N/2\times k_1\) 矩阵,表示挑选了一半能更好表示主题的子图
再使用\(k_2\) 个\(5\times 1\) 核,可得到\(k_1\times k_2\) 矩阵;此时已经对词嵌入的不同维数、子图中的不同词以及文档中的不同子图进行卷积
再使用最大池化得到\(k_1/2\times k_2\) 矩阵,然后是\(k_3\) 个尺寸为\(1\times 5\) 的核,滑动步为3,得到\(S\times k_3\) 矩阵;然后最大池化得到\(S/2\times k_3\) 矩阵
进入全连接层,同时添加dropout避免过拟合;dropout大致使收敛迭代次数增加了一倍,但它提高了网络的鲁棒性,提高了预测精度
最后一层与K个Sigmoid函数相连,分别对应层级中的K个标签;给定一组M个有标记的文档,模型优化交叉熵损失:\(H=-\sum_{m=1}^M\sum_{k=1}^Kl_k(d_m)logP_k(d_m)+(1-l_k(d_m))log(1-P_k(d_m))\)
递归正则:在层级中,父标签是子标签的超主题;引入标签间的依赖可以改善分类,因为当叶结点训练例子少时,决策可由其父正则
在最后全连接层上使用递归正则
作为一种简化,如果两个标签在层级中是相近的,那么标签之间的层级依赖关系鼓励标签的参数相似,即\(\lambda(\mathcal{W})=\sum_{l_i\in\mathcal{L}}\sum_{l_i^{(j)}}\frac{1}{2}||w_{l_i}-w_{l_i^{(j)}}||^2\)
最后的损失函数\(J=H+C\lambda(\mathcal{W})\)
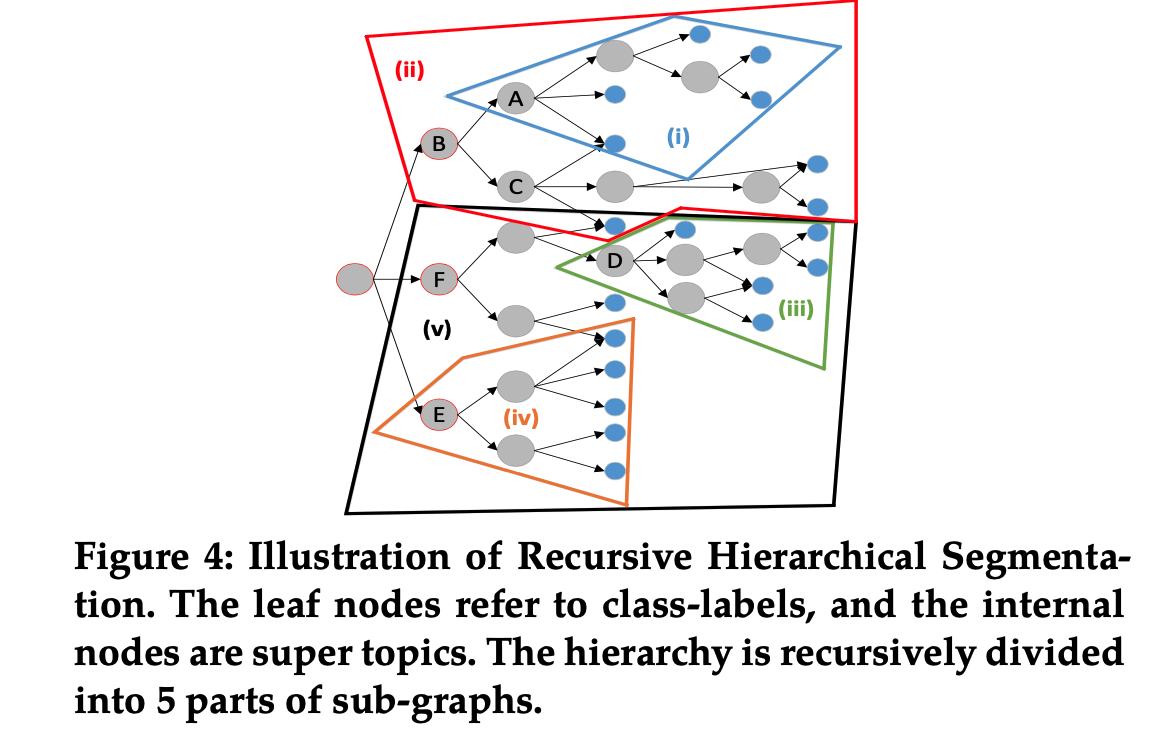
为了处理大规模标签层级,使用递归层级划分Segmentation来分治原始问题;如下图所示,假设每个子树至多包含5个叶子结点,然后执行深度优先和前序遍历:当遍历到A时,有5个叶结点,因此子树(i)先划分;然后子树(i)合成一个逻辑标签作为叶结点;当回溯到B时,孩子叶数目也是5,所以被划分成子树(ii)并合成叶结点;然后划分子树(iii)并合成叶结点
Text Level GNN[56]
文本图:将有\(l\) 个词的文本表示成\(T=\{\vec{r}_1,...,\vec{r}_i,...,\vec{r}_l\}\) ,\(\vec{r}_i\) 由d维词嵌入初始化,且在训练中更新;将文本中出现的所有词当作图结点,每条边从一个词出发,结束于它的邻接词;即\(N=\{\vec{r}_i|i\in [1,l]\},E=\{e_{ij}|i\in [1,l];j[i-p,i+p]\}\) ;如下图所示
将训练集中出现次数少于k次的边统一映射到一条“公共”边,使参数得到充分训练
与之前的方法相比,该方法大大减少图的规模;且其他方法对新来的文本不友好,该方法因其图只依赖它的内容而能解决这个问题
信息传递机制:利用非谱方法信息传递机制(MPM)来进行卷积
MPM先从邻接结点收集信息,然后基于自身原始表示和收集到的信息更新其表示,即\(M_n=max_{a\in N_n^p}e_{an}\vec{r}_a,\vec{r}_n^{'}=(1-\eta_n)M_n+\eta_n\vec{r}_n\)
预测文本的标签:\(y_i=softmax(ReLU(W\sum_{n\in N_i}\vec{r}_n^{'}+b))\)
交叉熵损失\(loss=-g_ilogy_i\) ,\(g_i\) 是one-hot向量
HyperCore[6]
疾病的国际分类ICD;ICD编码旨在将合适的ICD码分配给一个医学记录
手动编码费力又容易出错,寻求自动编码;但现有方法独立预测每个码,忽略两个重要特征:码层级和码共现
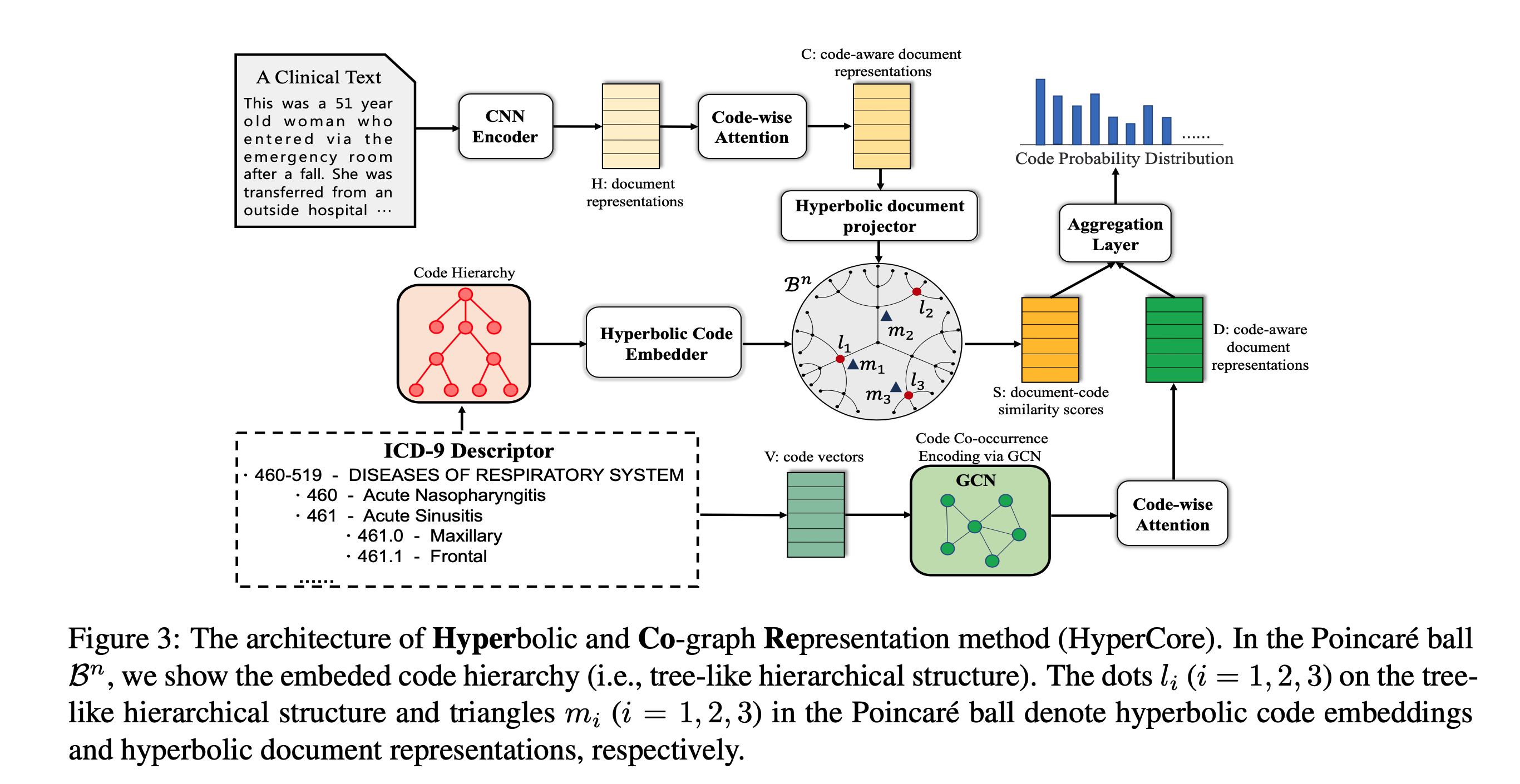
提出双曲和Co-graph表示方法:双曲表示方法利用码层级,GCN利用码共现;如下图所示。文档可表示成\(X=\{\vec{x}_1,\vec{x}_2,...,\vec{x}_N\}\) ,利用CNN编码文本(高效计算): \(\vec{h}_i=tanh(W_c*\vec{x}_{i:i+k-1}+b_c)\) ,k是filter的大小,可获得文档表示\(H=\{\vec{h}_1,\vec{h}_2,...,\vec{h}_N\}\) 。Code-wise注意力(由于需要为每个文档指派多个码且不同码关注文档的不同部分):先为每个码生成码向量,即平均其描述的词嵌入:\(\vec{v}_i=\frac{1}{N_d}\sum_{j=1}^{N_d}\vec{w}_j,i=1,...,L\) ,其中L是数据集中总共的码数目;然后生成code-wise注意力向量,即\(\vec{\alpha}_i=softmax(H^T\vec{v}_i)\) ,最后使用文档表示H和注意力向量\(\vec{\alpha}_i\) 生成码感知文档表示\(\vec{c}_i=H\vec{\alpha}_i\) ,连接\(\vec{c}_i,i=1,...,L\) 得到码感知文档表示,即\(C=\{\vec{c}_1,\vec{c}_2,...,\vec{c}_L\}\in R^{d_c\times L}\)
学习码双曲表示,衡量文档和码在双曲空间的相似性
双曲几何是非欧几何,研究常负曲率空间;基于Poincare ́ ball模型;让\(\mathcal{B}^n=\{\vec{x}\in R^n|||\vec{x}||<1\}\) 是开放n维单位球;Poincare ́ ball\((\mathcal{B}^n,g_{\vec{x}})\) 由Riemannian流形定义,即开放单位球具有黎曼度量张量,\(g_{\vec{x}}=(\frac{2}{1-||\vec{x}||^2})^2g^E\) ,\(g^E\) 表示欧式度量张量;两个点\(\vec{u},\vec{v}\in \mathcal{B}^n\) 之间的距离为\(d(\vec{u},\vec{v})=arcosh(1+2\frac{||\vec{u}-\vec{v}||^2}{(1-||\vec{u}||^2)(1-||\vec{v}||^2)})\) ,其中\(arcosh\) 是逆双曲余弦函数,即\(arcosh(x)=ln(x+\sqrt{(x^2-1)})\) ;当考虑原点O时,当两点\(\vec{u},\vec{v}\) 向球当外侧移动,即\(||\vec{u}||,||\vec{v}||\to 1\) ,则\(d(\vec{u},\vec{v})\) 倾向于\(d(\vec{u},O)+d(\vec{v},O)\) ,即两点间的路径会收敛于到一条通过原点的路径,可以看作是一个树状的层次结构
双曲空间的树状结构使其很自然地去嵌入层次结构;通过在Poincare ́ ball中嵌入码层级,顶部的码靠近原点,底部的码靠近边界;嵌入范数表示层次中的深度,嵌入之间的距离表示相似性;\(D=\{(l_p,l_q)\}\) 是码对之间父子关系的集合,\(\Theta=\{\vec{\theta}_i\}_{i=1}^T,\vec{\theta}_i\in \mathcal{B}^{d_p}\) 是对应的码嵌入集合,T是所有ICD码的数目;让相关的码靠的更近,最小化以下损失函数来得到码双曲表示:\(\mathcal{J}(\Theta)=-\sum_{(l_p,l_q)\in D}log\frac{exp(-d(\vec{\theta}_p,\vec{\theta}_q))}{\sum_{l_{q^{'}}\in N(l_p)}exp(-d(\vec{\theta}_p,\vec{\theta}_{q^{'}})}\) ,其中\(N(l_p)=\{l_{q^{'}}|(l_p,l_{q^{'}})\notin D\}\cup \{l_p\}\) ;将双曲码表示定义为\(\Theta_L=\{\vec{\theta}_i\}_{i=1}^L\)
需要将码感知文档表示映射到双曲空间:使用重参数技术来执行;需要计算一个方向向量\(\vec{r}\) 和一个范数幅度\(eta\) ,即\(\overline{\vec{r}}_i=\Phi_{dir}(\vec{c}_i),\vec{r}_i==\frac{\overline{\vec{r}}_i}{||\overline{\vec{r}}_i||},\overline{\eta}_i=\Phi_{norm}(\vec{c}_i),\eta_i=\sigma(\overline{\eta}_i)\) ,其中\(\Phi_{dir}:R^{d_c}\to R^{d_p}\) 是方向函数,参数化它为一个多层感知机MLP,\(\Phi_{norm}:R^{d_c}\to R\) 是范数幅度函数,使用线性层来执行,\(\sigma\) 是sigmoid函数,确保结果范数\(\eta_i\in (0,1)\) ;重参数的文档表示被定义为\(\vec{m}_i=\eta_i\vec{r}_i\)
计算文档-码相似性:使用双曲距离函数来建模文档和码之间的关系,即\(score_i=d(\vec{m}_i,\vec{\theta}_i),S=[score_1;score_2;...;score_L]\) ,得到\(S\in R^L\) 是文档-码相似性分数
利用GCN学习码共现表示,将它们作为查询向量获得码感知文档表示
码Co-graph创建:有L个结点的图,如果第i个码和第j个码共现在同一文本中,它们之间就有一条边,使用共现次数作为边权重
GCN的输入是初始码向量和邻接矩阵,\(H^{(l+1)}=\rho(\tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}}H^{(l)}W^{(l)})\) ;然后使用code-wise注意力来获得码感知文档表示,即\(D=\{\vec{d}_1,\vec{d}_2,...,\vec{d}_L\}\) ;使用平均+最大池化:每个词都在文本中起作用,关键词会贡献更多
最后将文档-码相似性分数和码感知文档表示聚合来预测码
\(U=\lambda W_SS+D^TW_d,U\in \{u_1,u_2,...,u_L\}\in R^L\) 是最后的文档表示每个码的预测:\(\hat{y}_i=\sigma(u_i),i=1,...,L\)
使用多标签的二元交叉熵损失\(\mathcal{L}=\sum_{i=1}^L[-y_ilog(\hat{y}_i)-(1-y_i)log(1-\hat{y}_i)]\)
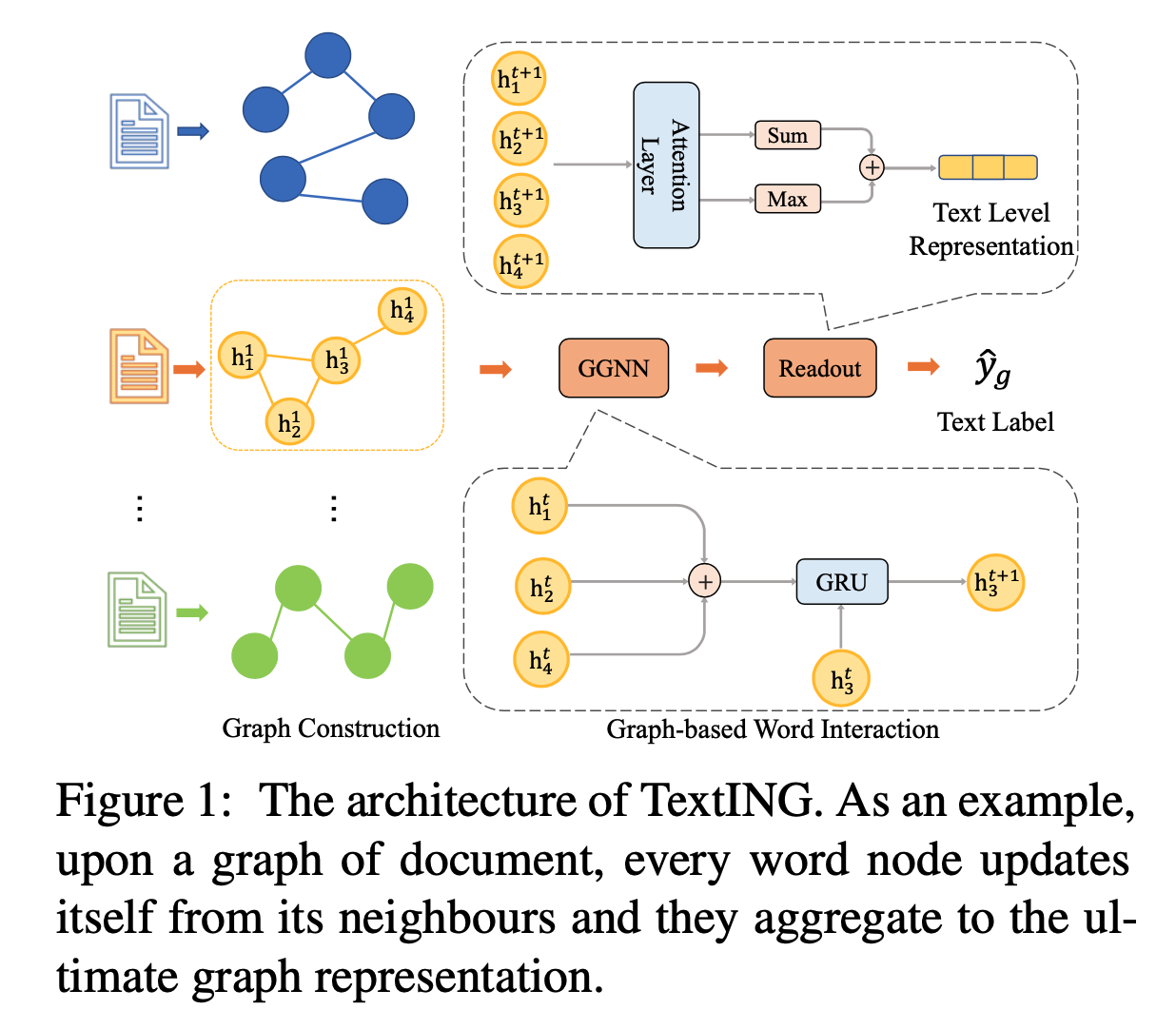
TextING[7]
现有的基于图的方法既不能捕获一个文档中上下文词的关系,也不能满足新词的归纳学习
提出TextING:为每个文档构建单独的图,然后使用GNN学习精细化词表示;如下图所示:
图创建:将不同的词作为结点,词之间的共现作为边,即\(\mathcal{G}=(\mathcal{V},\mathcal{E})\) ;共现指的是出现在一个固定大小滑动窗口内的词之间的关系
基于图的词交互:使用Gated GNN;\(a^t=Ah^{t-1}W_a,z^t=\sigma(W_za^t,U_zh^{t-1}+b_z),r^t=\sigma(W_ra^t,U_rh^{t-1}+b_r),\tilde{h}^t=tanh(W_ha^t+U_h(r^t\bigodot h^{t-1})+b_h),h^t=\tilde{h}^t\bigodot z^t+h^{t-1}\bigodot (1-z^t)\) ;z和r是更新门和重置门来决定邻居信息对当前结点嵌入的贡献
需要将词结点聚合成图级别表示,定义readout函数为\(h_v=\sigma(f_1(h_v^t))\bigodot tanh(f_2(h_v^t)),h_{\mathcal{G}}=\frac{1}{|\mathcal{V}|}\sum_{v\in \mathcal{V}}h_v+Maxpooling(h_1,...,h_{\mathcal{V}})\) ;其中\(f_1,f_2\) 是MLP,前者作用是软注意力权重,后者是非线性特征变换
\(\hat{y}_{\mathcal{G}}=softmax(Wh_{\mathcal{G}}+b),\mathcal{L}=-\sum_{i}y_{\mathcal{G}_i}log(\hat{y}_{\mathcal{G}_i})\)
扩展模型为multichannel branch TextING-M,具有局部结构的图(原始TextING)和具有全局结构的图(来自TextGCN的子图);结点不变,后者的边从大图(建立于整个语料库之上)中提取;分开训练,以1:1投票决定最后的预测
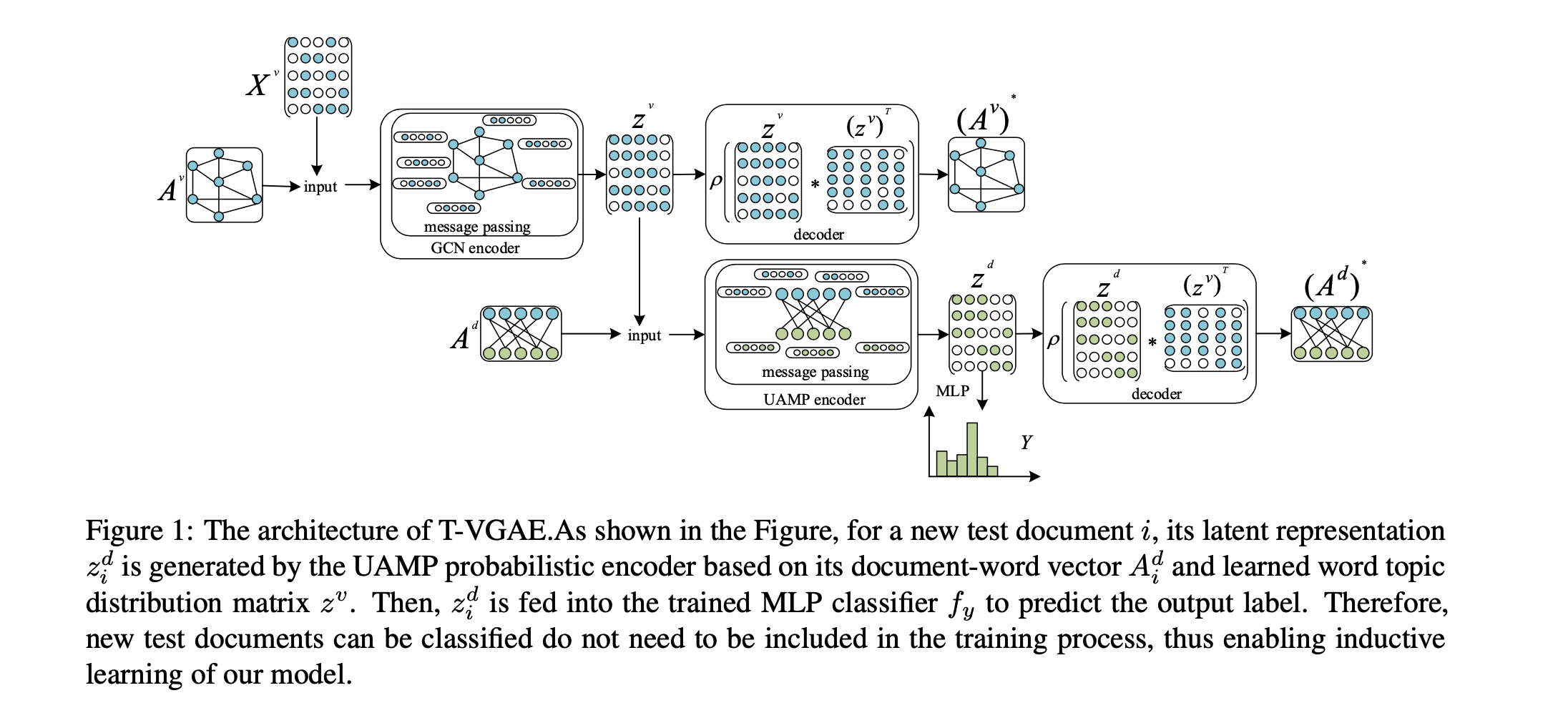
T-VGAE[57]
图创建:语料库为C,包含D个文档,ground truth标签\(Y\in c=\{1,...,M\}\) ,共有M类;每个文档\(t\in C\) 被表示成一系列词\(t=\{w_1,w_2,...,w_{n_t}\}\) ,v是词汇,大小为V
建立词关系图,\(G=(v,e)\) ,捕获词共现信息,使用正的PMI(PPMI) 来计算两个词结点之间的关系,即\(PPMI(w_i,w_j)=max(log\frac{p(w_i,w_j)}{p(w_i)p(w_j)},0)\)
与将所有文档和词考虑在一个异质图中不同,提出为每一个文档建立单独的图可以进行归纳学习,然后将文档表示成一个文档-词矩阵\(A^d\in R^{D\times V},A_i^d=\{x_{i1},...,x_{iv}\}\in R^{1\times V}\) ,其中\(x_{ij}\) 是词j在文档i中的TF-IDF权重,将文档从一个全局预定义图中解耦可处理新文档
主题变分图自编码机,如下图所示:
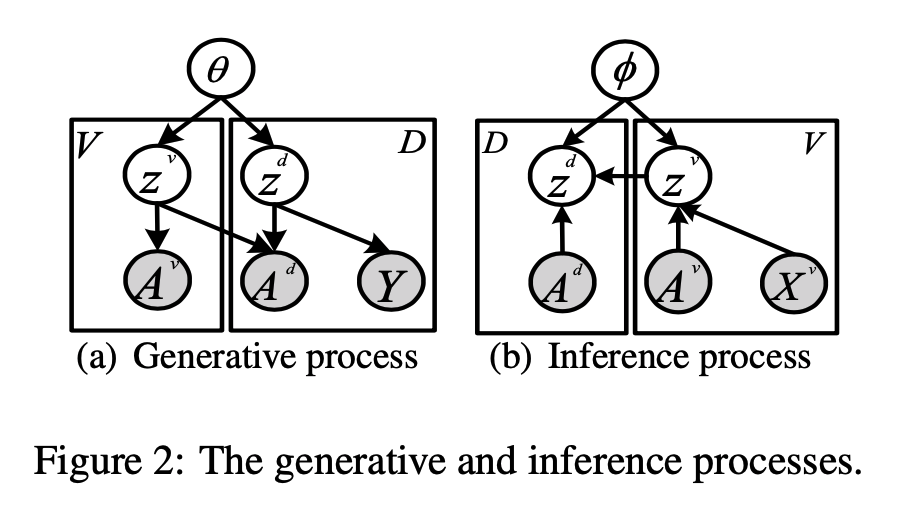
基于GCN的带结构隐含变量的深度生成模型:考虑文档t的词共现图\(A^v\) 和二部图\(A_t^d\) 是从具有两个隐含变量\(z^v\in R^{V\times K},z_t^d\in R^{1\times K}\) 的随机过程中生成的,K表示隐含主题数;生成过程如下图;对于词汇v中的词i,从先验\(p_{\theta}(z_i^v)\) 中得到隐含变量\(z_i^v\) ;对于每个观测到的边\(A_{ij}^v\) ,从条件概率\(p_{\theta}(A_{ij}^v|z_i^v,z_j^v)\) 得到\(A_{ij}^v\) ;对于每个文档t,先从先验\(p_{\theta}(z_t^d)\) 中得到隐含变量\(z_t^d\) ,然后从条件概率\(p_{\theta}(A_t^d|z_t^d,z^v)\) 得到\(A_t^d\) ,最后从条件概率\(p_{\theta}(Y_t|z_t^d)\) 得到\(Y_t\) ;\(\theta\) 是所有先验分布的参数集,这里考虑中心各向同性多变量高斯先验:\(p(z^v)=\prod_{i=1}^Vp(z_i^v)=\prod_{i=1}^VN(z_i^v|0,I),p(z^d)=\prod_{t=1}^Dp(z_t^d)=\prod_{t=1}^DN(z_t^d|0,I)\) ;最大化似然\(p(A^v,A^d,Y|Z^v,Z^d,X^v)=\prod_{t=1}^Dp_{\theta}(Y_t|z_t^d)p_{\theta}(A_t^d|z_t^d,z^v)p_{\theta}(z_t^d)\prod_{i=1}^V\prod_{j=1}^Vp_{\theta}(A_{ij}^v|z_i^v(z_j^v)^T)p_{\theta}(z^v)\) 来学习参数和隐含变量;由于\(z^v,z^d\) 的真实后验的推断不可求,引入变分后验分布\(q_{\phi}(z^v,z^d|A^v,A^d,X^v)\) 来估计真实后验\(p_{\theta}(z^v,z^d)=p_{\theta}(z^v)p_{\theta}(z^d)\) ;作出structured mean-field (SMF)假设,即\(q_{\phi}(z^v,z^d|A^v,A^d,X^v)=q_{\phi}(z^v|A^v,X^v)q_{\phi}(z^d|A^d,z^v)\) ,其中\(X^v\in R^{V\times M}\) 是词特征向量,可得到以下可求的ELBO:\(\mathcal{L}(\theta,\phi;A^v,A^d,X^v)=E_{q_{\phi}(z^v|A^v,X^v)}[logp_{\theta}(A^v|z^v)]+E_{q_{\phi}(z^d|A^d,z^v)}[logp_{\theta}(A^d|z^d,z^v)]+E_{q_{\phi}(z^d|A^d,z^v)}[logp_{\theta}(Y|z^d)]-KL[q_{\phi}(z^v|A^v,X^v)||p_{\theta}(z^v)]-KL[q_{\phi}(z^d|A^d,z^v)||p_{\theta}(z^d)]\) ,其中前三项是重建项;使用自编码变分贝叶斯(AVB)可用基于GCN的概率编码器和解码器参数化变分后验\(q_{\phi}\) 和真实后验\(p_{\theta}\) ,从而执行神经变分推断(NVI)
图卷积概率编码器:对于隐含变量\(z^v\) ,做mean-field近似,即\(q_{\phi}(z^v|A^v,X^v)=\prod_{i=1}^Vq_{\phi}(z_i^v|A^v,X^v)\) ,其中\(q_{\phi}(z_i^v|A^v,X^v)=N(z_i^v|\mu_i^v,diag((\sigma_i^v)^2))\)
GCN参数化:\((H^v)^{l+1}=\rho(\hat{A}^v(H^v)^{l}(W^v)^{l}),\mu^v=\rho(\hat{A}^v(H^v)^{l+1}(W_{\mu}^v)^{l+1}),log\sigma^v==\rho(\hat{A}^v(H^v)^{l+1}(W_{\sigma}^v)^{l+1})\) ;\(X^v\) 被初始化为单位矩阵
\(z^v\) 可根据重参数采样:\(z^v=\mu^v+\sigma^v\bigodot \epsilon,\epsilon\sim N(0,I)\) ,\(\epsilon\) 是噪声变量\(z^t\) 类似\(z^v\) ;虽然二部图\(A^d\) 中有两类结点,但我们关注基于词结点表示(从\(A^v\) 中学习)学习文档结点表示;提出单方向信息传递(UDMP)过程,从词将信息传播到文档:\(H_t^d=\rho(\sum_{i=1}^VA_{ti}^dz_i^vW^d)\) ;然后参数化后验并基于UDMP推断\(z^d\) : \(\mu^d=UDMP(A^d,z^v,W_{\mu}^d),log\sigma^d=UDMP(A^d,z^v,W_{\sigma}^d)\) 旨在结合VGAE和主题模型,改进具有隐含主题语义的词和文档表示,并提供概率解释能力
概率解码器
\(P_{\theta}(A^v|z^v)=\prod_{i=1}^Vp_{\theta}(A_i^v|z^v),p_{\theta}(A_i^v|z^v)=\prod_{i=1}^VN(A_i^v|\rho(z_i^v(z^v)^T),I)\) \(P_{\theta}(A^d|z^d,z^v)=\prod_{i=1}^Dp_{\theta}(A_i^d|z_i^d,z^v),p_{\theta}(A_i^d|z_i^d,z^v)=\prod_{i=1}^DN(A_i^d|\rho(z_i^d(z^v)^T),I)\) 假设\(P_{\theta}(Y|z^d)\) 服从多项式分布,\(P_{\theta}(Y|z^d)=Mul(Y|f_y(z^d))\) ,标签概率向量由\(z^d\) 生成,\(f_y\) 是多层神经网络;对于每一个文档t,预测由\(\hat{y}_t=argmax_{y\in c}P_{\theta}(y|f_y(z_t^d))\) 给出
优化:最大化变分目标函数 \(\mathcal{L}(\theta,\phi) \approx \sum_{i=1}^V\sum_{j=1}^Vlogp_{\theta}(A_{ij}^v|z_i^v,z_j^v)+\sum_{t=1}^D(logp_{\theta}(A_t^d|z_t^d,z^v)+logp_{\theta}(Y_t|z_t^d))-KL[q_{\phi}(z^v)||p_{\theta}(z^v)]-KL[q_{\phi}(z^d)||p_{\theta}(z^d)]\) ,其中\(logp_{\theta}(A_{i}^v|z^v)\approx ||A_{i}^v-\rho(z_i^v(z^v)^T)||^2,logp_{\theta}(A_t^d|z_t^d,z^v)\approx ||A_t^d-\rho(z_t^d(z^v)^T)||^2,logp_{\theta}(Y_t|z_t^d)\approx Y_tlog\hat{y}_t+(1-Y_t)log(1-\hat{y}_t),KL[q_{\phi}(z_i^v)||p_{\theta}(z_i^v)]\approx \frac{1}{2}\sum_{j=1}^V((\mu_{ij}^v)^2+(\sigma_{ij}^v)^2-(1+log(\sigma_{ij}^v)^2)),KL[q_{\phi}(z_t^d)||p_{\theta}(z_t^d)]\approx \frac{1}{2}\sum_{j=1}^V((\mu_{tj}^d)^2+(\sigma_{tj}^d)^2-(1+log(\sigma_{tj}^d)^2))\)
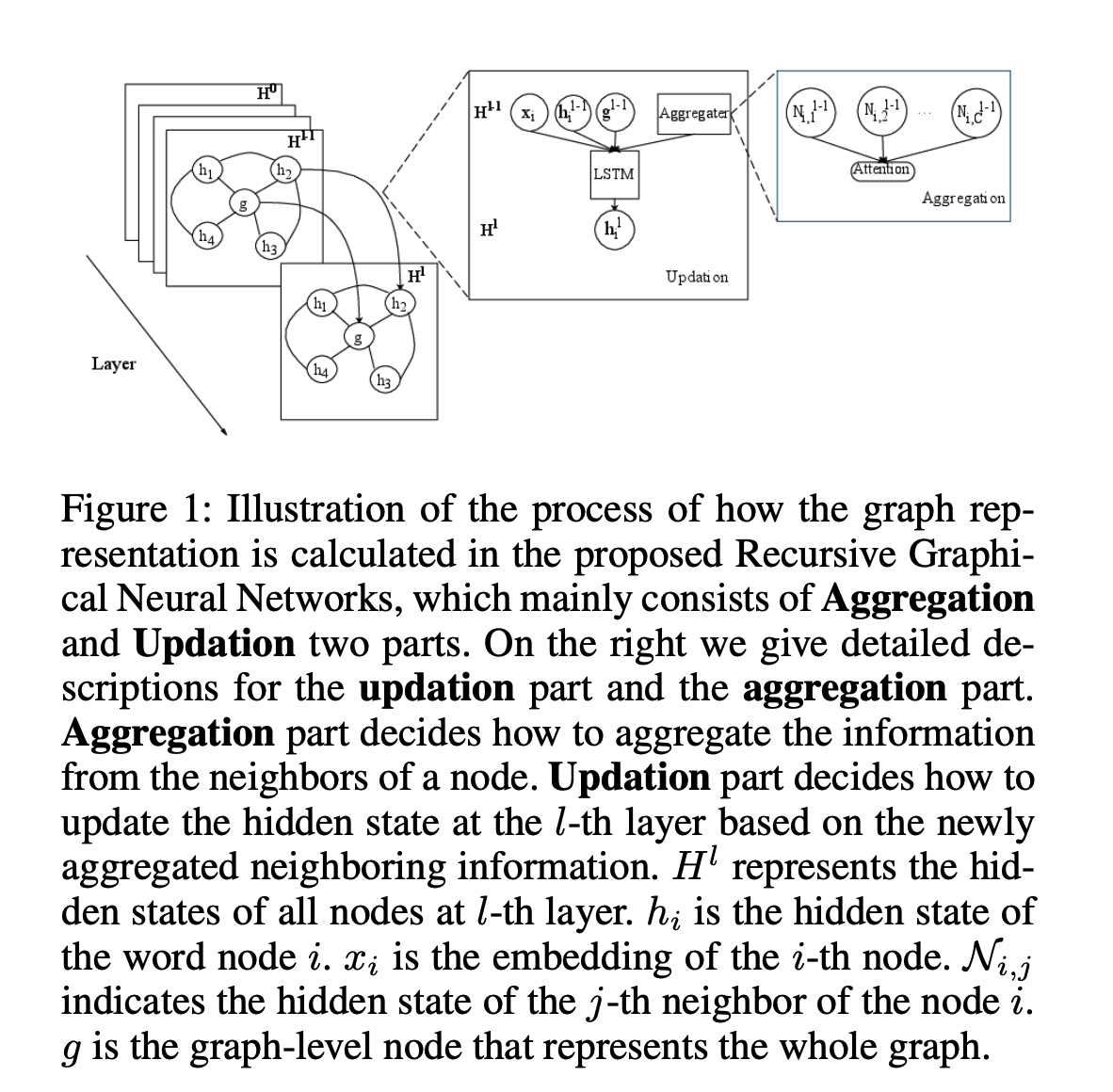
ReGNN[58]
文本图创建:基于词共现信息
文本创建不局限于词共现信息,其他方法如依赖解析也可使用
若文本包含多个句子,使用NLTK将文本划分成句子,并对句子进行分词;若句子结构未知,可使用滑动窗口来提取结构
给定一个文本span s(句子或在一个滑动窗口内的文本),具有m个词,每个词都是句子图结点;PMI用于决定两个点是否有边,基于语料库中的所有文本计算词共现(若两个词出现在同一个句子中,则它们的共现次数加1);为了进一步捕获词的局部上下文,词\(w_i\) 的直接邻居\(w_{i-1}\) 和\(w_{i+1}\) 也和词\(w_i\) 相连;最后只有\(w_i\) 的两个直接邻居和至多n-2个PMI值最高的词是\(w_i\) 的真正邻居
递归GNN:给定一个文本图,包含m个结点,不仅需要学习每个结点的表示,还需要学习整个图的表示g;如下图所示:
更新:循环结构被逐层应用,与Gated GNN一样,即\(H^l=<h_1^l,h_2^l,...,h_m^l,g^l>\) ,其中\(g^l\) 是图级别结点表示;对于初始状态\(H^0\) ,结点的隐含状态为设置为嵌入,即\(h_i^0=x_i\) ;具体变换为: \(i_i^l=\sigma(W_i[h_i^{l-1};x_i;g^{l-1};N_i^{l-1}]+b_i),f_i^l=\sigma(W_f[h_i^{l-1};x_i;g^{l-1};N_i^{l-1}]+b_f),o_i^l=\sigma(W_o[h_i^{l-1};x_i;g^{l-1};N_i^{l-1}]+b_o),u=tanh(W_u[h_i^{l-1};x_i;g^{l-1};N_i^{l-1}]+b_u),c_i^l=f_i^l\bigodot c_i^{l-1}+i_i^{l-1}\bigodot u,h_i^l=o_i^l\bigodot tanh(c_i^l)\) ,其中\([;;]\) 表示连接,每一层使用\(x_i\) 是为了使用词的原始意义,和残差连接的作用相似;通过使用g,网络可建模每个词和整个图的交互,使其能更好地关注重要信息
聚合:与S-LSTM只考虑直接的左右邻居不同,该模型考虑了灵活的邻居数;使用加注意力聚合邻居信息;假设\(w_i\) 有\(C_i\) 个邻居,\(w_i\) 的邻居的隐含表示\(N_i\) 如下计算:\(\mathcal{P}_i=h_i+p_i,\alpha_j=u(W_n[\mathcal{P}_i;x_i;g;\mathcal{P}_j]+b_n),score_j=\frac{exp(\alpha_j)}{\sum_{k}^{C_i}exp(\alpha_k)},N_i=\sum_{k}^{C_i}score_kh_{i_k}\) ,其中\(p_i\) 为位置嵌入,\(h_{i_k}\) 是\(w_i\) 的第k个邻居的隐含状态;若图不是由文本序列构造的,则不需要位置嵌入。LSTM和基于注意力的聚合的结合使得模型能够随着层数的增加从更长的依赖关系中收集信息,同时确定哪些信息有用并传递给更高的层
图级别结点:\(g^l\) 的值由上一层的隐含状态\(H^{l-1}\) 计算;先通过在词序列上计算注意力来计算\(\overline{h}^{l-1}\) ,即\(\alpha_i=u(W_ah_i),score_i=\frac{exp(\alpha_i)}{\sum_jexp(\alpha_j)},\overline{h}=\sum_jscore_jh_j\) ;然后对于每个\(h_i^{l-1}\) ,门\(f_i^{l}\) 被计算用于确定哪些信息应被图级别向量\(g^l\) 考虑,候选状态\(c_g^l\) 基于上一层的候选图状态\(c_g^{l-1}\) 和上一层的结点候选状态\(c_i^{l-1}\) 被计算;\(\hat{f}_g^l=\sigma(W_g[g^{l-1};\overline{h}^{l-1}]+b_g),\hat{f}_i^l=\sigma(W_f[g^{l-1};h_i^{l-1}]+b_f),o^l=\sigma(W_o[g^{l-1};\overline{h}^{l-1}]+b_o),f_0^l,...,f_m^l,f_g^l=softmax(\hat{f}_0^l,...,\hat{f}_m^l,\hat{f}_g^l),c_g^l=f_g^l\bigodot c_g^{l-1}+\sum_if_i^l\bigodot c_i^{l-1},g^l=o^l\bigodot tanh(c_g^l)\)
与线性LSTM(包括双向版本)比较:线性LSTM理论上的时间复杂度为\(O(N)\) ,N是输入序列长度;若内存足够大,则模型可以一次处理整张图,则理论上的时间复杂度为\(O(1)\) ,精确时间依赖于层数(隐含状态的计算只需要上一层的隐含状态,同一层结点的隐含状态可并发计算),这是个常数。在线性LSTM中有bias问题,而ReGNN中的图级别结点可和其他普通结点交互
和Transformer和GAT比较:Transformer的核心思想是使用注意力来建立当前token和其上下文的联系,该模型也使用注意力机制来学习上下文信息,但Transformer用于线性结构数据,ReGNN用于图结构数据,只有当图是全连接时Transformer可被应用,但会带来许多噪音;GAT是相似的,但它没有特殊的设计来预防过平滑问题,且没有涉及图级别结点
文本分类器
对于单标签任务,应用线性层来预测标签y,基于图级别向量\(g^L\) ,L是层数,即\(y=argmax(W_{out}g^L)\)
对于多标签任务,使用RNN解码器,具有注意力机制,可生成不同数目的标签而不用调阈值超参数
给定初始状态\(t_0\) (即\(g^L\) )和每个结点向量\(<h_1^L,h_2^L,...,h_m^L>\) ,解码器被限制生成标签序列\(y_1,y_2,...,y_k\) ,在每个解码步,上下文向量\(c_i\) 通过计算结点向量的注意力被计算;\(y_i=argmax(W_{out}t_i),t_i=LSTM(t_{i-1},Ey_{i-1}),c_i=\sum\alpha_j\times h_j^L,\alpha_j=\frac{exp(\delta(t_i,h_j^L))}{\sum exp(\delta(t_i,h_k^L))}\) ,其中\(\delta\) 是注意力函数,和被加到标签序列的头尾,当模型遇到toekn,生成过程结束
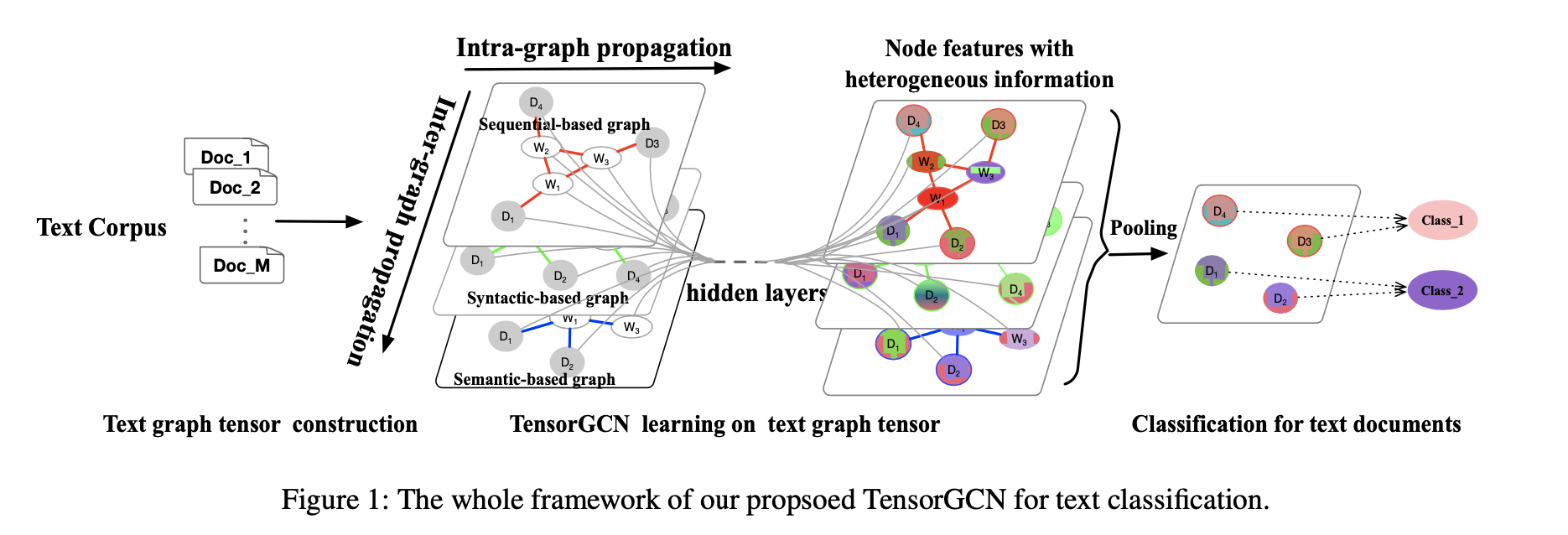
TensorGCN[59]
图张量定义:想利用一系列的图来充分调查感兴趣的数据(例如文本文档),不同的图代表了数据的不同属性。所有这些图都被压缩成一个图张量,即图张量由多个图组成,它们共享结点;\(\mathcal{G}=(G_1,...,G_r),G_i=(V_i,E_i,A_i),|V_i|=n,V_i=V_j,A_i\neq A_j\) 是一个图张量;将所有邻接矩阵压缩成一个图邻接张量,即\(\mathcal{A}=(A_1,...,A_r)\in R^{r\times n\times n}\) ;图特征矩阵被压缩成一个图特征张量,即\(\mathcal{H}^{(l)}=(H_1^{(l)},...,H_r^{(l)})\in R^{r\times n\times d_l}\)
文本图张量创建
从文本创建图最直接的方式是将词和文档当作结点,考虑词-文档边和词-词边,前者权重由TF-IDF确定,后者考虑三种不同语言属性:语义信息、句法依赖和局部序列上下文;基于不同的词-词边,可创建一系列文本图来描述文本文档
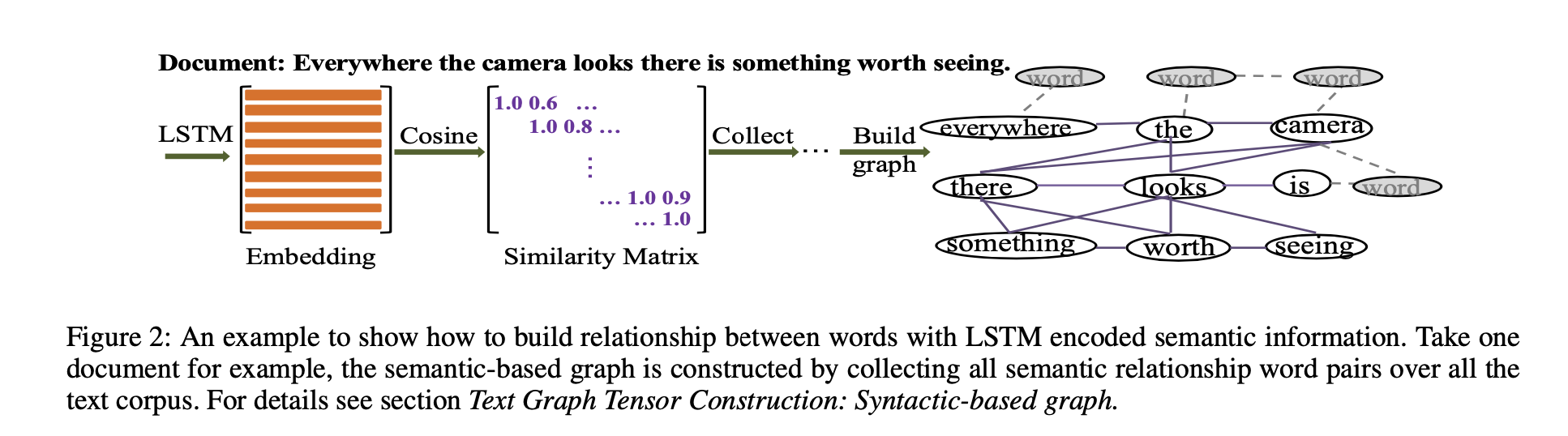
基于语义的图:基于LSTM的方法来创建基于语义的图,如下图所示;需要三步;第一步,在训练数据上训练LSTM;第二步,为每个文档/句子中的所有词得到LSTM语义特征/嵌入;第三步,基于词语义嵌入计算词-词边权重;对于每个文档/句子,计算词嵌入的余弦相似度,若超过某个预定义的阈值\(\rho_{sem}\) ,意味着这两个词在该文档/句子中有语义关系,在整个语料库中统计词对出现语义关系的次数;每个词对的边权重:\(d_{semantic}(w_i,w_j)=\frac{\text{#}N_{semantic}(w_i,w_j)}{\text{#}N_{total}(w_i,w_j)}\) ,\(\text{#}N_{semantic}(w_i,w_j)\) 表示在所有文档/句子上两个词有语义关系的次数,\(\text{#}N_{total}(w_i,w_j)\) 表示两个词存在于同一文档/句子的次数
基于句法的图:对于每个文档/句子,先利用Stanford CoreNLP parser来提取词之间的依赖;由于提取的依赖是有向的,为了简化,当作是无向的;与语义图中使用的策略类似,在整个语料库上统计词对有句法依赖的次数;每个词对的边权重:\(d_{syntactic}(w_i,w_j)=\frac{\text{#}N_{syntactic}(w_i,w_j)}{\text{#}N_{total}(w_i,w_j)}\) ,\(\text{#}N_{syntactic}(w_i,w_j)\) 表示在所有文档/句子上两个词有句法依赖关系的次数,\(\text{#}N_{total}(w_i,w_j)\) 表示两个词存在于同一文档/句子的次数
基于序列的图:序列上下文描述局部共现语言属性;使用PMI和滑动窗口策略来描述序列上下文信息;每个词对的边权重:\(d_{sequential}(w_i,w_j)=log\frac{p(w_i,w_j)}{p(w_i)p(w_j)},p(w_i,w_j)=\frac{\text{#}N_{co-occurrence}(w_i,w_j)}{\text{#}N_{windows}}\) ,\(\text{#}N_{windows}\) 是整个语料库上滑动窗口数目
图张量学习
初步模型:融合边+GCN
池化邻接矩阵: \(pooling(\mathcal{A})=pooling(A_1,...,A_r)\) ,如最大池化或平均池化;但一系列的初步实验表明这些池化都不起作用,由于这些图非常异质,来自不同图的边权重不匹配;因此使用逐边注意力策略来融合边权重,即\(A_{merge}=pooling(\mathcal{A})=\sum_{i=1}^rW_{edge}^i\bigodot A_i\)
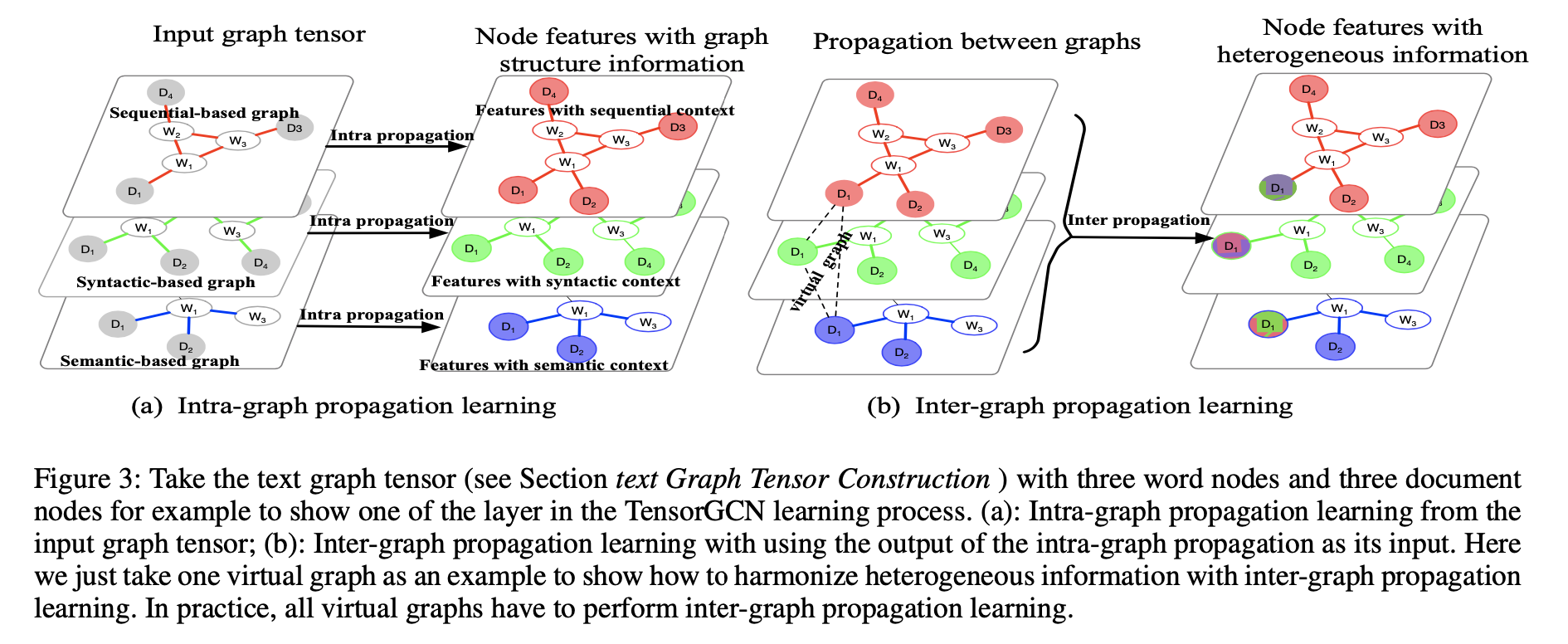
TensorGCN模型: 对于该模型的每一层,执行两种传播学习,一是图内intra-graph传播,二是图间inter-graph传播,即\(\mathcal{H}^{(l)}\underrightarrow{f_{intra}} \mathcal{H}_{intra}^{(l)}\underrightarrow{f_{inter}}\mathcal{H}^{(l+1)}\) ,\(\mathcal{H}^{(l)}\in R^{r\times n \times d_l}\) ;如下图所示
图内传播学习:每张图执行GCN学习,即\(\mathcal{H}_{intra}^{(l)}(i,:,:)=\sigma(\hat{\mathcal{A}}(i,:,:)\mathcal{H}^{(l)}(i,:,:)W_{intra}^{(l,i)})\)
图间传播学习:创建一系列特殊的图,称作虚拟图,让每一张图中的对应结点相互连接,这样可以得到n张虚拟图,形成一个新的图邻接张量\(\mathcal{A}^{+}\in R^{r\times r\times n}\) ,权重都是1;\(f_{inter}\) 如下执行:\(\mathcal{H}^{(l+1)}(:,j,:)=\sigma(\mathcal{A}^{+}(:,:,j)\mathcal{H}_{intra}^{(l)}(:,j,:)W_{inter}^{(l,j)})\) ,这里的\(\mathcal{A}^{+}(:,:,j)\) 既不做对称归一化也不加自环,首先前者没必要,因为边权重都设置为1,后者目的是使异质信息更有效地融合在一起;最后在多张图上执行平均池化,得到文档结点的最终表示用于分类,如下图所示:
Hi-AGM[60]
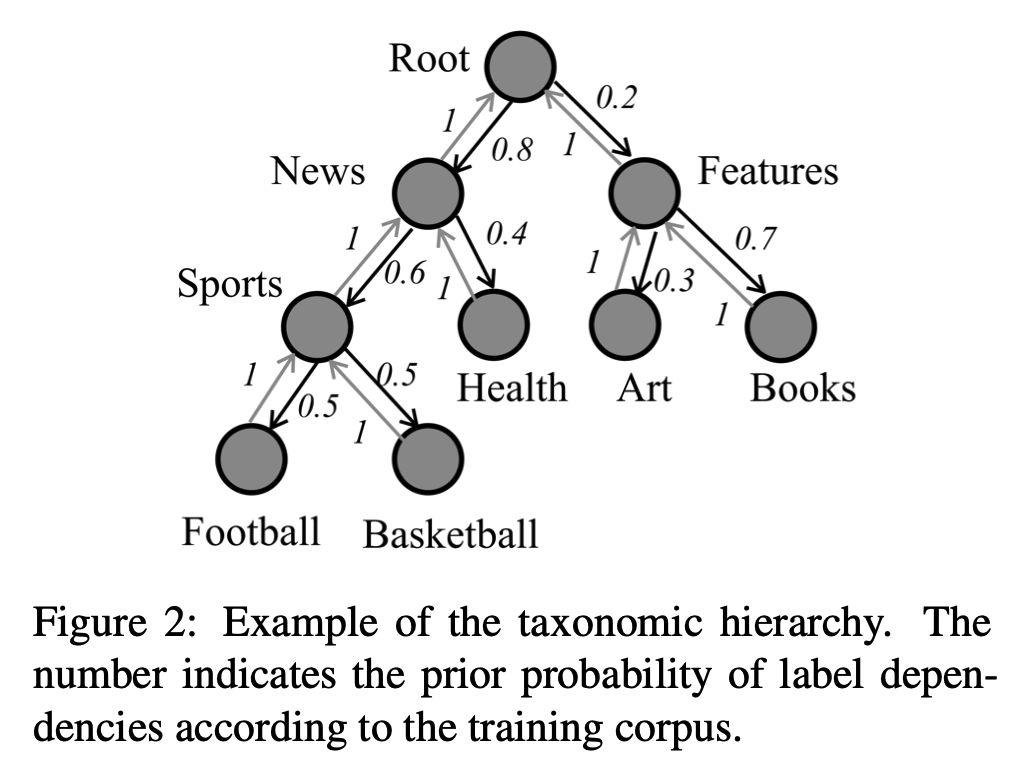
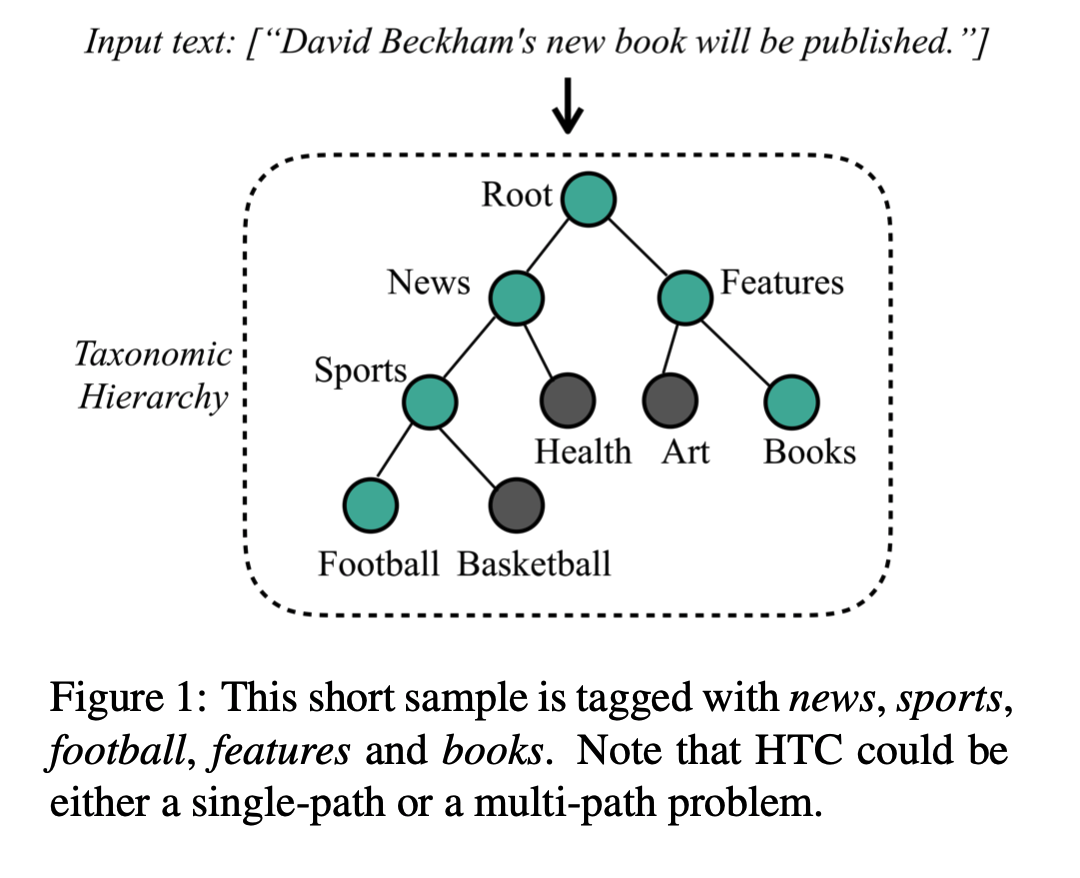
层次文本分类HTC以一个预定义的分类层级组织标签空间,该层级基于整个语料库预定义;分类层级主要包括树状结构和又有向环图(DAG)结构;通过将每个标签结点区分为单个路径结点,可以将DAG转换为树状结构,因此,分类层级可以简化为树状结构;如下图所示可将分类层级建模成有向图\(G=(V,\vec{E}, \overleftarrow{E})\) ,\(V=\{v_1,v_2,...,v_C\}\) ,C表示标签结点数目,\(\vec{E}=\{(v_i,v_j)|i\in V,j\in child(i)\}\) 是自上而下层级路径,\(\overleftarrow{E}=\{(v_j,v_i)|i\in V,j\in child(i)\}\) 是自下而上层级路
将HTC定义为\(H=(X,L)\) ,\(X=(x_1,x_2,...,x_N)\) 是一系列文本对象,\(L=(l_1,l_2,...,l_N)\) 是对应的有监督标签集序列,如下图所示,每个样本对应一个标签集,可包含多个类,对应类可属于层级中一个或多个子路径;若一个样本与孩子结点有关,则它属于其父结点
提出层级感知全局模型(HiAGM),利用细粒度层级信息,并聚合逐标签文本特征;HiAGM包含一个传统文本编码器(文本信息)和一个层级感知结构编码器(层次标签关联特征)
为了混合信息聚合,提出HiAGM的两个变种:多标签注意力模型HiAGM-LA和文本特征传播模型HiAGM-TP,前者使用结构编码器更新标签特征,并用多标签注意力机制生成标签感知文本特征,后者通过整个层级传播文本表示,因此可利用标签相关性融合获得逐标签文本特征
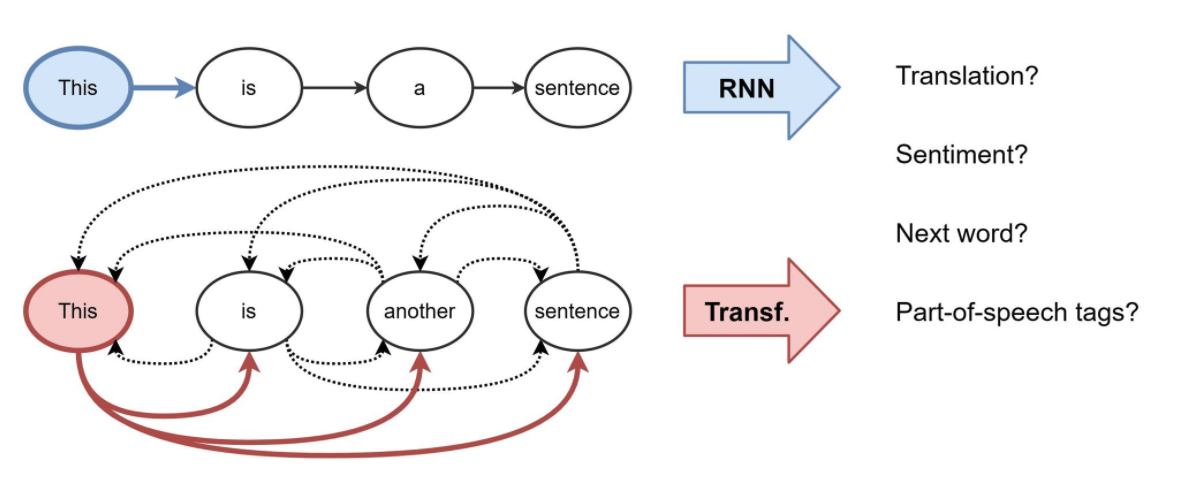
NLP的表示学习:RNN和Transformers,如下图所示
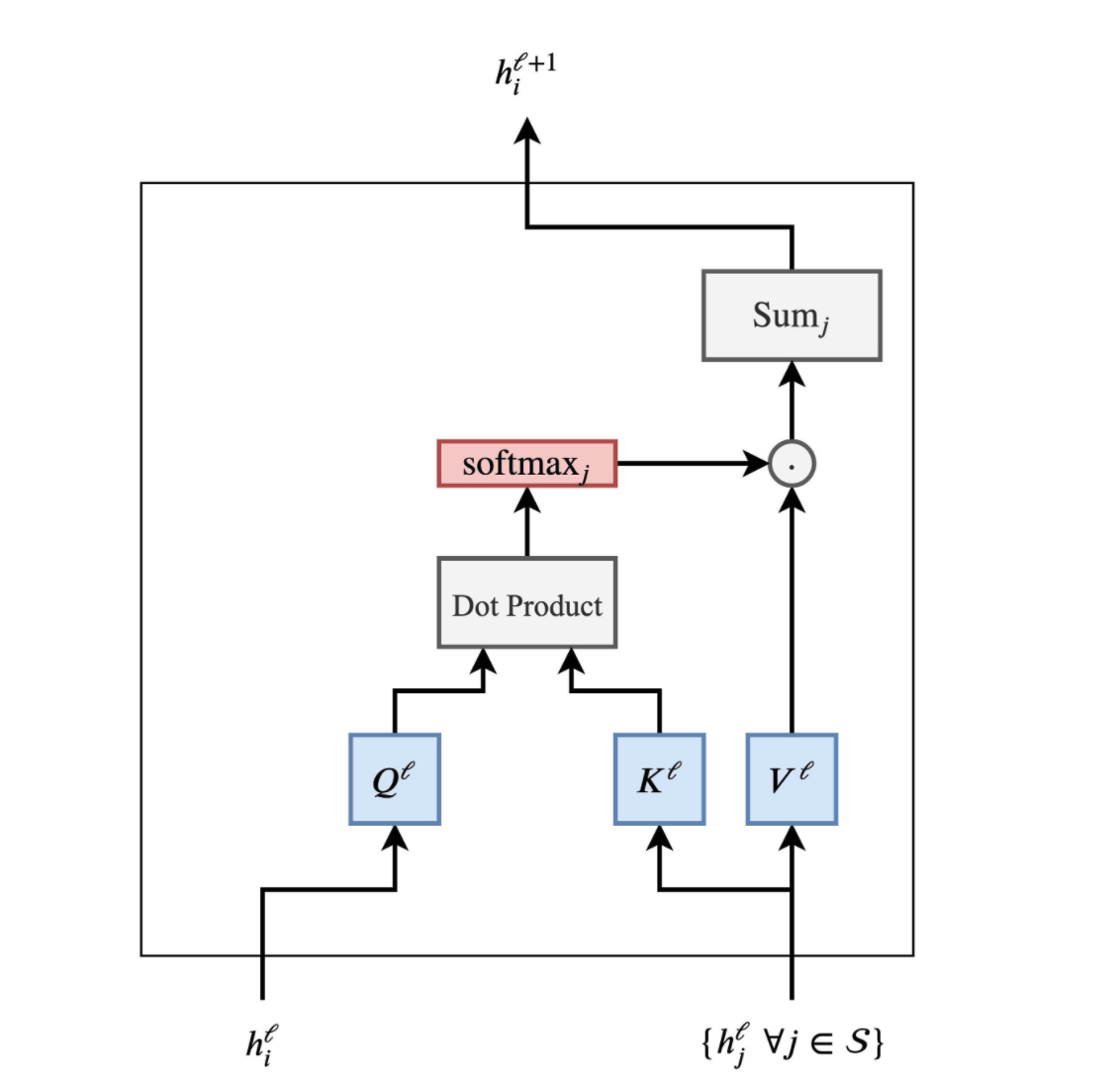
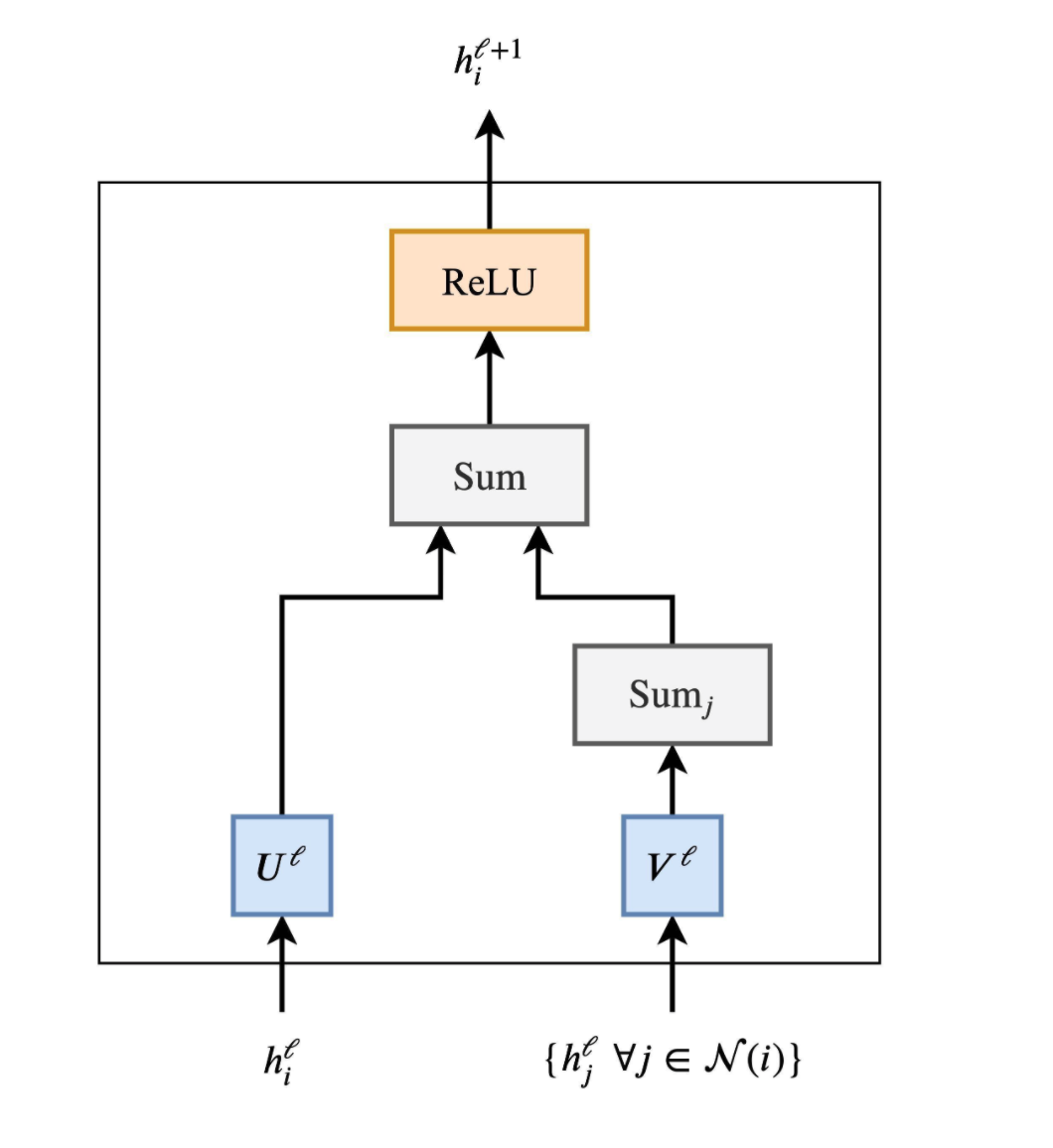
Transformers和GNN的对比图如下,上边是Transformers,下边是GNN;如果在GNN的基础上考虑注意力机制,则得到GAT,再添加归一化和前馈神经网络则得到Graph Transformer
将句子当作是全连接的词图,此时Transformers就是将多头注意力作为邻域聚合函数的GNN
一些延伸
句子是全连接图吗?:借助syntax trees来增强BERT[5]
难以学习长期依赖:一个含n词句子,需要\(n^2\) 的计算
Transformers可以学习到自然syntax吗?
知识图谱
知识图谱的嵌入
\(h_s=\sigma(\sum_{r\in R}\sum_{o\in N_r(s)}f(s,r,o))\) R-GCN[8]: \(f(s,r,o)=W_rh_o\)
SACN[9]: \(f(s,r,o)=\alpha_rWh_o\)
VR-GCN[10]: \(f(s,r,o)=W\Phi(h_r,h_o)\)
KBGAT[11]: \(f(s,r,o)=\alpha_{sro}Wh_{sro}\)
RotationH[12]
Inductive嵌入[13]
开放嵌入[14]
标签的校正
文本生成
GraphWriter+GraphTransformer[15]
推荐系统
实体对齐
MuGNN[17]
Freebase, NELL, YAGO: NLP的先验;独立创建,形式不同,内容互补。Wikipedia是多语言的
对齐知识图谱中的实体以提供一个统一的知识图谱
联合KG的推断和对齐
问答
结合知识图谱和文本[18]
QA上下文与KG的融合表示[19]
动态/时序知识图谱
每条边包含时序信息
时序推理:Know-Evolve[55]
非欧结构:层结构和环结构
提出非欧嵌入方法(Riemannian流形的积)[54]
文本、视觉与图
视觉问答
标签的校正
Zero-shot学习[20]:
为一个类学习一个视觉分类器,不需要训练样例,只使用类的词嵌入和它与其他类的关系
解决不熟悉或新奇类的关键是迁移从熟悉类中获得的知识来描述不熟悉的类
GCN预测视觉分类器,GCN集成结点特征(文本)和图特征(KG):使用语义嵌入和类关系来预测分类器
给定一个学习到的知识图谱,每个结点表示视觉类别
若视觉特征向量维数是D,则每个分类器也是一个D维向量,分类器会乘以图像特征产生分类分数
语言Grounding
表达理解
图像Captioning
RNN+GCN
syntax/句法结构
语义角色标注(SRL)[22]:识别一个句子中的predicate-argument结构(词表示->BiLSTM->GCN)
利用卷积探索syntax(语义表示接近于句法表示): 句法图卷积(syntactic GCN)(句法依赖树)(集成syntax和上下文),编码句子,产生一个句子中词的隐含特征表示
有向标注图:\(h_v=ReLU(\sum_{u\in N(v)}g_{u,v}(W_{d(u,v)}h_u+b_{l(u,v)}))\) ,其中\(W_{d(u,v)}\) 是方向的权重,\(b_{l(u,v)}\) 是标签和方向的偏置,\(g_{u,v}=\sigma(\hat{w}_{d(u,v)}h_u+\hat{b}_{l(u,v)})\) 是edge-wise gating
机器翻译[23]: 将句法结构包含进基于注意力的encoder-decoder模型
基于图的依赖解析
包含高阶特征[24]: 不是从中间解析树显式抽取高阶特征,而是以依赖树的结点表示来捕获高阶信息
语义解析任务
实体的结构信息对语义解析任务是重要的;[25]提出使用GNN在解析过程中整合有关实体及其关系的信息;结合一个decoder复制机制,这种方法提供了一种概念上简单的机制来生成带有实体的逻辑形式
图到序列的学习:优于基于语法的方法
使用GatedGNN[26]: 允许结点和边有自己的隐含表示;解决参数爆炸问题
Levi graph: 如句法依赖;允许边表示
GraphGRU: \(h_v^0=\vec{x}_v\) ,重置门\(r_v^t=\sigma(C_v^r\sum_{u\in N_v}W_{l_e}^rh_u^{(t-1)}+b_{l_e}^r)\) ,更新门\(z_v^t=\sigma(C_v^z\sum_{u\in N_v}W_{l_e}^zh_u^{(t-1)}+b_{l_e}^z)\) ,\(\tilde{h}_v^t=\rho(C_v\sum_{u\in N_v}W_{l_e}(r_u^t\bigodot h_u^{(t-1)})+b_{l_e})\) ,\(h_v^t=(1-z_v^t)\bigodot h_v^{(t-1)}+z_v^t\bigodot \tilde{h}_v^t\) ,其中\(l_e\) 是边标签,\(C_v=C_v^z=C_v^r=|N_v|^{-1}\) 是标准化常数
用于问题生成[27]:
基于强化学习
基于syntax的静态图和基于语义的动态图
用于Grounded视频描述[28]
图到文本的生成[29]:预训练模型BART和T5以及任务适应性预训练策略
在三个图领域展开研究:meaning表示、Wikipedia知识图谱、科技知识图谱
事件检测[30]:基于依赖树的CNN
当前工作只考虑句子的序列表示,忽略句法表示(直接将词与其信息上下文联系起来)
提出了一种新的池化方法,该方法依赖于实体提及来聚合卷积向量;BiLSTM+GCN
识别事件triggers,识别每个trigger的事件类型;可看成是一个多类别分类问题
文档中的词与包含该词的句子(上下文)相关联,以形成事件触发候选词;任务是为每个事件触发候选词预测事件标签,该标签可以是预定义事件类型中的一个或None(表明无触发候选词),即共有L+1类
多个事件抽取[31]:通过引入句法结构联合抽取多个事件triggers和arguments(trigger分类和argument角色标注)
多个事件存在于同一个句子中;共现的triggers减少歧义
嵌入层(词嵌入+词性标注+实体类型标签+位置)->BiLSTM->GCN
自注意力触发分类和argument角色标注
事件真实性预测[32]
文档date(预测文档创建时间):需要推断文档的时序结构
NeuralDater[33]:使用GCN来联合利用文档的句法和时序图结构
Attentive Deep Document Dater (AD3)[34]:同时利用上下文和时序信息
Ordered Event Model (OE-GCN)
Attentive Context Model (AC-GCN)
词嵌入[36]
SynGCN(句子级别): 利用syntax预测词
SemGCN(语料库级别): 利用预训练词嵌入中的语义;联合利用synonym和hypernym
关系抽取
识别实体间的关系:命名实体识别NER+图创建
RESIDE[37]:额外需要Side Information,如实体类型、关系的Alias
GraphRel[38]: 联合实体和关系抽取
联合实体和关系的类型推断[39]
句间关系抽取[40]:优化图创建
边导向图[41]:优化图创建
GP-GNN[42]: 去掉了图创建
图剪枝[43-44]
zero-shot RE[45]
社交媒体
社交媒体中的可解释假新闻检测[46]
GCAN: 图感知的Co-Attention网络
给定源短文本tweet和对应的retweet用户序列(没有文本评论),旨在预测源tweet是否是假的,并通过突出显示可疑转发者retweeters的证据和他们关注的词来生成解释
社交媒体中的政治视角检测[47]
使用GCN来编码社会信息,捕获这些信息是如何在社交网络中传播的
社会信息可以有效地作为远程监督的来源,当直接监督可用时,即使很少的社会信息也可以显著提高性能
检测伪装垃圾内容[48]:
中文文本垃圾检测是有挑战的,因为中文字符的字形glyph和发音phonetic的变异
StoneSkipping: 图(变异)和文本(语义、上下文)联合嵌入;中文字符变异表示
变异族增强图嵌入基于中文字符变异图,可学习到中文字符(局部)和隐含变异族(全局)的图嵌入
增强双向语言模型以及一个结合门函数和一个聚合学习函数,用于集成图和文本信息,同时捕获序列信息
情感分析
对话中的情感识别(ERC):用于分析用户行为和检测假新闻
使用GNN:考虑speakers言语之间的关系
使用关系图注意力网络(RGAT)
考虑序列信息:提出关系位置编码[53]
其他
跨文档的多跳阅读理解[49]: 从文档中创建一个基于路径的推理图,此图结合基于图和基于路径的方法的思想,更适合多条推理;同时提出Gated-RGCN,在基于路径的推理图上积累证据,包含一个新的问题感知门机制,以调节跨文档传播的信息的有用性,并在推理过程中添加问题信息
文档聚类[50]: 需要对长文本的复杂结构有个深入理解,尤其是句中(局部)和句间特征(全局)
在关键词关联图上创建GAE,该图由主题关键词作为结点,多个局部和全局特征作为边,GAE被用于聚合这两种特征
优于TFIDF和平均嵌入
GCN的限制
拓扑限制,包括拓扑的过平滑和局部同质homophily;现有的解决这些拓扑局限的研究通常只关注网络拓扑特征的卷积,这不可避免地严重依赖于网络结构
BiTe-GCN[51]: text-rich网络拓扑和特征的双向卷积
先将原始text-rich网络转换成增强bi-typed异质网络,不仅集成全局文档级别信息,还有局部文本序列信息;然后引入判别卷积机制,实现拓扑和特征的共同卷积
解释[52]:GNN将structural inductive biases集成进NLP模型
图的哪些部分有助于预测,如句法树或co-reference结构
提出post-hoc方法来解释识别不必要边的GNN预测;给定一个训练好的GNN模型,学习到一个简单的分类器,对于每一层的每一条边,预测该边是否可以去掉;这样的分类器可以一种完全可微的方式训练,利用随机门并通过期望\(L_0\) 范数激励稀疏性;使用该技术作为attribution方法来对两个任务分析GNN模型:问答和语义角色标注
可去掉大量边且不损失模型性能,同时剩余边可解释模型预测
参考文献
[1] 2019 | AAAI | Graph Convolutional Networks for Text Classification | Liang Yao et al.
[2] 2019 | KDD | Learning Dynamic Context Graphs for Predicting Social Events | Songgaojun Deng et al.
[3] 2018 | WWW | Large-Scale Hierarchical Text Classification with Recursively Regularized Deep Graph-CNN | Hao Peng et al.
[4] 2019 | EMNLP | Heterogeneous Graph Attention Networks for Semi-supervised Short Text Classification | Linmei Hu et al.
[5] 2021 | Do Syntax Trees Help Pre-trained Transformers Extract Information? | Devendra Singh Sachan et al.
[6] 2020 | ACL | HyperCore: Hyperbolic and Co-graph Representation for Automatic ICD Coding | Pengfei Cao et al.
[7] 2020 | ACL | Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks | Yufeng Zhang et al.
[8] 2018 | Modeling Relational Data with Graph Convolutional Networks | Michael Schlichtkrull et al.
[9] 2019 | AAAI | End-to-End Structure-Aware Convolutional Networks for Knowledge Base Completion | Chao Shang et al.
[10] 2019 | IJCAI | A Vectorized Relational Graph Convolutional Network for Multi-Relational Network Alignment | Rui Ye et al.
[11] 2019 | ACL | Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs | Deepak Nathani et al.
[12] 2019 | NIPS | Low-Dimensional Knowledge Graph Embeddings via Hyperbolic Rotations | Ines Chami et al.
[13] 2019 | AAAI | Logic Attention Based Neighborhood Aggregation for Inductive Knowledge Graph Embedding | Peifeng Wang et al.
[14] 2019 | EMNLP | CaRe: Open Knowledge Graph Embeddings | Swapnil Gupta et al.
[15] 2019 | ACL | Text Generation from Knowledge Graphs with Graph Transformers | Rik Koncel-Kedziorski et al.
[16] 2018 | KDD | Graph Convolutional Neural Networks for Web-Scale Recommender Systems | Rex Ying et al.
[17] 2019 | ACL | Multi-Channel Graph Neural Network for Entity Alignment | Yixin Cao et al.
[18] 2018 | EMNLP | Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text | Haitian Sun et al.
[19] 2021 | ACL | QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering | Michihiro Yasunaga et al.
[20] 2018 | CVPR | Zero-shot Recognition via Semantic Embeddings and Knowledge Graphs | Xiaolong Wang et al.
[21] 2018 | NIPS | Out of the Box: Reasoning with Graph Convolution Nets for Factual Visual Question Answering | Medhini Narasimhan et al.
[22] 2017 | EMNLP | Encoding Sentences with Graph Convolutional Networks for Semantic Role Labeling | Diego Marcheggiani and Ivan Titov.
[23] 2017 | EMNLP | Graph Convolutional Encoders for Syntax-aware Neural Machine Translation | Jasmijn Bastings et al.
[24] 2019 | ACL | Graph-based Dependency Parsing with Graph Neural Networks | Tao Ji et al.
[25] 2019 | Generating Logical Forms from Graph Representations of Text and Entities | Peter Shaw et al.
[26] 2018 | ACL | Graph-to-Sequence Learning using Gated Graph Neural Networks | Daniel Beck et al.
[27] 2020 | ICLR | Reinforcement Learning Based Graph-to-Sequence Model for Natural Question Generation | Yu Chen et al.
[28] 2020 | IJCAI | Hierarchical Attention Based Spatial-Temporal Graph-to-Sequence Learning for Grounded Video Description | Kai Shen et al.
[29] 2020 | Investigating Pretrained Language Models for Graph-to-Text Generation | Leonardo F. R. Ribeiro et al.
[30] 2018 | AAAI | Graph Convolutional Networks with Argument-Aware Pooling for Event Detection | Thien Huu Nguyen and Ralph Grishman
[31] 2018 | EMNLP | Jointly Multiple Events Extraction via Attention-based Graph Information Aggregation | Xiao Liu et al.
[32] 2019 | ACL | Graph based Neural Networks for Event Factuality Prediction using Syntactic and Semantic Structures | Amir Pouran Ben Veyseh et al.
[33] 2018 | ACL | Dating Documents using Graph Convolution Networks | Shikhar Vashishth et al.
[34] 2018 | EMNLP | AD3: Attentive Deep Document Dater | Swayambhu Nath Ray et al.
[35] 2016 | COLING | CATENA: CAusal and TEmporal relation extraction from NAtural language texts | Paramita Mirza and Sara Tonelli
[36] 2019 | ACL | Incorporating Syntactic and Semantic Information in Word Embeddings using Graph Convolutional Networks | Shikhar Vashishth et al.
[37] 2018 | EMNLP | RESIDE: Improving Distantly-Supervised Neural Relation Extraction using Side Information | Shikhar Vashishth et al.
[38] 2019 | ACL | GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction | Tsu-Jui Fu et al.
[39] 2019 | ACL | Joint Type Inference on Entities and Relations via Graph Convolutional | Changzhi Sun et al.
[40] 2019 | ACL | Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network | Sunil Kumar Sahu et al.
[41] 2019 | Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs | Fenia Christopoulou et al.
[42] 2019 | ACL | Graph Neural Networks with Generated Parameters for Relation Extraction | Hao Zhu et al.
[43] 2018 | EMNLP | Graph Convolution over Pruned Dependency Trees Improves Relation Extraction | Yuhao Zhang et al.
[44] 2019 | ACL | Attention Guided Graph Convolutional Networks for Relation Extraction | Zhijiang Guo et al.
[45] 2019 | ACL | Long-tail Relation Extraction via Knowledge Graph Embeddings and Graph Convolution Networks | Ningyu Zhang et al.
[46] 2020 | GCAN: Graph-aware Co-Attention Networks for Explainable Fake News Detection on Social Media | Yi-Ju Lu and Cheng-Te Li
[47] 2019 | ACL | Encoding Social Information with Graph Convolutional Networks for Political Perspective Detection in News Media | Chang Li and Dan Goldwasser
[48] 2019 | Detect Camouflaged Spam Content via StoneSkipping: Graph and Text Joint Embedding for Chinese Character Variation Representation | Zhuoren Jiang et al.
[49] 2020 | IJCAI | Multi-hop Reading Comprehension across Documents with Path-based Graph Convolutional Network | ZeyunTang et al.
[50] 2020 | ACL | Autoencoding Keyword Correlation Graph for Document Clustering | Billy Chiu et al.
[51] 2021 | WSDM | BiTe-GCN: A New GCN Architecture via Bidirectional Convolution of Topology and Features on Text-Rich Networks | Di Jin et al.
[52] 2020 | Interpreting Graph Neural Networks for NLP With Differentiable Edge Masking | Michael Sejr Schlichtkrull et al.
[53] 2019 | EMNLP | Relation-aware Graph Attention Networks with Relational Position Encodings for Emotion Recognition in Conversations | Taichi Ishiwatari et al.
[54] 2019 | EMNLP | DyERNIE: Dynamic Evolution of Riemannian Manifold Embeddings for Temporal Knowledge Graph Completion | Zhen Han et al.
[55] 2017 | PMLR | Know-Evolve: Deep Temporal Reasoning for Dynamic Knowledge Graphs | Rakshit Trivedi et al.
[56] 2019 | Text Level Graph Neural Network for Text Classification | Lianzhe Huang et al.
[57] 2021 | Inductive Topic Variational Graph Auto-Encoder for Text Classification | Qianqian Xie et al.
[58] 2020 | AAAI | Recursive Graphical Neural Networks for Text Classification | Wei Li et al.
[59] 2020 | AAAI | Tensor Graph Convolutional Networks for Text Classification | Xien Liu et al.
[60] 2020 | ACL | Hierarchy-Aware Global Model for Hierarchical Text Classification | Jie Zhou et al.
[61] 2021 | Graph Neural Networks for Natural Language Processing: A Survey | Lingfei Wu et al.
其他资料


 浙公网安备 33010602011771号
浙公网安备 33010602011771号