Spark Streaming概述
Spark Streaming概述
1. Spark Streaming
Spark Streaming用于流式数据的处理。但是Spark Streaming本质上是准实时的,微批次的数据处理框架。
Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫做DStream。DStream是随着时间推移而收到的数据的序列。DStream就是对RDD在实时数据处理场景的一种封装。
2. Spark Streaming的特点
- 易用
- 容错
- 易整合到Spark体系
3. Spark Streaming架构
1. 架构图
-
整体架构图
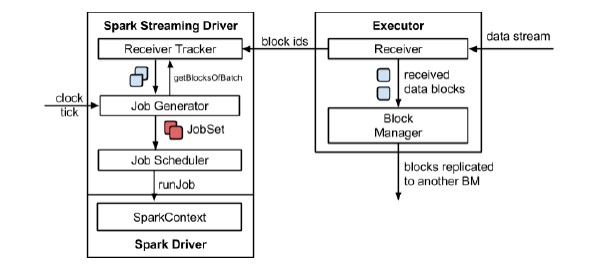
-
Spark Streaming架构图
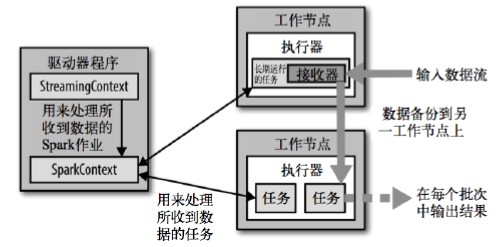
2. 背压机制
Spark 1.5以前版本,用户如果要限制Receiver的数据接收速率,可以通过设置静态配置参数spark.streaming.receiver.maxRate的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其他的问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5版本开始Spark Streaming可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即Spark Streaming Backpressure):根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。
通过属性spark.streaming.backpressure.enabled来控制是否启用backpressure机制,默认值false,即不启用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号