Python--函数
函数基础 & 装饰器 & 递归函数 & 函数嵌套及作用域 & 匿名函数 & 内置函数
Python基础-函数
认识函数
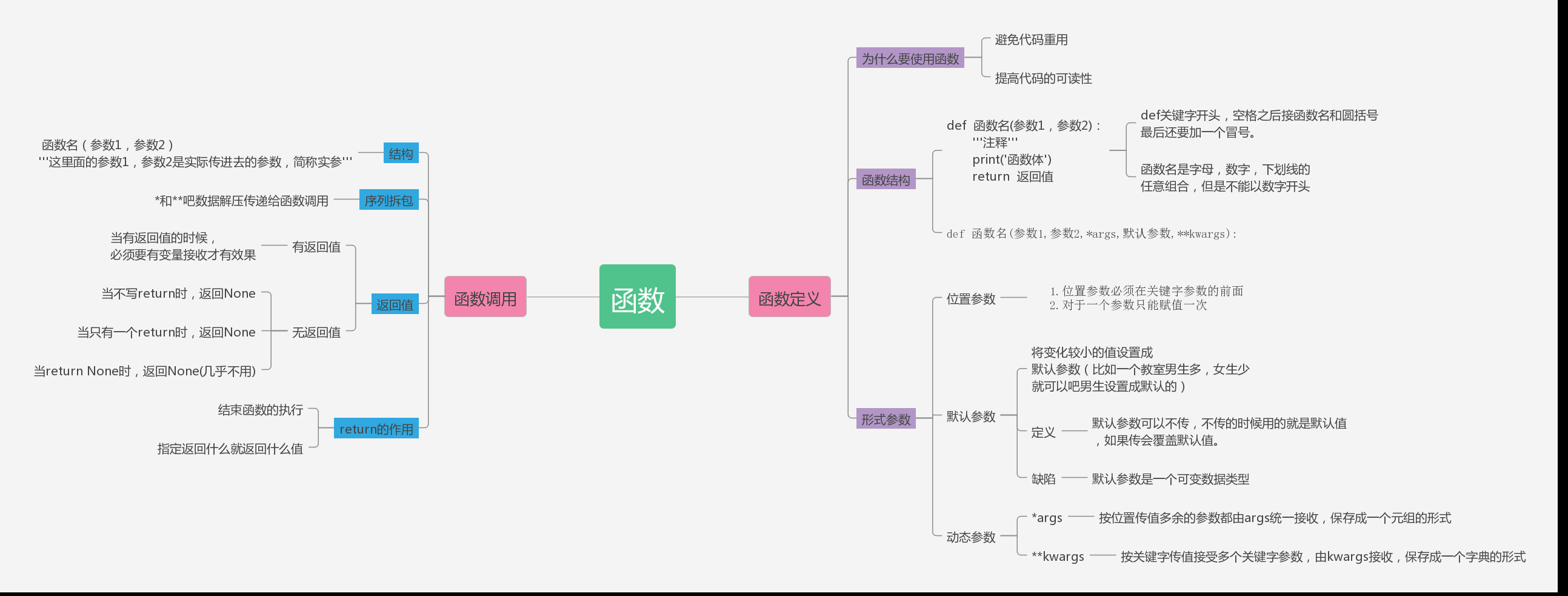
为什么要使用函数?
1.避免代码重用,在一个完整的项目中,某些功能会反复使用。那么会将功能封装成函数,当我们要使用功能的时候直接调用函数即可。
2.提高代码的可读性
本质:函数就是对功能的封装
优点:
1.简化代码结构,增加了代码的复用度(重复使用的程度)
2.如果想修改某些功能或者调试某个BUG,只需要修改对应的函数即可
函数的定义与调用
定义
def 函数名(参数1,参数2):
''' 函数注释'''
语句
return 返回值
定义:def关键字开头,空格之后接函数名和圆括号,最后还要加一个冒号,def是固定的,不能变
函数名:遵循标识符规则,函数名是包含字母,数字,下划线的任意组合,但是不能以数字开头。虽然函数名可以随便取名,但是一般尽量定义成可以表示函数功能的。
参数列表:(参数1,参数2,……,参数n)任何传入函数的参数和变量必须放在圆括号之间,用逗号分隔。函数从函数的调用者那里获取的信息
冒号:函数内容(封装的功能)以冒号开始,并且缩进。
语句:函数封装的功能
return:一般用于结束函数,并返回信息给函数的调用者
注意:最后的return表达式,可以不写,相当于return None
调用
格式:
返回值 = 函数名(参数1,参数2)
函数名:是要使用的功能的函数名字
参数:函数的调用者给函数传递的信息,如果没有参数,小括号也不能省略
函数调用的本质:实参给形参赋值的过程
下面我们先来定义一个求计算字符串长度的函数。假如我们的len()函数现在不能用了,那么我们就需要定义一个函数,求字符串的长度。如果让我们一次一次的去写相同的代码,会显得很麻烦。这时候我们的函数就上场了。
1.给定一个字符串,调用函数,当他没有返回值的时候返回Null def length(): s='hello world' length=0 for i in s: length+=1 print(length) print(length()) 2.return 必须放在函数里,当函数有返回值的时候,必须用变量接收才会有效果 def length(): s='hello world' length=0 for i in s: length+=1 return length print(length()) 计算字符串的长度
函数的返回值
return的作用:结束一个函数的执行
1、首先返回值可以是任意的数据类型
2、函数可以有返回值:如果有返回值,必须要用变量接收才有效果
也可以没有返回值:
没有返回值的时候分三种情况:
1.当不写return的时候,函数的返回值为None
2.当只写一个return的时候,函数的返回值为None
3.return None的时候,函数的返回值为None(几乎不用)
3、return返回一个值(一个变量)
4、return返回多个值(多个变量):多个值之间用逗号隔开,以元组的形式返回。
接收:可以用一个变量接收,也可以用多个变量接收,返回几个就用几个变量去接收


def func(): a=111 b=[1,2,3] c={'a':15,'b':6} #return a#返回一个值 #return a,b,c#返回多个值,变量之间按逗号隔开,以元组的形式返回 print(func()) 函数有一个或多个返回值
1.不写return时返回None def func(): a=111 b=[1,2,3] ret=func() print(ret) 2.只写一个return时返回None def func(): a=111 b=[1,2,3] return ret=func() print(ret) 3.return None的时候返回None def func(): a=111 b=[1,2,3] return None ret=func() print(ret) 函数没有返回值的函数
def func4(): print (1111111) return#结束一个函数的执行 print (1242451) func4()
方法一 def func(): list=['hello','egon',11,22] return list[-1] print(func()) 方法二 def func(): list=['hello','egon',11,22] return list m,n,k,g=func()# print(g) 定义一个列表,返回列表的最后一个值
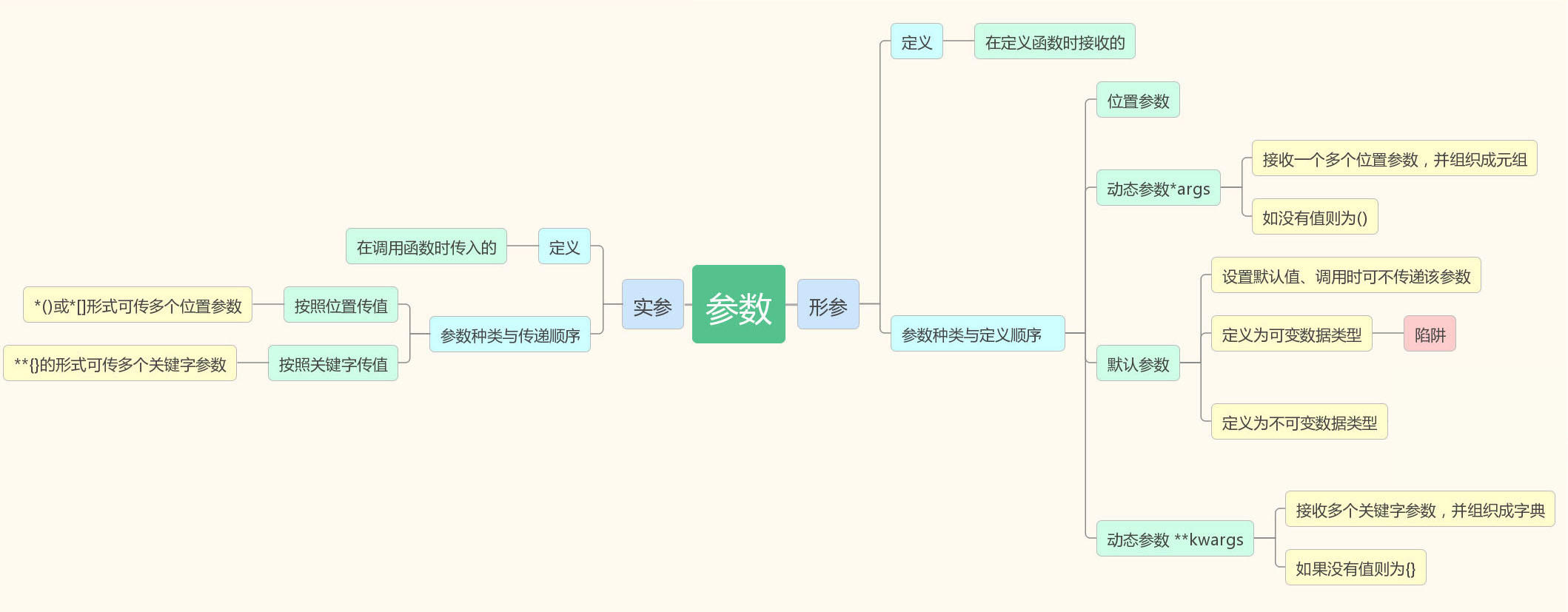
函数的参数
def fun(s):#参数接受:形式参数,简称形参 ''' 计算字符串长度的函数---------函数的功能 参数s:接受要计算的字符串--------参数的信息 return:要计算字符串长度 ---------返回值得信息 ''' length=0 for i in s: length+=1 return length ret=fun('helloword')#参数传入:实际参数,简称实参 print(ret)
实参和形参
形参:是函数定义时候定义的参数
实参:函数调用时候传进来的参数
传递多个参数
可以传递多个参数,多个参数之间用逗号隔开
站在参数的角度上,调用函数时传参数有两种方式:
1、按照位置传参数
2、按照关键字传参数
用法:1、位置参数必须在关键字参数的前面
2、对于一个参数只能赋值一次
def my_max(a,b):#位置参数:按顺序定义参数 if a>b: return a else: return b # 站在传参的角度上 print(my_max(20,30)) print(my_max(10,20))# 1.按照位置传参 print(my_max(b=50,a=30))# 2.按照关键字传参 print(my_max(10,b=30))#3.位置和关键字传参混搭
默认参数
用法:为什么要用默认参数?将变化比较小的值设置成默认参数(比如一个班的男生多,女生就几个,就可以设置个默认值参数)
定义:默认参数可以不传,不传的时候用的就是默认值,如果传会覆盖默认值。
默认的值是在定义函数的时候就已经确定了的
def stu_info(name,sex = "male"): """打印学生信息函数,由于班中大部分学生都是男生, 所以设置默认参数sex的默认值为'male' """ print(name,sex) stu_info('alex') stu_info('海燕','female')
默认参数缺陷:默认参数是一个可变数据类型
def default_param(a,l=[]): l.append(a) print(l) default_param('alex') default_param('rgon') 输出:['alex'] ['alex', 'egon']
动态参数
上面说过了参数,如果要给一个函数传递参数,而参数又不是确定的,或者我给一个函数传很多参数,我的形参就要写很多,很麻烦。这时候就可以使用到动态参数了。
动态参数分为两种:
1、动态参数接收位置参数(注意:动态参数必须在位置参数的后面,默认值参数必须在动态参数后面)
参数使用*args #args只是一个名字,可以自定义,比如*food
2、动态参数接收关键字参数
参数使用**kwargs
最终传参顺序为:
位置参数 > *args > 默认值参数 > **kwargs
按位置传值多余的参数都由args统一接收,保存成一个元组的形式
按关键字传值接受多个关键字参数,由kwargs接收,保存成一个字典的形式
def fun(a,b,*args): sum=a+b for i in args: sum+=i return sum print(fun(1,5,6,4))#输出1+5+6+4的和
def fun(a,b,**kwargs): print(a,b,kwargs) # 按照关键字传参数 fun(a = 10,b = 20,cccc= 30,dddd = 50)#输出10 20 {'cccc': 30, 'dddd': 50} def f(a,b,*args,defult=6,**kwargs): #位置参数,*args, 默认参数,**kwargs # print(a,b,args,defult,kwargs) return a,b,args,defult,kwargs #传参数的时候:必须先按照位置传参数,再按照关键字传参数 print(f(1,2,7,8,ccc=10,der=5))
# 形参:聚合 def func(*food): #聚合,位置参数 print(food) lst = ['鸡蛋','煎饼果子','豆腐'] # 实参:打散 func(*lst) #打散,把list,tuple,set,str 进行迭代打散 # 聚合成关键字参数 def func(**food): print(food) dic = {'name':'xiaobai', 'age': '18'} func(**dic) #打散成关键字参数
函数注释
def func(a,b): """ 这里是函数的注释,先写一下当前这个函数是干什么的,比如这个函数是处理a和b的和 :param a: 第一个数据 :param b: 第二个数据 :return: 返回的是两个数的和 """ return a + b #通过print(函数名.__doc__)可以查看函数的注释说明 print(func.__doc__) print(str.__doc__)
函数小结
1.定义:def 关键词开头,空格之后接函数名称和圆括号()。
2.参数:圆括号用来接收参数。若传入多个参数,参数之间用逗号分割。
参数可以定义多个,也可以不定义。
参数有很多种,如果涉及到多种参数的定义,应始终遵循位置参数、*args、默认参数、**kwargs顺序定义。
如上述定义过程中某参数类型缺省,其他参数依旧遵循上述排序
3.注释:函数的第一行语句应该添加注释。
4.函数体:函数内容以冒号起始,并且缩进。
5.返回值:return [表达式] 结束函数。不带表达式的return相当于返回 None
def 函数名(参数1,参数2,*args,默认参数,**kwargs):
"""注释:函数功能和参数说明"""
函数体
……
return 返回值
函数—闭包
- 什么是闭包?闭包就是内层函数对外层函数的变量的引用,叫闭包
def func(): name = "小白" def inner(): print(name) #在内层函数中调用了外层函数的变量,叫闭包;可以让一个局部变量常驻内存 inner() func() # 结果: 小白
可以使用__closure__来检测函数是否是闭包,使用函数名.__closure__返回cell就是闭包,返回None就不是闭包
def func(): name = "小白" def inner(): print(name) #闭包 inner() print(inner.__closure__) # (<cell at 0x000001C307BD7498: str object at 0x000001C307BD69D0>,) func()
- 问题,如何在函数外边调用内部函数?
def func(): name = "小白" # 内部函数 def inner(): print(name) #闭包 return inner ret = func() # 访问外部函数,获取到内部函数的内存地址 ret() # 访问内部函数
如果多层嵌套呢?很简单,只需要一层一层的往外层返回就行了
def func1(): def func2(): def func3(): print("哈哈") return func3 return func2 func1()()()
由它我们可以引出闭包的好处,由于我们在外界可以访问内部函数,那这个时候内部函数访问的时间和时机就不一定了,因为在外部,可以选择在任意的时间去访问内部函数,由于一个函数执行完毕,则这个函数中的变量以及局部命名空间中的内容都将会被销毁;在闭包中,如果变量被销毁了,那内部函数将不能正常执行,所以,python规定,如果在内部函数中访问了外层函数中的变量,那么这个变量将不会消亡,将会常驻在内存中,也就是说,使用闭包,可以保证外层函数中的变量在内存中常驻,这样有什么好处呢?看一个关于爬虫的代码:
from urllib.request import urlopen def but(): content = urlopen("http://news.baidu.com/guonei").read() def get_content(): return content return get_content fn = but() # 这个时候就开始加载校花100的内容 # 后⾯需要⽤到这⾥⾯的内容就不需要在执⾏⾮常耗时的⽹络连接操作了 content = fn() # 获取内容 print(content) content2 = fn() # 重新获取内容 print(content2)
闭包的作用:就是让一个变量能够常驻内存,供后面的程序使用
函数—装饰器
为什么要使用装饰器呢?
装饰器的功能:在不修改原函数及其调用方式的情况下对原函数功能进行扩展
装饰器的本质:就是一个闭包函数,把一个函数当做参数,返回一个替代版的函数,本质上就是一个返回函数的函数。
那么我们先来看一个简单的装饰器:实现计算每个函数的执行时间的功能
def timeer(f): def inner(*args, **kwargs): start = time.time() f(*args, **kwargs) end = time.time() ret = end - start print("执行该程序共计用时%s秒"%ret) return inner @timeer def wowo(): time.sleep(0.5) print("to day is a good day") wowo()
以上的装饰器都是不带参数的函数,现在装饰一个带参数的该怎么办呢?
def outer(func): def inner(age): if age > 20: age = 20 func(age) return inner # 使用@函数将装饰器应用到函数 @outer def say(age): print("小明今年已经过了%s岁了" % (age)) say(21)
import time def outer(func): def inner(*args,**kwargs): #添加修改的功能 startTime = time.time() time.sleep(1) print("&&&&&&&&&&&&&&") func(*args,**kwargs) endTime = time.time() print("执行该函数总共花了 %f" %(endTime - startTime)) return inner @outer def say(name,age): #函数的参数理论上是无限制的,但实际上最好不要超过6~7个 print("my name is %s, I am %d years old" %( name,age)) say("lee", 18)
import time def timer(func): def inner(*args,**kwargs): start = time.time() re = func(*args,**kwargs) end=time.time() print(end - start) return re return inner @timer #==> func1 = timer(func1) def jjj(a): print('in jjj and get a:%s'%(a)) return 'fun2 over' jjj('aaaaaa') print(jjj('aaaaaa'))
开放封闭的原则
1.对扩展是开放的
2.对修改是封闭的
装饰器的固定结构
import time def wrapper(func): # 装饰器 def inner(*args, **kwargs): '''函数执行之前的内容扩展''' ret = func(*args, **kwargs) '''函数执行之前的内容扩展''' return ret return inner @wrapper # =====>aaa=timmer(aaa) def aaa(): time.sleep(1) print('fdfgdg') aaa()
''' # 固定格式 def outer(func): def inner(*args,**kwargs): #添加修改的功能 pass func(*args,**kwargs) return inner '''
import time def outer(func): def inner(*args,**kwargs): #添加修改的功能 startTime = time.time() time.sleep(1) print("&&&&&&&&&&&&&&") func(*args,**kwargs) endTime = time.time() print("执行该函数总共花了 %f" %(endTime - startTime)) return inner @outer def say(name,age): #函数的参数理论上是无限制的,但实际上最好不要超过6~7个 print("my name is %s, I am %d years old" %( name,age)) say("lee", 18)
带参数的装饰器
带参数的装饰器:就是给装饰器传参
用处:就是当加了很多装饰器的时候,现在忽然又不想加装饰器了,想把装饰器给去掉了,但是那么多的代码,一个一个的去闲的麻烦,那么,我们可以利用带参数的装饰器去装饰它,这就他就像一个开关一样,要的时候就调用了,不用的时候就去掉了。给装饰器里面传个参数,那么那个语法糖也要带个括号。在语法糖的括号内传参。在这里,我们可以用三层嵌套,弄一个标识为去标识。如下面的代码示例
# 带参数的装饰器:(相当于开关)为了给装饰器传参 # F=True#为True时就把装饰器给加上了 F=False#为False时就把装饰器给去掉了 def outer(flag): def wrapper(func): def inner(*args,**kwargs): if flag: print('before') ret=func(*args,**kwargs) print('after') else: ret = func(*args, **kwargs) return ret return inner return wrapper @outer(F)#@wrapper def hahaha(): print('hahaha') @outer(F) def shuangwaiwai(): print('shuangwaiwai') hahaha() shuangwaiwai()
多个装饰器装饰一个函数
def qqqxing(fun): def inner(*args,**kwargs): print('in qqxing: before') ret = fun(*args,**kwargs) print('in qqxing: after') return ret return inner def pipixia(fun): def inner(*args,**kwargs): print('in qqxing: before') ret = fun(*args,**kwargs) print('in qqxing: after') return ret return inner @qqqxing @pipixia def dapangxie(): print('饿了吗') dapangxie() ''' @qqqxing和@pipixia的执行顺序:先执行qqqxing里面的 print('in qqxing: before'),然后跳到了pipixia里面的 print('in qqxing: before') ret = fun(*args,**kwargs) print('in qqxing: after'),完了又回到了qqqxing里面的 print('in qqxing: after')。所以就如下面的运行结果截图一样 '''

上例代码的运行结果截图
统计多少个函数被装饰了的小应用
# 统计多少个函数被我装饰了 l=[] def wrapper(fun): l.append(fun)#统计当前程序中有多少个函数被装饰了 def inner(*args,**kwargs): # l.append(fun)#统计本次程序执行有多少个带装饰器的函数被调用了 ret = fun(*args,**kwargs) return ret return inner @wrapper def f1(): print('in f1') @wrapper def f2(): print('in f2') @wrapper def f3(): print('in f3') print(l)
函数—迭代器
str,list,tuple,dict,set为什么我们可以称它们为可迭代对象?因为它们都遵循了可迭代协议,什么是可迭代协议?首先先看一段错误代码:
# 对的 s = "Welcom" for i in s: print(i) # 错的 for i in 123: print(i) # 结果: .... for i in 123: TypeError: 'int' object is not iterable
上面报错信息中有这样一句话. 'int' object is not iterable . 翻译过来就是整数类型对象是不可迭代的,iterable表示可迭代的,表示可迭代协议;如果判断数据类型是否符合可迭代协议?可以通过dir函数来查看类中定义好的所有方法。
s = "我的哈哈哈" print(dir(s)) # 可以打印对象中的⽅法和函数 print(dir(str)) # 也可以打印类中声明的⽅法和函数
在打印结果中,寻找__iter__ 如果能够找到,那么这个类的对象就是一个可迭代对象
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__',
'__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__',
'__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__',
'__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs',
'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric',
'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind',
'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
可以发现字符串中可以找到__iter__,继续看一下list,tuple,dict,set等
print("__iter__" in dir(list)) print("__iter__" in dir(tuple)) print("__iter__" in dir(dict)) print("__iter__" in dir(set)) # 结果: True True True True
所有的以上数据类型中都有一个函数__iter__() ;所以,所有包含了__iter__()的数据类型都是可迭代的数据类型 Iterable
这是查看一个对象是否是可迭代对象的第一种方法,还可以通过 isinstence() 函数来查看一个对象是什么类型
lst = [1, 2, 3] from collections import Iterable # 可迭代的 from collections import Iterator # 迭代器 # isinstence(对象, 类型) 判断xx对象是否是xxx类型的 print(isinstance(lst, Iterable)) print(isinstance(lst, Iterator)) # it = lst.__iter__() print(isinstance(it, Iterable)) # 判断是否是可迭代的 迭代器一定是可迭代的 print(isinstance(it, Iterator)) # 迭代器里面一定有__next__(), __iter__() print("__iter__" in dir(lst)) # 确定是一个可迭代的 print("__next__" in dir(lst)) # 确定不是一个迭代器
综上,可以看出如果对象中有__iter__函数,那么我们认为这个对象遵守了可迭代协议,就可以获取到相应的迭代器,这里的__iter__是帮助我们获取到对象的迭代器,我们使用迭代器中的__next__()来获取到一个迭代器中的元素。
for循环的工作原理到底是什么?继续看代码
s = "来了就是深圳人" sl = s.__iter__() # 获取迭代器 # 使用迭代器获取每一个元素 print(sl.__next__()) # 来 print(sl.__next__()) # 了 print(sl.__next__()) # 就 print(sl.__next__()) # 是 print(sl.__next__()) # 深 print(sl.__next__()) # 圳 print(sl.__next__()) # 人 print(sl.__next__()) # StopIteration # for循环机制 for i in s: print(i) # 使⽤while循环+迭代器来模拟for循环 while True: try: sle = s.__iter__() print(sle.__next__()) except StopIteration: break
总结:
- Iterable:可迭代对象,内部包含__iter__()函数
- Iterator:迭代器,内部包含__iter__()函数,同时包含__next__()函数
- 迭代器的特点:1、节省内存;2、惰性机制;3、不能反复,只能向下执行
我们可以把要迭代的内容当成子弹,然后呢,获取到迭代器__iter__(),就把子弹都装在弹夹中,然后发射就是__next__()把每一个子弹(元素)打出来,也就是说,for循环的时候,一开始的时候是__iter__()来获取迭代器,后面每次获取元素都是通过__next__()来完成的。当程序遇到StopIteration将结束循环
函数—递归函数
递归的定义
需求,输入一个数(大于等于1),求1+2+3+……+n的和 # 普通函数写法: def sun1(n): sum = 0 for x in range(1,n + 1): sum += x return sum # 递归来写 ''' 1+2+3+4+5 sum2(1) + 0 = sum2(1) sum2(1) + 2 = sum2(2) sum2(2) + 3 = sum2(3) sum2(3) + 4 = sum2(4) sum2(4) + 5 = sum2(5) 5 + sum2(4) 5 + 4 + sum2(3) 5 + 4 + 3 + sum2(2) 5 + 4 + 3 + 2 + sum2(1) 5 + 4 + 3 + 2 + 1 ''' def sum2(n): if n == 1: return 1 else: return n * sum2(n - 1) res = sum2(5) print(res)
1.什么是递归:在一个函数里在调用这个函数本身
2.最大递归层数做了一个限制:997,但是也可以自己限制
def foo(n): print(n) n+=1 foo(n) foo(1)
3.最大层数限制是python默认的,可以做修改,但是不建议你修改。(因为如果用997层递归都没有解决的问题要么是不适合使用递归来解决问题,要么就是你的代码太烂了)
import sys sys.setrecursionlimit(10000000)#修改递归层数 n=0 def f(): global n n+=1 print(n) f() f()
我们可以通过以上代码,导入sys模块的方式来修改递归的最大深度。
sys模块:所有和python相关的设置和方法
4.结束递归的标志:return
5.递归解决的问题就是通过参数,来控制每一次调用缩小计算的规模
6.使用场景:数据的规模在减少,但是解决问题的思路没有改变
7.很多排序算法会用到递归
递归小应用
1.下面我们来猜一下小明的年龄
小明是新来的同学,丽丽问他多少岁了。
他说:我不告诉你,但是我比滔滔大两岁。
滔滔说:我也不告诉你,我比晓晓大两岁
晓晓说:我也不告诉你,我比小星大两岁
小星也没有告诉他说:我比小华大两岁
最后小华说,我告诉你,我今年18岁了
这个怎么办呢?当然,有人会说,这个很简单啊,知道小华的,就会知道小星的,知道小星的就会知道晓晓的,以此类推,就会知道小明的年龄啦。这个过程已经非常接近递归的思想了。
| 小华 | 18+2 |
| 小星 | 20+2 |
| 晓晓 | 22+2 |
| 滔滔 | 24+2 |
| 小明 | 26+2 |
上面的图我们可以用个序号来表示吧
age(5) = age(4)+2 age(4) = age(3) + 2 age(3) = age(2) + 2 age(2) = age(1) + 2 age(1) = 18
那么代码该怎么写呢?
def age(n): if n == 1: return 18 else: return age(n - 1) + 2 ret=age(6) print(ret)
2.一个数,除2直到不能整除2
def cal(num): if num%2==0:#先判断能不能整除 num=num//2 return cal(num) else: return num print(cal(8))
3.如果一个数可以整除2,就整除,不能整除就*3+1
def func(num): print(num) if num==1: return if num%2==0: num=num//2 else: num=num*3+1 func(num) func(5)
三级菜单
menu = {
'北京': {
'海淀': {
'五道口': {
'soho': {},
'网易': {},
'google': {}
},
'中关村': {
'爱奇艺': {},
'汽车之家': {},
'youku': {},
},
'上地': {
'百度': {},
},
},
'昌平': {
'沙河': {
'老男孩': {},
'北航': {},
},
'天通苑': {},
'回龙观': {},
},
'朝阳': {},
'东城': {},
},
'上海': {
'闵行': {
"人民广场": {
'炸鸡店': {}
}
},
'闸北': {
'火车战': {
'携程': {}
}
},
'浦东': {},
},
'山东': {},
}
def threeLM(menu): while True: for key in menu:#循环字典的key,打印出北京,上海,山东 print(key) name=input('>>>:').strip() if name=='back' or name=='quit':#如果输入back,就返回上一层。如果输入quit就退出 return name #返回的name的给了ret if name in menu: ret=threeLM(menu[name]) if ret=='quit':return 'quit'#如果返回的是quit,就直接return quit 了,就退出了 threeLM() # print(threeLM(menu))#print打印了就返回出quit了,threeLM()没有打印就直接退出了
二分查找算法
从这个列表中找到55的位置lst = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
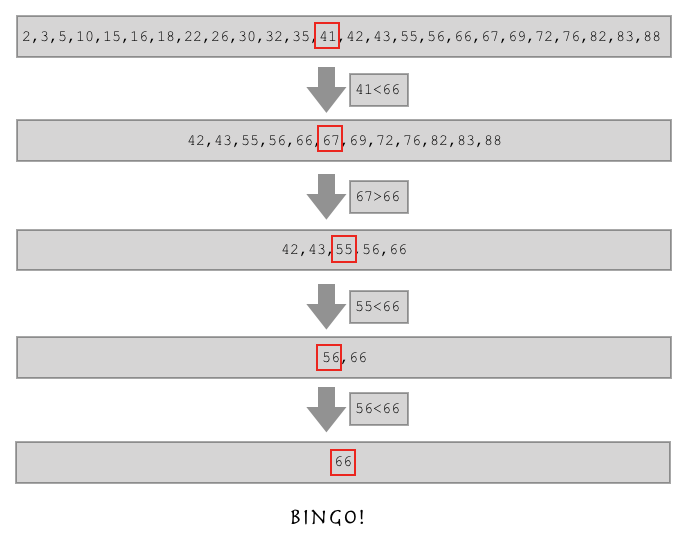
这就是二分查找,从上面的列表中可以观察到,这个列表是从小到大依次递增的有序列表。
按照上面的图就可以实现查找了。
- 普通方法:
lst = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] left = 0 # 列表的第一个元素 right = len(lst) - 1 # 列表的最后一个元素 n = 1 # 要查找的数 while left < right: middle = (left + right) // 2 # 列表中间那个数 if n < lst[middle]: right = middle elif n > lst[middle]: left = middle else: print("找到了,在第%s位"%(middle)) break else: print("没找到")
- 普通递归版本二分法:
lst = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] def binary_search(num, left, right): if left <= right: middle = (right+left) // 2 if num > lst[middle]: left = middle + 1 elif num < lst[middle]: right = middle - 1 else: return "找到了,在第%s位"%(middle) return binary_search(num,left,right) # 这个return必须加,否则接收到的永远是None. else: return -1 print(binary_search(6, 0, len(lst)-1))
l = [2, 3, 5, 10, 15, 16, 18, 22, 26, 30, 32, 35, 41, 42, 43, 55, 56, 66, 67, 69, 72, 76, 82, 83, 88] def find(l,aim): mid=len(l)//2#取中间值,//长度取整(取出来的是索引) if l[mid]>aim:#判断中间值和要找的那个值的大小关系 new_l=l[:mid]#顾头不顾尾 return find(new_l,aim)#递归算法中在每次函数调用的时候在前面加return elif l[mid]<aim: new_l=l[mid+1:] return find(new_l,aim) else: return l[mid] print(find(l,66))
l = [2, 3, 5, 10, 15, 16, 18, 22, 26, 30, 32, 35, 41, 42, 43, 55, 56, 66, 67, 69, 72, 76, 82, 83, 88] def func(l, aim,start = 0,end = len(l)-1): mid = (start+end)//2#求中间的数 if not l[start:end+1]:#如果你要找的数不在里面,就return'你查找的数字不在这个列表里面' return '你查找的数字不在这个列表里面' elif aim > l[mid]: return func(l,aim,mid+1,end) elif aim < l[mid]: return func(l,aim,start,mid-1) elif aim == l[mid]: print("bingo") return mid index = func(l,55) print(index) # print(func(l,41))
函数—函数嵌套及作用域
三元运算符
if条件成立的结果 if 条件 else 条件不成立的结果
列如:
a = 20 b = 10 c = a if a>b else b print(c)
命名空间
- 全局命名空间:创建的存储“变量名与值的关系”的空间叫做全局命名空间
- 局部命名空间:在函数的运行中开辟的临时的空间叫做局部命名空间
- 内置命名空间:内置命名空间中存放了python解释器为我们提供的名字:input,print,str,list,tuple...它们都是我们熟悉的,拿过来就可以用的方法。

三种命名空间之间的加载顺序和取值顺序:
加载顺序:内置(程序运行前加载)-->全局(从上到下顺序加载进来的)-->局部(调用的时候加载)--->内置
取值:在局部调用:局部命名空间--->全局命名空间--->内置命名空间
站在全局范围找:全局----内置----局部
使用:
全局不能使用局部的
局部的可以使用全局的
作用域
1.命令空间和作用域是分不开的
2.作用域分为两种:
全局作用域:全局命名空间与内置命名空间的名字都属于全局范围
在整个文件的任意位置都能被引用,全局有效
局部作用域:局部命名空间,只能在局部范围内生效
3.站在全局看:
使用名字的时候:如果全局有,用全局的
如果全局没有,用内置的
4.为什么要有作用域?
为了函数内的变量不会影响到全局
5.globals方法:查看全局作用域的名字【print(globals())】
locals方法:查看局部作用域的名字【print(locals())】
def func(): a = 12 b = 20 print(locals()) print(globals()) func()
站在全局看,globals is locals
global关键字:强制转换为全局变量
# x=1 # def foo(): # global x #强制转换x为全局变量 # x=10000000000 # print(x) # foo() # print(x) # 这个方法尽量能少用就少用
nonlocal让内部函数中的变量在上一层函数中生效,外部必须有
# x=1 # def f1(): # x=2 # def f2(): # # x=3 # def f3(): # # global x#修改全局的 # nonlocal x#修改局部的(当用nonlocal时,修改x=3为x=100000000,当x=3不存在时,修改x=2为100000000 ) # # 必须在函数内部 # x=10000000000 # f3() # print('f2内的打印',x) # f2() # print('f1内的打印', x) # f1() # # print(x)
函数的嵌套定义
def animal(): def tiger(): print('nark') print('eat') tiger() animal()
作用域链
x=1 def heihei(): x='h' def inner(): x='il' def inner2(): print(x) inner2() inner() heihei()
函数名的本质:就是函数的内存地址
def func(): print('func') print(func)#指向了函数的内存地址
函数名可以用作函数的参数

def func(): print('func') def func2(f): f() print('func2') func2(func)
函数名可以作为函数的返回值

return说明1 def func(): def func2(): print('func2') return func2 f2=func() f2() #func2=func() #func2() 2. def f1(x): print(x) return '123' def f2(): ret = f1('s') #f2调用f1函数 print(ret) f2() 3. def func(): def func2(): return 'a' return func2 #函数名作为返回值 func2=func() print(func2())
函数—匿名函数
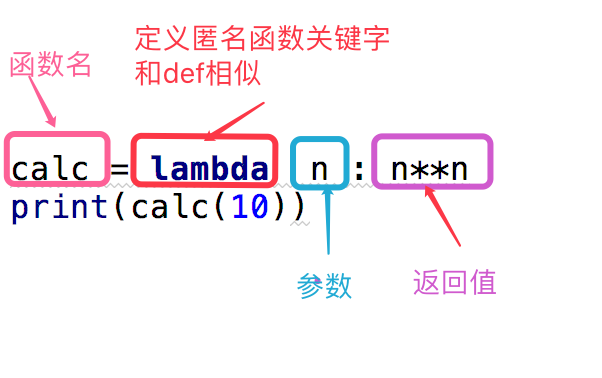
匿名函数介绍
不使用def这样的语句来定义函数,使用lambda来创建匿名函数;也叫lambda表达式 1.匿名函数的核心:一些简单的需要用函数去解决的问题,匿名函数的函数体只有一行 2.参数可以有多个,用逗号隔开 3.返回值和正常的函数一样可以是任意的数据类型 4.lambda函数有自己的命名空间,且不能访问自由参数列表之外的或全局命名空间的参数
匿名函数练习
请把下面的函数转换成匿名函数 def add(x,y) return x+y add() 结果: sum1=lambda x,y:x+y print(sum1(5,8))
dic = {'k1':50,'k2':80,'k3':90}
# func= lambda k:dic[k]
# print(max(dic,key=func))
print(max(dic,key = lambda k:dic[k]))#上面两句就相当于下面一句
3.map方法 l=[1,2,3,4] # def func(x): # return x*x # print(list(map(func,l))) print(list(map(lambda x:x*x,l)))
l=[15,24,31,14] # def func(x): # return x>20 # print(list(filter(func,l))) print(list(filter(lambda x:x>20,l)))
# 现有两个元组(('a'),('b')),(('c'),('d')), 请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}] # 方法一 t1=(('a'),('b')) t2=(('c'),('d')) # print(list(zip(t1,t2))) print(list(map(lambda t:{t[0],t[1]},zip(t1,t2)))) # 方法二 print(list([{i,j} for i,j in zip(t1,t2)])) #方法三 func = lambda t1,t2:[{i,j} for i,j in zip(t1,t2)] ret = func(t1,t2) print(ret)
函数—生成器与推导式
生成器
什么是生成器?
生成器实质就是迭代器。
在Python中有三种方式来获取生成器:
- 1、通过生成器函数
- 2、通过各种推导式来实现生成器
- 3、通过数据的转换也可以获取生成器
首先看一个很简单的函数:
def func(): print("123") return 456 ret = func() print(ret) # 结果: 123 456
将函数中的return换成yield就是生成器
def func(): print("123") yield 456 ret = func() print(ret) # 结果: <generator object func at 0x0000023853646A40>
运行的结果和上面不一样,为什么呢?由于函数中存在了yield,那么这个函数就是一个生成器函数,这个时候,再执行这个函数的时候,就不再是函数的执行了,而是获取这个生成器;如何使用呢?想想迭代器.生成器的本质就是迭代器,所以,可以执行__next__()来执行以下生成器
def func(): print("123") yield 456 ret = func() # 这个时候函数不会执⾏. ⽽是获取到⽣成器 gen = ret.__next__() # 这个时候函数才会执⾏. yield的作⽤和return⼀样. 也是返回数据 print(gen) # 结果: 123 456
那么可以看到,yield和return的效果是不一样的,有什么区别呢?yield是分段来执行一个函数,return呢?直接停止函数
def func(): print("123") yield 456 print("111") yield 222 gener = func() ret1 = gener.__next__() print(ret1) ret2 = gener.__next__() print(ret2) ret3 = gener.__next__() # 最后⼀个yield执⾏完毕. 再次__next__()程序报错, 也就是说. 和return⽆关了. print(ret3) # 结果: 123 Traceback (most recent call last): 456 File "E:/练习/函数/生成器.py", line 47, in <module> 111 222 ret3 = gener.__next__() StopIteration
当程序运行完最后一个yield,那么后面继续进行__next__()程序会报错
生成器的作用示例:
# 我们来看这样⼀个需求. 麻花藤向马荣订购10000套衣服. 马荣就比较实在. 直接造出来10000套衣服 def cloth(): lis = [] for i in range(0, 10001): lis.append("衣服"+str(i)) return lis cl = cloth() # 但是呢, 问题来了. 麻花藤现在没有这么多人啊. ⼀次性给这么多. 往哪⾥放啊. 很尴尬啊. 最好的效果是什么样呢? 麻花藤要1套. 马荣给麻花藤1套. ⼀共10000套. 是不是最完美的. def cloth(): for i in range(0,10001): yield "衣服"+str(i) cl = cloth() print(cl.__next__()) print(cl.__next__()) print(cl.__next__()) print(cl.__next__())
第一种是直接一次性全部拿出来,会很占内存,第二种使用生成器,一次就一个,用多少生成多少,生成器是一个一个的指向下一个,不会回去,__next__()到哪儿,指针就到哪儿。下一次继续获取指针指向的值
生成器send方法:
send和__next__()一样可以让生成器执行到下一个yield。
def eat(): print("我吃什么啊") a = yield "馒头" print("a=",a) b = yield "⼤饼" print("b=",b) c = yield "⾲菜盒⼦" print("c=",c) yield "GAME OVER" gen = eat() # 获取⽣成器 ret1 = gen.__next__() print(ret1) ret2 = gen.send("胡辣汤") print(ret2) ret3 = gen.send("狗粮") print(ret3) ret4 = gen.send("猫粮") print(ret4)
send和__next__()区别:
- send和next()都是让生成器向下走一次
- send可以给上一个yield的位置传递值,不能给最后一个yield传递值(会报错);在第一次执行生成器代码的时候不能使用send()
生成器可以使用for循环来循环获取内部的元素:
def func(): print(111) yield 222 print(333) yield 444 print(555) yield 666 gen = func() for i in gen: print(i) 结果: 111 222 333 444 555 666
列表推导式
- 语法:[ 最终结果(变量) for 变量 in 可迭代对象 if 条件筛选 ]
- 示例:从1~100的数,写入到列表
# 普通写法 lis = [] for i in range(1,101): lis.append(i) print(lis) # 列表推导式写法 list = [ i for i in range(1, 101) ] print(list)
# 1. 打印100以内的偶数 list = [ i for i in range(1,101) if i%2==0 ] print(list) # 2. 获取1-100内能被3整除的数 num = [ i for i in range(1,101) if i%3 == 0 ] print(num) # 3. 100以内能被3整除的数的平方 num = [ i*i for i in range(1,101) if i%3 == 0 ] print(num) # 4. 寻找名字中带有两个e的⼈的名字 names = [['Tom', 'Billy', 'Jefferson' , 'Andrew' , 'Wesley' , 'Steven' , 'Joe'],['Alice', 'Jill' , 'Ana', 'Wendy', 'Jennifer', 'Sherry' , 'Eva']] name = [name for nameLs in names for name in nameLs if name.count("e") == 2 ] print(name)
生成器推导式
- 语法:( 结果 for 变量 in 可迭代对象 if 条件筛选 )
生成器推导式和列表推导式的语法基本上时一样的,只是把[]替换成()
gen = (i for i in range(10)) print(gen) # 结果: <generator object <genexpr> at 0x0000020C25196BA0>
打印的结果就是一个生成器,可以使用for循环来循环这个生成器
gen = (i for i in range(10)) for num in gen: print(num)
生成器也可以进行筛选
# 1. 获取1-100内能被3整除的数 gen = (i for i in range(1,100) if i % 3 == 0) for num in gen: print(num) # 2. 100以内能被3整除的数的平⽅ gen = (i * i for i in range(100) if i % 3 == 0) for num in gen: print(num) # 3. 寻找名字中带有两个e的⼈的名字 names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'], ['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']] # 推导式 gen = (name for first in names for name in first if name.count("e") >= 2) for name in gen: print(name)
生成器与列表推导式的区别:
- 列表推导式比较耗内存,一次性加载,生成器推导式几乎不占内存,使用的时候才分配和使用内存
- 得到的值不一样,列表推导式得到的是一个列表,生成器推导式获取的是一个生成器
- 比如:
# 同样⼀篮⼦鸡蛋. 列表推导式: 直接拿到⼀篮⼦鸡蛋. ⽣成器表达式: 拿到⼀个老⺟鸡. 需要鸡蛋就给你下鸡蛋. # ⽣成器的惰性机制: ⽣成器只有在访问的时候才取值. 说⽩了. 你找他要他才给你值. 不找他要. 他是不会执⾏的.
def func(): print(111) yield 222 g = func() # ⽣成器g g1 = (i for i in g) # ⽣成器g1. 但是g1的数据来源于g g2 = (i for i in g1) # ⽣成器g2. 来源g1 print(list(g)) # 获取g中的数据. 这时func()才会被执⾏. 打印111.获取到222. g完毕. print(list(g1)) # 获取g1中的数据. g1的数据来源是g. 但是g已经取完了. g1 也就没有数据了 print(list(g2)) # 和g1同理
字典推导式
- 语法:{ 结果(k:v) for 变量 in 可迭代对象 if 条件筛选 }
# 1. 把字典中的key和value互换 dic = {'a': 1, 'b': '2'} new_dict = { dic[key]:key for key in dic } print(new_dict) # 2. 在以下list中. 从lst1中获取的数据和lst2中相对应的位置的数据组成⼀个新字典 lst1 = ['jay', 'jj', 'sylar'] lst2 = ['周杰伦', '林俊杰', '邱彦涛'] new_dict = { lst1[i]:lst2[i] for i in range(len(lst1)) } print(new_dict) # 3. 合并大小写对应的value值,将k统一成小写 mcase = {'a':10,'b':34,'A':7} res = {i.lower():mcase.get(i.lower(),0)+mcase.get(i.upper(),0) for i in mcase} print(res)
集合推导式
- 语法:{ 结果(k) for 变量 in 可迭代对象 if 条件筛选 }
集合推导式可以帮我们直接生成一个集合,集合的特点:无序,不重复,所以集合推导式自带去重功能
# 1. 绝对值去重 lis = [1, 2, -4, -8, -4, 3, 2] s = [abs(i) for i in lis] print(s) # 2. 求每个值的平凡 l=[5,-5,1,2,5] print({i**2 for i in l})
友情提示:惰性机制,不到最后不会拿值
# 一道有意思的题
def add(a, b): return a + b def test(): for i in range(4): yield i g = test() for n in [2,10]: g = (add(n, i) for i in g) print(list(g))
函数—内置函数
# 内置函数操作 #!usr/bin/env python # -*- coding:utf-8 -*- # 1.locals()和globals() def func(): x=1 y=2 print(locals()) print(globals()) func() # 2.eval,exec,和compile print(123) "print(456)"#字符串 eval("print(456)")#吧字符串转换成python代码去执行(有返回值) exec("print(7889)")#吧字符串转换成python代码去执行(无返回值) num = eval('4+5+6')#执行了,有返回值 print(num) num = exec('4+5+6')#执行了,没有返回值 print(num) # compile#做编译 com=compile('1+2+3','',mode = 'eval')#节省时间 print(eval(com)) print(eval('1+2+3'))#这句效果和上面的compile()效果一样 # 3.print print('123',end='')#不换行 print('456',end='') print(1,2,3) print(1,2,3,4,5,6,sep=',') # print()函数的小例子 import time import sys for i in range(0,101,2): time.sleep(0.1) char_num = i//2 #打印多少个# per_str = '%s%% : %s\n' % (i, '*' * char_num) if i == 100 else '\r%s%% : %s'%(i,'*'*char_num) print(per_str,end='', file=sys.stdout, flush=True) import sys for i in range(0, 101, 2): time.sleep(0.1) char_num = i // 2 per_str = '\r%s%% : %s' % (i, '*' * char_num) print(per_str, file=sys.stdout, flush=True) # 4.input() # 5.type() # 6.hash print(hash('asdsffd'))#一开始几个都是不变的,,然后重新运行一次就变了 print(hash('asdsffd')) print(hash('asdsffd')) print(hash('asdsffd')) print(hash('asdsffd')) print(hash((1,2,3,4))) # 7.open # r,w,a,r+,w+,a+(都可以加b) f=open('tmp','r+')#r+打开文件 print(f.read(3))#如果读了在写,追加 f.seek(5)#如果seek指定了光标的位置,就从该位置开始覆盖这写 f.write('aaaaaa')#如果直接写,从头覆盖 f.close() # 8.__import__() import os import sys import time # 9.callable:查看能不能调用 print(callable(123))#数字不能调用结果就是False print(callable(open))#函数可以调用就返回True # 10.dir 查看数据类型的方法 print(dir(__builtins__))#看着报错,,但其实不报错 print(dir(int)) print(dir(list)) print(dir(0))#和int一样 print(set(dir(list))-set(dir(tuple))) # 11.int num1=int(123) num2=int(12.3)#强制转换成int类型 print(num1,num2) # 12.取商/余 print(divmod(7,3)) # 13.计算最小值 print(min(1,2,3,4)) print(min([5,6])) # 13.计算最大值 print(max(1,2,3,4)) print(max([5,6])) # 14.sum求和 print(sum(1,3,4,5))#出错了,参数是序列,散列不行 print(sum([5,6])) print(sum((1,2,3,4))) # 以下的两个方式是一样的 print(1+2) print(int(1).__add__(2)) # 15.round精确度 print(round(3.1415926,2))#保留两位 # 16.pow()幂运算 print(pow(2,3)) print(2**3) # 17.和数据结构相关的 # 1.reversed()顺序的反转 l=[1,2,3,4] print(list(reversed(l)))#是生成了一个新的列表,没有改变原来的列表(以后能不用reversed就不用reversed,用reverse) # l.reverse()#在现在的列表的基础上修改了,修改的是原来的列表 print(l) # 2.slice切片 # 3.format()#除了格式化以外的作业 print(format('test','<20')) print(format('test','>40')) print(format('test','^40')) # 4.bytes s='你好' sb=bytes(s,encoding='utf-8') print(sb) print(sb.decode('utf-8')) sb2=bytearray(s,encoding='utf-8') sb2[0]=229 #修改 了解就好 print(sb2.decode('utf-8')) print(sb2) print(sb2[0]) # 5.repr print(repr('1234')) print(repr(1234)) print('name:%r'%('egon'))#你怎么传进去的就按什么格式打印出来了 # 6.set和frozenset(不可变的集合)就像list和tuple # 7.enumerate l=['a','b'] for i in enumerate(l): print(i) for i ,j in enumerate(l): print(i,j) # 8.all和any print(all([1,2,3])) print(all([0,2,3]))#因为0是False print(any([1,2,3])) print(any([0,2,3])) # 9.zip() l=[1,2,3] l2=[4,5,6,7,8] print(zip(l,l2)) print(list(zip(l,l2))) l3={'k':'v'} print(list(zip(l,l3))) print(ret) 常见内置函数的操作
sorted() 排序
排序函数:sorted
- 语法:sorted(lterable, key=None, reverse=False)
Iterable: 可迭代对象 key: 排序规则(排序函数), 在sorted内部会将可迭代对象中的每⼀个元素传递给这个函 数的参数. 根据函数运算的结果进⾏排序 reverse: 是否是倒叙. True: 倒叙, False: 正序lst = [1,5,3,4,6] lst2 = sorted(lst) print(lst) # 原列表不会改变 print(lst2) # 返回的新列表是经过排序的 dic = {1:'A', 3:'C', 2:'B'} print(sorted(dic)) # 如果是字典. 则返回排序过后的key
- 和函数组合使用:
# 按照字符串的长度进行排序 lst = ['小白', '小白1', '小白21','小白123', '小黑1','小黑3232'] # 计算字符串长度 def func(lst): return len(lst) ll = sorted(lst, key=func) print(ll)
- 和lambda组合使用:
# 按照字符串的长度进行排序 lst = ['小白', '小白1', '小白21','小白123', '小黑1','小黑3232'] # 计算字符串长度 def func(lst): return len(lst) print(sorted(lst, key=lambda s:len(s))
# 按照年龄排序 lst = [ {"name":"小白", "age":14}, {"name":"小黑", "age":25}, {"name":"小黄", "age":11}, {"name":"小蓝", "age":30}, {"name":"小粉", "age":8}, ] def func(dic): return dic["age"] ll = sorted(lst, key=func) print(ll) # 使用匿名函数: ll = sorted(lst, key=lambda dic:dic["age"]) print(ll)
filter() 筛选
- 语法:filter(function, lterable)
function: ⽤来筛选的函数. 在filter中会⾃动的把iterable中的元素传递给function. 然后根据function返回的True或者False来判断是否保留此项数据 terable: 可迭代对象lst = [1,2,3,4,5,6,7] ll = filter(lambda x: x%2==0, lst) # 筛选所有的偶数 print(ll) # 得到的是一个迭代器 print(list(ll))
# 筛选年龄大于20岁的 lst = [ {"name":"小白", "age":14}, {"name":"小黑", "age":25}, {"name":"小黄", "age":11}, {"name":"小蓝", "age":30}, {"name":"小粉", "age":8}, ] fl = filter(lambda e:e["age"]>20, lst) print(list(fl))
map() 映射
- 语法:map(function, iterable)
可以对可迭代对象中的每⼀个元素进⾏映射. 分别取执⾏function
- 计算列表中每个元素的平方,返回新列表
def func(e): return e * e mp = map(func,[1,3,5,7,9]) print(list(mp))
改写成lambda
mp = map(lambda e:e*e, [1,3,5,7,9]) print(list(mp))
- 计算两个列表中两个相同位置的数据的和
lst1 = [1, 2, 3, 4, 5] lst2 = [2, 4, 6, 8, 10] print(list(map(lambda x,y:x+y, lst1,lst2)))
内置参数详解 https://docs.python.org/3/library/functions.html?highlight=built#ascii
内置函数流程图 https://www.processon.com/mindmap/5be92ca8e4b0128076976f13

 浙公网安备 33010602011771号
浙公网安备 33010602011771号