
pyhton算法-宽度优先【以爬取网页链接中的链接为例】
宽度优先算法,在python中主要用的是队列(queue)
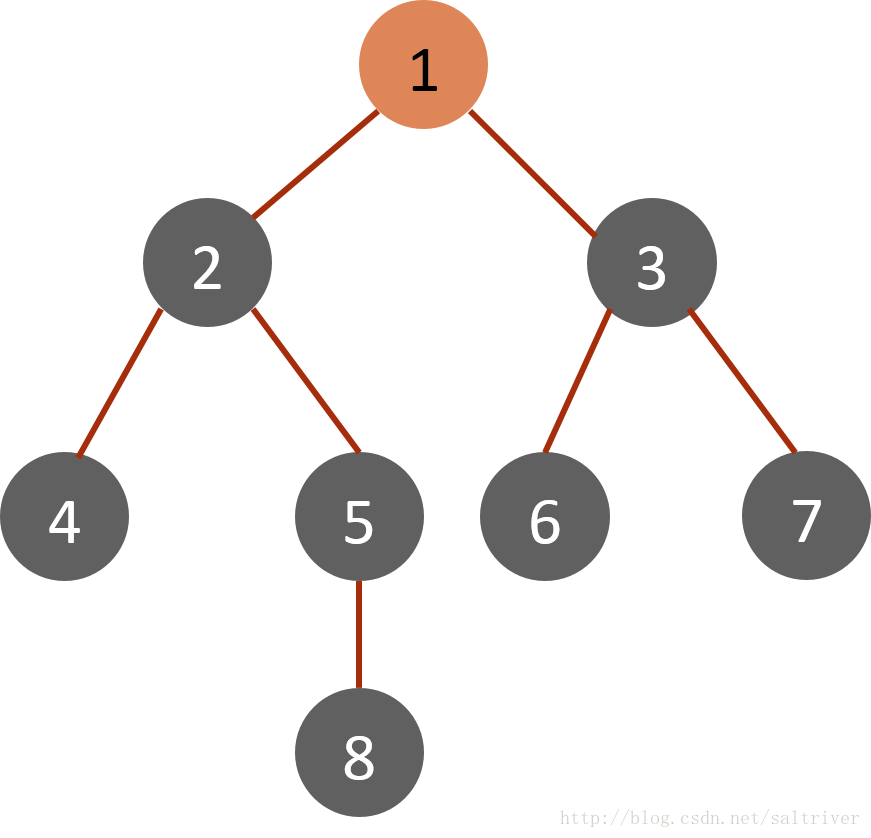
如图所示,从1开始作为根来计算,【将1,放进一个队列中[1]】然后解析1,得到的是23【将23放进队列中[2,3],1不在了的原因是在计算中1被计算完值后就拿出了列表】,然后再解析2,得到的是45【将45放进队列中[3,4,5]】,然后再解析3,得到67【将67放进队列中[4,5,6,7]】,最后解析5得到8【将8放进队列中[6,7,8],4先被解析了,然后才解析5】
from queue import Queue import sys import os import requests from bs4 import BeautifulSoup def zhuaqu(rootUrl,urls:Queue): fangWenGuoDeURL = set() urls.put(rootUrl) while not urls.empty(): currentUrl = urls.get() fangWenGuoDeURL.add(currentUrl) try: html = requests.get(currentUrl).text bs4 = BeautifulSoup(html, 'html.parser') for tmp in bs4.find_all("a"): url = tmp.get('href') if None != url and url.startswith("http") and(url not in fangWenGuoDeURL): print(url) urls.put(url) except BaseException as e: print(e) if __name__ == "__main__": root = "https://www.sina.com.cn/?from=kandian" urls = Queue() zhuaqu(root,urls)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号