pandas数据合并merge
数据合并merge
#参数解释
merge(
self,
right: DataFrame | Series,
how: str = "inner",#连接方式:‘inner’(默认);还有,‘outer’、‘left’、‘right’
on: IndexLabel | None = None,#用于连接的列名,必须同时存在于左右两个DataFrame对象中,如果位指定,则以left和right列名的交集作为连接键
left_on: IndexLabel | None = None,#左侧DataFarme中用作连接键的列
right_on: IndexLabel | None = None,#右侧DataFarme中用作连接键的列
left_index: bool = False,#将左侧的行索引用作其连接键
right_index: bool = False,#将右侧的行索引用作其连接键
sort: bool = False,
suffixes: Suffixes = ("_x", "_y"),#字符串值元组,用于追加到重叠列名的末尾,默认为(‘_x’,‘_y’).例如,左右两个DataFrame对象都有‘data’,则结果中就会出现‘data_x’,‘data_y’
copy: bool = True,
indicator: bool = False,#会在结果中新增加一列来标明合并的结果是左右两边,还是仅在左边或仅在右边。参数为True时,新增列的标签为“_merge”当indicator=字符串时,返回的结果为字符串
validate: str | None = None,
)
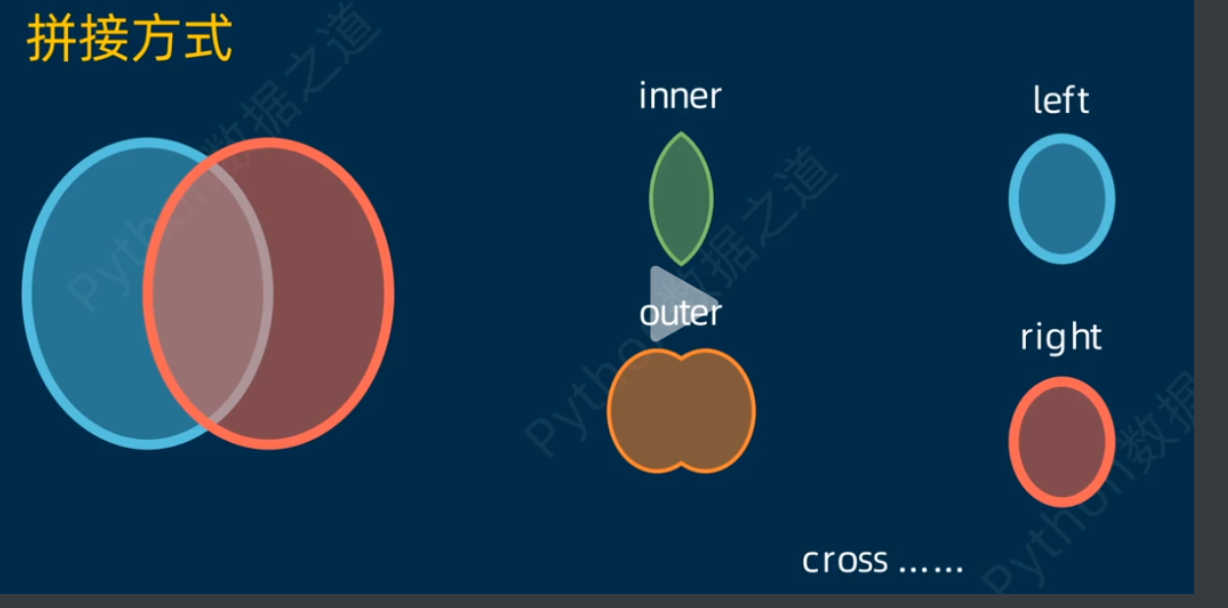
- merge的5种拼接方式inner/left/outer/right/cross
a = {"name":["lemon","jack","peter","Emma","james"],
"city":["长沙","上海","深圳","北京","北京"],
"a":[80,90,60,73,89],
"b":[80,75,80,85,83],
"c":[70,75,80,73,62]}
df1 = pd.DataFrame(data=a,index=["d","e","f","g","h"])
a2 = {"name":["lemon","jack","peter","jacob",],
"city":["长沙","上海","深圳","北京"],
"e":[85,92,70,83],
"f":[83,75,82,87]}
df2 = pd.DataFrame(data=a2,index=["e","f","g","h"])
df1.merge(df2,left_on="name",right_on="name")#2个数据框中的“name”列中有相同元素值得数据行参与拼接,其他数据行不
# 参与拼接,同时在结果中其他列如有相同的列名称,则会以添加后缀的方式进行重命名,同时新的数据框的行索引标签会根据
# 行的数量进行重置
"""
#输出结果:
name city_x a b c city_y e f
0 lemon 长沙 80 80 70 长沙 85 83
1 jack 上海 90 75 75 上海 92 75
2 peter 深圳 60 80 80 深圳 70 82
"""
df1.merge(df2,left_on="name",right_on="name",how="outer")#并集方式呈现
"""
#输出结果
name city_x a b c city_y e f
0 lemon 长沙 80.0 80.0 70.0 长沙 85.0 83.0
1 jack 上海 90.0 75.0 75.0 上海 92.0 75.0
2 peter 深圳 60.0 80.0 80.0 深圳 70.0 82.0
3 Emma 北京 73.0 85.0 73.0 NaN NaN NaN
4 james 北京 89.0 83.0 62.0 NaN NaN NaN
5 jacob NaN NaN NaN NaN 北京 83.0 87.0
"""
df1.merge(df2,left_on="name",right_on="name",how="left")#只保留第一个的
"""
#输出结果
name city_x a b c city_y e f
0 lemon 长沙 80 80 70 长沙 85.0 83.0
1 jack 上海 90 75 75 上海 92.0 75.0
2 peter 深圳 60 80 80 深圳 70.0 82.0
3 Emma 北京 73 85 73 NaN NaN NaN
4 james 北京 89 83 62 NaN NaN NaN
"""
df1.merge(df2,how="cross")#此时不需要设置left_on与right_on,是将左右2个数据框的数据行以乘积的方式分别进行匹配
"""
name_x city_x a b c name_y city_y e f
0 lemon 长沙 80 80 70 lemon 长沙 85 83
1 lemon 长沙 80 80 70 jack 上海 92 75
2 lemon 长沙 80 80 70 peter 深圳 70 82
3 lemon 长沙 80 80 70 jacob 北京 83 87
4 jack 上海 90 75 75 lemon 长沙 85 83
5 jack 上海 90 75 75 jack 上海 92 75
6 jack 上海 90 75 75 peter 深圳 70 82
7 jack 上海 90 75 75 jacob 北京 83 87
8 peter 深圳 60 80 80 lemon 长沙 85 83
9 peter 深圳 60 80 80 jack 上海 92 75
10 peter 深圳 60 80 80 peter 深圳 70 82
11 peter 深圳 60 80 80 jacob 北京 83 87
12 Emma 北京 73 85 73 lemon 长沙 85 83
13 Emma 北京 73 85 73 jack 上海 92 75
14 Emma 北京 73 85 73 peter 深圳 70 82
15 Emma 北京 73 85 73 jacob 北京 83 87
16 james 北京 89 83 62 lemon 长沙 85 83
17 james 北京 89 83 62 jack 上海 92 75
18 james 北京 89 83 62 peter 深圳 70 82
19 james 北京 89 83 62 jacob 北京 83 87
"""
#也可以设置“on”参数
df1.merge(df2,on="name")
"""
name city_x a b c city_y e f
0 lemon 长沙 80 80 70 长沙 85 83
1 jack 上海 90 75 75 上海 92 75
2 peter 深圳 60 80 80 深圳 70 82
"""
#“on”参数也可以是列表
df1.merge(df2,on=["name","city"])#有图可知name与city中的重复值已经完全合并
"""
name city a b c e f
0 lemon 长沙 80 80 70 85 83
1 jack 上海 90 75 75 92 75
2 peter 深圳 60 80 80 70 82
"""
#当结果中有列索引标签重复的数据列时,可以设置参数suffixes来对列索引标签添加后缀
df1.merge(df2,on = "name",suffixes=["_left","_right"])
"""
name city_left a b c city_right e f
0 lemon 长沙 80 80 70 长沙 85 83
1 jack 上海 90 75 75 上海 92 75
2 peter 深圳 60 80 80 深圳 70 82
"""
#如果有列索引标签重复时,可以设置参数suffixes为False,则会报错
df1.merge(df2,on = "name",suffixes=[False,False])
"""
df1.merge(df2,on = "name",suffixes=[False,False])
"""
#indicator参数,会在结果中新增加一列来标明合并的结果是左右两边,还是仅在左边或仅在右边。参数为True时,新增列的标签为“_merge”
df1.merge(df2,on = "name",how="outer",indicator=True)
"""
name city_x a b c city_y e f _merge
0 lemon 长沙 80.0 80.0 70.0 长沙 85.0 83.0 both
1 jack 上海 90.0 75.0 75.0 上海 92.0 75.0 both
2 peter 深圳 60.0 80.0 80.0 深圳 70.0 82.0 both
3 Emma 北京 73.0 85.0 73.0 NaN NaN NaN left_only
4 james 北京 89.0 83.0 62.0 NaN NaN NaN left_only
5 jacob NaN NaN NaN NaN 北京 83.0 87.0 right_only
"""
#当indicator=字符串时,返回的结果为字符串
df1.merge(df2,on = "name",how="outer",indicator="重复的列")
"""
name city_x a b c city_y e f 重复的列
0 lemon 长沙 80.0 80.0 70.0 长沙 85.0 83.0 both
1 jack 上海 90.0 75.0 75.0 上海 92.0 75.0 both
2 peter 深圳 60.0 80.0 80.0 深圳 70.0 82.0 both
3 Emma 北京 73.0 85.0 73.0 NaN NaN NaN left_only
4 james 北京 89.0 83.0 62.0 NaN NaN NaN left_only
5 jacob NaN NaN NaN NaN 北京 83.0 87.0 right_only
"""
#merge还有另外一种形式为pandas.merge,下案例使用pd.merge,将左右两个数据框作为参数在函数中设置得到的结果与dataframe.merge是一样的
pd.merge(df1,df2,on=["name","city"],how="outer")
"""
name city a b c e f
0 lemon 长沙 80.0 80.0 70.0 85.0 83.0
1 jack 上海 90.0 75.0 75.0 92.0 75.0
2 peter 深圳 60.0 80.0 80.0 70.0 82.0
3 Emma 北京 73.0 85.0 73.0 NaN NaN
4 james 北京 89.0 83.0 62.0 NaN NaN
5 jacob 北京 NaN NaN NaN 83.0 87.0
"""
#参数validate可以设置对齐方式,其值可以是“one_to_one”、“one_to_many”、“many_to_one”、“many_to_many”
pd.merge(df1,df2,on="city",how="outer",validate="many_to_one")
"""
name_x city a b c name_y e f
0 lemon 长沙 80 80 70 lemon 85 83
1 jack 上海 90 75 75 jack 92 75
2 peter 深圳 60 80 80 peter 70 82
3 Emma 北京 73 85 73 jacob 83 87
4 james 北京 89 83 62 jacob 83 87
"""
pd.merge(df1,df2,on="city",how="outer")
"""
name_x city a b c name_y e f
0 lemon 长沙 80 80 70 lemon 85 83
1 jack 上海 90 75 75 jack 92 75
2 peter 深圳 60 80 80 peter 70 82
3 Emma 北京 73 85 73 jacob 83 87
4 james 北京 89 83 62 jacob 83 87
"""
#例子data3中"bought_by":[1,1,3]},[1,1,3]为data4中的行索引,将2个数据框连接起来
data3 = {"product":["computer","phone","TV"],"bought_by":[1,1,3]}
df3 = pd.DataFrame(data3,index=["A","B","C"])
data4 = {"name":["lemmon","jack","emma"],"age":[23,20,32]}
df4 = pd.DataFrame(data4,index=[1,2,3])
df3.merge(df4,how="inner",right_index=True,left_on="bought_by")#left_on 右侧DataFarme中用作连接键的列,right_index=True将右侧的行索引用作其连接键
"""
product bought_by name age
A computer 1 lemmon 23
B phone 1 lemmon 23
C TV 3 emma 32
"""
记录学习的点点滴滴

 浙公网安备 33010602011771号
浙公网安备 33010602011771号