

Oracle----语法篇
FETCH
从12c之后,可以使用这个语法,从第二个开始,找3条数据
SELECT * FROM CBondAnalysisCNBD1 OFFSET 1 ROWS FETCH NEXT 3 ROWS ONLY;
CASE
SELECT ACCOUNT_NO AS baseAcctNo, 'CNY' AS ccy,
(CASE
WHEN CHECK_STATUS = '0' AND REPORT_CHECK = '0' THEN '03'
WHEN CHECK_STATUS IN ('2', '4') AND REPORT_CHECK = '0' THEN '02'
WHEN CHECK_STATUS = '1' AND REPORT_CHECK = '1' THEN '01'
END) AS asFlag,
CHECK_REPORT_DATE AS asDate
FROM T_ACCOUNT_INFO
DECODE
decode与case比较,decode只能做等值比较
#表达式
decode(条件,值1,返回值1,值2,返回值2,…值n,返回值n,缺省值)
decode(条件,值1,返回值1,缺省值)
#使用
select t.id,
t.name,
t.age,
decode(t.sex, '1', '男生', '2', '女生', '其他') as sex
from STUDENT2 t
||
- 字符串拼接
select 'update SYS_USERS set userid='||'1'||' where userid='||userID,USERNAME from SYS_USERS;
UNION
select userID from (select userID from SYS_USERS OFFSET 1 ROWS FETCH NEXT 3 ROWS ONLY) union all select userID from (select userID from SYS_USERS OFFSET 1 ROWS FETCH NEXT 3 ROWS ONLY);
MERGE
格式
MERGE INTO [target-table] A USING [source-table sql] B ON([conditional expression] and [...]...) WHEN MATCHED THEN [UPDATE sql] WHEN NOT MATCHED THEN [INSERT sql]
使用
有两张表的数据
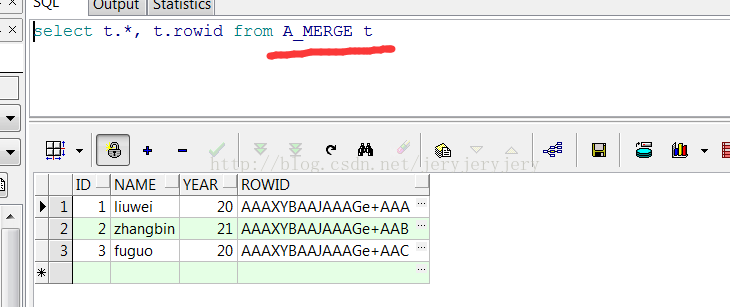
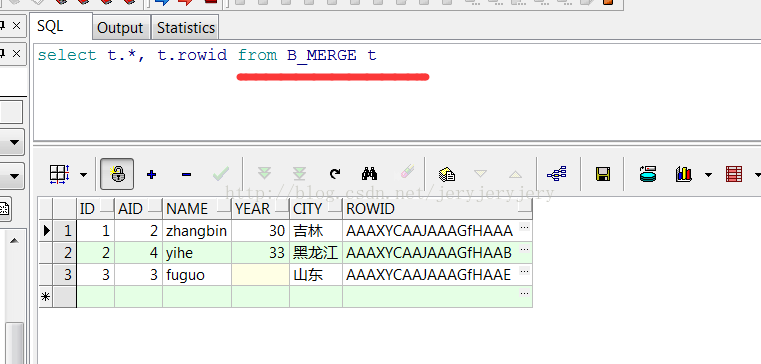
然后再使用merge into用B_MERGE来更新A_MERGE中的数据
MERGE INTO A_MERGE A USING (select B.AID,B.NAME,B.YEAR from B_MERGE B) C ON (A.id=C.AID) #如果只需要insert,这个匹配可以删除 WHEN MATCHED THEN UPDATE SET A.YEAR=C.YEAR #如果只需要update,这个匹配可以删除 WHEN NOT MATCHED THEN INSERT(A.ID,A.NAME,A.YEAR) VALUES(C.AID,C.NAME,C.YEAR);
connect by
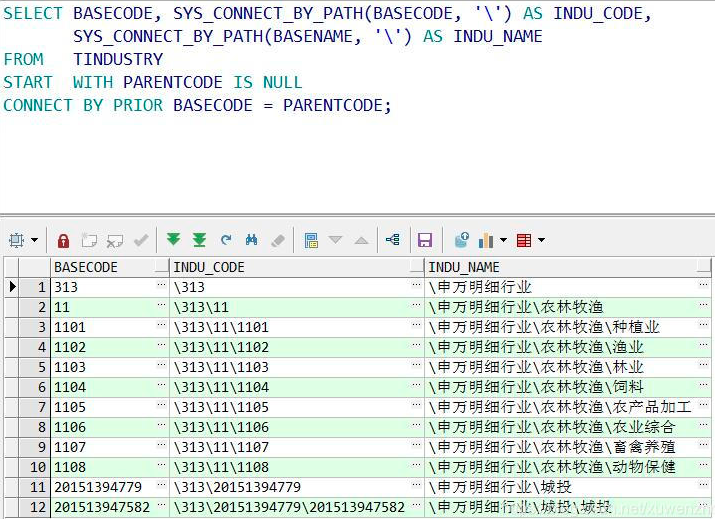
sys_connect_by_path
函数主要作用是可以把一个父节点下的所有子节点通过某个字符进行区分,然后连接在一个列中显示
prior
放在子节点端,则表示扫描树是以start with指定的节点作为根节点从上往下扫描。可能对应一个或多 个分支。
prior放在父节点端,则表示扫描树是以start with指定的节点作为最低层子节点,从下往上扫描。顺序是子节点往父节点扫描,直到根节点为止,这种情况只能得到一个分支。
start with
可以省略,如果省略,表示对所有节点都当成根节点分别进行遍历
level
可以用level关键字查看所在层次,select level....
Substr
1、select substr('HelloWorld',0,3) value from dual; //返回结果:Hel,截取从“H”开始3个字符
2、select substr('HelloWorld',1,3) value from dual; //返回结果:Hel,截取从“H”开始3个字符
3、select substr('HelloWorld',2,3) value from dual; //返回结果:ell,截取从“e”开始3个字符
4、select substr('HelloWorld',0,100) value from dual; //返回结果:HelloWorld,100虽然超出预处理的字符串最长度,但不会影响返回结果,系统按预处理字符串最大数量返回。
5、select substr('HelloWorld',5,3) value from dual; //返回结果:oWo
6、select substr('Hello World',5,3) value from dual; //返回结果:o W (中间的空格也算一个字符串,结果是:o空格W)
7、select substr('HelloWorld',-1,3) value from dual; //返回结果:d (从后面倒数第一位开始往后取1个字符,而不是3个。原因:下面红色 第三个注解)
8、select substr('HelloWorld',-2,3) value from dual; //返回结果:ld (从后面倒数第二位开始往后取2个字符,而不是3个。原因:下面红色 第三个注解)
9、select substr('HelloWorld',-3,3) value from dual; //返回结果:rld (从后面倒数第三位开始往后取3个字符)
10、select substr('HelloWorld',-4,3) value from dual; //返回结果:orl (从后面倒数第四位开始往后取3个字符)
11、select substr('HelloWorld',0) value from dual; //返回结果:HelloWorld,截取所有字符
12、select substr('HelloWorld',1) value from dual; //返回结果:HelloWorld,截取所有字符
13、select substr('HelloWorld',2) value from dual; //返回结果:elloWorld,截取从“e”开始之后所有字符
14、select substr('HelloWorld',3) value from dual; //返回结果:lloWorld,截取从“l”开始之后所有字符
15、select substr('HelloWorld',-1) value from dual; //返回结果:d,从最后一个“d”开始 往回截取1个字符
16、select substr('HelloWorld',-2) value from dual; //返回结果:ld,从最后一个“d”开始 往回截取2个字符
17、select substr('HelloWorld',-3) value from dual; //返回结果:rld,从最后一个“d”开始 往回截取3个字符
ROUND
#语法
ROUND( number, decimal_places )
number : 需四舍五入处理的数值
decimal_places : 四舍五入 , 小数取几位 ( 预设为 0 )
#使用
select round(123.456, 0) from dual; 回传 123
select round(123.456, 1) from dual; 回传 123.5
select round(123.456, 2) from dual; 回传 123.46
select round(123.456, 3) from dual; 回传 123.456
select round(-123.456, 2) from dual; 回传 -123.46
#如果为负数则表示从小数点开始左边的位数,相应整数数字用0填充
select round(1234.5678,-1) from dual; 回传1230
select round(1234.5678,-2) from dual; 回传1200
select round(1234.5678,-4) from dual; 回传0
to_char
日期比较
select count(*) from SRC_TGT_SECINFO where to_char(IMPORTDATE,'YYYY/MM/DD')='2021/01/26';//忽略秒的存在,使用to_date,不能忽略掉秒
数字转成字符串
Select TO_CHAR(1.0123) FROM DUAL;
日期转成字符串
select TO_CHAR(sysdate,'yyyy') from dual; Select TO_CHAR(sysdate, 'YYYY-MM-DD hh24:mi:ss') FROM DUAL; to_char函数特殊用法 to_char(sysdate,'d') 每周第几天 to_char(sysdate,'dd') 每月第几天 to_char(sysdate,'ddd') 每年第几天 to_char(sysdate,'ww') 每年第几周 to_char(sysdate,'mm') 每年第几月 to_char(sysdate,'q') 每年第几季
转化数字型指定小数点位数的用法
#FM:除空格,小数点左边最多 Select TO_CHAR(1.00,'900.9999') FROM DUAL // 01.0000 Select TO_CHAR(11111.01,'99.9999') FROM DUAL //######## Select TO_CHAR(11.01,'9999.9999') FROM DUAL // 11.0100【前面有空格】 Select TO_CHAR(11.0100,'FM9999.9999') FROM DUAL //11.01【去除空格,0后面如果没有数字,全部清除】 Select TO_CHAR(11.0000,'FM9999.9999') FROM DUAL //11.【去除空格,0后面如果没有数字,全部清除】 完美【小数点前面只允许4位】 Select TO_CHAR(11.0000,'FM9999.0099') FROM DUAL //11.00【去除空格,0后面如果没有数字,会保两位】 补充 Select TO_CHAR(01,'0009') FROM DUAL //0001,补0
NVL
语法 NVL(eExpression1, eExpression2) select nvl(a.name,'空的') as name from student a join school b on a.ID=b.ID
CAST
类型转换
--截断小数
SELECT CAST('123.447654' AS decimal(5,2)) as result from dual; #123.45
SELECT CAST('123.4' AS int) as result from dual;#123
select cast(empno as varchar2(10)) as empno from emp;
minus
表A{1,2,3,4,5,}
表B{4,5,6,7,8,}
查询A中有的数据,B中没有的数据
select * from A minus select * from B;#1,2,3。
查询A,B中所有的数据,去重
select * from A unionselect * from B;#1,2,3,4,5,6,7,8。
查询A,B都有的数据
select * from A minus (select * from A minus select * from B); #4,5
rownum
select * from (select rownum as rn,OA_HY_HYGL.* from OA_HY_HYGL) where ROWNUM between 1 and 10;
<select id="selectEntities" resultType="java.util.Map">
select * from (select rownum as rn, HYGL.*,JBXX1.ZGXM,ZZJG.ZZJGMC,ORGLIST1.ONAME as CJBM,SECUSER.U_NAME,ORGLIST2.ONAME as XGBM
from OA_HY_HYGL HYGL
left join RL_RY_JBXX JBXX1 on JBXX1.JBXX_PKID = HYGL.LXR
left join RL_SSO_ZZJG ZZJG on ZZJG.ZZJG_PKID = HYGL.DYBM
left join FG_ORGLIST ORGLIST1 on ORGLIST1.OCODE = HYGL.FG_ORGLIST_PKID_CJBM
left join FG_ORGLIST ORGLIST2 on ORGLIST2.OCODE = HYGL.FG_ORGLIST_PKID_XGBM
left join SECUSER SECUSER on SECUSER.LOGID = HYGL.SEC_USER_PKID_XGR
<where>
<if test="entity.HYGL_PKID != null" >
and HYGL_PKID = #{entity.HYGL_PKID}
</if>
<if test="entity.HYBH != null" >
and HYBH like concat(concat('%',#{entity.HYBH}), '%')
</if>
<if test="entity.HYMC != null" >
and HYMC like concat(concat('%',#{entity.HYMC}), '%')
</if>
<if test="entity.ZT != null" >
and ZT like concat(concat('%',#{entity.ZT}), '%')
</if>
<if test="entity.HYSMC != null" >
and HYSMC like concat(concat('%',#{entity.HYSMC}), '%')
</if>
</where>
)
<where>
<if test="pageinfo!= null and pageinfo.first!=null and pageinfo.last!=null">
and rn between #{pageinfo.first} and #{pageinfo.last} //主要rn的位置
</if>
</where>
<if test="pageinfo!=null and pageinfo.order!= null and pageinfo.sort!=null">
order by concat('HYGL.',${pageinfo.sort}) ${pageinfo.order} //order不能放到where里面,否走可能会 where order 报错
</if>
<if test="pageinfo==null or pageinfo.order == null" >
order by CJSJ desc
</if>
</select>
(+)
oracle中的(+)是一种特殊的用法,(+)表示外连接,并且总是放在非主表的一方。 例如左外连接: select A.a,B.a from A LEFT JOIN B ON A.b=B.b; 等价于 select A.a,B.a from A,B where A.b = B.b(+); 再举个例子,这次是右外连接: select A.a,B.a from A RIGHT JOIN B ON A.b=B.b; 等价于 select A.a,B.a from A,B where A.b (+) = B.b;
REPLACE
REPLACE ( char, search_string [, replace_string]) select replace(name,"郑“,"刘“) from xx 将姓郑的 替换成姓刘的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号