
|NO.Z.00079|——————————|BigDataEnd|——|Hadoop&kafka.V64|——|kafka.v64|稳定性|一致性保证.v04|
一、Leader Epoch使用
### --- Kafka解决方案:造成上述两个问题的根本原因在于
~~~ # HW值被用于衡量副本备份的成功与否。
~~~ # 在出现失败重启时作为日志截断的依据。
~~~ 但HW值的更新是异步延迟的,特别是需要额外的FETCH请求处理流程才能更新,
~~~ 故这中间发生的任何崩溃都可能导致HW值的过期。
~~~ Kafka从0.11引入了leader epoch 来取代HW值。
~~~ Leader端使用内存保存Leader的epoch信息,即使出现上面的两个场景也能规避这些问题。
~~~ 所谓Leader epoch实际上是一对值:<epoch, offset>:### --- epoch表示Leader的版本号,从0开始,Leader变更过1次,epoch+1
### --- offset对应于该epoch版本的Leader写入第一条消息的offset。因此假设有两对值:
<0, 0>
<1, 120>~~~ # 则表示第一个Leader从位移0开始写入消息;共写了120条[0, 119];
~~~ # 而第二个Leader版本号是1,从位移120处开始写入消息。
~~~ Leader broker中会保存这样的一个缓存,并定期地写入到一个checkpoint 文件中。
~~~ 当Leader写Log时它会尝试更新整个缓存:
~~~ 如果这个Leader首次写消息,则会在缓存中增加一个条目;否则就不做更新。
~~~ 每次副本变为Leader时会查询这部分缓存,获取出对应Leader版本的位移,
~~~ 则不会发生数据不一致和丢失的情况。二、规避数据丢失
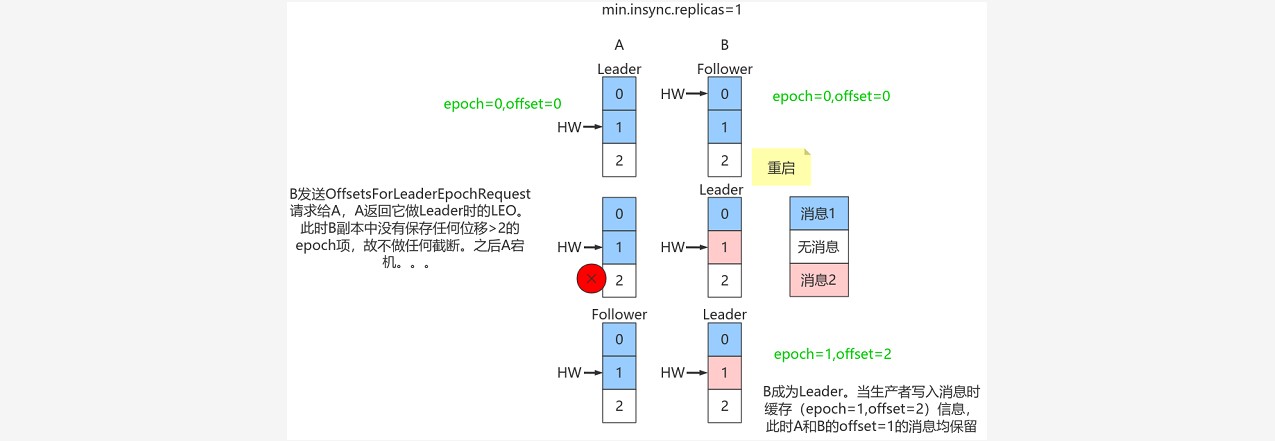
~~~ 只需要知道每个副本都引入了新的状态来保存自己当leader时开始写入的第一条消息的offset
~~~ 以及leader版本。这样在恢复的时候完全使用这些信息而非HW来判断是否需要截断日志。三、规避数据不一致
### --- 规避数据不一致
~~~ 依靠Leader epoch的信息可以有效地规避数据不一致的问题。
~~~ 对于使用unclean.leader.election.enable = true 设置的群集,该方案不能保证消息的一致性。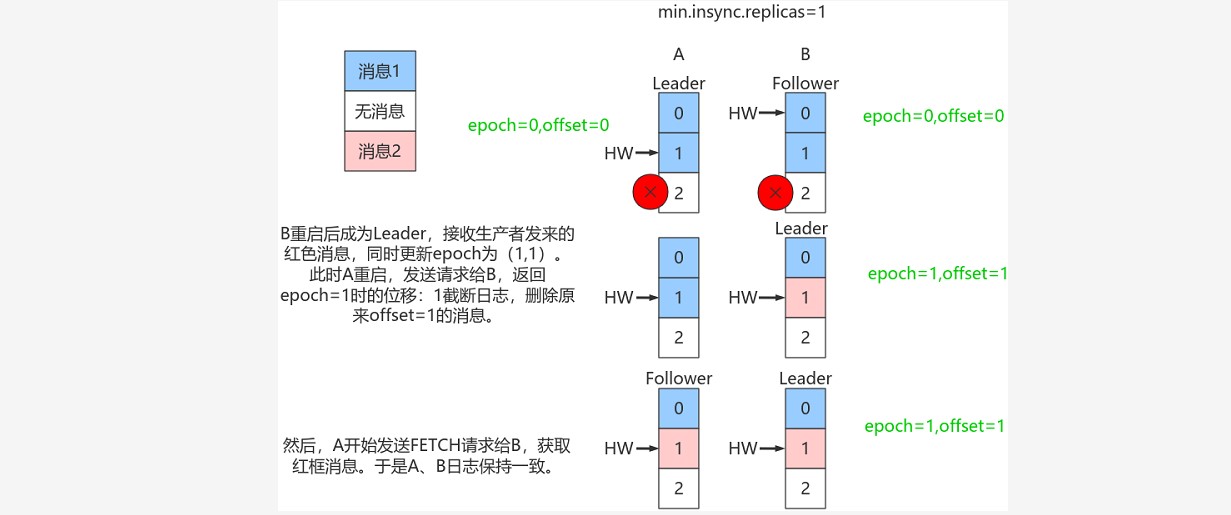
Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor

 浙公网安备 33010602011771号
浙公网安备 33010602011771号