大数据判断数据是否存在——布隆过滤器
题目:给定十亿个数字,怎么去判断这个数据是否存在;
这个一个典型的查找问题,我们知道面对查找的时候,最快的查找是基于hash查找,那么都是在O(1)的时间内找到指定的数据集,但是这样要把数据全部load到内存里,内存大部分的时候是不支持一次性load十亿的数据的,而且hash的空间利用率来说相对比较低。
这个时候运用得比较好的方式就是利用布隆过滤器(Bloom Filter),它可以在很小的内存空间内查找某个数据是否存在;
算法:
1. 首先需要k个hash函数,每个函数可以把key散列成为1个整数
2. 初始化时,需要一个长度为n比特的数组,每个比特位初始化为0
3. 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1
4. 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
其实这个算法的本质还是基于hash去计算的,只是多重hash去保证空间的覆盖性;
抄一个图来用图来就很好理解了,长度为8的数组,2次hash,如果来了一个数据3000,通过hash两次发现第六个位置为0,那么说明3000这个数据一定不存在。
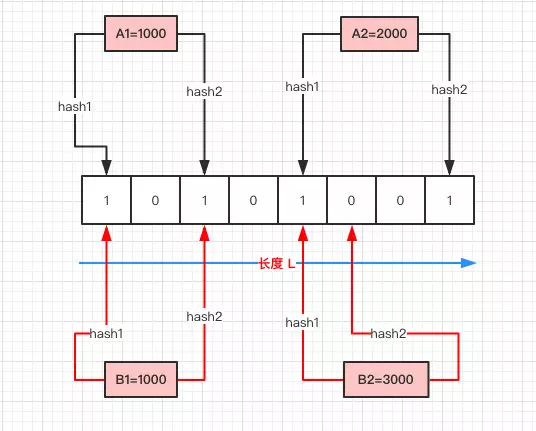
那么这个布隆过滤器就有这么几个特点:
1.只要返回数据不存在,则肯定不存在。
2.返回数据存在,但只能是大概率存在。
3.同时不能清除其中的数据。
其实布隆过滤器只要尽量减少不存在的数据映射到旧的hash位上,就是一个很好的算法了。那么怎么去判断的呢:
详细的概率公式如下:
https://www.cnblogs.com/liyulong1982/p/6013002.html
有空可以理解一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号