pandas 数据访问与数据运算
常见的数据访问
查看数据的信息
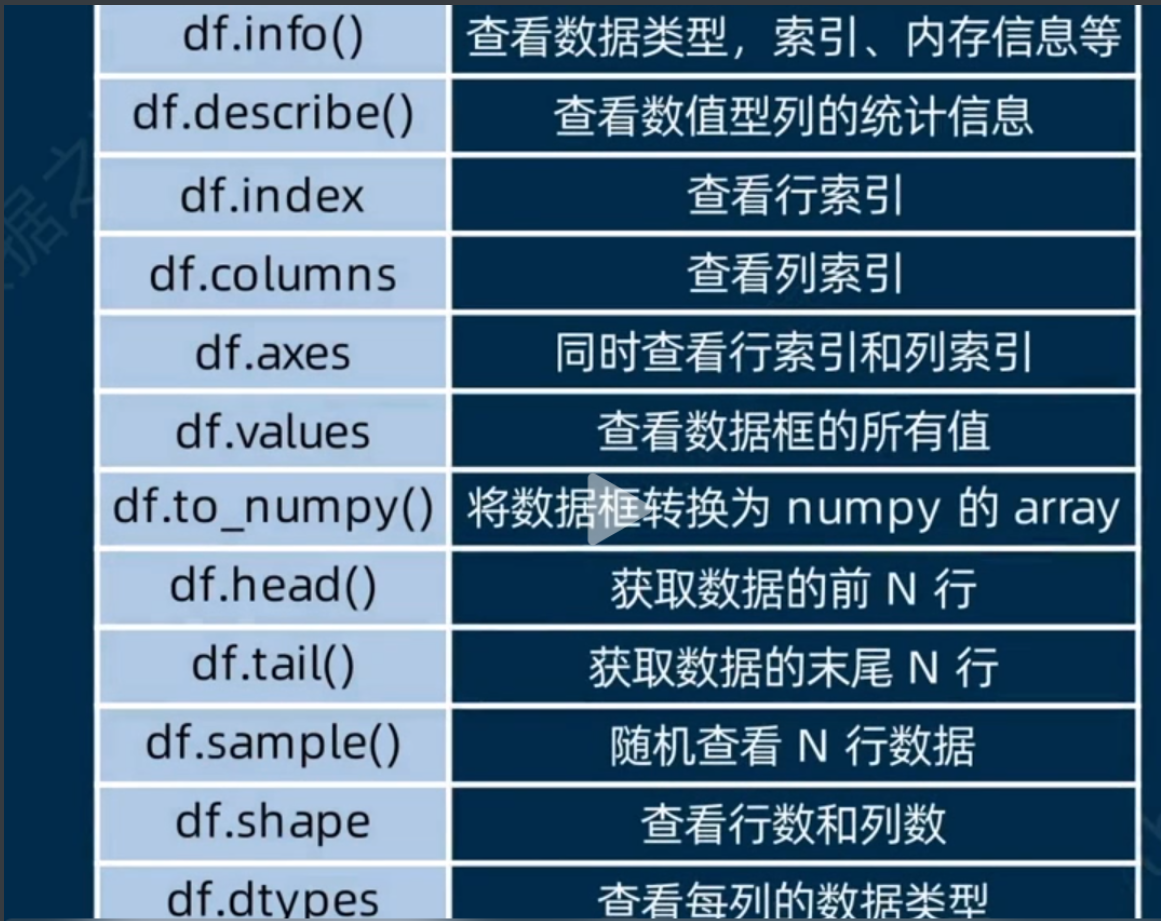
#除此之外,还有数据转置
df.T #实现列表转置
数据运算
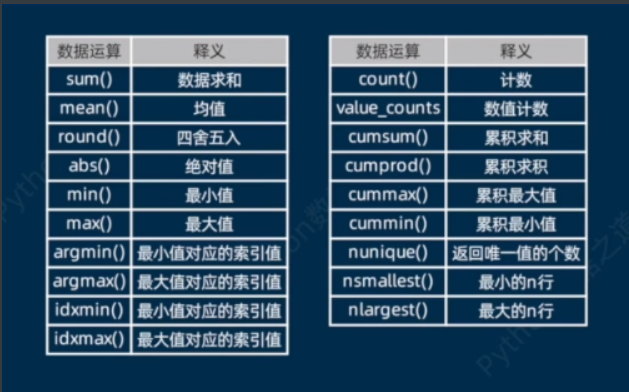
#下列运算默认均按照0轴(纵轴方向),设置axis=1,则按横轴方向,同时支持行或列等Series进行计算
#在pandas中数值None、NAN、NaT被视为NA值
axis = 1/"columns" #沿着横轴方向进行运算
axis = 0/"index" #沿着纵轴方向进行运算
#求和
df.sum()
#对某行和某列求和
df["name"].sum()
df.sum(axis=1)
#对指定列和行进行求和
a = df[["a","c"]].loc[0:].sum(axis=1)
#求乘积
df.prod()
#对某行和某列求积
df["name"].prod()
df.prod(axis=1)
#求平均值
df["a"].mean()#求某列的平均值,只支持数字类型的数据
#保留小数位数
#设置小数点位数,默认所有的数值型保留几位小数
df["b"].round(2)#b列保留2位小数
df.round({"b":2,"c":1})#通过字典指定多列的小数点位数
#获取数据的绝对值
df.abs()
#最大值
df.max()#获取每1行的最大值
df.max(axis=1) #获取每1列的最大值
df.min(axis=1) #获取每1列的最小值
#最小值的位置
#某列最小值做对应的索引的位置
df11["a"].argmin()
#某列最小值做对应的索引的名称
df11["a"].idxmin()
#最大值的位置
#某列最大值做对应的索引的位置
df11["a"].argmin()
#某列最大值做对应的索引的名称
df11["a"].idxmin()
#计数
df11.count()#count函数用来计算每列或每行的非NA数据的个数
#values_count()
df = df.value_counts(normalize=True) #normalize=True,相同行出现次数的百分比
df = df.value_counts(ascending=True) #ascending=True,相同行出现次数升序排列
df = df.value_counts(ascending=False) #ascending=True,相同行出现次数降序排列
df = df.value_counts(dropna=False) #计算结果会包含NA
df = df.value_counts(subset=["name","city"]) #对指定的列进行计数
#累计求和
df.loc[0:1].cumsum(axis=1)#累计求和
#累计求乘积运算
df.cumprod()
#累计最大值
df.cummax(axis=1)#累计最大值
#累计最小值
df.cummin(axis=1)#累计最大值
#获取唯一值的数量,默认不包含NA值
df.nunique()#获取唯一值的数量
#设置参数dropna,结果中包含Na值
df.nunique(dropna=False)
#获取series的唯一值
df["a"].unique()#获取唯一值,不计数,但unique只适用于series
#当出现相同的数据时nsmallest的keep参数,默认取最先出现的几个,当keep=“all”,并列出现的几个,等于last取后几个
#获取最小的几行数据nsmallest、
df["a"].nsmallest(3)#获取最小的3行数据
#或者
df.nsmallest(n = 3,columns="a")
#获取最小的几行数据nsmallest、
df["a"].nlargest(3)#获取最小的3行数据
#或者
df.nlargest(n = 3,columns="a")
记录学习的点点滴滴

 浙公网安备 33010602011771号
浙公网安备 33010602011771号