TCP/IP协议栈在Linux内核中的运行时序分析
TCP/IP协议栈在Linux内核中的运行时序分析
目录
1. TCP/IP协议族简述
1.1 OSI 7层模型
| 层次 | 数据单元 | 功能 |
|---|---|---|
| 应用层 | 报文(message) | 通过进程间交互完成网络应用 |
| 表示层 | / | 数据格式转换、压缩、加/解密 |
| 会话层 | / | 建立、管理、终止会话,实现同步 |
| 传输层 | 报文段(segment)/用户数据报 | 进程间通信提供通用数据传输服务 |
| 网络层 | 数据报(datagram) | 为分组交换网上的不同主机提供服务 |
| 链路层 | 帧(frame) | 把数据报封装成帧传到下一个节点 |
| 物理层 | bit | 一个比特一个比特传输到下个节点 |
1.2 TCP/IP四层模型
| 层次 | 功能 |
|---|---|
| 应用层 | 对客户发出的一个请求,服务器作出响应并提供相应的服务。 |
| 传输层 | 为通信双方的主机提供端到端的服务,传输层对信息流具有调节作用,提供可靠性传输,确保数据到达无误。 |
| 网络层 | 进行网络互连,根据网间报文IP地址,从一个网络通过路由器传到另一网络。 |
| 网络接口层 | 负责接收IP数据报,并负责把这些数据报发送到指定网络上。 |
1.3 TCP/IP协议的特点
- TCP/IP协议不依赖于任何特定的计算机硬件或操作系统,提供开放的协议标准,即使不考虑Internet,TCP/IP协议也获得了广泛的支持。所以TCP/IP协议成为一种联合各种硬件和软件的实用系统。
- 标准化的高层协议,可以提供多种可靠的用户服务。
- 统一的网络地址分配方案,使得整个TCP/IP设备在网中都具有惟一的地址。
- TCP/IP协议并不依赖于特定的网络传输硬件,所以TCP/IP协议能够集成各种各样的网络。用户能够使用以太网(Ethernet)、令牌环网(Token Ring Network)、拨号线路(Dial-up line)、X.25网以及所有的网络传输硬件。
2. Linux网络模型
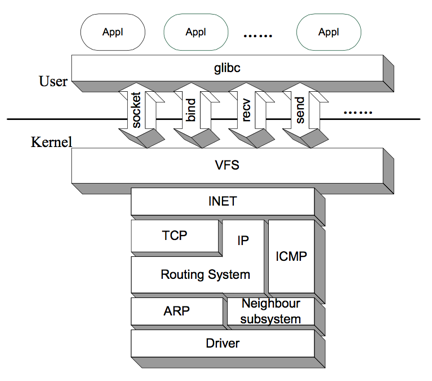
如图所示,系统调用是操作系统内核空间与用户空间的界面。strace工具的结果表明,回溯上述的各个glibc库函数的调用,最终都是系统调用——socket对应sys_socket系统调用,bind对应sys_bind系统调用,send对应sys_sendto系统调用等。
这些系统调用是我们进入内核的入口。进入内核后,VFS(虚拟文件系统)将会进行一些处理。上文说明过,一个socket对应一个socket文件作为操作的实体。本文讨论的这些网络相关的系统调用,都把socket文件作为重要参数,如sys_socket系统就是用来新建并初始化这个socket文件的。sys_bind系统将地址、端口等信息绑定在这个文件上。
离开VFS层,我们下到INET层。这一层的核心数据结构,就是struct socket。每一个socket文件都有一个socket控制实体(数据结构struct socket的实例)与之对应。这个socket控制实体自身以及其成员包含了socket的所有信息,包括状态、标志、操作、数据缓冲区信息等。
有必要说明的是INET这一名称的来历:回顾之前socket应用的例子,可以看到我们调用socket()时曾经传递过一个参数AF_INET。计算机网络课程中我们学习过“细腰结构”——IP over Everything & Everything over IP。但实际上第三层还是有很多不同于IP协议的存在,如IPv6、IPX、DNNET等。Linux称它们为不同的地址簇(Address Families, AF),或叫协议簇(Protocal Families, PF)。INET就是一个地址簇。从另一个角度看,内核代码的net目录下有很多子目录都是一个个独立的地址簇,其中包含一个命名为af_XXX.c的文件用于初始化该地址簇以及提供一些重要的操作。例如在net/ipv4目录中,我们可以看到af_inet.c文件。原来INET就是使用IP(第四版)协议的地址簇!更佳准确的说法是INET封装了TCP/IP。我们在这里只关注TCP/IP协议,只研究INET。
IP和INET有着紧密的联系,但IP层和INET层并不是等价的概念。INET仅仅是使用了IPv4的协议的地址簇,在TCP/IP参考模型中,它不是单独的一层。INET是Linux网络子系统的一个抽象层次,向上提供了操作的接口,但实际还需要调用下层的功能才能完成数据发收、监听等任务。具体调用下层的什么功能,要根据通信类别来选择。TCP/IP协议栈中,通讯有三种类别:TCP、UDP和RAW方式。前两种方式在计算机网络课程中有较多的讨论,大家比较熟悉。最后一种RAW,从某种意义上说,并不是额外的应用层通信方式——它只是告诉应用层不用理会,直接把数据传递到下一层即可,由网络层直接处理。ICMP是基于RAW方式的一个重要协议,只不过它有一些特殊的性质,所以单独列在这里。
如果是发送数据包,数据通过TCP、UDP操作的处理,或是直接通过RAW方式,最终将来到IP层。这一层中出现了重要的数据结构sk_buff(socket buffer的缩写),存储着数据和连接信息,后面操作的中心从之前的socket、sock数据结构转移到sk_buff上来,sock被释放。IP层对数据进行处理后需要对其进行发送。考虑到IP层的一项重要任务是路由,这里的发送不是直接将数据包传递给下面的层次,而是需要在路由系统中进行游历。在Linux中,路由表被称作转发表(Forward Information Base, FIB)。为了提升查找性能,转发表有一个cache叫做rtable(字面意为“路由表”)。为了避免混淆,我们称rtable为转发表的cache。查找路由表的方式同一般的cache机制:首先查找转发表cache,若命中即使用该路由,否则查找转发表,并将路由信息添加进转发表cache。转发表cache是用带桶的hash表实现的,其key是流标识flowi(Flow Identifier),用来唯一确定一条业务流。如果找到合适的路由后,我们就便把发送的数据传递给下层。但也可能发生找不到路由的情况,例如第一次向一台远程主机发送数据。这时,内核将会暂停发送数据的工作,转而完成邻居发现/地址解析(ARP)。
完成这一工作的是图中倒数第二层的ARP和邻居子系统。它们之间类似于包含关系。ARP的功能是将IP地址映射成MAC地址。邻居子系统的功能是将IP地址映射成链路层硬件地址。MAC地址是硬件地址的一种。对于非以太网设备,其硬件地址不一定是MAC地址。所以ARP可以看成是邻居子系统的一个特殊情况。当然地址解析不是每次都能成功的,特别是第一次向某个主机发送数据时。这时邻居系统将会暂停数据发送流程,转而进行邻居发现的流程。这一层次的功能实质是衔接IP层和链路层,开始使用硬件地址,并有了设备的概念。
真正与设备紧密联系的是图中的最后一层:设备驱动层。它位于参考模型中的链路层。正是它控制硬件,将数据包发送出去。虽然内核编程使用的C语言是面相过程的程序设计语言,但Linux的驱动模型具有鲜明的面相对象特征。驱动这一“抽象类”定义了很多虚”方法”,由具体的驱动程序去实现这些”方法“。这些”方法“对应着网卡硬件功能的抽象,由操作系统内核回调,以完成数据收发、网卡配置等任务。
3. send全过程
3.1 应用层
3.1.1 socket
应用层的各种网络应用程序基本上都是通过 Linux Socket 编程接口来和内核空间的网络协议栈通信的。Linux Socket 是从 BSD Socket 发展而来的,它是 Linux 操作系统的重要组成部分之一,它是网络应用程序的基础。从层次上来说,它位于应用层,是操作系统为应用程序员提供的 API,通过它,应用程序可以访问传输层协议。
- socket 位于传输层协议之上,屏蔽了不同网络协议之间的差异
- socket 是网络编程的入口,它提供了大量的系统调用,构成了网络程序的主体
- 在Linux系统中,socket 属于文件系统的一部分,网络通信可以被看作是对文件的读取,使得我们对网络的控制和对文件的控制一样方便。

3.1.2 应用层处理流程
- 网络应用调用Socket API socket (int family, int type, int protocol) 创建一个 socket,该调用最终会调用 Linux system call socket() ,并最终调用 Linux Kernel 的 sock_create() 方法。该方法返回被创建好了的那个 socket 的 file descriptor。对于每一个 userspace 网络应用创建的 socket,在内核中都有一个对应的 struct socket和 struct sock。其中,struct sock 有三个队列(queue),分别是 rx , tx 和 err,在 sock 结构被初始化的时候,这些缓冲队列也被初始化完成;在收据收发过程中,每个 queue 中保存要发送或者接受的每个 packet 对应的 Linux 网络栈 sk_buffer 数据结构的实例 skb。
- 对于 TCP socket 来说,应用调用 connect()API ,使得客户端和服务器端通过该 socket 建立一个虚拟连接。在此过程中,TCP 协议栈通过三次握手会建立 TCP 连接。默认地,该 API 会等到 TCP 握手完成连接建立后才返回。在建立连接的过程中的一个重要步骤是,确定双方使用的 Maxium Segemet Size (MSS)。因为 UDP 是面向无连接的协议,因此它是不需要该步骤的。
- 应用调用 Linux Socket 的 send 或者 write API 来发出一个 message 给接收端
- sock_sendmsg 被调用,它使用 socket descriptor 获取 sock struct,创建 message header 和 socket control message
- _sock_sendmsg 被调用,根据 socket 的协议类型,调用相应协议的发送函数。
- 对于 TCP ,调用 tcp_sendmsg 函数。
- 对于 UDP 来说,userspace 应用可以调用 send()/sendto()/sendmsg() 三个 system call 中的任意一个来发送 UDP message,它们最终都会调用内核中的 udp_sendmsg() 函数。
3.2 传输层
传输层的最终目的是向它的用户提供高效的、可靠的和成本有效的数据传输服务,主要功能包括 (1)构造 TCP segment (2)计算 checksum (3)发送回复(ACK)包 (4)滑动窗口(sliding windown)等保证可靠性的操作。TCP 协议栈的大致处理过程如下图所示:

TCP 栈简要过程:
- tcp_sendmsg 函数会首先检查已经建立的 TCP connection 的状态,然后获取该连接的 MSS,开始 segement 发送流程。
- 构造 TCP 段的 playload:它在内核空间中创建该 packet 的 sk_buffer 数据结构的实例 skb,从 userspace buffer 中拷贝 packet 的数据到 skb 的 buffer。
- 构造 TCP header。
- 计算 TCP 校验和(checksum)和 顺序号 (sequence number)。
- TCP 校验和是一个端到端的校验和,由发送端计算,然后由接收端验证。其目的是为了发现TCP首部和数据在发送端到接收端之间发生的任何改动。如果接收方检测到校验和有差错,则TCP段会被直接丢弃。TCP校验和覆盖 TCP 首部和 TCP 数据。
- TCP的校验和是必需的
- 发到 IP 层处理:调用 IP handler 句柄 ip_queue_xmit,将 skb 传入 IP 处理流程。
3.3 网络层
网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。网络层将数据链路层提供的帧组成数据包,包中封装有网络层包头,其中含有逻辑地址信息- -源站点和目的站点地址的网络地址。其主要任务包括 (1)路由处理,即选择下一跳 (2)添加 IP header(3)计算 IP header checksum,用于检测 IP 报文头部在传播过程中是否出错 (4)可能的话,进行 IP 分片(5)处理完毕,获取下一跳的 MAC 地址,设置链路层报文头,然后转入链路层处理。

- 首先,ip_queue_xmit(skb)会检查skb->dst路由信息。如果没有,比如套接字的第一个包,就使用ip_route_output()选择一个路由。
- 接着,填充IP包的各个字段,比如版本、包头长度、TOS等。
- 中间的一些分片等,可参阅相关文档。基本思想是,当报文的长度大于mtu,gso的长度不为0就会调用 ip_fragment 进行分片,否则就会调用ip_finish_output2把数据发送出去。ip_fragment 函数中,会检查 IP_DF 标志位,如果待分片IP数据包禁止分片,则调用 icmp_send()向发送方发送一个原因为需要分片而设置了不分片标志的目的不可达ICMP报文,并丢弃报文,即设置IP状态为分片失败,释放skb,返回消息过长错误码。
- 接下来就用 ip_finish_ouput2 设置链路层报文头了。如果,链路层报头缓存有(即hh不为空),那就拷贝到skb里。如果没,那么就调用neigh_resolve_output,使用 ARP 获取。
3.4 链路层
功能上,在物理层提供比特流服务的基础上,建立相邻结点之间的数据链路,通过差错控制提供数据帧(Frame)在信道上无差错的传输,并进行各电路上的动作系列。数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。在这一层,数据的单位称为帧(frame)。数据链路层协议的代表包括:SDLC、HDLC、PPP、STP、帧中继等。
实现上,Linux 提供了一个 Network device 的抽象层,其实现在 linux/net/core/dev.c。具体的物理网络设备在设备驱动中(driver.c)需要实现其中的虚函数。Network Device 抽象层调用具体网络设备的函数。

3.5 物理层
- 物理层在收到发送请求之后,通过 DMA 将该主存中的数据拷贝至内部RAM(buffer)之中。在数据拷贝中,同时加入符合以太网协议的相关header,IFG、前导符和CRC。对于以太网网络,物理层发送采用CSMA/CD,即在发送过程中侦听链路冲突。
- 一旦网卡完成报文发送,将产生中断通知CPU,然后驱动层中的中断处理程序就可以删除保存的 skb 了。
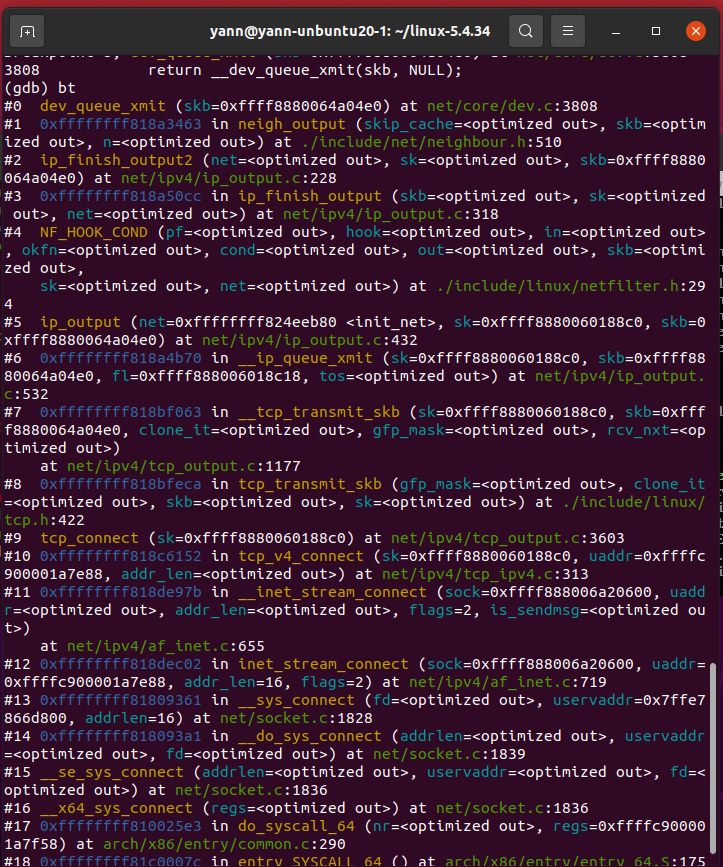
3.6 gdb调试
打上断点后在dev_queue_xmit的栈帧如下
3.7 部分代码
tcp_v4_connect
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *usin = (struct sockaddr_in *)uaddr;
struct inet_sock *inet = inet_sk(sk);
struct tcp_sock *tp = tcp_sk(sk);
__be16 orig_sport, orig_dport;
__be32 daddr, nexthop;
struct flowi4 *fl4;
struct rtable *rt;
int err;
struct ip_options_rcu *inet_opt;
struct inet_timewait_death_row *tcp_death_row = &sock_net(sk)->ipv4.tcp_death_row;
if (addr_len < sizeof(struct sockaddr_in))
return -EINVAL;
if (usin->sin_family != AF_INET)
return -EAFNOSUPPORT;
nexthop = daddr = usin->sin_addr.s_addr;
inet_opt = rcu_dereference_protected(inet->inet_opt,
lockdep_sock_is_held(sk));
if (inet_opt && inet_opt->opt.srr) {
if (!daddr)
return -EINVAL;
nexthop = inet_opt->opt.faddr;
}
orig_sport = inet->inet_sport;
orig_dport = usin->sin_port;
fl4 = &inet->cork.fl.u.ip4;
rt = ip_route_connect(fl4, nexthop, inet->inet_saddr,
RT_CONN_FLAGS(sk), sk->sk_bound_dev_if,
IPPROTO_TCP,
orig_sport, orig_dport, sk);
if (IS_ERR(rt)) {
err = PTR_ERR(rt);
if (err == -ENETUNREACH)
IP_INC_STATS(sock_net(sk), IPSTATS_MIB_OUTNOROUTES);
return err;
}
if (rt->rt_flags & (RTCF_MULTICAST | RTCF_BROADCAST)) {
ip_rt_put(rt);
return -ENETUNREACH;
}
if (!inet_opt || !inet_opt->opt.srr)
daddr = fl4->daddr;
if (!inet->inet_saddr)
inet->inet_saddr = fl4->saddr;
sk_rcv_saddr_set(sk, inet->inet_saddr);
if (tp->rx_opt.ts_recent_stamp && inet->inet_daddr != daddr) {
/* Reset inherited state */
tp->rx_opt.ts_recent = 0;
tp->rx_opt.ts_recent_stamp = 0;
if (likely(!tp->repair))
WRITE_ONCE(tp->write_seq, 0);
}
inet->inet_dport = usin->sin_port;
sk_daddr_set(sk, daddr);
inet_csk(sk)->icsk_ext_hdr_len = 0;
if (inet_opt)
inet_csk(sk)->icsk_ext_hdr_len = inet_opt->opt.optlen;
tp->rx_opt.mss_clamp = TCP_MSS_DEFAULT;
/* Socket identity is still unknown (sport may be zero).
* However we set state to SYN-SENT and not releasing socket
* lock select source port, enter ourselves into the hash tables and
* complete initialization after this.
*/
tcp_set_state(sk, TCP_SYN_SENT);
err = inet_hash_connect(tcp_death_row, sk);
if (err)
goto failure;
sk_set_txhash(sk);
rt = ip_route_newports(fl4, rt, orig_sport, orig_dport,
inet->inet_sport, inet->inet_dport, sk);
if (IS_ERR(rt)) {
err = PTR_ERR(rt);
rt = NULL;
goto failure;
}
/* OK, now commit destination to socket. */
sk->sk_gso_type = SKB_GSO_TCPV4;
sk_setup_caps(sk, &rt->dst);
rt = NULL;
if (likely(!tp->repair)) {
if (!tp->write_seq)
WRITE_ONCE(tp->write_seq,
secure_tcp_seq(inet->inet_saddr,
inet->inet_daddr,
inet->inet_sport,
usin->sin_port));
tp->tsoffset = secure_tcp_ts_off(sock_net(sk),
inet->inet_saddr,
inet->inet_daddr);
}
inet->inet_id = prandom_u32();
if (tcp_fastopen_defer_connect(sk, &err))
return err;
if (err)
goto failure;
err = tcp_connect(sk);
if (err)
goto failure;
return 0;
failure:
/*
* This unhashes the socket and releases the local port,
* if necessary.
*/
tcp_set_state(sk, TCP_CLOSE);
ip_rt_put(rt);
sk->sk_route_caps = 0;
inet->inet_dport = 0;
return err;
}
ip_queue_xmit
int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl,
__u8 tos)
{
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
struct ip_options_rcu *inet_opt;
struct flowi4 *fl4;
struct rtable *rt;
struct iphdr *iph;
int res;
/* Skip all of this if the packet is already routed,
* f.e. by something like SCTP.
*/
rcu_read_lock();
inet_opt = rcu_dereference(inet->inet_opt);
fl4 = &fl->u.ip4;
rt = skb_rtable(skb);
if (rt)
goto packet_routed;
/* Make sure we can route this packet. */
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (!rt) {
__be32 daddr;
/* Use correct destination address if we have options. */
daddr = inet->inet_daddr;
if (inet_opt && inet_opt->opt.srr)
daddr = inet_opt->opt.faddr;
/* If this fails, retransmit mechanism of transport layer will
* keep trying until route appears or the connection times
* itself out.
*/
rt = ip_route_output_ports(net, fl4, sk,
daddr, inet->inet_saddr,
inet->inet_dport,
inet->inet_sport,
sk->sk_protocol,
RT_CONN_FLAGS_TOS(sk, tos),
sk->sk_bound_dev_if);
if (IS_ERR(rt))
goto no_route;
sk_setup_caps(sk, &rt->dst);
}
skb_dst_set_noref(skb, &rt->dst);
packet_routed:
if (inet_opt && inet_opt->opt.is_strictroute && rt->rt_uses_gateway)
goto no_route;
/* OK, we know where to send it, allocate and build IP header. */
skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
skb_reset_network_header(skb);
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (tos & 0xff));
if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->protocol = sk->sk_protocol;
ip_copy_addrs(iph, fl4);
/* Transport layer set skb->h.foo itself. */
if (inet_opt && inet_opt->opt.optlen) {
iph->ihl += inet_opt->opt.optlen >> 2;
ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0);
}
ip_select_ident_segs(net, skb, sk,
skb_shinfo(skb)->gso_segs ?: 1);
/* TODO : should we use skb->sk here instead of sk ? */
skb->priority = sk->sk_priority;
skb->mark = sk->sk_mark;
res = ip_local_out(net, sk, skb);
rcu_read_unlock();
return res;
no_route:
rcu_read_unlock();
IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES);
kfree_skb(skb);
return -EHOSTUNREACH;
}
ip_finish_output2
static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct dst_entry *dst = skb_dst(skb);
struct rtable *rt = (struct rtable *)dst;
struct net_device *dev = dst->dev;
unsigned int hh_len = LL_RESERVED_SPACE(dev);
struct neighbour *neigh;
bool is_v6gw = false;
if (rt->rt_type == RTN_MULTICAST) {
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUTMCAST, skb->len);
} else if (rt->rt_type == RTN_BROADCAST)
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUTBCAST, skb->len);
/* Be paranoid, rather than too clever. */
if (unlikely(skb_headroom(skb) < hh_len && dev->header_ops)) {
struct sk_buff *skb2;
skb2 = skb_realloc_headroom(skb, LL_RESERVED_SPACE(dev));
if (!skb2) {
kfree_skb(skb);
return -ENOMEM;
}
if (skb->sk)
skb_set_owner_w(skb2, skb->sk);
consume_skb(skb);
skb = skb2;
}
if (lwtunnel_xmit_redirect(dst->lwtstate)) {
int res = lwtunnel_xmit(skb);
if (res < 0 || res == LWTUNNEL_XMIT_DONE)
return res;
}
rcu_read_lock_bh();
neigh = ip_neigh_for_gw(rt, skb, &is_v6gw);
if (!IS_ERR(neigh)) {
int res;
sock_confirm_neigh(skb, neigh);
/* if crossing protocols, can not use the cached header */
res = neigh_output(neigh, skb, is_v6gw);
rcu_read_unlock_bh();
return res;
}
rcu_read_unlock_bh();
net_dbg_ratelimited("%s: No header cache and no neighbour!\n",
__func__);
kfree_skb(skb);
return -EINVAL;
}
__dev_queue_xmit
static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev)
{
struct net_device *dev = skb->dev;
struct netdev_queue *txq;
struct Qdisc *q;
int rc = -ENOMEM;
bool again = false;
skb_reset_mac_header(skb);
if (unlikely(skb_shinfo(skb)->tx_flags & SKBTX_SCHED_TSTAMP))
__skb_tstamp_tx(skb, NULL, skb->sk, SCM_TSTAMP_SCHED);
/* Disable soft irqs for various locks below. Also
* stops preemption for RCU.
*/
rcu_read_lock_bh();
skb_update_prio(skb);
qdisc_pkt_len_init(skb);
#ifdef CONFIG_NET_CLS_ACT
skb->tc_at_ingress = 0;
# ifdef CONFIG_NET_EGRESS
if (static_branch_unlikely(&egress_needed_key)) {
skb = sch_handle_egress(skb, &rc, dev);
if (!skb)
goto out;
}
# endif
#endif
/* If device/qdisc don't need skb->dst, release it right now while
* its hot in this cpu cache.
*/
if (dev->priv_flags & IFF_XMIT_DST_RELEASE)
skb_dst_drop(skb);
else
skb_dst_force(skb);
txq = netdev_core_pick_tx(dev, skb, sb_dev);
q = rcu_dereference_bh(txq->qdisc);
trace_net_dev_queue(skb);
if (q->enqueue) {
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
/* The device has no queue. Common case for software devices:
* loopback, all the sorts of tunnels...
* Really, it is unlikely that netif_tx_lock protection is necessary
* here. (f.e. loopback and IP tunnels are clean ignoring statistics
* counters.)
* However, it is possible, that they rely on protection
* made by us here.
* Check this and shot the lock. It is not prone from deadlocks.
*Either shot noqueue qdisc, it is even simpler 8)
*/
if (dev->flags & IFF_UP) {
int cpu = smp_processor_id(); /* ok because BHs are off */
if (txq->xmit_lock_owner != cpu) {
if (dev_xmit_recursion())
goto recursion_alert;
skb = validate_xmit_skb(skb, dev, &again);
if (!skb)
goto out;
HARD_TX_LOCK(dev, txq, cpu);
if (!netif_xmit_stopped(txq)) {
dev_xmit_recursion_inc();
skb = dev_hard_start_xmit(skb, dev, txq, &rc);
dev_xmit_recursion_dec();
if (dev_xmit_complete(rc)) {
HARD_TX_UNLOCK(dev, txq);
goto out;
}
}
HARD_TX_UNLOCK(dev, txq);
net_crit_ratelimited("Virtual device %s asks to queue packet!\n",
dev->name);
} else {
/* Recursion is detected! It is possible,
* unfortunately
*/
recursion_alert:
net_crit_ratelimited("Dead loop on virtual device %s, fix it urgently!\n",
dev->name);
}
}
rc = -ENETDOWN;
rcu_read_unlock_bh();
atomic_long_inc(&dev->tx_dropped);
kfree_skb_list(skb);
return rc;
out:
rcu_read_unlock_bh();
return rc;
}
4. recv全过程
4.1 网络接口层
- 一个 package 到达机器的物理网络适配器,当它接收到数据帧时,就会触发一个中断,并将通过 DMA 传送到位于 linux kernel 内存中的 rx_ring。
- 网卡发出中断,通知 CPU 有个 package 需要它处理。中断处理程序主要进行以下一些操作,包括分配 skb_buff 数据结构,并将接收到的数据帧从网络适配器I/O端口拷贝到skb_buff 缓冲区中;从数据帧中提取出一些信息,并设置 skb_buff 相应的参数,这些参数将被上层的网络协议使用,例如skb->protocol;
- 终端处理程序经过简单处理后,发出一个软中断(NET_RX_SOFTIRQ),通知内核接收到新的数据帧。
- 内核 2.5 中引入一组新的 API 来处理接收的数据帧,即 NAPI。所以,驱动有两种方式通知内核:(1) 通过以前的函数netif_rx;(2)通过NAPI机制。该中断处理程序调用 Network device的 netif_rx_schedule 函数,进入软中断处理流程,再调用 net_rx_action 函数。
- 该函数关闭中断,获取每个 Network device 的 rx_ring 中的所有 package,最终 pacakage 从 rx_ring 中被删除,进入 netif _receive_skb 处理流程。
- netif_receive_skb 是链路层接收数据报的最后一站。它根据注册在全局数组 ptype_all 和 ptype_base 里的网络层数据报类型,把数据报递交给不同的网络层协议的接收函数(INET域中主要是ip_rcv和arp_rcv)。该函数主要就是调用第三层协议的接收函数处理该skb包,进入第三层网络层处理。
4.2 网络层
-
IP 层的入口函数在 ip_rcv 函数。该函数首先会做包括 package checksum 在内的各种检查,如果需要的话会做 IP defragment(将多个分片合并),然后 packet 调用已经注册的 Pre-routing netfilter hook ,完成后最终到达 ip_rcv_finish 函数。
-
ip_rcv_finish 函数会调用 ip_router_input 函数,进入路由处理环节。它首先会调用 ip_route_input 来更新路由,然后查找 route,决定该 package 将会被发到本机还是会被转发还是丢弃:
-
- 如果是发到本机的话,调用 ip_local_deliver 函数,可能会做 de-fragment(合并多个 IP packet),然后调用 ip_local_deliver 函数。该函数根据 package 的下一个处理层的 protocal number,调用下一层接口,包括 tcp_v4_rcv (TCP), udp_rcv (UDP),icmp_rcv (ICMP),igmp_rcv(IGMP)。对于 TCP 来说,函数 tcp_v4_rcv 函数会被调用,从而处理流程进入 TCP 栈。
- 如果需要转发 (forward),则进入转发流程。该流程需要处理 TTL,再调用 dst_input 函数。该函数会 (1)处理 Netfilter Hook (2)执行 IP fragmentation (3)调用 dev_queue_xmit,进入链路层处理流程。
4.3 传输层
- 传输层 TCP 处理入口在 tcp_v4_rcv 函数(位于 linux/net/ipv4/tcp ipv4.c 文件中),它会做 TCP header 检查等处理。
- 调用 _tcp_v4_lookup,查找该 package 的 open socket。如果找不到,该 package 会被丢弃。接下来检查 socket 和 connection 的状态。
- 如果socket 和 connection 一切正常,调用 tcp_prequeue 使 package 从内核进入 user space,放进 socket 的 receive queue。然后 socket 会被唤醒,调用 system call,并最终调用 tcp_recvmsg 函数去从 socket recieve queue 中获取 segment。
4.4 应用层
- 每当用户应用调用 read 或者 recvfrom 时,该调用会被映射为/net/socket.c 中的 sys_recv 系统调用,并被转化为 sys_recvfrom 调用,然后调用 sock_recgmsg 函数。
- 对于 INET 类型的 socket,/net/ipv4/af inet.c 中的 inet_recvmsg 方法会被调用,它会调用相关协议的数据接收方法。
- 对 TCP 来说,调用 tcp_recvmsg。该函数从 socket buffer 中拷贝数据到 user buffer。
- 对 UDP 来说,从 user space 中可以调用三个 system call recv()/recvfrom()/recvmsg() 中的任意一个来接收 UDP package,这些系统调用最终都会调用内核中的 udp_recvmsg 方法。
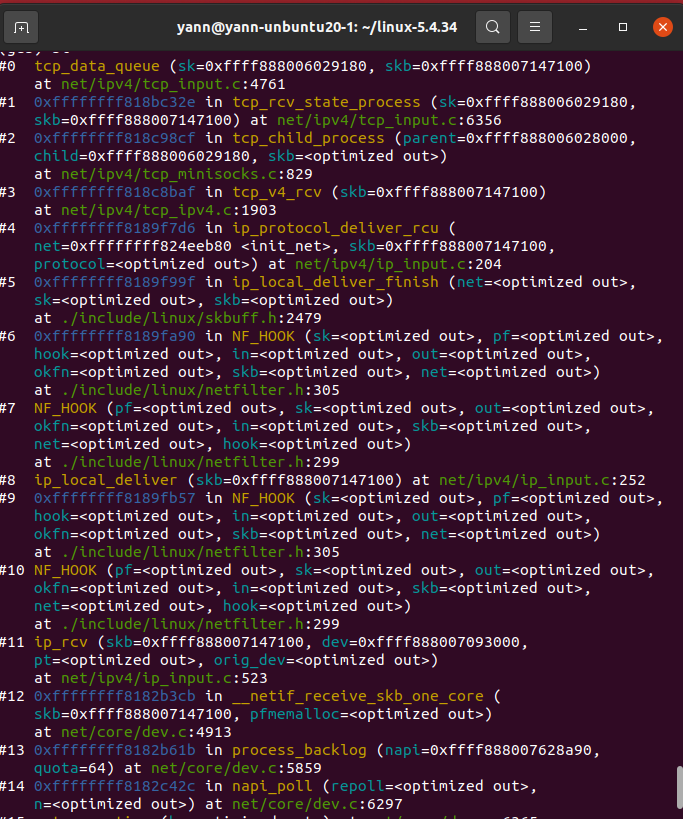
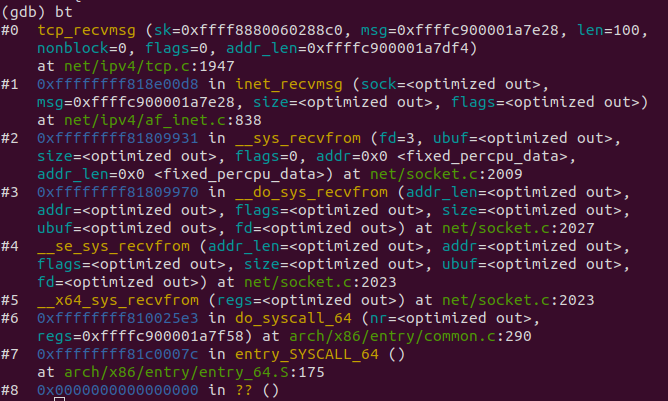
4.5 gdb调试
4.6 部分代码
net_rx_action
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
unsigned long time_limit = jiffies +
usecs_to_jiffies(netdev_budget_usecs);
int budget = netdev_budget;
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
if (list_empty(&list)) {
if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
goto out;
break;
}
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 ||
time_after_eq(jiffies, time_limit))) {
sd->time_squeeze++;
break;
}
}
local_irq_disable();
list_splice_tail_init(&sd->poll_list, &list);
list_splice_tail(&repoll, &list);
list_splice(&list, &sd->poll_list);
if (!list_empty(&sd->poll_list))
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
net_rps_action_and_irq_enable(sd);
out:
__kfree_skb_flush();
}
int ip_rcv
/*
* IP receive entry point
*/
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,
struct net_device *orig_dev)
{
struct net *net = dev_net(dev);
skb = ip_rcv_core(skb, net);
if (skb == NULL)
return NET_RX_DROP;
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
}
ip_rcv_finish
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
int ret;
/* if ingress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_rcv(skb);
if (!skb)
return NET_RX_SUCCESS;
ret = ip_rcv_finish_core(net, sk, skb, dev);
if (ret != NET_RX_DROP)
ret = dst_input(skb);
return ret;
}
tcp_data_queue
static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
bool fragstolen;
int eaten;
if (TCP_SKB_CB(skb)->seq == TCP_SKB_CB(skb)->end_seq) {
__kfree_skb(skb);
return;
}
skb_dst_drop(skb);
__skb_pull(skb, tcp_hdr(skb)->doff * 4);
tcp_ecn_accept_cwr(sk, skb);
tp->rx_opt.dsack = 0;
/* Queue data for delivery to the user.
* Packets in sequence go to the receive queue.
* Out of sequence packets to the out_of_order_queue.
*/
if (TCP_SKB_CB(skb)->seq == tp->rcv_nxt) {
if (tcp_receive_window(tp) == 0) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPZEROWINDOWDROP);
goto out_of_window;
}
/* Ok. In sequence. In window. */
queue_and_out:
if (skb_queue_len(&sk->sk_receive_queue) == 0)
sk_forced_mem_schedule(sk, skb->truesize);
else if (tcp_try_rmem_schedule(sk, skb, skb->truesize)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPRCVQDROP);
goto drop;
}
eaten = tcp_queue_rcv(sk, skb, &fragstolen);
if (skb->len)
tcp_event_data_recv(sk, skb);
if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)
tcp_fin(sk);
if (!RB_EMPTY_ROOT(&tp->out_of_order_queue)) {
tcp_ofo_queue(sk);
/* RFC5681. 4.2. SHOULD send immediate ACK, when
* gap in queue is filled.
*/
if (RB_EMPTY_ROOT(&tp->out_of_order_queue))
inet_csk(sk)->icsk_ack.pending |= ICSK_ACK_NOW;
}
if (tp->rx_opt.num_sacks)
tcp_sack_remove(tp);
tcp_fast_path_check(sk);
if (eaten > 0)
kfree_skb_partial(skb, fragstolen);
if (!sock_flag(sk, SOCK_DEAD))
tcp_data_ready(sk);
return;
}
if (!after(TCP_SKB_CB(skb)->end_seq, tp->rcv_nxt)) {
tcp_rcv_spurious_retrans(sk, skb);
/* A retransmit, 2nd most common case. Force an immediate ack. */
NET_INC_STATS(sock_net(sk), LINUX_MIB_DELAYEDACKLOST);
tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq);
out_of_window:
tcp_enter_quickack_mode(sk, TCP_MAX_QUICKACKS);
inet_csk_schedule_ack(sk);
drop:
tcp_drop(sk, skb);
return;
}
/* Out of window. F.e. zero window probe. */
if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt + tcp_receive_window(tp)))
goto out_of_window;
if (before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) {
/* Partial packet, seq < rcv_next < end_seq */
tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, tp->rcv_nxt);
/* If window is closed, drop tail of packet. But after
* remembering D-SACK for its head made in previous line.
*/
if (!tcp_receive_window(tp)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPZEROWINDOWDROP);
goto out_of_window;
}
goto queue_and_out;
}
tcp_data_queue_ofo(sk, skb);
}
tcp_recvmsg
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock,
int flags, int *addr_len)
{
struct tcp_sock *tp = tcp_sk(sk);
int copied = 0;
u32 peek_seq;
u32 *seq;
unsigned long used;
int err, inq;
int target; /* Read at least this many bytes */
long timeo;
struct sk_buff *skb, *last;
u32 urg_hole = 0;
struct scm_timestamping_internal tss;
int cmsg_flags;
if (unlikely(flags & MSG_ERRQUEUE))
return inet_recv_error(sk, msg, len, addr_len);
if (sk_can_busy_loop(sk) && skb_queue_empty_lockless(&sk->sk_receive_queue) &&
(sk->sk_state == TCP_ESTABLISHED))
sk_busy_loop(sk, nonblock);
lock_sock(sk);
err = -ENOTCONN;
if (sk->sk_state == TCP_LISTEN)
goto out;
cmsg_flags = tp->recvmsg_inq ? 1 : 0;
timeo = sock_rcvtimeo(sk, nonblock);
/* Urgent data needs to be handled specially. */
if (flags & MSG_OOB)
goto recv_urg;
if (unlikely(tp->repair)) {
err = -EPERM;
if (!(flags & MSG_PEEK))
goto out;
if (tp->repair_queue == TCP_SEND_QUEUE)
goto recv_sndq;
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out;
/* 'common' recv queue MSG_PEEK-ing */
}
seq = &tp->copied_seq;
if (flags & MSG_PEEK) {
peek_seq = tp->copied_seq;
seq = &peek_seq;
}
target = sock_rcvlowat(sk, flags & MSG_WAITALL, len);
do {
u32 offset;
/* Are we at urgent data? Stop if we have read anything or have SIGURG pending. */
if (tp->urg_data && tp->urg_seq == *seq) {
if (copied)
break;
if (signal_pending(current)) {
copied = timeo ? sock_intr_errno(timeo) : -EAGAIN;
break;
}
}
/* Next get a buffer. */
last = skb_peek_tail(&sk->sk_receive_queue);
skb_queue_walk(&sk->sk_receive_queue, skb) {
last = skb;
/* Now that we have two receive queues this
* shouldn't happen.
*/
if (WARN(before(*seq, TCP_SKB_CB(skb)->seq),
"TCP recvmsg seq # bug: copied %X, seq %X, rcvnxt %X, fl %X\n",
*seq, TCP_SKB_CB(skb)->seq, tp->rcv_nxt,
flags))
break;
offset = *seq - TCP_SKB_CB(skb)->seq;
if (unlikely(TCP_SKB_CB(skb)->tcp_flags & TCPHDR_SYN)) {
pr_err_once("%s: found a SYN, please report !\n", __func__);
offset--;
}
if (offset < skb->len)
goto found_ok_skb;
if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)
goto found_fin_ok;
WARN(!(flags & MSG_PEEK),
"TCP recvmsg seq # bug 2: copied %X, seq %X, rcvnxt %X, fl %X\n",
*seq, TCP_SKB_CB(skb)->seq, tp->rcv_nxt, flags);
}
/* Well, if we have backlog, try to process it now yet. */
if (copied >= target && !sk->sk_backlog.tail)
break;
if (copied) {
if (sk->sk_err ||
sk->sk_state == TCP_CLOSE ||
(sk->sk_shutdown & RCV_SHUTDOWN) ||
!timeo ||
signal_pending(current))
break;
} else {
if (sock_flag(sk, SOCK_DONE))
break;
if (sk->sk_err) {
copied = sock_error(sk);
break;
}
if (sk->sk_shutdown & RCV_SHUTDOWN)
break;
if (sk->sk_state == TCP_CLOSE) {
/* This occurs when user tries to read
* from never connected socket.
*/
copied = -ENOTCONN;
break;
}
if (!timeo) {
copied = -EAGAIN;
break;
}
if (signal_pending(current)) {
copied = sock_intr_errno(timeo);
break;
}
}
tcp_cleanup_rbuf(sk, copied);
if (copied >= target) {
/* Do not sleep, just process backlog. */
release_sock(sk);
lock_sock(sk);
} else {
sk_wait_data(sk, &timeo, last);
}
if ((flags & MSG_PEEK) &&
(peek_seq - copied - urg_hole != tp->copied_seq)) {
net_dbg_ratelimited("TCP(%s:%d): Application bug, race in MSG_PEEK\n",
current->comm,
task_pid_nr(current));
peek_seq = tp->copied_seq;
}
continue;
found_ok_skb:
/* Ok so how much can we use? */
used = skb->len - offset;
if (len < used)
used = len;
/* Do we have urgent data here? */
if (tp->urg_data) {
u32 urg_offset = tp->urg_seq - *seq;
if (urg_offset < used) {
if (!urg_offset) {
if (!sock_flag(sk, SOCK_URGINLINE)) {
WRITE_ONCE(*seq, *seq + 1);
urg_hole++;
offset++;
used--;
if (!used)
goto skip_copy;
}
} else
used = urg_offset;
}
}
if (!(flags & MSG_TRUNC)) {
err = skb_copy_datagram_msg(skb, offset, msg, used);
if (err) {
/* Exception. Bailout! */
if (!copied)
copied = -EFAULT;
break;
}
}
WRITE_ONCE(*seq, *seq + used);
copied += used;
len -= used;
tcp_rcv_space_adjust(sk);
skip_copy:
if (tp->urg_data && after(tp->copied_seq, tp->urg_seq)) {
tp->urg_data = 0;
tcp_fast_path_check(sk);
}
if (used + offset < skb->len)
continue;
if (TCP_SKB_CB(skb)->has_rxtstamp) {
tcp_update_recv_tstamps(skb, &tss);
cmsg_flags |= 2;
}
if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)
goto found_fin_ok;
if (!(flags & MSG_PEEK))
sk_eat_skb(sk, skb);
continue;
found_fin_ok:
/* Process the FIN. */
WRITE_ONCE(*seq, *seq + 1);
if (!(flags & MSG_PEEK))
sk_eat_skb(sk, skb);
break;
} while (len > 0);
/* According to UNIX98, msg_name/msg_namelen are ignored
* on connected socket. I was just happy when found this 8) --ANK
*/
/* Clean up data we have read: This will do ACK frames. */
tcp_cleanup_rbuf(sk, copied);
release_sock(sk);
if (cmsg_flags) {
if (cmsg_flags & 2)
tcp_recv_timestamp(msg, sk, &tss);
if (cmsg_flags & 1) {
inq = tcp_inq_hint(sk);
put_cmsg(msg, SOL_TCP, TCP_CM_INQ, sizeof(inq), &inq);
}
}
return copied;
out:
release_sock(sk);
return err;
recv_urg:
err = tcp_recv_urg(sk, msg, len, flags);
goto out;
recv_sndq:
err = tcp_peek_sndq(sk, msg, len);
goto out;
}
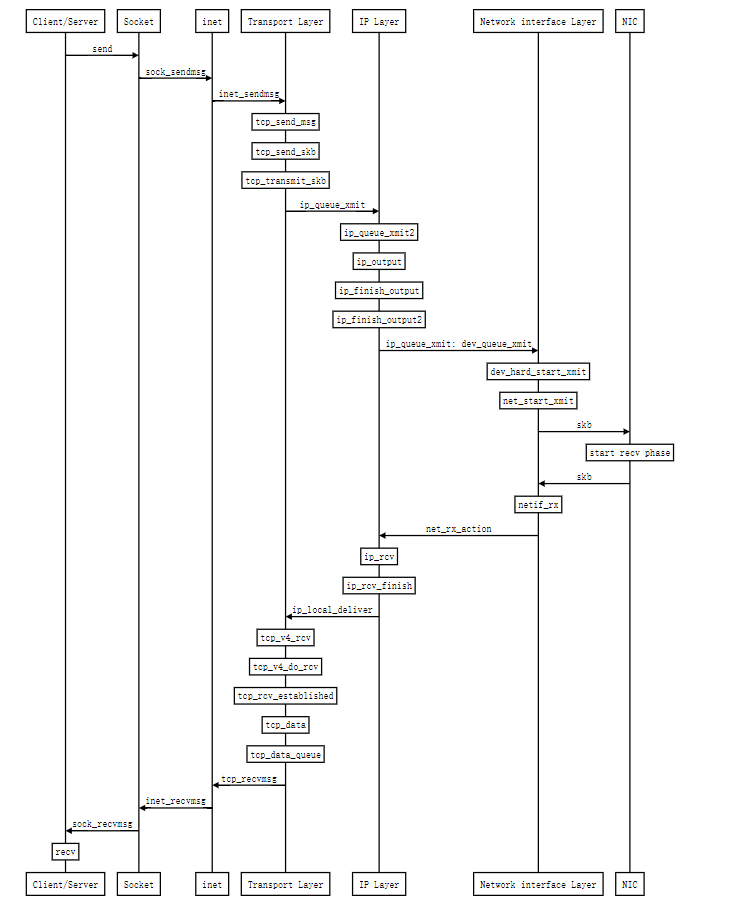
5. 时序图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号