
pyhton算法-深度优先【以爬取网页链接中的链接为例】
深度优先算法,python中主要是用栈来实现的【栈--先进后出】
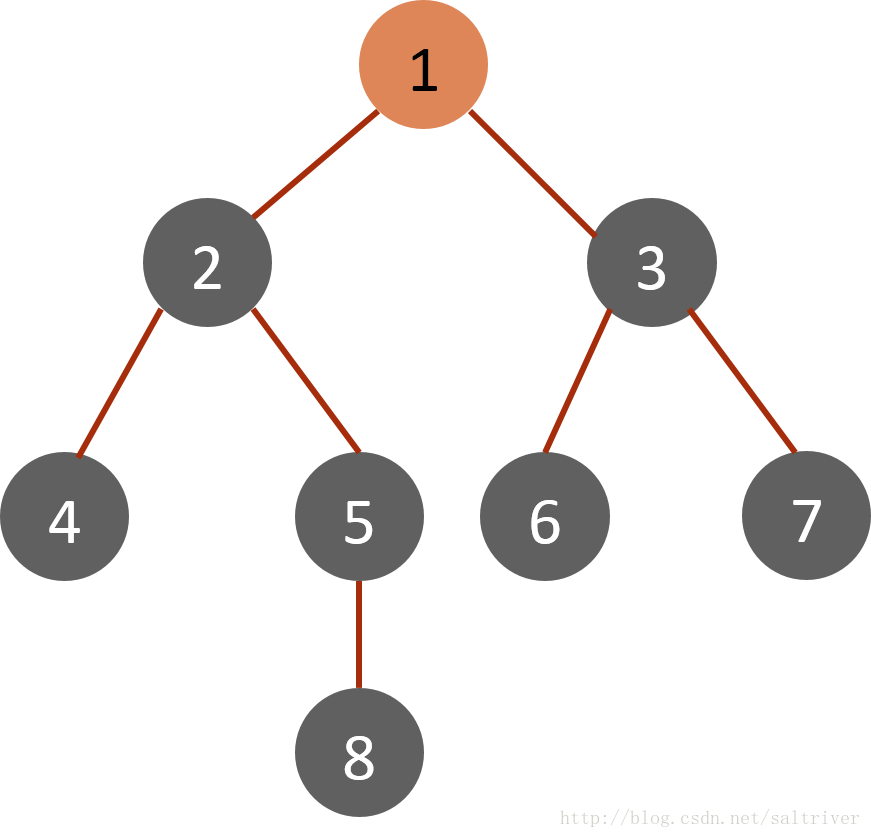
如图所示,从1开始作为根来计算,【将1,放进一个列表中[1]】然后解析1,得到的是23【将23放进队列中[2,3],1不在了的原因是在计算中1被计算完值后就拿出了列表】,然后再解析3,得到67【将6,7放进列表中[2,6,7]】,然后再解析7,6,解析2得到4,5【将45放进列表中[4,5]】,然后解析5,得到8【将8放进列表中[4,8]】然后解析8,4;结束
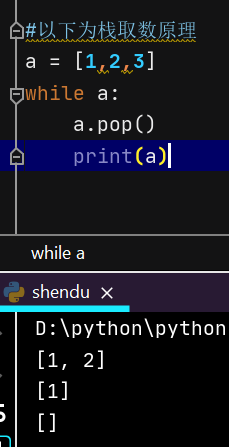
以下为栈pop方法的取数原理:
#以下为栈取数原理 a = [1,2,3] while a: a.pop() print(a)
接下来是写的解析网页的代码【以解析www.sougou.com为例,还可以添加一些条件来结束,新手还没学会】:
import sys import os import requests from bs4 import BeautifulSoup import requests from bs4 import BeautifulSoup import time def zhuaqu(rooturl): url_set = set() url_empty = [] url_list = [rooturl] #当列表不为空的时候开始算 while url_list != url_empty: print(url_list) #从列表中取数【先进后出,数会被直接拿出来】 url = url_list.pop() print("正在解析:{}".format(url)) #将已经解析过的url放进集合中 url_set.add(url) try: #获取页面的所有链接 html_doc = requests.get(url).content.decode() soup = BeautifulSoup(html_doc, 'html.parser') for tmp in soup.find_all('a'): url_1 = tmp.get("href") if url_1 not in url_set and "http:" in url_1: url_list.append(url_1) #捕获所有异常,并打印出来 except BaseException as e: print("无法访问{},错误信息{}".format(url,e)) rooturl = "https://www.sogou.com/" zhuaqu(rooturl)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号