

MySQL----存储过程
基本命令
#声明变量 DECLARE a INT; #对变量赋值 SET a = 5;
基本使用
创建存储过程
DROP PROCEDURE if exists p8;
CREATE PROCEDURE p8 ()
BEGIN
DECLARE a INT;
DECLARE b INT;
DECLARE @TIMES INT;--
SET a = 5;
SET b = 5;
INSERT INTO user(name, age) VALUES (a,b);
select * from user;
END;
调用存储过程
call p8();
游标
- 游标的声明需要在所有其他变量之后,游标常常要配合一个状态值来实现功能,需要声明一个休止标识
- declare continue handler for not found set 休止标识=1;
- 游标使用要先open,最后需要close
- 游标值的获取用fetch my_cursor into 某变量
基本使用
delimiter $$
CREATE procedure changeName()
begin
declare stopflag int default 0;
declare myname varchar(20) default '';
declare my_cursor cursor for select sname from student where sid%2=0;
declare continue handler for not found set stopflag=1;
open my_cursor;
while(stopflag=0) do
begin
fetch my_cursor into myname;
update student set sname = concat(sname,'aab') where sname = myname;
end;
end while;
close my_cursor;
end;
$$
利用存储过程进行秒杀
实用有并发,但是并发量不大,请求压力在后台。如果高并发的情况下,需要做额外的处理
建表
-- 整个项目的数据库脚本
-- 开始创建一个数据库
CREATE DATABASE seckill;
-- 使用数据库
USE seckill;
-- 创建秒杀库存表
CREATE TABLE seckill(
`seckill_id` BIGINT NOT NULL AUTO_INCREMENT COMMENT '商品库存ID',
`name` VARCHAR(120) NOT NULL COMMENT '商品名称',
`number` INT NOT NULL COMMENT '库存数量',
`start_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP() COMMENT '秒杀开启的时间',
`end_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP() COMMENT '秒杀结束的时间',
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP() COMMENT '创建的时间',
PRIMARY KEY (seckill_id),
KEY idx_start_time(start_time),
KEY idx_end_time(end_time),
KEY idx_create_time(create_time)
)ENGINE =InnoDB AUTO_INCREMENT=1000 DEFAULT CHARSET=utf8 COMMENT='秒杀库存表';
-- 插入初始化数据
insert into
seckill(name,number,start_time,end_time)
values
('1000元秒杀iphone6',100,'2016-5-22 00:00:00','2016-5-23 00:00:00'),
('500元秒杀iPad2',200,'2016-5-22 00:00:00','2016-5-23 00:00:00'),
('300元秒杀小米4',300,'2016-5-22 00:00:00','2016-5-23 00:00:00'),
('200元秒杀红米note',400,'2016-5-22 00:00:00','2016-5-23 00:00:00');
-- 秒杀成功明细表
-- 用户登录相关信息
create table success_killed(
`seckill_id` BIGINT NOT NULL COMMENT '秒杀商品ID',
`user_phone` BIGINT NOT NULL COMMENT '用户手机号',
`state` TINYINT NOT NULL DEFAULT -1 COMMENT '状态标示:-1无效 0成功 1已付款',
`create_time` TIMESTAMP NOT NULL COMMENT '创建时间',
PRIMARY KEY (seckill_id,user_phone), /*联合主键*/
KEY idx_create_time(create_time)
)ENGINE =InnDB DEFAULT CHARSET =utf8 COMMENT ='秒杀成功明细表'
建立存储过程
-- 秒杀执行储存过程
DELIMITER $$ -- console ; 转换为
$$
-- 定义储存过程
-- 参数: in 参数 out输出参数
-- row_count() 返回上一条修改类型sql(delete,insert,update)的影响行数
-- row_count:0:未修改数据 ; >0:表示修改的行数; <0:sql错误
CREATE PROCEDURE `seckill`.`execute_seckill`
(IN v_seckill_id BIGINT, IN v_phone BIGINT,
IN v_kill_time TIMESTAMP, OUT r_result INT)
BEGIN
DECLARE insert_count INT DEFAULT 0;
START TRANSACTION;
#先插入,seckill_id, user_phone建立了主键,如果重复插入会报错,我们使用IGNORE,忽略重复插入,如果重复插入,SELECT row_count()返回0,就会rollback;
INSERT IGNORE INTO success_killed
(seckill_id, user_phone, create_time)
VALUES (v_seckill_id, v_phone, v_kill_time);
SELECT row_count()
INTO insert_count;
IF (insert_count = 0)
THEN
ROLLBACK;
SET r_result = -1;
ELSEIF (insert_count < 0)
THEN
ROLLBACK;
SET r_result = -2;
ELSE
#更新仓库数量,如果更新成功,SELECT row_count()返回值>0,就可以继续走;
UPDATE seckill
SET number = number - 1
WHERE seckill_id = v_seckill_id
AND end_time > v_kill_time
AND start_time < v_kill_time
AND number > 0;
SELECT row_count()
INTO insert_count;
IF (insert_count = 0)
THEN
ROLLBACK;
SET r_result = 0;
ELSEIF (insert_count < 0)
THEN
ROLLBACK;
SET r_result = -2;
ELSE
COMMIT;
SET r_result = 1;
END IF;
END IF;
END;
$$
测试
set @r_result =111; CALL execute_seckill(1003, 13502172891, now(), @r_result); SELECT @r_result;
在mapper接口
void killByProcedure(Map<String,Object> paramMap);
xml
<!--调用储存过程-->
<select id="killByProcedure" statementType="CALLABLE">
CALL execute_seckill(
#{seckillId,jdbcType=BIGINT,mode=IN},
#{phone,jdbcType=BIGINT,mode=IN},
#{killTime,jdbcType=TIMESTAMP,mode=IN},
#{result,jdbcType=INTEGER,mode=OUT}
)
</select>
ps:关于select row_count(),在控制台可以测试出来,返回上一次update,insert,delete影响行数。
if not exists注意事项
在if not exists中出现异常,不会报错,直接跳出if判断。所以很容易出现问题,尽量少用,参考上面(秒杀)使用。
delimitr $$
CREATE PROCEDURE `test_proc`(
pid int
)
begin
if not exists (select * from t where id=pid) then
insert into t(id) values(pid);
end if;
update t set total=total+1 where id=pid;
end $$
delimiter ;
基本语法
DELIMITER 介绍
因为默认情况下 SQL 采用(;)作为结束符,这样当存储过程中的每一句 SQL 结束之后,采用(;)作为结束符,就相当于告诉 SQL 可以执行这一句了。但是存储过程是一个整体,我们不希望 SQL 逐条执行,而是采用存储过程整段执行的方式,因此我们就需要临时定义新的 DELIMITER,新的结束符可以用(//)或者($$)。
例子
DELIMITER //
CREATE PROCEDURE `add_num`(IN n INT)
BEGIN
DECLARE i INT;
DECLARE sum INT;
SET i = 1;
SET sum = 0;
WHILE i <= n DO
SET sum = sum + i;
SET i = i +1;
END WHILE;
SELECT sum;
END //
DELIMITER ;
参数类型
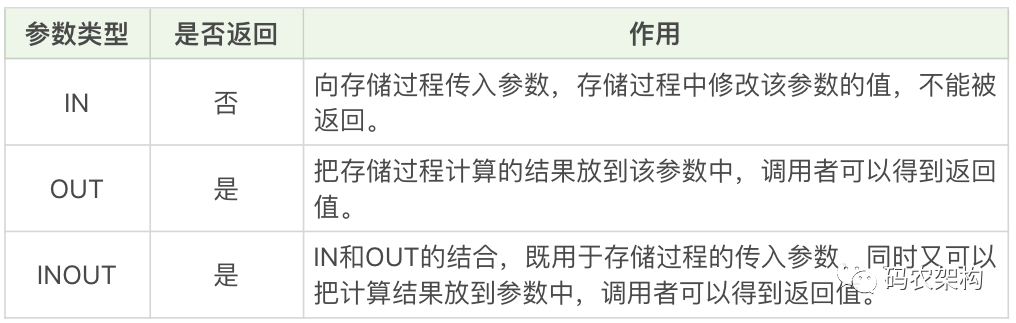
例子
CREATE PROCEDURE `get_hero_scores`(
OUT max_max_hp FLOAT,
OUT min_max_mp FLOAT,
OUT avg_max_attack FLOAT,
s VARCHAR(255)
)
BEGIN
//将查询的值赋值到 max_max_hp, min_max_mp, avg_max_attack
SELECT MAX(hp_max), MIN(mp_max), AVG(attack_max) FROM heros WHERE role_main = s INTO max_max_hp, min_max_mp, avg_max_attack;
END
调用:
- 调用的时候需要在变量前面加 @ , 否则报错
//执行存储过程 CALL get_hero_scores(@max_max_hp, @min_max_mp, @avg_max_attack, '战士'); //查询存储过程中给我们返回的值 SELECT @max_max_hp, @min_max_mp, @avg_max_attack;
控制语句
-
BEGIN…END:BEGIN…END 中间包含了多个语句,每个语句都以(;)号为结束符。
-
DECLARE:DECLARE 用来声明变量,使用的位置在于 BEGIN…END 语句中间,而且需要在其他语句使用之前进行变量的声明。
-
SET:赋值语句,用于对变量进行赋值。
-
SELECT…INTO:把从数据表中查询的结果存放到变量中,也就是为变量赋值。
-
IF…THEN…ENDIF:条件判断语句,我们还可以在 IF…THEN…ENDIF 中使用 ELSE 和 ELSEIF 来进行条件判断。
-
CASE:CASE 语句用于多条件的分支判断,使用的语法是下面这样的。
-
LOOP、LEAVE 和 ITERATE:LOOP 是循环语句,使用 LEAVE 可以跳出循环,使用 ITERATE 则可以进入下一次循环。如果你有面向过程的编程语言的使用经验,你可以把 LEAVE 理解为 BREAK,把 ITERATE 理解为 CONTINUE。
-
REPEAT…UNTIL…END REPEAT:这是一个循环语句,首先会执行一次循环,然后在 UNTIL 中进行表达式的判断,如果满足条件就退出,即 END REPEAT;如果条件不满足,则会就继续执行循环,直到满足退出条件为止。
-
WHILE…DO…END WHILE:这也是循环语句,和 REPEAT 循环不同的是,这个语句需要先进行条件判断,如果满足条件就进行循环,如果不满足条件就退出循环。
CASE
WHEN expression1 THEN ...
WHEN expression2 THEN ...
...
ELSE
--ELSE语句可以加,也可以不加。加的话代表的所有条件都不满足时采用的方式。
END
关于存储过程使用的争议 存储过程有很多好处:
- 存储过程可以一次编译多次使用
- 存储过程的安全性强
- 可以减少网络传输量
缺点也是很明显的:
- 可移植性差
- 调试困难
- 版本管理也很困难
- 不适合高并发的场景

 浙公网安备 33010602011771号
浙公网安备 33010602011771号