
Map:HashMap
参考:
https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/HashMap.md
https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20%E5%AE%B9%E5%99%A8.md#hashmap
HashMap 的底层实现
JDK1.8 之前
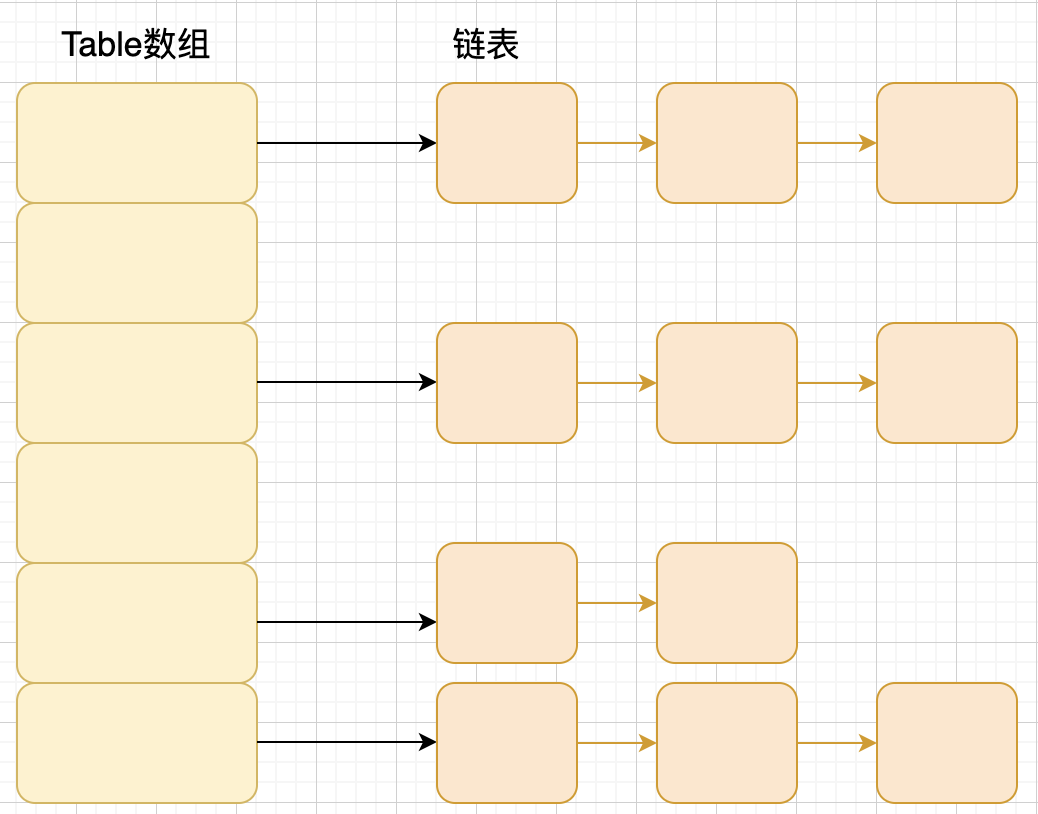
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 HashMap 的 hash 方法源码:
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。


static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
对比一下 JDK1.7 的 HashMap 的 hash 方法源码.
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
JDK1.8 之后
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
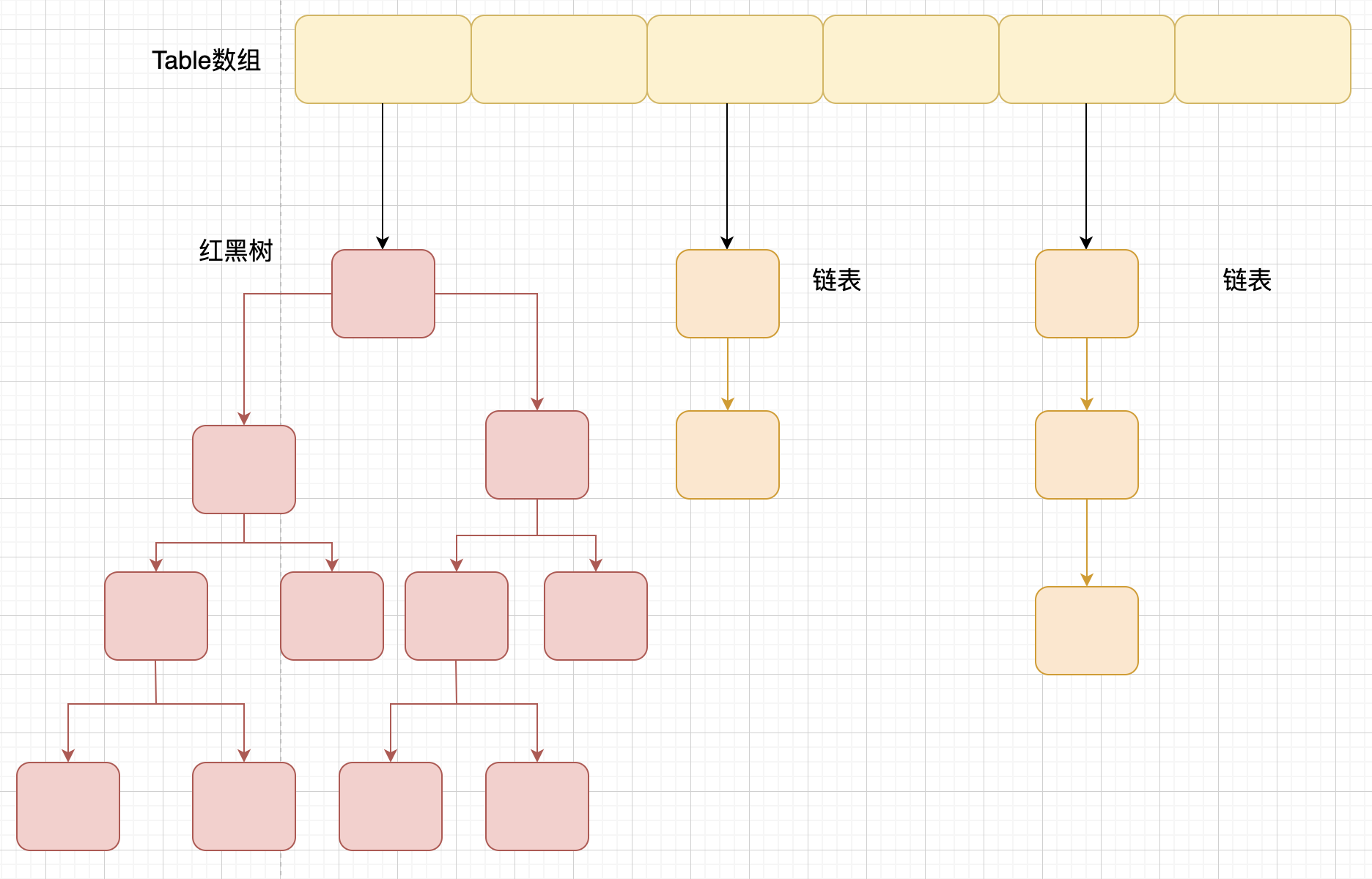
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
HashMap 的长度为什么是 2 的幂次方
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。
我们上面也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。
但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。
这个数组下标的计算方法是“ (n - 1) & hash”。(n 代表数组长度)。这也就解释了 HashMap 的长度为什么是 2 的幂次方。
这个算法应该如何设计呢?
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
HashMap 的 7 种遍历方式与性能分析!
参考:https://mp.weixin.qq.com/s/Zz6mofCtmYpABDL1ap04ow
使用迭代器(Iterator)EntrySet 的方式进行遍历;
使用迭代器(Iterator)KeySet 的方式进行遍历;
使用 For Each EntrySet 的方式进行遍历;
使用 For Each KeySet 的方式进行遍历;
使用 Lambda 表达式的方式进行遍历;
使用 Streams API 单线程的方式进行遍历;
使用 Streams API 多线程的方式进行遍历。
1.迭代器 EntrySet
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
System.out.print(entry.getKey());
System.out.print(entry.getValue());
}
}
}
2.迭代器 KeySet
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Integer key = iterator.next();
System.out.print(key);
System.out.print(map.get(key));
}
}
}
3.ForEach EntrySet
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.print(entry.getKey());
System.out.print(entry.getValue());
}
}
}
4.ForEach KeySet
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
for (Integer key : map.keySet()) {
System.out.print(key);
System.out.print(map.get(key));
}
}
}
5.Lambda
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
map.forEach((key, value) -> {
System.out.print(key);
System.out.print(value);
});
}
}
6.Streams API 单线程
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
map.entrySet().stream().forEach((entry) -> {
System.out.print(entry.getKey());
System.out.print(entry.getValue());
});
}
}
7.Streams API 多线程
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
map.entrySet().parallelStream().forEach((entry) -> {
System.out.print(entry.getKey());
System.out.print(entry.getValue());
});
}
}
可以得出的结论是,除了并行循环的 parallelStream 性能比极高之外(多线程方式性能肯定比较高),其他方式的遍历方法在性能方面几乎没有任何差别。
使用 EntrySet 和 KeySet 代码差别不是很大,并不像网上说的那样 KeySet 的性能远不如 EntrySet,因此从性能的角度来说 EntrySet 和 KeySet 几乎是相近的,但从代码的优雅型和可读性来说,还是推荐使用 EntrySet。
迭代器中循环删除数据安全。
For 循环中删除数据非安全。
Lambda 循环中删除数据非安全。 map.keySet().removeIf(key -> key == 1); 可以先使用 Lambda 的 removeIf 删除多余的数据,再进行循环是一种正确操作集合的方式。
Stream 循环中删除数据非安全
map.entrySet().stream().filter(m -> 1 != m.getKey()).forEach((entry) -> {
if (entry.getKey() == 1) {
System.out.println("del:" + entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
});
可以使用 Stream 中的 filter 过滤掉无用的数据,再进行遍历也是一种安全的操作集合的方式。
小结
我们不能在遍历中使用集合 map.remove() 来删除数据,这是非安全的操作方式,但我们可以使用迭代器的 iterator.remove() 的方法来删除数据,这是安全的删除集合的方式。同样的我们也可以使用 Lambda 中的 removeIf 来提前删除数据,或者是使用 Stream 中的 filter 过滤掉要删除的数据进行循环,这样都是安全的,当然我们也可以在 for 循环前删除数据在遍历也是线程安全的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号