hive 调优
1、架构优化
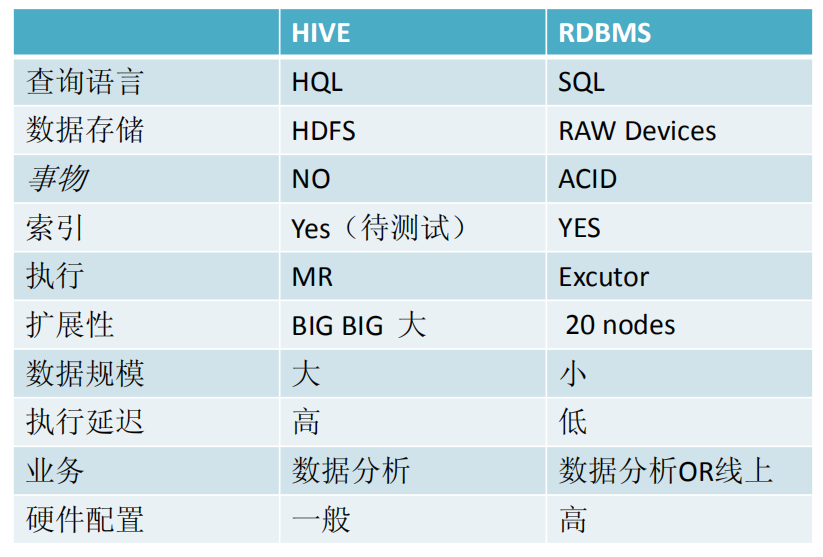
hive和关系型数据刻的区别:
2、MR阶段优化
MR可以主要分为Map、shuffle、Reduce三个阶段。
1)Map优化
• mapred.map.tasks 无效 • num_map_tasks切割大小影响参数
//最大切片大小 – mapred.max.split.size 默认: 256M
//最小的切片大小 – mapred.min.split.size 默认: 1B
//hdfs文件块大小 – dfs.block.size默认:128M
•// 切割算法、计算切片大小的算法 – splitSize = max[minSize,min(maxSize,blockSize)] – minSize = ${mapred.min.split.size} – maxSize = ${mapred.max.split.size} • 列裁剪 hive.optimize.cp=true • map端聚合 hive.map.aggr=true • Map端谓语下推 hive.optimize.ppd=true
2)Reduce优化
• mapred.reduce.tasks 直接设置 • num_reduce_tasks大小影响参数
//Reduce最大个数 – hive.exec.reducers.max 默认:999 – hive.exec.reducers.bytes.per.reducer 默认:1G//每个reduce输入总文件大小 • 切割算法 – numRTasks = min[maxReducers,input.size/perReducer] • maxReducers = ${hive.exec.reducers.max} • perReducer = {hive.exec.reducers.bytes.per.reducer}
3)Shuffle阶段优化
• 压缩中间数据
– 减少磁盘操作
– 减少网络传输数据量
• 配置方法:
– mapred.compress.map.output 设为true//是否压缩map端输出结果
– mapred.compress.output.compression.codec//map端输出压缩算法设置
• org.apache.hadoop.io.compress.LzoCodec
• org.apache.hadoop.io.compress.SnappyCodec
***在hive端设置中间文件是否压缩以及采用什么压缩算法
//中间文件是否压缩
hive.exec.compress.intermediate=true
//中间文件的压缩算法 hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec
//输出文件是否压缩 hive.exec.compress.output=true mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec //输出文件压缩算法
3、JOB优化
1)执行模式优化、
• 本地模式(小数据量)
//开启本地模式
– hive.exec.mode.local.auto=true
//本地模式的最大输入数据量 – hive.exec.mode.local.auto.inputbytes.max(128MB by default) //本地模式的最大task数
– hive.exec.mode.local.auto.tasks.max(4 by default)
//reduce 任务数 – num_reduce_tasks <= 1
•伪分布式模式
– 单机测试使用
•分布式模式
– 正常job
2)join优化
•map端join
//开启map端join
• hive.auto.convert.join=true (default false) map端join小文件的大小
• hive.mapjoin.smalltable.filesize=600M(default 25M) //查询语句强制map端join
• Select /*+MAPJOIN(a)+*/ ..a join b强制指定mapjoin
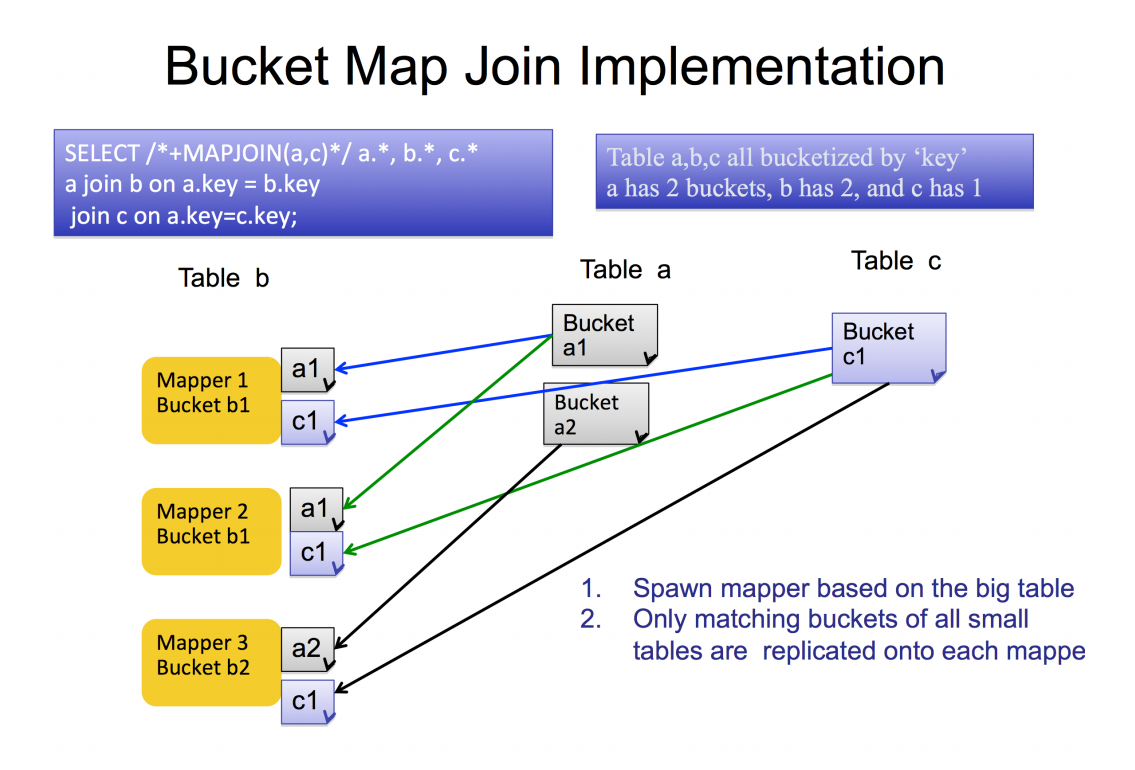
Bucket Map Join
• set hive.optimize.bucketmapjoin=true
• mapjoin一起工作
• 所有要join的表必须分桶,大表的桶的个数是小表的整数倍
• 做了bucket的列必须等于join的列
数据倾斜
1)count distinct数据倾斜
• Select count(distinct id) from acorn_3g.iplog where log_date like ‘2013-12%’;
– 耗时:1600S
• Select count(1) from (select distinct id from acorn_3g.iplog where log_date like ‘2013-12%’ and id>0) tmp;
– 耗时:260s
2)common join倾斜
• select m.uid as user_id,m.from_id,m.app_id,m.is_auto,u.stage from acorn_3g.mcs_access m join user u on m.uid = u.id where m.log_date='2013-12-12’;
– 耗时:最起码2个小时
• select m.uid,m.from_id,m.app_id,m.is_auto,u.stage from user u join (select m.uid,m.from_id,m.app_id,m.is_auto from acorn_3g.mcs_access m where log_date='2013-12-12' and uid>0 group by m.uid,m.
4、sql作业优化
1)并行执行
当作业2和作业3同时依赖于作业1,而作业2,3之间并没有联系,那么就可以开启并行执行
jdbc:hive2://> SET hive.exec.parallel=true;
jdbc:hive2://> SET hive.exec.parallel.thread.number=16;
2)jvm重用
当作业个数很多,而且作业持续时间很短的情况下,那么可以开启jvm重用
jdbc:hive2://> SET mapred.job.reuse.jvm.num.tasks=5;
3)MR迭代次数推测
• Sql语句之我见
– 聚合函数
• max、min、avg、count、distinct
– 连接
• Join、left outer join、right outer join。。
• 多表连接迭代推测
– Select …from a join b on a.id = b.id
– Select col1,..count(col2) from a join b on ..
– Select col1,..count(distinct col2) from a join b on ..
– 公式:逢join、distinct加1,遇map join减1
5、Hql语句优化
1)想对去重结果去重,使用group by 比distinct 性能更高
2)当多重查询时,最终结果需要加where对查询结果进行限定得时候,where尽量写在内层,更早得减少检索数据量,提高查询速度。
3)尽量使用分区表,避免全表扫描。
4)活用中间表,临时表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号