
JVM排查案例-1
线上四台机器同一时间全部 OOM,到底发生了什么?
案发现场
昨天晚上突然短信收到 APM (即 Application Performance Management 的简称,我们内部自己搭建了这样一套系统来对应用的性能、可靠性进行线上的监控和预警的一种机制)大量告警 画外音: 监控是一种非常重要的发现问题的手段,没有的话一定要及时建立哦
紧接着运维打来电话告知线上部署的四台机器全部 OOM (out of memory, 内存不足),服务全部不可用,赶紧查看问题!
问题排查
首先运维先重启了机器,保证线上服务可用,然后再仔细地看了下线上的日志,确实是因为 OOM 导致服务不可用

第一时间想到 dump 当时的内存状态,但由于为了让线上尽快恢复服务,运维重启了机器,导致无法 dump 出事发时的内存。所以我又看了下我们 APM 中对 JVM 的监控图表
画外音:一种方式不行,尝试另外的角度切入!再次强调,监控非常重要!完善的监控能还原当时的事发现场,方便定位问题

不看不知道,一看吓一跳,从 16:00 开始应用中创建的线程居然每时每刻都在上升,一直到 3w 左右,重启后(蓝色箭头),线程也一直在不断增长),正常情况下的线程数是多少呢,600!问题找到了,
应该是在下午 16:00 左右发了一段有问题的代码,导致线程一直在创建,且创建的线程一直未消亡!
查看发布记录,发现发布记录只有这么一段可疑的代码 diff:在 HttpClient 初始化的时候额外加了一个 evictExpiredConnections 配置

问题定位了,应该是就是这个配置导致的!(线程上升的时间点和发布时间点完全吻合!),于是先把这个新加的配置给干掉上线,上线之后线程数果然恢复正常了。
那 evictExpiredConnections 做了什么导致线程数每时每刻在上升呢?这个配置又是为了解决什么问题而加上的呢?于是找到了相关同事来了解加这个配置的前因后果
还原事发经过
最近线上出现不少 NoHttpResponseException 的异常, 而上面那个配置就是为了解决这个异常而添加的,那是什么导致了这个异常呢?
在说这个问题之前我们得先了解一下 http 的 keep-alive 机制。
先看下正常的一个 TCP 连接的生命周期
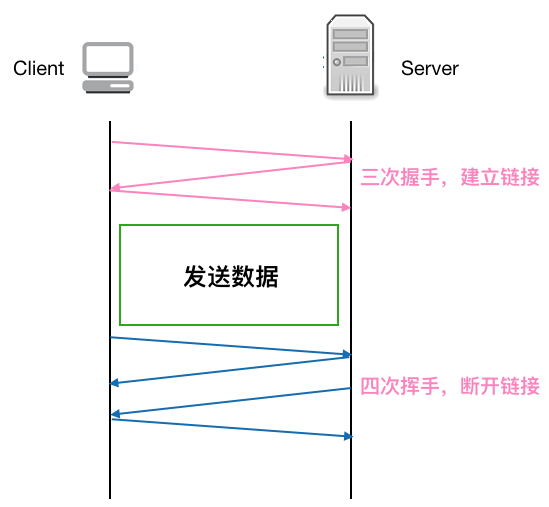
可以看到每个 TCP 连接都要经过三次握手建立连接后才能发送数据,要经过四次挥手才能断开连接,如果每个 TCP 连接在 server 返回 response 后都立马断开,
则发起多个 HTTP 请求就要多次创建断开 TCP, 这在 Http 请求很多的情况下无疑是很耗性能的, 如果在 server 返回 response 不立即断开 TCP 链接,而是复用这条链接进行下一次的 Http 请求,则无形中省略了很多创建 / 断开 TCP 的开销,性能上无疑会有很大提升。
如下图示,左图是不复用 TCP 发起多个 HTTP 请求的情况,右图是复用 TCP 的情况,可以看到发起三次 HTTP 请求,复用 TCP 的话可以省去两次建立 / 断开 TCP 的开销,
理论上一个应用只要开启一个 TCP 连接即可,其他 HTTP 请求都可以复用这个 TCP 连接,这样 n 次 HTTP 请求可以省去 n-1 次创建 / 断开 TCP 的开销。这对性能的提升无疑是有巨大的帮助。
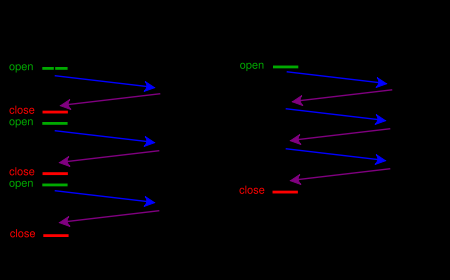
回过头来看 keep-alive (又称持久连接,连接复用)做的就是复用连接, 保证连接持久有效。
画外音: Http 1.1 之后 keep-alive 默认支持并开启,目前大部分网站都用了 http 1.1 了,也就是说大部分都默认支持连接复用了
天下没有免费的午餐 ,虽然 keep-alive 省去了很多不必要的握手/挥手操作,但由于连接长期保活,如果一直没有 http 请求的话,这条连接也就长期闲着了,会占用系统资源,有时反而会比复用连接带来更大的性能消耗。
所以我们一般会为 keep-alive 设置一个 timeout, 这样如果连接在设置的 timeout 时间内一直处于空闲状态(未发生任何数据传输),经过 timeout 时间后,连接就会释放,就能节省系统开销。
看起来给 keep-alive 加 timeout 是完美了,但是又引入了新的问题(一波已平,一波又起!),考虑如下情况:
如果服务端关闭连接,发送 FIN 包(注:在设置的 timeout 时间内服务端如果一直未收到客户端的请求,服务端会主动发起带 FIN 标志的请求以断开连接释放资源),
在这个 FIN 包发送但是还未到达客户端期间,客户端如果继续复用这个 TCP 连接发送 HTTP 请求报文的话,服务端会因为在四次挥手期间不接收报文而发送 RST 报文给客户端,客户端收到 RST 报文就会提示异常 (即 NoHttpResponseException)
我们再用流程图仔细梳理一下上述这种产生 NoHttpResponseException 的原因,这样能看得更明白一些
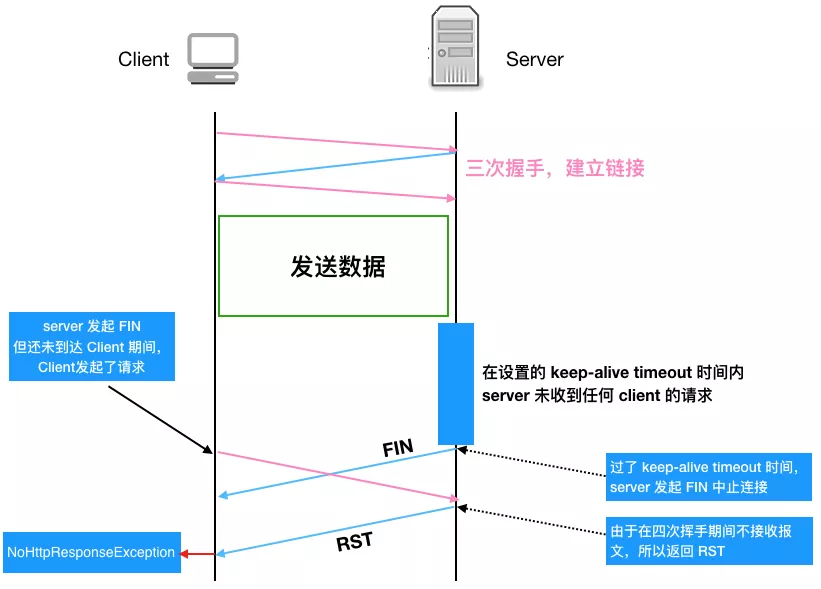
费了这么大的功夫,我们终于知道了产生 NoHttpResponseException 的原因,那该怎么解决呢,有两种策略
重试,收到异常后,重试一两次,由于重试后客户端会用有效的连接去请求,所以可以避免这种情况,不过一次要注意重试次数,避免引起雪崩!
设置一个定时线程,定时清理上述的闲置连接,可以将这个定时时间设置为 keep alive timeout 时间的一半以保证超时前回收。
evictExpiredConnections 就是用的上述第二种策略,来看下官方用法使用说明
Makes this instance of HttpClient proactively evict idle connections from the
connection pool using a background thread.
调用这个方法只会产生一个定时线程,那为啥应用中线程会一直增加呢,因为我们对每一个请求都创建了一个 HttpClient! 这样由于创建每一个 HttpClient 实例j时都会调用 evictExpiredConnections ,导致有多少请求就会创建多少个定时线程!
还有一个问题,为啥线上四台机器几乎同一时间点全挂呢?因为由于负载均衡,这四台机器的权重是一样的,硬件配置也一样,收到的请求其实也可以认为是差不多的,这样这四台机器由于创建 HttpClient 而生成的后台线程也在同一时间达到最高点,然后同时 OOM。
解决问题
所以针对以上提到的问题,我们首先把 HttpClient 改成了单例,这样保证服务启动后只会有一个定时清理线程,另外我们也让运维针对应用的线程数做了监控,如果超过某个阈值直接告警,这样能在应用 OOM 前及时发现处理。
画外音:再次强调,监控相当重要,能把问题扼杀在摇篮里!
总结
本文通过线上四台机器同时 OOM 的现象,来详细剖析定位了产生问题的原因,可以看到我们在应用某个库时首先要对这个库要有充分的了解(上述 HttpClient 的创建不用单例显然是个问题),
其次必要的网络知识还是需要的,所以要成为一个合格的程序员,不光对语言本身有所了解,还要对网络,数据库等也要有所涉猎,这些对排查问题以及性能调优等会有非常大的帮助,再次,完善的监控非常重要,通过触发某个阈值提前告警,可以将问题扼杀在摇篮里!
线上服务 CPU 100%?一键定位 so easy!
0、背景
经常做后端服务开发的同学,或多或少都遇到过 CPU 负载特别高的问题。尤其是在周末或大半夜,突然群里有人反馈线上机器负载特别高,不熟悉定位流程和思路的同学可能登上服务器一通手忙脚乱,定位过程百转千回。
对此,也有不少同学曾经整理过相关流程或方法论,类似把大象放进冰箱要几步,传统的方案一般是4步:
1. top oder by with P:1040 // 首先按进程负载排序找到 axLoad(pid)
2. top -Hp 进程PID:1073 // 找到相关负载 线程PID
3. printf “0x%x
”线程PID: 0x431 // 将线程PID转换为 16进制,为后面查找 jstack 日志做准备
4. jstack 进程PID | vim +/十六进制线程PID - // 例如:jstack 1040|vim +/0x431 -
但是对于线上问题定位来说,分秒必争,上面的 4 步还是太繁琐耗时了,有没有可能封装成为一个工具,在有问题的时候一键定位,秒级找到有问题的代码行呢?
当然可以!工具链的成熟与否不仅体现了一个开发者的运维能力,也体现了开发者的效率意识。淘宝的oldratlee 同学就将上面的流程封装为了一个工具:show-busy-java-threads.sh(https://github.com/oldratlee/useful-scripts),可以很方便的定位线上的这类问题,下面我会举两个例子来看实际的效果。
快速安装使用:
source <(curl -fsSL https://raw.githubusercontent.com/oldratlee/useful-scripts/master/test-cases/self-installer.sh)
一、java 正则表达式回溯造成 CPU 100%
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexLoad {
public static void main(String[] args) {
String[] patternMatch = {"([\w\s]+)+([+\-/*])+([\w\s]+)",
"([\w\s]+)+([+\-/*])+([\w\s]+)+([+\-/*])+([\w\s]+)"};
List<String> patternList = new ArrayList<String>();
patternList.add("Avg Volume Units product A + Volume Units product A");
patternList.add("Avg Volume Units / Volume Units product A");
patternList.add("Avg retailer On Hand / Volume Units Plan / Store Count");
patternList.add("Avg Hand Volume Units Plan Store Count");
patternList.add("1 - Avg merchant Volume Units");
patternList.add("Total retailer shipment Count");
for (String s :patternList ){
for(int i=0;i<patternMatch.length;i++){
Pattern pattern = Pattern.compile(patternMatch[i]);
Matcher matcher = pattern.matcher(s);
System.out.println(s);
if (matcher.matches()) {
System.out.println("Passed");
}else
System.out.println("Failed;");
}
}
}
}
编译、运行上述代码之后,咱们就能观察到服务器多了一个 100% CPU 的 java 进程:
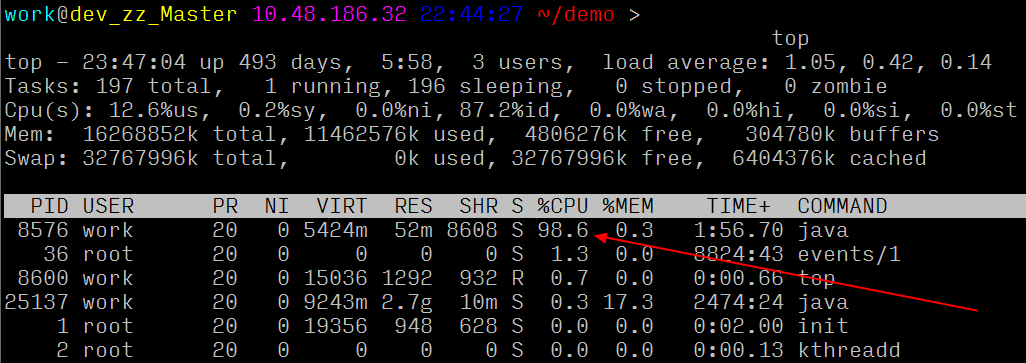
怎么使用呢?
show-busy-java-threads.sh
# 从 所有的 Java进程中找出最消耗CPU的线程(缺省5个),打印出其线程栈。
show-busy-java-threads.sh -c <要显示的线程栈数>
show-busy-java-threads.sh -c <要显示的线程栈数> -p <指定的Java Process>
# -F选项:执行jstack命令时加上-F选项(强制jstack),一般情况不需要使用
show-busy-java-threads.sh -p <指定的Java Process> -F
show-busy-java-threads.sh -s <指定jstack命令的全路径>
# 对于sudo方式的运行,JAVA_HOME环境变量不能传递给root,
# 而root用户往往没有配置JAVA_HOME且不方便配置,
# 显式指定jstack命令的路径就反而显得更方便了
show-busy-java-threads.sh -a <输出记录到的文件>
show-busy-java-threads.sh -t <重复执行的次数> -i <重复执行的间隔秒数>
# 缺省执行一次;执行间隔缺省是3秒
##############################
# 注意:
##############################
# 如果Java进程的用户 与 执行脚本的当前用户 不同,则jstack不了这个Java进程。
# 为了能切换到Java进程的用户,需要加sudo来执行,即可以解决:
sudo show-busy-java-threads.sh
示例:
work@dev_zz_Master 10.48.186.32 23:45:50 ~/demo >
bash show-busy-java-threads.sh
[1] Busy(96.2%) thread(8577/0x2181) stack of java process(8576) under user(work):
"main" prio=10 tid=0x00007f0c64006800 nid=0x2181 runnable [0x00007f0c6a64a000]
java.lang.Thread.State: RUNNABLE
at java.util.regex.Pattern$GroupHead.match(Pattern.java:4168)
at java.util.regex.Pattern$Loop.match(Pattern.java:4295)
...
at java.util.regex.Matcher.match(Matcher.java:1127)
at java.util.regex.Matcher.matches(Matcher.java:502)
at RegexLoad.main(RegexLoad.java:27)
[2] Busy(1.5%) thread(8591/0x218f) stack of java process(8576) under user(work):
"C2 CompilerThread1" daemon prio=10 tid=0x00007f0c64095800 nid=0x218f waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
[3] Busy(0.8%) thread(8590/0x218e) stack of java process(8576) under user(work):
"C2 CompilerThread0" daemon prio=10 tid=0x00007f0c64093000 nid=0x218e waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
[4] Busy(0.2%) thread(8593/0x2191) stack of java process(8576) under user(work):
"VM Periodic Task Thread" prio=10 tid=0x00007f0c640a2800 nid=0x2191 waiting on condition
[5] Busy(0.1%) thread(25159/0x6247) stack of java process(25137) under user(work):
"VM Periodic Task Thread" prio=10 tid=0x00007f13340b4000 nid=0x6247 waiting on condition
work@dev_zz_Master 10.48.186.32 23:46:04 ~/demo >
可以看到,一键直接定位异常代码行,是不是很方便?
二、线程死锁,程序 hang 住
import java.util.*;
public class SimpleDeadLock extends Thread {
public static Object l1 = new Object();
public static Object l2 = new Object();
private int index;
public static void main(String[] a) {
Thread t1 = new Thread1();
Thread t2 = new Thread2();
t1.start();
t2.start();
}
private static class Thread1 extends Thread {
public void run() {
synchronized (l1) {
System.out.println("Thread 1: Holding lock 1...");
try { Thread.sleep(10); }
catch (InterruptedException e) {}
System.out.println("Thread 1: Waiting for lock 2...");
synchronized (l2) {
System.out.println("Thread 2: Holding lock 1 & 2...");
}
}
}
}
private static class Thread2 extends Thread {
public void run() {
synchronized (l2) {
System.out.println("Thread 2: Holding lock 2...");
try { Thread.sleep(10); }
catch (InterruptedException e) {}
System.out.println("Thread 2: Waiting for lock 1...");
synchronized (l1) {
System.out.println("Thread 2: Holding lock 2 & 1...");
}
}
}
}
}
执行之后的效果:

如何用工具定位:
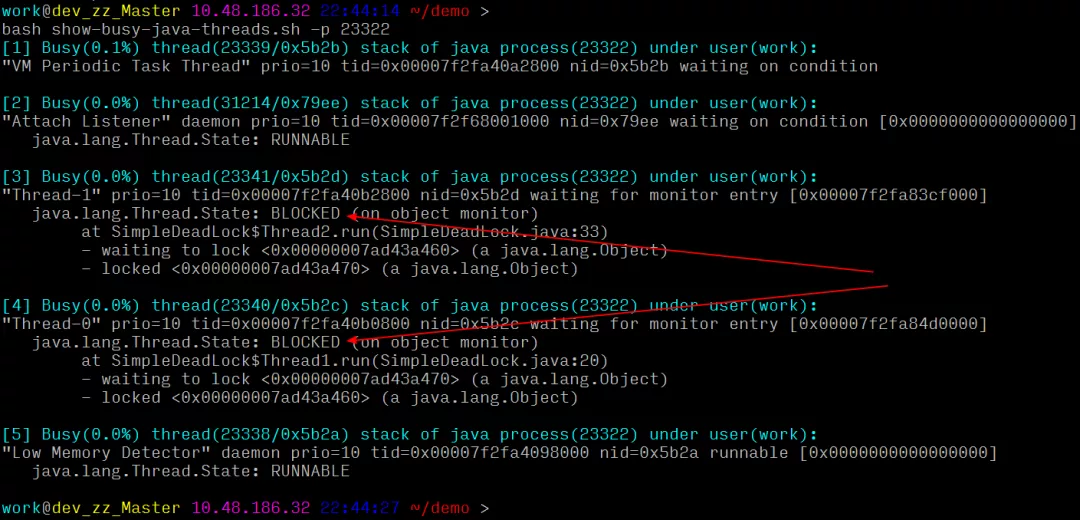
一键定位:可以清晰的看到线程互相锁住了对方等待的资源,导致死锁,直接定位到代码行和具体原因。
通过上面两个例子,我想各位同学应该对这个工具和工具能解决什么问题有了比较深刻的了解了,遇到 CPU 100% 问题可以从此不再慌乱。但是更多的还是依赖大家自己去实践,毕竟实践出真知嘛~
三、免费实用的脚本工具大礼包
除了正文提到的 show-busy-java-threads.sh,oldratlee 同学还整合和不少常见的开发、运维过程中涉及到的脚本工具,觉得特别有用的我简单列下:
(1)show-duplicate-java-classes
偶尔会遇到本地开发、测试都正常,上线后却莫名其妙的 class 异常,历经千辛万苦找到的原因竟然是 Jar冲突!这个工具就可以找出Java Lib(Java库,即Jar文件)或Class目录(类目录)中的重复类。
Java开发的一个麻烦的问题是Jar冲突(即多个版本的Jar),或者说重复类。会出NoSuchMethod等的问题,还不见得当时出问题。找出有重复类的Jar,可以防患未然。
# 查找当前目录下所有Jar中的重复类
show-duplicate-java-classes
# 查找多个指定目录下所有Jar中的重复类
show-duplicate-java-classes path/to/lib_dir1 /path/to/lib_dir2
# 查找多个指定Class目录下的重复类。Class目录 通过 -c 选项指定
show-duplicate-java-classes -c path/to/class_dir1 -c /path/to/class_dir2
# 查找指定Class目录和指定目录下所有Jar中的重复类的Jar
show-duplicate-java-classes path/to/lib_dir1 /path/to/lib_dir2 -c path/to/class_dir1 -c path/to/class_dir2
例如:
# 在war模块目录下执行,生成war文件
$ mvn install
...
# 解压war文件,war文件中包含了应用的依赖的Jar文件
$ unzip target/*.war -d target/war
...
# 检查重复类
$ show-duplicate-java-classes -c target/war/WEB-INF/classes target/war/WEB-INF/lib
...
(2)find-in-jars
在当前目录下所有jar文件里,查找类或资源文件。
用法:注意,后面Pattern是grep的 扩展正则表达式。
find-in-jars 'log4j.properties'
find-in-jars 'log4j.xml$' -d /path/to/find/directory
find-in-jars log4j\.xml
find-in-jars 'log4j.properties|log4j.xml'
示例:
$ ./find-in-jars 'Service.class$'
./WEB-INF/libs/spring-2.5.6.SEC03.jar!org/springframework/stereotype/Service.class
./rpc-benchmark-0.0.1-SNAPSHOT.jar!com/taobao/rpc/benchmark/service/HelloService.class
(3)housemd pid [java_home]
很早的时候,我们使用BTrace排查问题,在感叹BTrace的强大之余,也曾好几次将线上系统折腾挂掉。2012年淘宝的聚石写了HouseMD,将常用的几个Btrace脚本整合在一起形成一个独立风格的应用,
其核心代码用的是Scala,HouseMD是基于字节码技术的诊断工具,
因此除了Java以外, 任何最终以字节码形式运行于JVM之上的语言, HouseMD都支持对它们进行诊断, 如Clojure(感谢@Killme2008提供了它的使用入门), scala, Groovy, JRuby, Jython, kotlin等.
使用housemd对java程序进行运行时跟踪,支持的操作有:
查看加载类
跟踪方法
查看环境变量
查看对象属性值
详细信息请参考: https://github.com/CSUG/HouseMD/wiki/UserGuideCN
(4)jvm pid
执行jvm debug工具,包含对java栈、堆、线程、gc等状态的查看,支持的功能有:
========线程相关=======
1 : 查看占用cpu最高的线程情况
2 : 打印所有线程
3 : 打印线程数
4 : 按线程状态统计线程数
========GC相关=======
5 : 垃圾收集统计(包含原因)可以指定间隔时间及执行次数,默认1秒, 10次
6 : 显示堆中各代的空间可以指定间隔时间及执行次数,默认1秒,5次
7 : 垃圾收集统计。可以指定间隔时间及执行次数,默认1秒, 10次
8 : 打印perm区内存情况*会使程序暂停响应*
9 : 查看directbuffer情况
========堆对象相关=======
10 : dump heap到文件*会使程序暂停响应*默认保存到`pwd`/dump.bin,可指定其它路径
11 : 触发full gc。*会使程序暂停响应*
12 : 打印jvm heap统计*会使程序暂停响应*
13 : 打印jvm heap中top20的对象。*会使程序暂停响应*参数:1:按实例数量排序,2:按内存占用排序,默认为1
14 : 触发full gc后打印jvm heap中top20的对象。*会使程序暂停响应*参数:1:按实例数量排序,2:按内存占用排序,默认为1
15 : 输出所有类装载器在perm里产生的对象。可以指定间隔时间及执行次数
========其它=======
16 : 打印finalzer队列情况
17 : 显示classloader统计
18 : 显示jit编译统计
19 : 死锁检测
20 : 等待X秒,默认为1
q : exit
进入jvm工具后可以输入序号执行对应命令
可以一次执行多个命令,用分号";"分隔,如:1;3;4;5;6
每个命令可以带参数,用冒号":"分隔,同一命令的参数之间用逗号分隔,如:
Enter command queue:1;5:1000,100;10:/data1/output.bin
(5)greys[@IP:PORT]
PS:目前Greys仅支持Linux/Unix/Mac上的Java6+,Windows暂时无法支持
Greys是一个JVM进程执行过程中的异常诊断工具,可以在不中断程序执行的情况下轻松完成问题排查工作。和HouseMD一样,Greys-Anatomy取名同名美剧“实习医生格蕾”,目的是向前辈致敬。代码编写的时候参考了BTrace和HouseMD两个前辈的思路。
使用greys对java程序进行运行时跟踪(不传参数,需要先greys -C pid,再greys)。支持的操作有:
查看加载类,方法信息
查看JVM当前基础信息
方法执行监控(调用量,失败率,响应时间等)
方法执行数据观测、记录与回放(参数,返回结果,异常信息等)
方法调用追踪渲染
详细信息请参考: https://github.com/oldmanpushcart/greys-anatomy/wiki
(6)sjksjk --commands sjk --help
使用sjk对Java诊断、性能排查、优化工具
ttop:监控指定jvm进程的各个线程的cpu使用情况
jps: 强化版
hh: jmap -histo强化版
gc: 实时报告垃圾回收信息
更多信息请参考: https://github.com/aragozin/jvm-tools
在服务器上排除问题的头 5 分钟
一、尽可能搞清楚问题的前因后果
不要一下子就扎到服务器前面,你需要先搞明白对这台服务器有多少已知的情况,还有故障的具体情况。不然你很可能就是在无的放矢。
必须搞清楚的问题有:
故障的表现是什么?无响应?报错?
故障是什么时候发现的?
故障是否可重现?
有没有出现的规律(比如每小时出现一次)
最后一次对整个平台进行更新的内容是什么(代码、服务器等)?
故障影响的特定用户群是什么样的(已登录的, 退出的, 某个地域的…)?
基础架构(物理的、逻辑的)的文档是否能找到?
是否有监控平台可用? (比如Munin、Zabbix、 Nagios、 New Relic… 什么都可以)
是否有日志可以查看?. (比如Loggly、Airbrake、 Graylog…)
最后两个是最方便的信息来源,不过别抱太大希望,基本上它们都不会有。只能再继续摸索了。
二、有谁在?
$ w
$ last
用这两个命令看看都有谁在线,有哪些用户访问过。这不是什么关键步骤,不过最好别在其他用户正干活的时候来调试系统。有道是一山不容二虎嘛。(ne cook in the kitchen is enough.)
三、之前发生了什么?
$ history
查看一下之前服务器上执行过的命令。看一下总是没错的,加上前面看的谁登录过的信息,应该有点用。另外作为admin要注意,不要利用自己的权限去侵犯别人的隐私哦。
到这里先提醒一下,等会你可能会需要更新 HISTTIMEFORMAT 环境变量来显示这些命令被执行的时间。对要不然光看到一堆不知道啥时候执行的命令,同样会令人抓狂的。
四、现在在运行的进程是啥?
$ pstree -a
$ ps aux
这都是查看现有进程的。ps aux 的结果比较杂乱, pstree -a 的结果比较简单明了,可以看到正在运行的进程及相关用户。
五、监听的网络服务
$ netstat -ntlp
$ netstat -nulp
$ netstat -nxlp
我一般都分开运行这三个命令,不想一下子看到列出一大堆所有的服务。netstat -nalp倒也可以。不过我绝不会用 numeric 选项 (鄙人一点浅薄的看法:IP 地址看起来更方便)。
找到所有正在运行的服务,检查它们是否应该运行。查看各个监听端口。在netstat显示的服务列表中的PID 和 ps aux 进程列表中的是一样的。
如果服务器上有好几个Java或者Erlang什么的进程在同时运行,能够按PID分别找到每个进程就很重要了。
通常我们建议每台服务器上运行的服务少一点,必要时可以增加服务器。如果你看到一台服务器上有三四十个监听端口开着,那还是做个记录,回头有空的时候清理一下,重新组织一下服务器。
六、CPU 和内存
$ free -m
$ uptime
$ top
$ htop
注意以下问题:
还有空余的内存吗? 服务器是否正在内存和硬盘之间进行swap?
还有剩余的CPU吗? 服务器是几核的? 是否有某些CPU核负载过多了?
服务器最大的负载来自什么地方? 平均负载是多少?
七、硬件
$ lspci
$ dmidecode
$ ethtool
有很多服务器还是裸机状态,可以看一下:
找到RAID 卡 (是否带BBU备用电池?)、 CPU、空余的内存插槽。根据这些情况可以大致了解硬件问题的来源和性能改进的办法。
网卡是否设置好? 是否正运行在半双工状态? 速度是10MBps? 有没有 TX/RX 报错?
八、IO 性能
$ iostat -kx 2
$ vmstat 2 10
$ mpstat 2 10
$ dstat --top-io --top-bio
这些命令对于调试后端性能非常有用。
检查磁盘使用量:服务器硬盘是否已满?
是否开启了swap交换模式 (si/so)?
CPU被谁占用:系统进程? 用户进程? 虚拟机?
dstat 是我的最爱。用它可以看到谁在进行 IO: 是不是MySQL吃掉了所有的系统资源? 还是你的PHP进程?
九、挂载点 和 文件系统
$ mount
$ cat /etc/fstab
$ vgs
$ pvs
$ lvs
$ df -h
$ lsof +D / /* beware not to kill your box */
一共挂载了多少文件系统?
有没有某个服务专用的文件系统? (比如MySQL?)
文件系统的挂载选项是什么:noatime? default? 有没有文件系统被重新挂载为只读模式了?
磁盘空间是否还有剩余?
是否有大文件被删除但没有清空?
如果磁盘空间有问题,你是否还有空间来扩展一个分区?
十、内核、中断和网络
$ sysctl -a | grep ...
$ cat /proc/interrupts
$ cat /proc/net/ip_conntrack /* may take some time on busy servers */
$ netstat
$ ss -s
你的中断请求是否是均衡地分配给CPU处理,还是会有某个CPU的核因为大量的网络中断请求或者RAID请求而过载了?
SWAP交换的设置是什么?对于工作站来说swappinness 设为 60 就很好, 不过对于服务器就太糟了:你最好永远不要让服务器做SWAP交换,不然对磁盘的读写会锁死SWAP进程。
conntrack_max 是否设的足够大,能应付你服务器的流量?
在不同状态下(TIME_WAIT, …)TCP连接时间的设置是怎样的?
如果要显示所有存在的连接,netstat 会比较慢, 你可以先用 ss 看一下总体情况。
你还可以看一下 Linux TCP tuning 了解网络性能调优的一些要点。
十一、系统日志和内核消息
$ dmesg
$ less /var/log/messages
$ less /var/log/secure
$ less /var/log/auth
查看错误和警告消息,比如看看是不是很多关于连接数过多导致?
看看是否有硬件错误或文件系统错误?
分析是否能将这些错误事件和前面发现的疑点进行时间上的比对。
十二、定时任务
$ ls /etc/cron* + cat
$ for user in $(cat /etc/passwd | cut -f1 -d:); do crontab -l -u $user; done
是否有某个定时任务运行过于频繁?
是否有些用户提交了隐藏的定时任务?
在出现故障的时候,是否正好有某个备份任务在执行?
十三、应用系统日志
这里边可分析的东西就多了, 不过恐怕你作为运维人员是没功夫去仔细研究它的。关注那些明显的问题,比如在一个典型的LAMP(Linux+Apache+Mysql+Perl)应用环境里:
Apache & Nginx; 查找访问和错误日志, 直接找 5xx 错误, 再看看是否有 limit_zone错误。
MySQL; 在mysql.log找错误消息,看看有没有结构损坏的表, 是否有innodb修复进程在运行,是否有disk/index/query 问题.
PHP-FPM; 如果设定了 php-slow 日志, 直接找错误信息 (php, mysql, memcache, …),如果没设定,赶紧设定。
Varnish; 在varnishlog 和 varnishstat 里, 检查 hit/miss比. 看看配置信息里是否遗漏了什么规则,使最终用户可以直接攻击你的后端?
HA-Proxy; 后端的状况如何?健康状况检查是否成功?是前端还是后端的队列大小达到最大值了?
结论
经过这5分钟之后,你应该对如下情况比较清楚了:
在服务器上运行的都是些啥?
这个故障看起来是和 IO/硬件/网络 或者 系统配置 (有问题的代码、系统内核调优, …)相关。
这个故障是否有你熟悉的一些特征?比如对数据库索引使用不当,或者太多的apache后台进程。
你甚至有可能找到真正的故障源头。就算还没有找到,搞清楚了上面这些情况之后,你现在也具备了深挖下去的条件。继续努力吧!
Java进程CPU占用高导致的网页请求超时的故障排查
一、发现问题的系统检查:
一个管理平台门户网页进统计页面提示请求超时,随进服务器操作系统检查load average超过4负载很大,PID为7163的进程占用到了800%多。
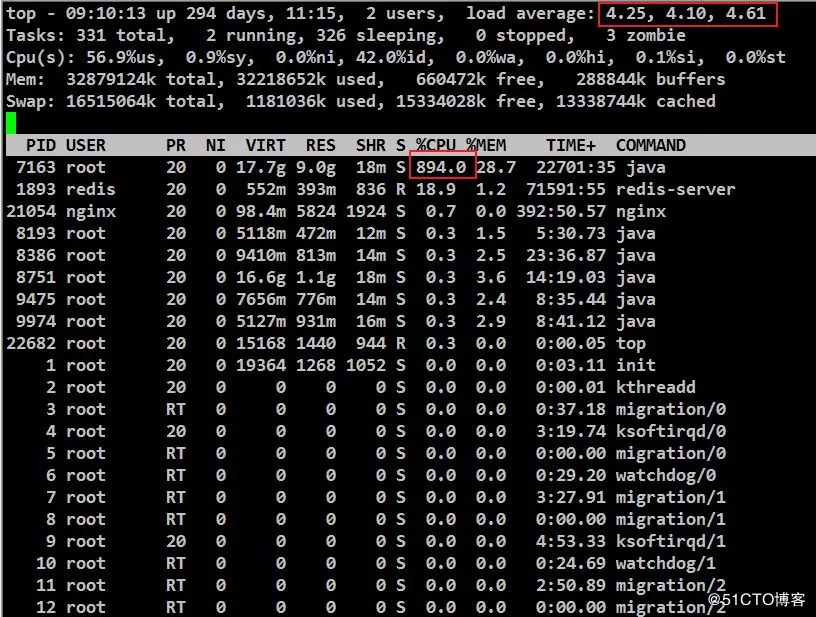
二、定位故障
根据这种故障的一般处理思路,先找出问题进程内CPU占用率高的线程,再通过线程栈信息找出该线程当时在运行的问题代码段,操作如下:
2.1、根据思路查看高占用的“进程中”占用高的“线程”,追踪发现7163的进程中16298的线程占用较高,使用命令:
top -Hbp 7163 | awk '/java/ && $9>50'
显示结果:
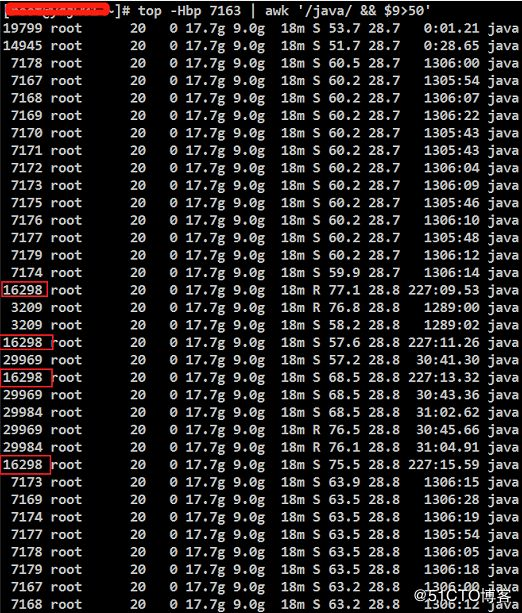
2.2、将16298的线程ID转换为16进制的线程ID。
printf "%x\n" 16298
3faa
2.3、通过jvm的jstack查看进程信息,发现是调用数据库的问题。
jstack 7163 | grep "3faa" -A 30
显示结果:

2.4、既然是数据库的问题就检查数据库,思路是先打印了所有在跑的数据库线程,检查后发现跟进情况找到问题表:
2.4.1、打印mysql现有进程信息,并把信息生成log文件,使用的命令如下:
mysql -uroot -p -e "show full processlist" > mysql_full_process.log
2.4.2、过滤log文件,发现查询最多的表,使用的命令如下:
grep Query mysql_full_process.log
2.4.3、确认表中数据量,发现表中已经有将近300万条数据,判断问题是查询时间过长导致的,使用的命令如下:
use databases_name;
select count(1) from table_name;
2.4.4、确认表是否有索引,发现表未创建索引;
show create table table_name\G
三、确认及处理问题:
询问了研发表的数据是否重要,确认不重要,检查字段有时间字段,根据时间确认只留一个月的数据,操作如下:
3.1、清理数据只保留一个月的数据,清理后数据只剩下4000多,使用命令如下;
delete from table_name where xxxx_time < '2019-07-01 00:00:00' or xxxx_time is null;
3.2、由于表未加索引,所以给表创建索引,使用命令如下:
alter table table_name add index (device_uuid);
3.3、检查索引是否创建,已经有device_uuid的索引。
show create table table_name;
四、结果:
处理后进程的CPU占用到了40%,本次排查主要用到了jvm进程查看及dump进程详细信息的操作,确认是由数据库问题导致的原因,并对数据库进行了清理并创建了索引。
五、其他:
在处理问题后,又查询了一下数据库相关问题的优化,有方案说在mysql配置文件中添加innodb_buffer_pool_size参数也可以优化查询查询时间,
但该参数的意义把数据放到内存了,也就是说如果数据更新了,还会导致buffer失效,通常的优化方法还是添加索引。该方法添加参数具体如下:
innodb_buffer_pool_size=4G
面试官:如果你们的系统 CPU 突然飙升且 GC 频繁,如何排查?
处理过线上问题的同学基本上都会遇到系统突然运行缓慢,CPU 100%,以及Full GC次数过多的问题。
当然,这些问题的最终导致的直观现象就是系统运行缓慢,并且有大量的报警。
本文主要针对系统运行缓慢这一问题,提供该问题的排查思路,从而定位出问题的代码点,进而提供解决该问题的思路。
对于线上系统突然产生的运行缓慢问题,如果该问题导致线上系统不可用,那么首先需要做的就是,导出jstack和内存信息,然后重启系统,尽快保证系统的可用性。
这种情况可能的原因主要有两种:
代码中某个位置读取数据量较大,导致系统内存耗尽,从而导致Full GC次数过多,系统缓慢;
代码中有比较耗CPU的操作,导致CPU过高,系统运行缓慢;相对来说,这是出现频率最高的两种线上问题,而且它们会直接导致系统不可用。
另外有几种情况也会导致某个功能运行缓慢,但是不至于导致系统不可用:
代码某个位置有阻塞性的操作,导致该功能调用整体比较耗时,但出现是比较随机的;
某个线程由于某种原因而进入WAITING状态,此时该功能整体不可用,但是无法复现;
由于锁使用不当,导致多个线程进入死锁状态,从而导致系统整体比较缓慢。
对于这三种情况,通过查看CPU和系统内存情况是无法查看出具体问题的,因为它们相对来说都是具有一定阻塞性操作,CPU和系统内存使用情况都不高,但是功能却很慢。
下面我们就通过查看系统日志来一步一步甄别上述几种问题。
1. Full GC次数过多
相对来说,这种情况是最容易出现的,尤其是新功能上线时。对于Full GC较多的情况,其主要有如下两个特征:
线上多个线程的CPU都超过了100%,通过jstack命令可以看到这些线程主要是垃圾回收线程
通过jstat命令监控GC情况,可以看到Full GC次数非常多,并且次数在不断增加。
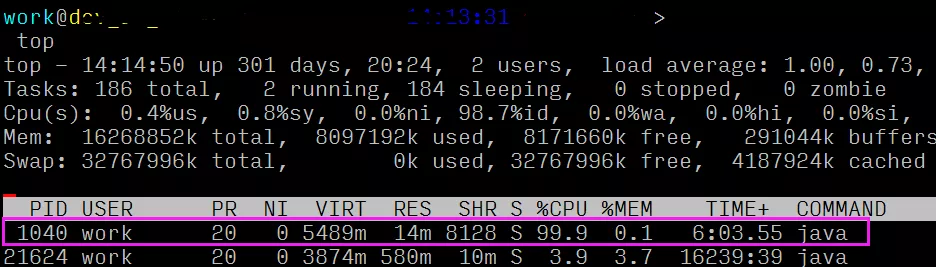
首先我们可以使用 top命令查看系统CPU的占用情况,如下是系统CPU较高的一个示例:
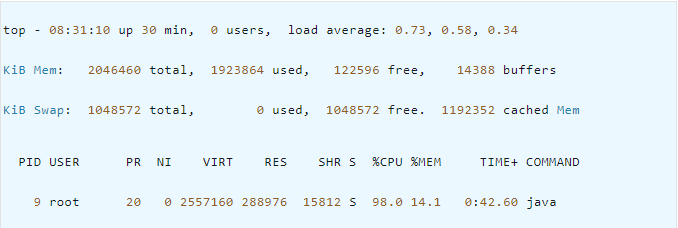
可以看到,有一个Java程序此时CPU占用量达到了98.8%,此时我们可以复制该进程id 9,并且使用如下命令查看呢该进程的各个线程运行情况:

该进程下的各个线程运行情况如下:
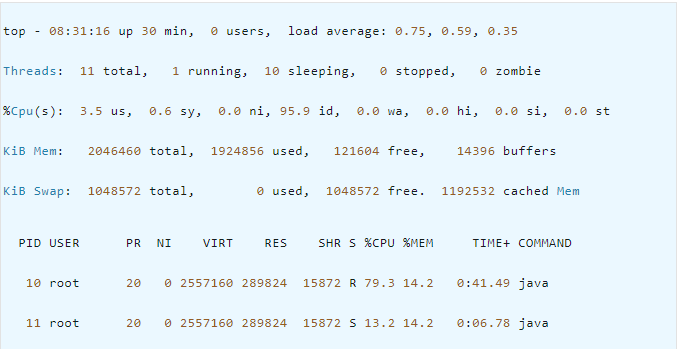
可以看到,在进程为 9的Java程序中各个线程的CPU占用情况,接下来我们可以通过jstack命令查看线程id为 10的线程为什么耗费CPU最高。
需要注意的是,在jsatck命令展示的结果中,线程id都转换成了十六进制形式。可以用如下命令查看转换结果,也可以找一个科学计算器进行转换:

这里打印结果说明该线程在jstack中的展现形式为 0xa,通过jstack命令我们可以看到如下信息:
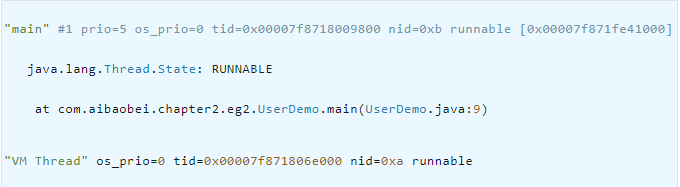
这里的VM Thread一行的最后显示 nid=0xa,这里nid的意思就是操作系统线程id的意思。而VM Thread指的就是垃圾回收的线程。
这里我们基本上可以确定,当前系统缓慢的原因主要是垃圾回收过于频繁,导致GC停顿时间较长。我们通过如下命令可以查看GC的情况:
root@8d36124607a0:/# jstat -gcutil 9 1000 10 S0 S1 E O M CCS YGC YGCT FGC FGCT GCT 0.00 0.00 0.00 75.07 59.09 59.60 3259 0.919 6517 7.715 8.635 0.00 0.00 0.00 0.08 59.09 59.60 3306 0.930 6611 7.822 8.752 0.00 0.00 0.00 0.08 59.09 59.60 3351 0.943 6701 7.924 8.867 0.00 0.00 0.00 0.08 59.09 59.60 3397 0.955 6793 8.029 8.984
可以看到,这里FGC指的是Full GC数量,这里高达6793,而且还在不断增长。从而进一步证实了是由于内存溢出导致的系统缓慢。
那么这里确认了内存溢出,但是如何查看你是哪些对象导致的内存溢出呢,这个可以dump出内存日志,然后通过eclipse的mat工具进行查看
如下是其展示的一个对象树结构:
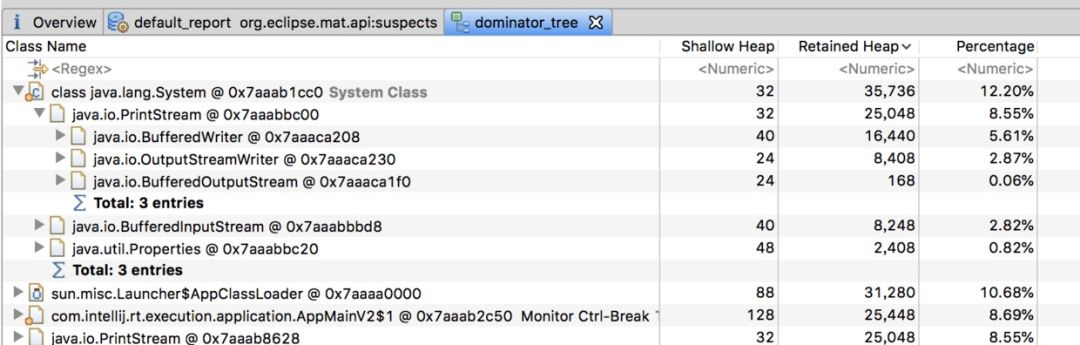
经过mat工具分析之后,我们基本上就能确定内存中主要是哪个对象比较消耗内存,然后找到该对象的创建位置,进行处理即可。
这里的主要是PrintStream最多,但是我们也可以看到,其内存消耗量只有12.2%。
也就是说,其还不足以导致大量的Full GC,此时我们需要考虑另外一种情况,就是代码或者第三方依赖的包中有显示的 System.gc()调用。
这种情况我们查看dump内存得到的文件即可判断,因为其会打印GC原因:
[Full GC (System.gc()) [Tenured: 262546K->262546K(349568K), 0.0014879 secs] 262546K->262546K(506816K), [Metaspace: 3109K->3109K(1056768K)], 0.0015151 secs] [Times: user=0.00 sys=0.00, real=0.01 secs][GC (Allocation Failure) [DefNew: 2795K->0K(157248K), 0.0001504 secs][Tenured: 262546K->402K(349568K), 0.0012949 secs] 265342K->402K(506816K), [Metaspace: 3109K->3109K(1056768K)], 0.0014699 secs] [Times: user=0.00
比如这里第一次GC是由于 System.gc()的显示调用导致的,而第二次GC则是JVM主动发起的。总结来说,对于Full GC次数过多,主要有以下两种原因:
代码中一次获取了大量的对象,导致内存溢出,此时可以通过eclipse的mat工具查看内存中有哪些对象比较多;
内存占用不高,但是Full GC次数还是比较多,此时可能是显示的 System.gc()调用导致GC次数过多,这可以通过添加 -XX:+DisableExplicitGC来禁用JVM对显示GC的响应。
2. CPU过高
在前面第一点中,我们讲到,CPU过高可能是系统频繁的进行Full GC,导致系统缓慢。而我们平常也肯能遇到比较耗时的计算,导致CPU过高的情况,此时查看方式其实与上面的非常类似。
首先我们通过 top命令查看当前CPU消耗过高的进程是哪个,从而得到进程id;
然后通过 top-Hp来查看该进程中有哪些线程CPU过高,一般超过80%就是比较高的,80%左右是合理情况。这样我们就能得到CPU消耗比较高的线程id。
接着通过该 线程id的十六进制表示在 jstack日志中查看当前线程具体的堆栈信息。
在这里我们就可以区分导致CPU过高的原因具体是Full GC次数过多还是代码中有比较耗时的计算了。
如果是Full GC次数过多,那么通过 jstack得到的线程信息会是类似于VM Thread之类的线程,而如果是代码中有比较耗时的计算,那么我们得到的就是一个线程的具体堆栈信息。
如下是一个代码中有比较耗时的计算,导致CPU过高的线程信息:
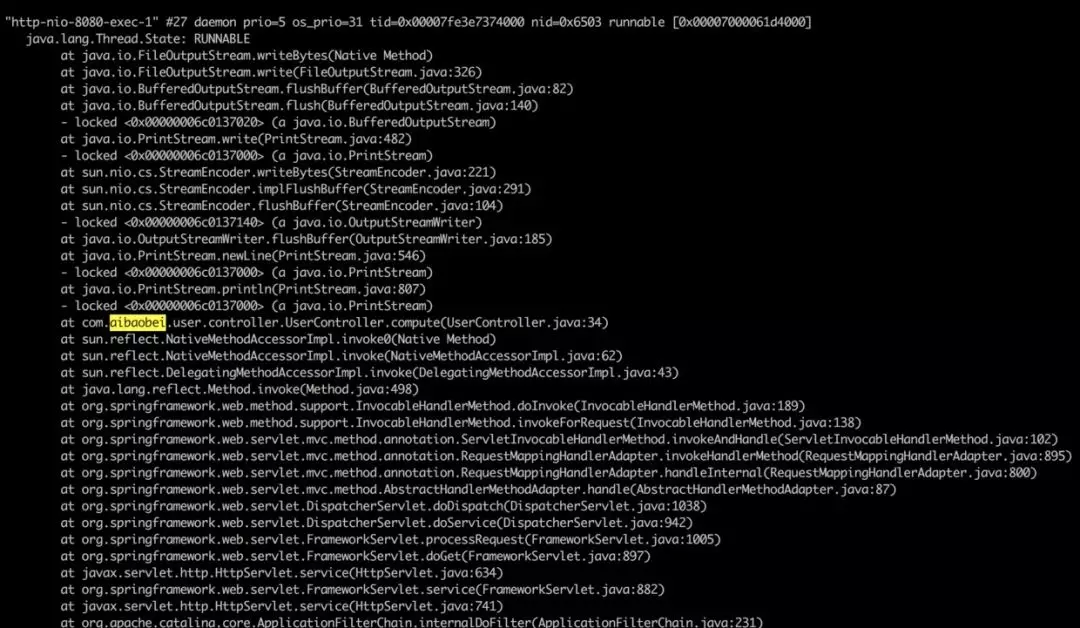
这里可以看到,在请求UserController的时候,由于该Controller进行了一个比较耗时的调用,导致该线程的CPU一直处于100%。
我们可以根据堆栈信息,直接定位到UserController的34行,查看代码中具体是什么原因导致计算量如此之高。
3. 不定期出现的接口耗时现象
对于这种情况,比较典型的例子就是,我们某个接口访问经常需要2~3s才能返回。
这是比较麻烦的一种情况,因为一般来说,其消耗的CPU不多,而且占用的内存也不高,也就是说,我们通过上述两种方式进行排查是无法解决这种问题的。
而且由于这样的接口耗时比较大的问题是不定时出现的,这就导致了我们在通过 jstack命令即使得到了线程访问的堆栈信息,我们也没法判断具体哪个线程是正在执行比较耗时操作的线程。
对于不定时出现的接口耗时比较严重的问题,我们的定位思路基本如下:
首先找到该接口,通过压测工具不断加大访问力度,如果说该接口中有某个位置是比较耗时的,由于我们的访问的频率非常高,那么大多数的线程最终都将阻塞于该阻塞点
这样通过多个线程具有相同的堆栈日志,我们基本上就可以定位到该接口中比较耗时的代码的位置。
如下是一个代码中有比较耗时的阻塞操作通过压测工具得到的线程堆栈日志:
-
"http-nio-8080-exec-2" #29 daemon prio=5 os_prio=31 tid=0x00007fd08cb26000 nid=0x9603 waiting on condition [0x00007000031d5000] -
java.lang.Thread.State: TIMED_WAITING (sleeping) -
at java.lang.Thread.sleep(Native Method) -
at java.lang.Thread.sleep(Thread.java:340) -
at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:386) -
at com.aibaobei.user.controller.UserController.detail(UserController.java:18)
-
"http-nio-8080-exec-3" #30 daemon prio=5 os_prio=31 tid=0x00007fd08cb27000 nid=0x6203 waiting on condition [0x00007000032d8000] -
java.lang.Thread.State: TIMED_WAITING (sleeping)
-
at java.lang.Thread.sleep(NativeMethod)
-
at java.lang.Thread.sleep(Thread.java:340)
-
at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
-
at com.aibaobei.user.controller.UserController.detail(UserController.java:18)
-
"http-nio-8080-exec-4" #31 daemon prio=5 os_prio=31 tid=0x00007fd08d0fa000 nid=0x6403 waiting on condition [0x00007000033db000]
-
java.lang.Thread.State: TIMED_WAITING (sleeping)
-
at java.lang.Thread.sleep(NativeMethod)
-
at java.lang.Thread.sleep(Thread.java:340)
-
at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
-
at com.aibaobei.user.controller.UserController.detail(UserController.java:18)
从上面的日志可以看你出,这里有多个线程都阻塞在了UserController的第18行,说明这是一个阻塞点,也就是导致该接口比较缓慢的原因。
4. 某个线程进入WAITING状态
对于这种情况,这是比较罕见的一种情况,但是也是有可能出现的,而且由于其具有一定的“不可复现性”,因而我们在排查的时候是非常难以发现的。
笔者曾经就遇到过类似的这种情况,具体的场景是,在使用CountDownLatch时,由于需要每一个并行的任务都执行完成之后才会唤醒主线程往下执行。
当时我们是通过CountDownLatch控制多个线程连接并导出用户的gmail邮箱数据,这其中有一个线程连接上了用户邮箱,但是连接被服务器挂起了,导致该线程一直在等待服务器的响应。最终导致我们的主线程和其余几个线程都处于WAITING状态。
对于这样的问题,查看过jstack日志的读者应该都知道,正常情况下,线上大多数线程都是处于 TIMED_WAITING状态,而我们这里出问题的线程所处的状态与其是一模一样的,这就非常容易混淆我们的判断。
解决这个问题的思路主要如下:
通过grep在jstack日志中找出所有的处于 TIMED_WAITING状态的线程,将其导出到某个文件中,如a1.log,如下是一个导出的日志文件示例:
"Attach Listener" #13 daemon prio=9 os_prio=31 tid=0x00007fe690064000 nid=0xd07 waiting on condition [0x0000000000000000]"DestroyJavaVM" #12 prio=5 os_prio=31 tid=0x00007fe690066000 nid=0x2603 waiting on condition [0x0000000000000000]"Thread-0" #11 prio=5 os_prio=31 tid=0x00007fe690065000 nid=0x5a03 waiting on condition [0x0000700003ad4000]"C1 CompilerThread3" #9 daemon prio=9 os_prio=31 tid=0x00007fe68c00a000 nid=0xa903 waiting on condition [0x0000000000000000]
等待一段时间之后,比如10s,再次对jstack日志进行grep,将其导出到另一个文件,如a2.log,结果如下所示:
"DestroyJavaVM" #12 prio=5 os_prio=31 tid=0x00007fe690066000 nid=0x2603 waiting on condition [0x0000000000000000]"Thread-0" #11 prio=5 os_prio=31 tid=0x00007fe690065000 nid=0x5a03 waiting on condition [0x0000700003ad4000]"VM Periodic Task Thread" os_prio=31 tid=0x00007fe68d114000 nid=0xa803 waiting on condition
重复步骤2,待导出3~4个文件之后,我们对导出的文件进行对比,找出其中在这几个文件中一直都存在的用户线程,这个线程基本上就可以确认是包含了处于等待状态有问题的线程。
因为正常的请求线程是不会在20~30s之后还是处于等待状态的。
经过排查得到这些线程之后,我们可以继续对其堆栈信息进行排查,如果该线程本身就应该处于等待状态,比如用户创建的线程池中处于空闲状态的线程,那么这种线程的堆栈信息中是不会包含用户自定义的类的。
这些都可以排除掉,而剩下的线程基本上就可以确认是我们要找的有问题的线程。通过其堆栈信息,我们就可以得出具体是在哪个位置的代码导致该线程处于等待状态了。
这里需要说明的是,我们在判断是否为用户线程时,可以通过线程最前面的线程名来判断,因为一般的框架的线程命名都是非常规范的,我们通过线程名就可以直接判断得出该线程是某些框架中的线程,这种线程基本上可以排除掉。
而剩余的,比如上面的 Thread-0,以及我们可以辨别的自定义线程名,这些都是我们需要排查的对象。
经过上面的方式进行排查之后,我们基本上就可以得出这里的 Thread-0就是我们要找的线程,通过查看其堆栈信息,我们就可以得到具体是在哪个位置导致其处于等待状态了。
如下示例中则是在SyncTask的第8行导致该线程进入等待了。
"Thread-0" #11 prio=5 os_prio=31 tid=0x00007f9de08c7000 nid=0x5603 waiting on condition [0x0000700001f89000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:304) at com.aibaobei.chapter2.eg4.SyncTask.lambda$main$0(SyncTask.java:8) at com.aibaobei.chapter2.eg4.SyncTask$$Lambda$1/1791741888.run(Unknown Source) at java.lang.Thread.run(Thread.java:748)
5. 死锁
对于死锁,这种情况基本上很容易发现,因为 jstack可以帮助我们检查死锁,并且在日志中打印具体的死锁线程信息。如下是一个产生死锁的一个 jstack日志示例:
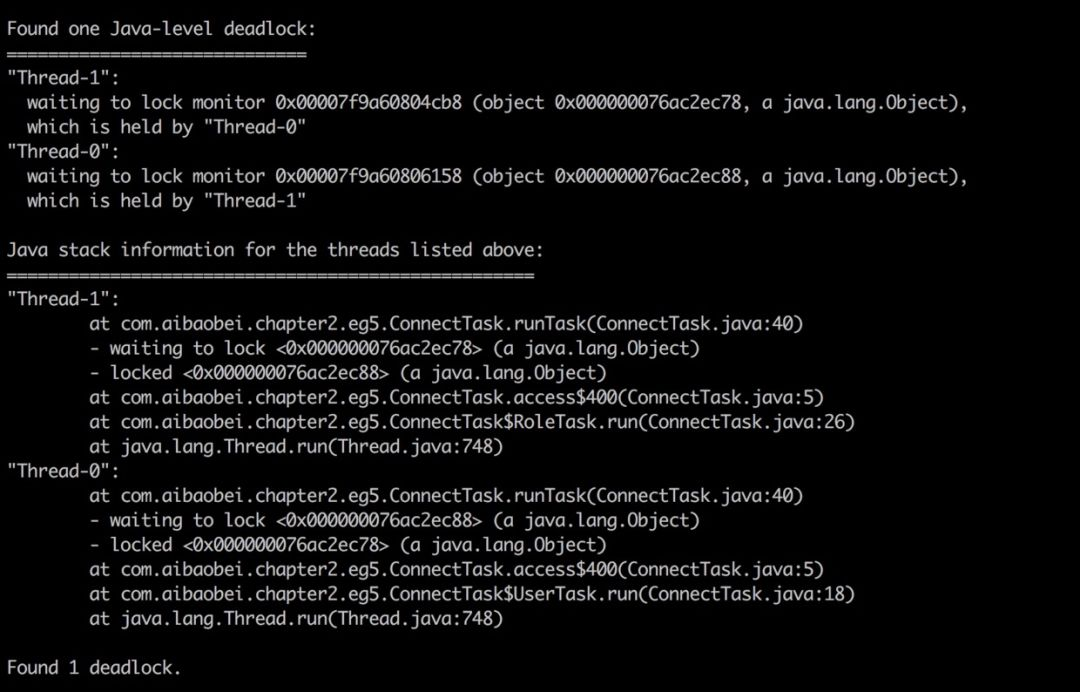
可以看到,在jstack日志的底部,其直接帮我们分析了日志中存在哪些死锁,以及每个死锁的线程堆栈信息。
这里我们有两个用户线程分别在等待对方释放锁,而被阻塞的位置都是在ConnectTask的第5行,此时我们就可以直接定位到该位置,并且进行代码分析,从而找到产生死锁的原因。
6. 小结
本文主要讲解了线上可能出现的五种导致系统缓慢的情况,详细分析了每种情况产生时的现象,已经根据现象我们可以通过哪些方式定位得到是这种原因导致的系统缓慢。
简要的说,我们进行线上日志分析时,主要可以分为如下步骤:
通过 top命令查看CPU情况,如果CPU比较高,则通过 top-Hp命令查看当前进程的各个线程运行情况,找出CPU过高的线程之后,将其线程id转换为十六进制的表现形式,然后在jstack日志中查看该线程主要在进行的工作。这里又分为两种情况
如果是正常的用户线程,则通过该线程的堆栈信息查看其具体是在哪处用户代码处运行比较消耗CPU;
如果该线程是 VMThread,则通过 jstat-gcutil命令监控当前系统的GC状况,然后通过 jmapdump:format=b,file=导出系统当前的内存数据。导出之后将内存情况放到eclipse的mat工具中进行分析即可得出内存中主要是什么对象比较消耗内存,进而可以处理相关代码;
如果通过 top 命令看到CPU并不高,并且系统内存占用率也比较低。此时就可以考虑是否是由于另外三种情况导致的问题。具体的可以根据具体情况分析
如果是接口调用比较耗时,并且是不定时出现,则可以通过压测的方式加大阻塞点出现的频率,从而通过 jstack查看堆栈信息,找到阻塞点;
如果是某个功能突然出现停滞的状况,这种情况也无法复现,此时可以通过多次导出 jstack日志的方式对比哪些用户线程是一直都处于等待状态,这些线程就是可能存在问题的线程;
如果通过 jstack可以查看到死锁状态,则可以检查产生死锁的两个线程的具体阻塞点,从而处理相应的问题。
本文主要是提出了五种常见的导致线上功能缓慢的问题,以及排查思路。
当然,线上的问题出现的形式是多种多样的,也不一定局限于这几种情况,如果我们能够仔细分析这些问题出现的场景,就可以根据具体情况具体分析,从而解决相应的问题。
参考:
面试官:如果你们的系统 CPU 突然飙升且 GC 频繁,如何排查?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号