Linux-负载均衡HAproxy
负载均衡之HAProxy
现在常用的三大开源软件负载均衡器分别是Nginx、LVS、HAProxy。三大软件特点如下:
- LVS负载均衡的特点:
(1)抗负载能力强,抗负载能力强、性能高、能达到F5硬件的60%;对内存和cpu资源消耗比较低。 (2)工作在网络4层,通过VRRP协议转发(仅作分发之用),具体的流量由linux内核处理,因此没有流量产生。 (3)稳定性、可靠性好,自身有完美的热备方案(如:LVS+Keepalived)。 (4)应用范围比较广,可以对所有应用做负载均衡。 (5)不支持正则处理,不能做动静分离。 (6)支持负载均衡算法:rr(轮循)、wrr(加权轮循)、lc(最小连接)、wlc(权重最小连接)。 (7)配置复杂,对网络依赖比较大,稳定性很高。
- Nginx负载均衡的特点:
(1)工作在网络的七层之上,可以针对http应用做一些分流的策略,比如针对域名、目录结构。 (2)Nginx对网络的依赖比较小,理论上能ping通就能进行负载均衡。 (3)Nginx安装和配置比较简单,测试起来比较方便。 (4)也可以承担高的负载压力且稳定,一般能支撑超过1万次的并发。 (5)对后端服务器的健康检查,只支持通过端口检测,不支持通过url来检测。 (6)Nginx对请求的异步处理可以帮助节点服务器减轻负载。 (7)Nginx仅能支持http、https和Email协议,这样就在使用范围较小。 (8)不支持Session的直接保持,但能通过ip_hash来解决,对Big request header的支持不是很好。 (9)支持负载均衡算法:Round-robin(轮循)、Weight-round-robin(加权轮循)、IP-hash(IP哈希)。 (10)Nginx还能做Web服务器即Cache功能。
- HAProxy负载均衡的特点:
(1)支持两种代理模式:TCP(四层)和HTTP(七层)。 (2)能够补充Nginx的一些缺点比如Session的保持,Cookie的引导等工作。 (3)支持url检测后端的健康状态。 (4)更多负载均衡策略比如:动态加权轮循(Dynamic Round Robin),加权源地址哈希(Weighted Source Hash),加权URL哈希和加权参数哈希(Weighted Parameter Hash)。 (5)单纯从效率上来将HAProxy更会比Nginx有更出色的负载均衡速度。 (6)HAProxy可以对Mysql进行负载均衡,对后端的DB节点进行检测和负载均衡。 (7)支持负载均衡算法:Round-robin(轮循)、Weight-round-robin(加权轮循)、source(源地址保持)、RI(请求URL)、rdp-cookie(根据cookie) (8)不能做Web服务器即Cache
这三大主流软件负载均衡器使用业务场景:
(1)网站建设初期,可以选用Nginx/HAProxy作为反向代理负载均衡(或者流量不大都可以不选用负载均衡),因为其配置简单,性能也能满足一般的业务场景。如果考虑到负载均衡器是有单点问题,可以采用Nginx+Keepalived/HAProxy+Keepalived避免负载均衡器自身的单点问题。
(2)网站并发达到一定程度之后,为了提高稳定性和转发效率,可以使用LVS、毕竟LVS比Nginx/HAProxy要更稳定,转发效率也更高。不过维护LVS对维护人员的要求也会更高,投入成本也更大。
需要注意的是
Nginx和HAProxy比较:Nginx支持七层、用户量最大,稳定性比较可靠。HAProxy支持四层和七层,支持更多的负载均衡算法,支持session保存等。具体选择看使用场景。目前来说HAProxy由于弥补了一些Nginx的缺点致使其用户量也不断在提升。
衡量负载均衡器好坏的几个重要因素
(1)会话率:单位时间内的处理的请求数 (2)会话并发能力:并发处理能力 (3)数据率:处理数据能力
经过官方测试统计,haproxy 单位时间处理的最大请求数为20000个,可以同时维护40000-50000个并发连接,最大数据处理能力为10Gbps。综合上述,haproxy是性能优越的负载均衡、反向代理服务器。
HAProxy简介
HAProxy是法国人Willy Tarreau开发的一款可应对客户端10000以上的同时连接的高性能的TCP和HTTP负载均衡器。由于其丰富强大的功能在国内备受推崇,是目前主流的负载均衡器。Haproxy是一个开源的高性能的反向代理或者说是负载均衡服务软件之一,它支持双机热备、虚拟主机、基于TCP和HTTP应用代理等功能。其配置简单,而且拥有很好的对服务器节点的健康检查功能(相当于keepalived健康检查),当其代理的后端服务器出现故障时,Haproxy会自动的将该故障服务器摘除,当服务器的故障恢复后haproxy还会自动重新添加回服务器主机。
Haproxy实现了一种事件驱动、单一进程模型,此模型支持非常大的并发连接数。多进程或多线程模型受内存限制、系统调度器限制以及无处不在的锁限制,很少能处理数千并发连接。事件驱动模型因为在有更好的资源和时间管理的用户空间(User-Space)实现所有这些任务,所以没有这些问题。此模型的弊端是,在多核系统上,这些程序通常扩展性较差。这就是为什么必须对其进行优化以使每个CPU时间片(Cycle)做更多的工作。
Haproxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。haproxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进当前架构中,同时可以保护web服务器不被暴露到网络上。
Haproxy软件引入了frontend,backend的功能,frontend(acl规则匹配)可以根据任意HTTP请求头做规则匹配,然后把请求定向到相关的backend(server pools等待前端把请求转过来的服务器组)。通过frontend和backend,可以很容易的实现Haproxy的7层负载均衡代理功能。
HAProxy是一种高效、可靠、免费的高可用及负载均衡解决方案,非常适合于高负载站点的七层数据请求。客户端通过HAProxy代理服务器获得站点页面,而代理服务器收到客户请求后根据负载均衡的规则将请求数据转发给后端真实服务器。
同一客户端访问服务器,HAProxy保持会话的三种方案:
(1)HAProxy将客户端IP进行Hash计算并保存,由此确保相同IP来访问时被转发到同一台真实服务器上。 (2)HAProxy依靠真实服务器发送给客户端的cookie信息进行会话保持。 (3)HAProxy保存真实服务器的session及服务器标识,实现会话保持功能。
HAProxy工作原理
HAProxy提供高可用、负载均衡以及基于TCP(第四层)和HTTP(第七层)的应用的代理,支持虚拟主机,他是免费、快速并且可靠的一种解决方案。HAProxy特别是用于那些负载特别大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在时下的硬件上,完全可以支持数以万计的并发连接,并且它的运行模式使得它可以很简单安全的整合进您当前的架构中,同时可以保护你的web服务器不被暴露到网络上。
HAProxy实现了一种事件驱动、单一进程模型,此模型支持非常大的并发连接数。多进程或多线程模型受内存限制、系统调度器限制以及无处不在的锁限制,很少能处理数千并发链接。事件驱动模型因为在有更好的资源和时间管理的用户端(user-space)实现所有这些任务,所以没有这些问题。此模型的弊端是,在多核系统上,这些程序通常扩展性较差。这就是为什么他们必须进行优化以及使每个CPU时间片(Cycle)做更多的工作。
HAProxy的优点
(1)免费开源,稳定性也是非常好。单HAProxy也跑的不错,稳定性可以与硬件级的F5相媲美。
(2)根据官方文档,HAProxy可以跑满10Gbps,这个数值作为软件级负载均衡器也是相当惊人的。
(3)HAProxy支持连接拒绝:因为维护一个连接的打开的开销是很低的,有时我们需要限制攻击蠕虫(attack bots),也就是说限制它们的连接打开从而限制它们的危害。这个已经为一个陷于小型DDoS攻击的网站开发了而且已经拯救了很多站点,这个优点也是其它负载均衡器没有的。
(4)HAProxy支持全透明代理(已具备硬件防火墙的典型特点):可以用客户端IP地址或者任何其它地址来连接后端服务器。这个特性仅在Linux 2.4/2.6内核打了tcp proxy补丁后才可以使用。这个特性也使得为某特殊服务器处理部分流量同时又不修改服务器的地址成为可能。
(5)HAProxy现在多用于线上的MySQL集群环境,常用它作为MySQL(读)负载均衡。
(6)自带强大的监控服务器状态的页面,实际环境中可以结合Nagios进行邮件或短报警。
HAProxy主要工作位置
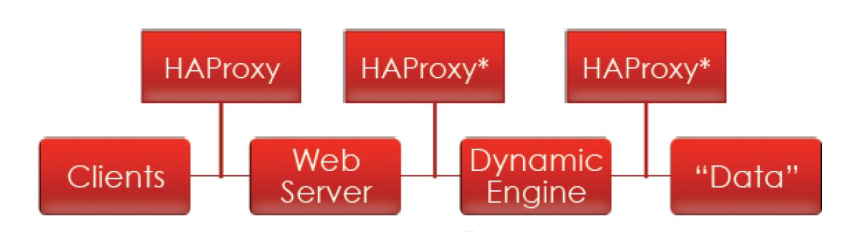
- HAProxy支持http反向代理
- HAProxy支持动态程序的反向代理
-HAProxy支持基于数据库的反向代理
HAProxy 相关术语
访问控制列表(ACL)
在负载均衡中,ACL用于测试某些状况,并根据测试结果执行某些操作(例如选定一套服务器或者屏蔽某条请求),如下ACL示例
acl url_blog path_beg /blog
如果用户请求的路径以/blog 开头,则匹配这条ACL。举例来说,http://www.cnblogs.com/blog/blog-entry-1请求即符合这一条件。
Backend
所谓的backend是指一组服务器,负责接收各转发请求。Backend在HAProxy配置中的backend部分进行定义。一般来讲,backend的定义主要包括:
- 使用哪种负载均衡算法
- 一套服务器与端口列表
一条backend能够容纳一套或者多套服务器一一总体而言向backend中添加更多服务器将能够将负载扩散至更多的服务器,从而增加潜在负载容量。这种方式也能够提升可靠性,从而应对服务器发生故障的情况。
下面来看一套双backend配置示例,分别为web-backend与blog-backend,其各自包含两套web服务器,且监听端口80:
backend web-backend balance roundrobin server web1 web1.kevin.com:80 check server web2 web2.kevin.com:80 check backend blog-backend balance roundrobin mode http server blog1 blog1.kevin.com:80 check server blog2 blog2.kevin.com:80 check
其中:
- balance roundrobin行指定负载均衡算法,具体细节参考负载均衡算法部分
- mode http 则指定所使用的7层代理机制,具体参考负载均衡类型部分
- 结尾处的check 选项指定在这些后端服务器上执行运行状态检查
Frontend
一条frontend负责定义请求如何被转发至backend。Frontend在HAProxy配置中的frontend部分。其定义由以下几个部分组成:
- 一组IP地址与一个端口(例如10.1.1.2:80,*:443,等等)
- ACL
- use_backend规则,其负责根据当前ACL条件定义使用哪个backend,而default_backend规则处理一切其它情况
可以将同一frontend配置至多种不同网络流量类型!
负载均衡的基本类型
无负载均衡
简单的无负载均衡Web应用环境,用户会直接接入Web服务器,即ktest.com且其中不存在负载均衡机智。如果单一Web服务器发生故障,用户将无法进入到该服务器。另外,如果多位用户同时访问该服务器,且其无法处理该负载,则可能出现相应缓慢或者无法接入的情况
四层负载均衡
最为简单的负载均衡方式,将网络流量引导至多台服务器以使用四层(即传输层)负载均衡。这种方式会根据IP范围与端口进行用户流量转发(如果有请求执行http://ktest.com/anything,则该流量将被转发至backend,并由其处理全部指向ktest.com在端口80上的请求)
frontend web_80 mode tcp bind :80 default_backend web-backend backend web-backend mode tcp server 192.168.1.25 192.168.1.25:80 weight 1 check inter 1s rise 2 fall 2 server 192.168.1.26 192.168.1.26:80 weight 1 check inter 1s rise 2 fall 2
用户访问负载均衡器,后者将用户请求转发至后端服务器的web-backend组。被选定的后端服务器将直接影响用户请求。总体而言,web-backend中的全部服务器都应当拥有同样的内容,否则用户可能会遭遇内容不一致的问题。请注意后端两个Web服务器都接入同样的数据库服务器。
七层负载均衡
另一种更为复杂的负载均衡方式,网络流量使用7层(即应用层)负载均衡。使用7层意味着负载均衡器能够根据用户的请求内容将请求转发至不同后端服务器。这种方式允许大家在同一域名及端口上运行多套Web应用服务器。下图为一套简单的7层负载均衡示例,在本示例中,如果用户向ktest.com/blog发送请求,则会被转发至blog后端,其包含一组运行有同一blog应用的服务器。其它请求则会被转发至web-backend,其负责运行其应用。本示例中的两套backend皆使用同样的数据库服务器。
frontend http bind *:80 mode http acl url_blog path_beg /blog use_backend blog-backend if url_blog default_backend web-backend backend web-backend mode http balance roundrobin cookie SERVERID insert indirect nocache option httpclose option forwardfor server web01 192.168.1.25:80 weight 1 cookie 3 check inter 2000 rise 2 fall 5 server web01 192.168.1.26:80 weight 1 cookie 3 check inter 2000 rise 2 fall 5
这部分片段配置一套名为http的frontend,其负责处理端口80上的所有输入流量。
- acl url_blog path_beg 这里的/blog表示匹配那些用户请求路径以/blog开头的请求。
- use_backend blog-backend if url_blog 这里采用该ACL将流量代理至blog-backend。
- default_backend web-backend 这里指定全部其它流量将被转至web-backend。
负载均衡算法
HAProxy支持的负载均衡算法
负载均衡算法用于检测后端中的哪套服务器被负载均衡机制选定进行请求响应。HAProxy提供多种算法选项。除了负载均衡算法之外,我们还能够为服务器分配一个weight参数来指定该服务器被选定的频率。由于HAProxy提供多种负载均衡算法,下面说明几种常用的算法:
- roundrobin:表示简单的轮循,即客户端每访问一次,请求轮循跳转到后端不同的节点机器上
- static-rr:基于权重轮循,根据权重轮循调度到后端不同节点
- leastconn:加权最少连接,表示最少连接者优先处理
- source:表示根据请求源IP,这个跟Nginx的IP_hash机制类似,使用其作为解决session问题的一种方法
- uri:表示根据请求的URL,调度到后端不同的服务器
- url_param:表示根据请求的URL参数来进行调度
- hdr(name):表示根据HTTP请求头来锁定每一次HTTP请求
- rdp-cookie(name):表示根据cookie(name)来锁定并哈希每一次TCP请求
常用的负载均衡算法
- 轮循算法:roundrobin,Round Robin会对服务器进行轮流选定,亦为HAProxy的默认算法。即客户端每访问一次,请求就跳转到后端不同的节点机器上。
- 根据请求源IP算法:source,其根据源IP(即用户IP地址)进行服务器选定。通过这种方式,我们可以确定同一用户接入同一服务器。
- 最少连接者先处理算法:lestconn,选定连接数量最少的服务器——建议在周期较长的会话中使用这一算法。同一后端中的服务器亦会以轮循方式进行轮流选定。
粘性会话
部分应用要求用户始终接入同一后端服务器,这一点需要利用粘性会话实现,其要求在backend中使用appsession参数。
运行状态检查
HAProxy利用运行状态来检测后端服务器是否可用于处理请求。通过这种方式,我们不必以手动方式撤下不可用的后端服务器。默认运行状态检查会与目标服务器建立一条TCP连接,即检查后端服务器是否在监听所配置的IP地址和端口。
如果某套服务器未能通过运行状态检查,并因此无法相应请求,则其会在后端中被自动禁用——意味着流量将不再被转发至该服务器处,直到其重新恢复状态。如果后端中的全部服务器皆发生故障,则服务将不再可用,直到至少一套后端服务器重新恢复正常。
对于特定后端类型,列如特定状态下的数据库服务器,默认运行状态检查可能无法正确识别其正常与否。
其它解决方案
如果觉得HAProxy可能太过复杂,那么以下解决方案同样值得考虑:
- LVS - 一套简单且快速的4层负载均衡器,多数linux发行版都内置有这套方案
- Nginx - 一套快速且可靠的Web服务器,亦可用于代理及负载均衡。Nginx通常与HAProxy相结合以实现缓存及压缩功能。
HAProxy部署
源码编译安装
(1)安装依赖软件包
# yum install -y net-tools vim lrzsz tree screen lsof tcpdump nc mtr nmap gcc glib gcc-c++ make
(2)下载软件包
# cd /usr/local/ # wget https://www.haproxy.org/download/1.9/src/haproxy-1.9.6.tar.gz
(3)编译安装
# tar xzf haproxy-1.9.6.tar.gz # cd haproxy-1.9.6/ # make TARGET=linux2628 PREFIX=/usr/local/haproxy-1.9.6 # make install # cp /usr/local/sbin/haproxy /usr/sbin/ # haproxy -v HA-Proxy version 1.9.6 2019/03/29 - https://haproxy.org/
(4)启动脚本
# cp /usr/local/haproxy-1.9.6/examples/haproxy.init /etc/init.d/haproxy # chmod 755 /etc/init.d/haproxy
(5)配置文件
# useradd -r haproxy //创建haproxy用户 # mkdir /etc/haproxy //创建存放配置文件的目录 # mkdir /var/lib/haproxy //创建存放socket文件的目录 # vim /etc/haproxy/haproxy.cfg //编辑配置文件 global log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon stats socket /var/lib/haproxy/stats defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 listen admin bind 0.0.0.0:8088 stats enable stats refresh 2s stats uri /status stats auth haproxy:superman stats realm "haproxy info" stats hide-version
(6)启动haproxy
# systemctl start haproxy
说明:如果启动HAProxy出现 /etc/rc.d/init.d/haproxy: line 26: [: =: unary operator expected 这个错误,修改/etc/init.d/haproxy 文件的26行 [ ${NETWORKING} = "no" ] && exit 0 为 [ "${NETWORKING}" = "no" ] && exit 0
yum安装
(1)直接yum安装即可
# yum install haproxy -y
(2)文件存放位置
/usr/sbin/haproxy //二进制文件 /usr/share/haproxy //共享文件 /var/lib/haproxy //库文件 /etc/rc.d/init.d/haproxy //启动二进制文件 /etc/logrotate.d/haproxy //日志切割 /etc/sysconfig/haproxy //配置 /etc/haproxy //配置目录
HAProxy配置
HAProxy配置过程的3个主要部分
- 命令行参数,这是最优先的
- global(全局)段,设置进程级参数
- 代理配置段,通常位于“default”,“listen”,“frontend”,“backend”这样的形式内
配置文件的语法是由关键字后跟可选的一个或者多个参数(参数之间有空格)组成。如果字符串中包含空格,必须使用“\”进行转义。\本身需要使用\进行转义。
一些参数值为时间,比如说 timeout。时间通常单位为毫秒(ms),但是也可以通过加后缀来使用其他的单位,支持的单位有:
- us : microseconds. 1 microsecond = 1/1000000 second - ms : milliseconds. 1 millisecond = 1/1000 second. This is the default. - s : seconds. 1s = 1000ms - m : minutes. 1m = 60s = 60000ms - h : hours. 1h = 60m = 3600s = 3600000ms - d : days. 1d = 24h = 1440m = 86400s = 86400000ms
HAProxy配置中的五大部分
HAProxy配置文件根据功能和用途,主要有5个部分组成,但有些部分不是必须的,可以根据需要选择相应的部分进行配置。
- global:用来设定全局配置参数,属于进程级的配置,通常和操作系统配置有关。
- defaults:默认参数的配置部分,有些部分设置的参数值,默认会自动引用到下面的frontend、backend和listen部分中,因此,如果某些参数属于公用的配置,只需要在defaults部分添加一次即可。而如果在frontend、backend和listen部分中也配置了与defaults部分一样的参数,那么defaults部分参数对应的值自动被覆盖。
- frontend:此部分用于设置用户请求的前端虚拟节点。匹配用户接收客户所请求的域名,url等,并针对不同的匹配,做不同的请求处理。
- backend:此部分用于设置集群后端服务集群的配置,也就是用来添加一组真实服务器,以及对后端服务器的一些权重、队列、连接数等选项的设置。
- listen:此部分可以理解为frontend和backend的结合题。
HAProxy配置文件的配置方法主要用两种:
一种是有前端(frontend)和后端(backend)配置块组成,前端和后端都可以有多个。
第二种是只有一个listen配置块来同时实现前端和后端。
global #全局参数的配置
log 127.0.0.1 local0 info # log语法:log [max_level_1] # 全局的日志配置,使用log关键字,指定使用127.0.0.1上的syslog服务中的local0日志设备,记录日志等级为info的日志 maxconn 4096 # 定义每个haproxy进程的最大连接数,由于每个连接包括一个客户端和一个服务器端,所以单个进程的TCP会话最大数目将是该值的两倍。 user haproxy group haproxy # 设置运行haproxy的用户和组,也可使用uid,gid关键字替代之 daemon # 以守护进程的方式运行 nbproc 16 # 设置haproxy启动时的进程数,根据官方文档的解释,我将其理解为:该值的设置应该和服务器的CPU核心数一致,即常见的2颗8核心CPU的服务器,即共有16核心,则可以将其值设置为:<=16 ,创建多个进程数,可以减少每个进程的任务队列,但是过多的进程数也可能会导致进程的崩溃。这里我设置为16 maxconn 4096 # 定义每个haproxy进程的最大连接数,由于每个连接包括一个客户端和一个服务器端,所以单个进程的TCP会话最大数目将是该值的两倍。 #ulimit -n 65536 # 设置最大打开的文件描述符数,在1.4的官方文档中提示,该值会自动计算,所以不建议进行设置 pidfile /var/run/haproxy.pid # 定义haproxy的pid
示例:
global maxconn 100000 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid uid 99 gid 99 daemon nbproc 1 log 127.0.0.1 local3 info stats socket /var/lib/haproxy/stats
代理(Proxies)相关设置
使用HAProxy进行反向代理负载均衡,最常修改的部分就是代理相关的配置了,代理相关配置位于下列配置段中,
-defaults <name>
-frontend <name>
-backend <name>
-listen <name>
"defaults"段为其后的所有其他配置段设置默认参数。 "defaults"段可以有多个,后设置的总是会覆盖之前的配置。查看下面的列表可以知道"defaults"段可以使用哪些配置参数。"defaults"关键字是可选的,但是为了更好的可读性,建议加上。
"frontend"段描述了一组监听的套接字,它们接受客户端连接。
"backend"段描述了一组服务器,代理(Haproxy)会连接这些服务器并转发客户端请求到这些服务器上。
"listen"段定义了一个完整的代理,它的前段(frontend)和后端(frontend)都在这个配置段里。这种配置通常用于仅TCP的流量.
代理名必须由大(小)写字母、数字、'-'、'_'、'.'、':'组成。ACL名字是大小写敏感的,也即www和WWW分别指不同的代理。
由于历史原因,所有的代理名字是可以重叠的,这种仅仅会导致日志有些问题。后来内容交换(Content Switching)的加入使得两个有重复功能的代理(frontend/backend)必须使用不同的名字。然而,仍然允许frontend和backend使用同一个名字,因为这种配置会经常遇到。
当前,HAProxy支持两种主要的代理模式: "tcp"也即4层,和"http",即7层。在4层模式下,HAproxy仅在客户端和服务器之间转发双向流量。7层模式下,HAProxy会分析协议,并且能通过允许、拒绝、交换、增加、修改或者删除请求(request)或者回应(response)里指定内容来控制协议,这种操作要基于特定规则。
defaults 配置
defaults # 默认部分的定义 mode http # mode语法:mode {http|tcp|health} 。http是七层模式,tcp是四层模式,health是健康检测,返回OK log 127.0.0.1 local3 err # 使用127.0.0.1上的syslog服务的local3设备记录错误信息 retries 3 # 定义连接后端服务器的失败重连次数,连接失败次数超过此值后将会将对应后端服务器标记为不可用 option httplog # 启用日志记录HTTP请求,默认haproxy日志记录是不记录HTTP请求的,只记录“时间[Jan 5 13:23:46] 日志服务器[127.0.0.1] 实例名已经pid[haproxy[25218]] 信息[Proxy http_80_in stopped.]”,日志格式很简单。 option redispatch # 当使用了cookie时,haproxy将会将其请求的后端服务器的serverID插入到cookie中,以保证会话的SESSION持久性;而此时,如果后端的服务器宕掉了,但是客户端的cookie是不会刷新的,如果设置此参数,将会将客户的请求强制定向到另外一个后端server上,以保证服务的正常。 option abortonclose # 当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接 option dontlognull # 启用该项,日志中将不会记录空连接。所谓空连接就是在上游的负载均衡器或者监控系统为了探测该服务是否存活可用时,需要定期的连接或者获取某一固定的组件或页面,或者探测扫描端口是否在监听或开放等动作被称为空连接;官方文档中标注,如果该服务上游没有其他的负载均衡器的话,建议不要使用该参数,因为互联网上的恶意扫描或其他动作就不会被记录下来 option httpclose # 这个参数我是这样理解的:使用该参数,每处理完一个request时,haproxy都会去检查http头中的Connection的值,如果该值不是close,haproxy将会将其删除,如果该值为空将会添加为:Connection: close。使每个客户端和服务器端在完成一次传输后都会主动关闭TCP连接。与该参数类似的另外一个参数是“option forceclose”,该参数的作用是强制关闭对外的服务通道,因为有的服务器端收到Connection: close时,也不会自动关闭TCP连接,如果客户端也不关闭,连接就会一直处于打开,直到超时。 contimeout 5000 # 设置成功连接到一台服务器的最长等待时间,默认单位是毫秒,新版本的haproxy使用timeout connect替代,该参数向后兼容 clitimeout 3000 # 设置连接客户端发送数据时的成功连接最长等待时间,默认单位是毫秒,新版本haproxy使用timeout client替代。该参数向后兼容 srvtimeout 3000 # 设置服务器端回应客户度数据发送的最长等待时间,默认单位是毫秒,新版本haproxy使用timeout server替代。该参数向后兼容
示例:
defaults option http-keep-alive maxconn 100000 mode http timeout connect 5000ms timeout client 50000ms timeout server 50000ms
Listen 配置
listen status # 定义一个名为status的部分 bind 192.168.1.24:1080 # 定义监听的套接字 mode http # 定义为HTTP模式 log global # 继承global中log的定义 stats refresh 30s # stats是haproxy的一个统计页面的套接字,该参数设置统计页面的刷新间隔为30s stats uri /status # 设置统计页面的uri为/status,访问地址即为:http://192.168.1.24:1080/status stats realm "Private lands" # 设置统计页面认证时弹出对话框的提示内容 stats auth admin:password # 设置统计页面认证的用户和密码,如果要设置多个,另起一行写入即可 stats hide-version # 隐藏统计页面上的haproxy版本信息
示例:
listen status mode http bind 192.168.1.24:1080 stats enable stats uri /status stats auth haproxy:superman stats hide-version
Frontend 配置
frontend http_80_in # 定义一个名为http_80_in的前端部分 bind 0.0.0.0:80 # http_80_in定义前端部分监听的套接字 mode http # 定义为HTTP模式 log global # 继承global中log的定义 option forwardfor # 启用X-Forwarded-For,在requests头部插入客户端IP发送给后端的server,使后端server获取到客户端的真实IP acl static_down nbsrv(static_server) lt 1 # 定义一个名叫static_down的acl,当backend static_sever中存活机器数小于1时会被匹配到 use_backend php_server if static_down # 如果满足策略static_down时,就将请求交予backend php_server
示例:
frontend frontend_www_example_com bind 192.168.1.24:80 mode http option httplog log global default_backend backend_www_example_com //应用后端自定义服务器组名backend_www_example_com
Backend 配置
backend php_server #定义一个名为php_server的后端部分 mode http # 设置为http模式 balance source # 设置haproxy的调度算法为源地址hash cookie SERVERID # 允许向cookie插入SERVERID,每台服务器的SERVERID可在下面使用cookie关键字定义 option httpchk GET /test/index.php # 开启对后端服务器的健康检测,通过GET /test/index.php来判断后端服务器的健康情况 server php_server_1 10.12.25.68:80 cookie 1 check inter 2000 rise 3 fall 3 weight 2 server php_server_2 10.12.25.72:80 cookie 2 check inter 2000 rise 3 fall 3 weight 1 server php_server_bak 10.12.25.79:80 cookie 3 check inter 1500 rise 3 fall 3 backup # server语法:server [:port] [param*] # 使用server关键字来设置后端服务器;为后端服务器所设置的内部名称[php_server_1],该名称将会呈现在日志或警报中、后端服务器的IP地址,支持端口映射[10.12.25.68:80]、指定该服务器的SERVERID为1[cookie 1]、接受健康监测[check]、监测的间隔时长,单位毫秒[inter 2000]、监测正常多少次后被认为后端服务器是可用的[rise 3]、监测失败多少次后被认为后端服务器是不可用的[fall 3]、分发的权重[weight 2]、最为备份用的后端服务器,当正常的服务器全部都宕机后,才会启用备份服务器[backup]
示例:
backend backend_www_example_com option forwardfor header X-REAL-IP option httpchk HEAD / HTTP/1.0 balance source server web-node1 192.168.1.25:8080 cookie 1 check inter 2000 rise 3 fall 3 server web-node2 192.168.1.26:8080 cookie 2 check inter 2000 rise 3 fall 3 server web-node3_bak 192.168.1.27:80 cookie 3 check inter 1500 rise 3 fall 3 backup
HAProxy健康检查
HAProxy作为Loadbalance,支持对 backend 的健康检查,以保证在后端的 backend 不能服务时,把从 frontend进来的 request 分配至其它可服务的 backend,从而保证整体服务的可用性。
通过监听端口进行健康检测
这种检测方式,haproxy 知会去检查后端 server 的端口,并不能保证服务的真正可用
listen http_proxy 0.0.0.0:80 mode http cookie SERVERID balance roundrobin option httpchk server web1 192.168.1.25:80 cookie server01 check server web2 192.168.1.26:80 cookie server02 check inter 500 rise 1 fall 2
通过URL获取进行健康检测
这种检测方式,是用过去GET 后端的 server 的web页面,基本上可以代表后端服务的可用性
listen http_proxy 0.0.0.0:80 mode http cookie SERVERID balance roundrobin option httpchk GET /index.html server web1 192.168.1.25:80 cookie server01 check server web2 192.168.1.26:80 cookie server02 check inter 500 rise 1 fall 2
相关配置
option httpchk <method><uri><version> 启用七层健康检测 http-check disable-on-404 //如果backend返回404,则除了长连接之外的后续请求将不被分配至该backend http-check send-state //增加一个header,同步HAProxy中看到的backend状态。该header为server可见。 X-Haproxy-Server-State: UP 2/3; name=bck/srv2; node=lb1; weight=1/2; scur=13/22; qcur=0 server option check:启用健康检测 inter:健康检测间隔 rise:检测服务可用的连续次数 fall:检测服务不可用的连续次数 error-limit:往server写数据连续失败的次数上限,执行on-error的设定 observe <mode>:把正常服务过程作为健康检测请求,即实时检测 on-error <mode>:满足error-limit后执行的操作(fastinter、fail-check、sudden-death、mark-down)。其中fastinter表示立即按照fastinter的检测延时进行。fail-check表示改次error作为一次检测;sudden-death表示模仿一次fatal,如果紧接着一次fail则置server为down;mark-down表示直接把server置为down状态。 其它 retries:连接失败重试的次数,如果重试该次数后还不能正常服务,则断开连接。
参考文章:https://www.cnblogs.com/skyflask/p/6970154.html https://www.cnblogs.com/kevingrace/p/6138150.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号