
论文翻译——2020_ESResNet: Environmental Sound Classification Based on Visual Domain Models
ESResNet:基于视觉域模型的环境声音分类
作者:Andrey Guzhov, Federico Raue, Jörn Hees, Andreas Dengel
摘要:环境声音分类(ESC)是音频领域中一个非常活跃的研究领域,近年来取得了很大的进展。然而,许多现有的方法通过依赖于特定领域的特性和架构来实现高精度,使得从其他领域(例如图像领域)的进步中获益变得更加困难。此外,过去的一些成功归因于结果评估方式的差异(即UrbanSound8K(US8K)数据集的非官方分割),扭曲了该领域的整体进展。
本文的贡献是双重的。首先,我们提出了一个模型,这是固有的单声道和立体声声音输入兼容。我们的模型基于简单对数功率短时傅立叶变换(STFT)谱图,并将其与图像领域的几种著名方法(即ResNet、siames-like网络和注意力)相结合。我们调查了跨域预训练、体系结构更改的影响,并在标准数据集上评估了我们的模型。我们发现,我们的模型在一个公平的比较中优于所有先前已知的方法,实现了97.0%(ESC-10)、91.5%(ESC-50)和84.2%/85.4%(US8K单声道/立体声)的精度。第二,我们通过区分之前在US8K数据集上报告的几个官方或非官方拆分结果,全面概述了该领域的实际状况。为了更好的再现性,我们的代码(包括任何重新实现)是可用的。
1 介绍
随着语音助手的日益普及,其中许多都使用了深度学习技术,目前音频领域最明显的任务可能是自动语音识别。然而,除了这个非常突出的例子之外,音频领域还存在许多其他挑战。其中一个挑战是环境声音分类(ESC),它涉及到如何正确区分我们在日常环境中所经历的声音类别(例如,“婴儿哭声”、“汽车喇叭声”、“儿童玩耍声”、“狗吠声”、“警笛声”、“打鼾声”、“街头音乐”)。电子稳定控制系统有许多潜在的应用领域,其中一个最明显的应用领域是多媒体检索,电子稳定控制系统可以通过更好地利用音频模式来提高视频检索系统的性能[1]。另一个应用领域是城市声音的自动分析,例如为高噪声水平提供更详细的见解[2]。
虽然电子稳定控制系统是一个相对年轻的领域,但在 ESC-50[3]和UrbanSound8K(US8K)[4]等大型数据集在社会上得到广泛接受之后,取得了许多进展。然而,我们观察到ESC社区的总趋势是设计特定于音频域的体系结构,并将它们与专门设计的功能结合起来。一方面,这种方法更难从其他领域的进步中获益,比如计算机视觉领域。另一方面,这个场景激发了我们的兴趣来研究当前最先进的图像域方法在ESC上的性能。在我们的调查中,我们发现,虽然我们的方法在ESC-50数据集上立即优于所有以前的方法,但它最初在US8K上的性能似乎相当差,尽管它实际上可以利用立体声输入。然而,在我们的随访中,我们注意到wrt存在再现性问题。以前的出版物报道了US8K数据集:许多现有的方法缺乏必要的细节来复制和使用的数据集分割。给出一个公平的比较,我们的方法实际上比所有以前的电子稳定控制系统模型也在US8K上。
本文的其余部分组织如下。在第二节中,我们讨论了用于环境声音分类的先前模型。然后,我们在第三节描述了我们基于对数功率STFT谱图和著名CNN模型提出的方法,第四节描述了它是如何训练和评估的,然后在第五节介绍了我们的结果,并在第六节总结了总结和未来的工作。
2 相关工作
与图像相关任务(图像分类、分割、目标检测等)不同,环境声音分类任务意味着使用局部相关的一维信号,因此输入沿单个轴拉伸。环境声音分类领域最广为人知的数据集是ESC-50/-10[3]和UrbanSound8K(US8K)[4],第四节将进一步详细介绍。
音频的表示与视觉信号(如照片)有很大不同,视觉信号在两个空间维度上都具有局部相关性。因此,许多方法被提出专门针对音频领域。我们可以把他们分成以下几大类。所有方法的综合概述和比较见表1。
A 原始波形和一维CNN
使用原始信号作为输入提供了一个简单的解决方案,可以建立一个模型,在内部处理任何类型的时频转换。这类模型最重要的特点是不需要对数据进行预处理。首先,[5]和[6]提出了一种称为EnvNet v1/2的一维体系结构,它当时能够实现最先进的结果。后来,在[7]中,一维CNNs的概念被扩展到一个模型中,该模型在不同的时间尺度上对输入信号进行操作。[8]中提出了另一种改进这类模型性能的方法,其中使用伽玛通滤波器组进行模型初始化可以改善与其他随机权重初始化相比的结果。
相比之下,为了简单和减少可训练参数的数量(考虑到有限的训练数据),我们决定在我们的模型中依赖具有宽频谱范围的固定时频变换。然而,我们在今后的工作中提到这方面的潜在改进。
B 可学习滤波器组和2D-CNN
虽然一维cnn在内部处理输入信号的所有变换,这使得以端到端的方式应用它们成为可能,但是这种方法涉及到对变换表示的缺乏控制。在[8]中使用gammatone初始化有助于部分解决这个问题。[9]的独特之处在于将模型分为两部分,即卷积受限Boltzman机(ConvRBM)用于特征提取(而不是我们工作中使用的固定过程)和[10]中提出的CNN用于实际分类任务。
C 预计算时频表示与2DCNN
为环境声音分类设置基线的第一个模型是[10](PiczakCNN)中提出的CNN,它对Mel标度的[11]频谱图进行操作。使用固定的特征提取程序可以获得具有所需特征的模型输入。单特征输入的进一步发展和数据扩充技术的研究在[12]中完成。后续研究涉及将输入特征扩展到其他主要基于短时傅里叶变换(STFT)[13]到Mel频率倒谱系数(MFCC)[14],[15];交叉递归图(CRP)[16],[15];蒂格能量算子(TEO)[17],[18];(相位编码)滤波器组能量((PE)FBE)[19];伽玛酮光谱图[20]、[21]、[22];色度图[23]、[24];光谱对比度[25]、[24];和托内茨[26]、[24]。
然而,上述所有特性的开发都考虑到了计算复杂性的降低或压缩。随着计算能力的增长,似乎我们现在可以利用一个单一的功能,涵盖整个范围内没有任何减少。我们提出的模型属于这一大类,它也处理单特征输入(对数功率谱图)。
我们在表1中详细描述了上述研究中使用的特征。
D 数据扩充
数据增强是一种强大的技术,它可以增加训练数据的可变性,从而起到防止过度拟合的正则化作用。根据[12]和[6],有以下几种变换来增强音频训练数据:1)时间拉伸:这种方法改变音频的持续时间,同时保持其频谱特性不变。2) 基音偏移:与时间拉伸相反,这种方法允许操纵光谱特性并保持轨迹的持续时间。3) 时间反演:时间反演应用于[6]中,是一种有效的数据增强技术,它与视觉分类数据集训练过程中图像的随机翻转有关。
E UrbanSound8K(US8K)数据集结果的可比性
根据我们的调查结果,至少有5篇论文(2019年有3篇)的报告结果无法与其他论文直接比较。特别是,如[21]所述,[18]的作者使用了US8K数据集的非官方分割。此外,文献[15]的作者指出,结果是通过非标准拆分获得的,而文献[8]的作者则提供了自定义代码片段生成策略的描述。最后,我们确定[24]和[27]发布的结果与US8K数据集的官方分割[4]获得的结果是不可比较的。我们在表一和第V-D节中提供了有关这方面的进一步细节。
3 模型
本文提出了一种结合对数功率谱图的视觉域卷积神经网络来解决环境声分类问题。本节描述了模型的体系结构以及如何通过注意机制对其进行扩展。我们还描述了它在立体声音频中的应用,网络权值的初始化和对数功率谱图的计算过程。
A 残差网络
残差神经网络的特点是额外的跳过连接,绕过一些层并合并它们的输入和输出。这样做的动机是为了防止梯度消失,这使得以前设计深层神经网络非常困难[28]。在我们的工作中,我们提出了基于vanilla ResNet-50体系结构的ESResNet模型,以证明它能够在该模型不适用的领域上实现最先进的结果。模型的总体结构如图1所示。
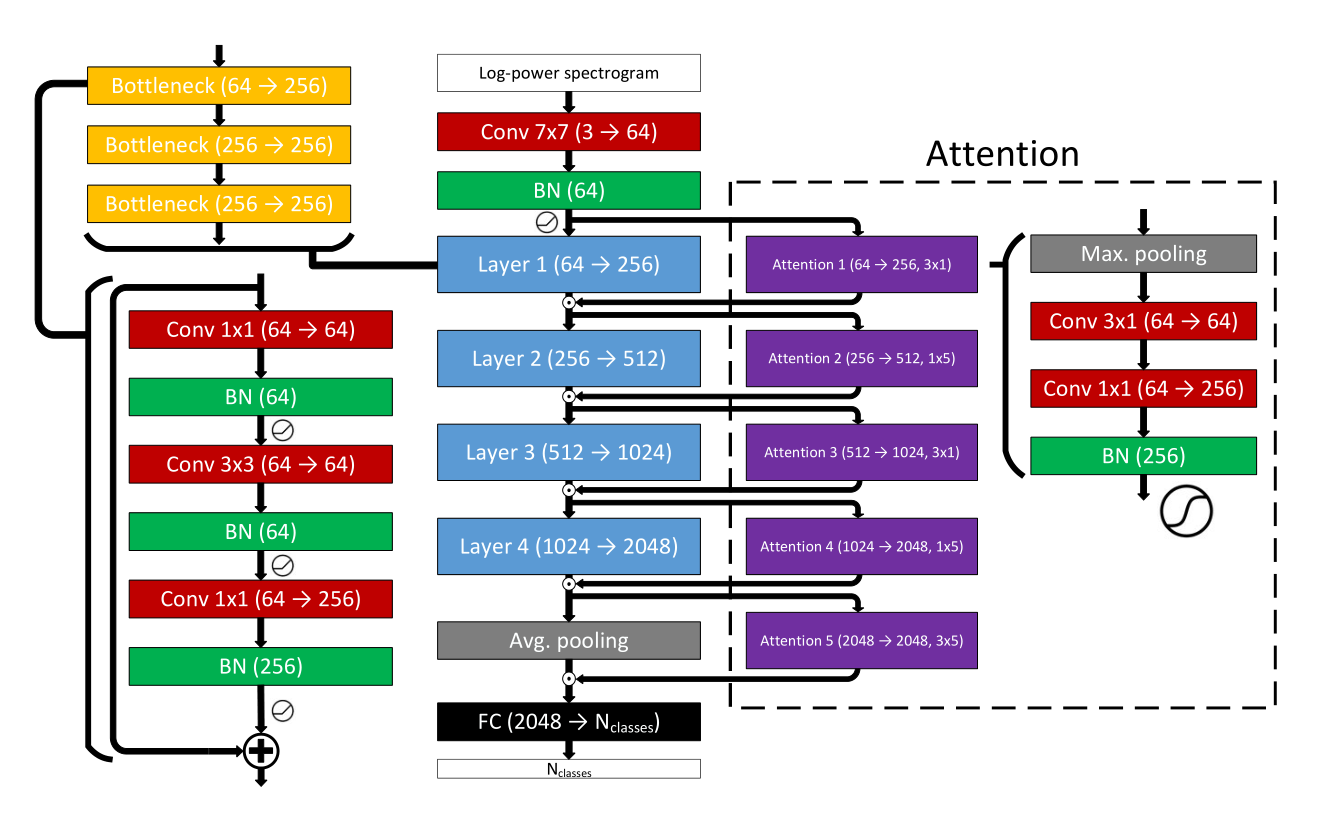
图1:ESResNet模型处理单通道输入的概述。主分支(第2列)由卷积层(红色)和批标准化层(绿色)堆叠在一起,然后是剩余层1–4(蓝色)、平均池(灰色)和完全连接层(黑色)。左边是残余层的典型结构。每个剩余层由瓶颈层(橙色)的堆栈组成,瓶颈层包括按顺序应用的Conv-BN操作和跳过连接。整流线性单元(ReLU)作为激活函数。右侧(以虚线为界)显示了ESResNet模型通过注意块的可选扩展。如果应用,则注意块(紫色)平行于剩余层1到4或平均汇集层堆叠。注意块包括最大池操作(灰色),然后是深度方向的可分离卷积,并与批标准化叠加在一起。注意块的输出由logistic函数给出。
B 注意力机制
注意机制最初是为了与循环模型结合使用而提出的,特别是在序列建模任务中[29]。它的主要目的是突出一个长序列中的相关部分,去掉不相关的部分。在视觉领域,人们使用注意块来对输入信号进行加权。通常,有几个注意子分支由一个或多个卷积层组成,与主分支并行处理特征映射。
对于环境声音分类任务,注意块的主要目的是将模型集中在时域和频域的最重要信息上。为了实现注意机制,我们扩展了ESResNet模型(受[22]的启发),并行添加了一堆注意块(ESResNet attention,图1)。前4个块中的每个块处理与频率或时间相关的信息。例如,第一注意块A1接收与第一层L1相同的输入,然后使用频率专用卷积滤波器处理信号x,并提供与L1提供的输出相同形状的输出。最后,第二层的输入通过L1和A1块的输出的按元素相乘来构造(等式1)。

最后一个注意块处理联合时频表示。注意块的核心是深度方向的可分离卷积[30]。每个注意块的输出由logistic函数给出。
C 频谱图
频谱图是频率随时间变化的频谱的图像表示。关于数字信号处理,有几种方法可以获得频谱图。在我们的工作中,我们从音频信号X(τ,ω)的STFT计算对数功率谱(方程2)。
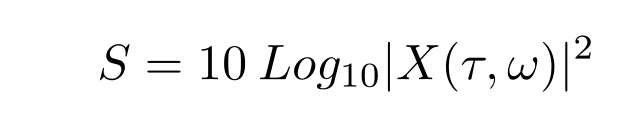
1) 短时傅里叶变换(STFT):STFT属于傅里叶相关变换家族,用于确定时域信号x中不同时间点τ处的基正弦频率ω的幅度和相位。

在实践中,为了计算等式3,将输入信号分割成与窗函数w相乘的重叠帧,然后对每个帧分别应用快速傅里叶变换(FFT)[31]。
2) 窗函数:为了减少由成帧引起的频谱扰动,采用窗函数。加窗的使用减少了频谱中的噪声量,因此提高了信噪比。使用窗函数的缺点是所谓的频谱泄漏。频谱泄漏是傅里叶变换在非基本频率下产生的非零值的通称。窗口函数的选择是许多特性之间的权衡。在我们的工作中,我们决定选择最小的4项Blackman-Harris窗[32],这是由等式4给出的,因为它提供了合理的带宽和非常低的频谱泄漏,这使得它成为通用窗[33]的良好选择:
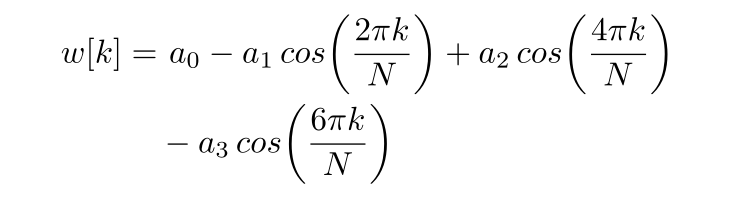
a0= 0.35875;a1= 0.48829;a2= 0.14128;a3= 0.01168
作为时间和频率分辨率之间的权衡,我们将输入信号分割成37.5ms长的帧。后续帧之间的对应重叠取决于所选的窗口函数。在我们的例子中,使用了Blackman-Harris窗口的建议重叠66.1%(24.8 ms)[33]。
D 输入通道变换
对于像我们这样的图像分类模型,通常表示输入数据的方法是具有3个输入通道(红色、绿色和蓝色)的RGB模型。然而,我们的光谱图只提供单一通道形式的输入(灰度值)。解决这个问题的一种方法是将光谱图复制到其他通道,或者改为传递零。这种解决方案的主要缺点是不必要的冗余或信息丢失,并增加了计算成本。为了克服这一限制,我们决定将频谱图沿着其频率轴映射到三个输入通道上,因此将其分为三个频带(图2):低(0.00−7.35kHz)、中(7.35−14.70kHz)和高(14.7−22.05 kHz)。
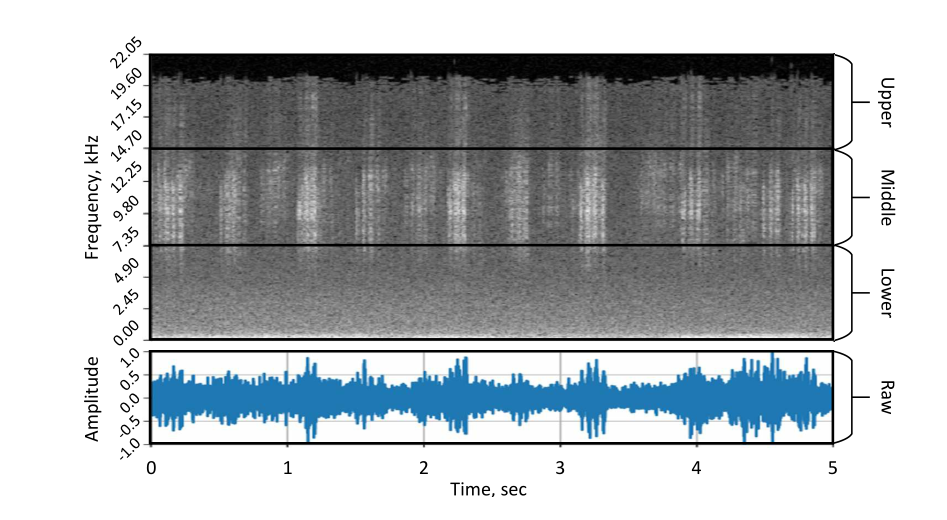
图2:ESResNet模型的输入示例。原始音频(底部)用于创建对数功率谱图,该谱图分为三个频段:低、中、高。因此,网络的输入由三个与视觉通道对齐的通道组成(分别为红色、绿色和蓝色)。
E 使用孪生结构处理立体声音
人类感知听觉信息的方式本质上是立体的。在这项工作中,我们利用额外的音频通道带来的优势,并在US8K数据集上显示,一个小的架构调整有助于我们执行最先进的成果。
孪生神经网络的发展是为了产生两个输入样本的相似性度量[34]。然而,在这项工作中,我们使用通用的广义符号来调用任何网络连体,它将相同的一组权重应用于两个不同的输入,从而产生两个可比较的向量(或嵌入)。如图3所示,我们采用双通道音频输入,然后进行对数功率谱图计算(通过STFT),并将每个通道分别通过各层。在我们获得网络的输出之后,我们通过一个元素的加法来融合它们,并通过最后一个完全连接的层来进行最终的分类。
F ImageNet训练作为权重初始化器
ESC数据集包含有限数量的样本。这种设置在ESC-50数据集的情况下变得尤为重要,因为它提供了一项具有挑战性的任务,即仅使用1600个训练样本来区分50个类[3]。为了充分利用深度神经网络的能力,数据量应该随着参数的数量呈指数增长。如果训练样本的数量受到限制,一种方法是执行微调。在这项工作中,我们决定采用一个在ImageNet数据集上从头开始训练的模型[35]。ImageNet数据集提供了100多万个训练样本,分为1000个类。我们将在第五节中看到,基于ImageNet图像分类任务预训练的权重初始化有利于环境声音分类。

图3:处理双通道输入的ESResNet模型概述。省略了可选的注意块。配色方案与图1相同。第一个通道通过主分支(饱和着色),因此获得大小为2048的结果嵌入。然后,第二信道通过相同的权重集(浅颜色),导致大小2048的另一嵌入。最后,两个嵌入按元素添加,它们的总和通过最后一个完全连接的层传递,该层对输入样本所属的类执行最终预测。
4 实验装置
在本节中,我们将从数据集、预处理以及如何训练模型开始,描述我们的实验设置。我们还描述了我们对先前结果的再现/对其方法的重新实现,以供比较。
A 数据集
1) ESC-50/-10:ESC-50数据集由2000个单音样本组成,这些样本分为50个类别,可分为5组,如动物音、自然音和水声、非言语人声、室内声和室外声[3]。样本平均分布在不同的类中,因此每个类由40个记录组成。每个音轨的长度为5秒,本机采样率为44.1千赫。数据集被作者分成5个部分,我们在当前的工作中使用它们来执行我们的评估。ESC-10数据集是ESC-50数据集的子集。它仅由10类组成,仅限于以下类别:具有时间模式的瞬态/撞击声、具有强谐波内容的声音和噪声/声景。ESC-10数据集的所有其他特征与ESC-50数据集的特征相同。
2) UrbanSound8K:US8K数据集包含8732个样本(单声道和立体声),分为10类:“空调”、“汽车喇叭”、“儿童玩耍”、“狗吠”、“钻孔”、“发动机空转”、“枪声”、“手提钻”、“警笛”和“街头音乐”[4]。在每节课的总录音长度方面,各节课并不均衡。每个音轨长度可变,最长为4秒,本机采样率从16 kHz到48 kHz不等。数据集被作者分成10个部分,我们在当前的工作中使用它们来执行我们的评估。
我们想通过描述[4]作者获取训练样本的方式,明确强调使用官方提供的褶皱的重要性。在收集时,Freesound项目[36]提供的定性标记录音的数量受到限制[4],每首曲目被分成重叠50%的片段[4]。让我们考虑属于同一类的两条磁道A和B(图4)。应用一个滑动窗口并以50%的重叠度移动它,我们分别得到了称为A1–4和B1–4的片段。随后的两个片段共享了原始轨迹的一部分,因此必须确保它们出现在训练集或评估集(官方分割)中,而不是同时出现在这两个集中(随机洗牌是许多非官方分割的基础)。
3) 数据预处理:对于所有数据集,使用librosa0.7.2库将音频样本标准化为44.1khz的采样率[37]。根据选择的窗长37.5ms,帧长为1654个样本。由于底层实现包括FFT,因此使用反射填充策略将帧显式填充到下一次幂2(211=2048)[31]。
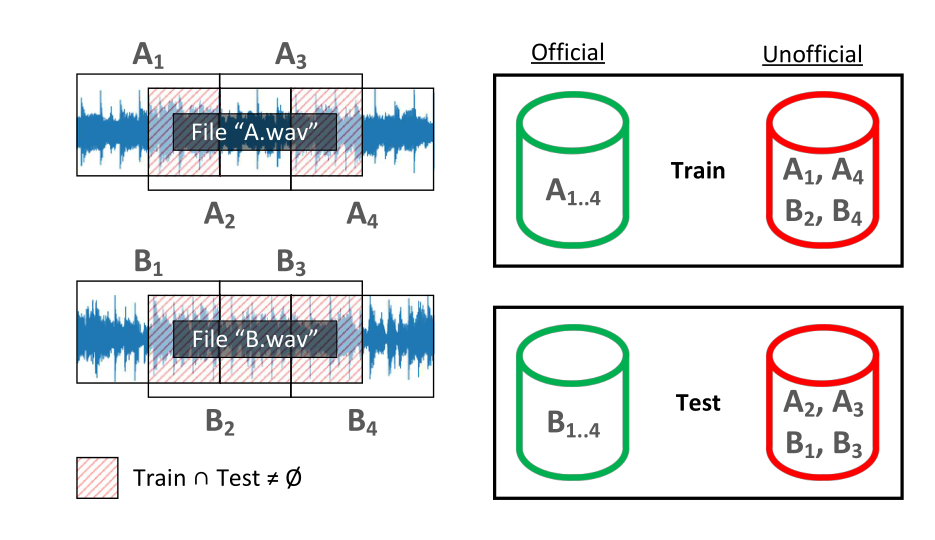
图4:UrbanSound8K数据集的生成和拆分。该数据集由使用滑动窗口获得的样本组成,滑动窗口与Freesound项目提供的原始记录重叠50%[36]。数据集的官方分割负责将后续样本放入火车或测试集中,因此两者中都没有原始轨道的共享部分。随机拆分(非官方拆分中经常出现)不遵循此约束,这会导致列车和测试数据(突出显示区域)混淆,从而导致模型性能不合理的高。
B 模型训练
使用Adam[38]优化器对模型进行了300个时期的训练。将批大小设置为16,在每个历元之后在批之间洗牌训练样本。在训练过程中,根据指数衰减时间表和热身调整学习率[39]。基本学习率值设置为0.00025。前5个时期的学习率是前10个时期的10倍,之后10个时期的学习率呈线性增长。在热身期之后,它以指数形式衰减,γ=0.985,因此训练结束时的学习率为3.37e−6。为了在训练过程中引入更多的稳定性,采用了α=0.0005[40]的权重衰减。其他超参数[38],如β1、β2、?已设置为其默认值。分类交叉熵作为损失函数。
在训练阶段,应用了以下增强(见第II-D节):随机时间反演和时间标度[6]。后者可以看作是时间拉伸和音高偏移的结合。这种组合变换的主要优点是计算量小。例如,基音偏移意味着正向和反向STFT,这使得在训练过程中动态应用这种变换的效率很低。时间反演的概率设为0.5。比例因子从连续范围[1.25-1,1.25]中均匀取样。
C 重复实现
由于[27]特别是[24]报告的结果非常高,我们将重点放在它们上,以找到实现如此高性能的关键。由于模型和/或设置的描述不允许我们确定关键组件,我们决定重现它们的结果。可悲的是,[24]的作者没有公布他们的代码,他们中的任何人也没有在一个月内回复我们的电子邮件。因此,我们重新实现了名为LMCNet的TSCNN-DS模型的一部分,并使用作者提供的所有可用实现细节,在US8K数据集的官方[4]和非官方随机分割上对其进行了评估。[27]的作者已经发布了部分源代码,包括他们的TFNet模型的超参数(只有ESC-50),这允许我们通过少量的重新实现(通过扩展到US8K)来重现他们的结果。遗憾的是,通过电子邮件与他们联系后,原来的存储库消失了。对于我们对US8K数据集的非官方随机分割的评估,我们使用了scikit learn提供的分层折叠[41]。将分裂次数设为10次,所有实验均用相同的随机种子进行。我们在表一(斜体字强调)中报告了复制的结果,并在第5-D节中讨论了它们。
5 结果
如表一所示,我们提出的方法在公平比较中优于所有以前的方法。
A ImageNet 权重与随机权重
正如我们在第4-A节中所讨论的,可用训练样本的数量对于深度学习模型起着至关重要的作用。在这项工作中,我们比较了一个从零开始训练的模型和一个 在ImageNet数据集上预先训练,然后进行微调。在ESC-50数据集上可以观察到最大的相对变化(从81.15%到90.80%,ESResNet),因为它与有限数量的训练样本一起提出了一个具有挑战性的问题。我们仍然发现ESC-10(从92.50%到96.75%,ESResNet)和US8K数据集(从79.91%到83.59%,ESResNet)有很大的改进。
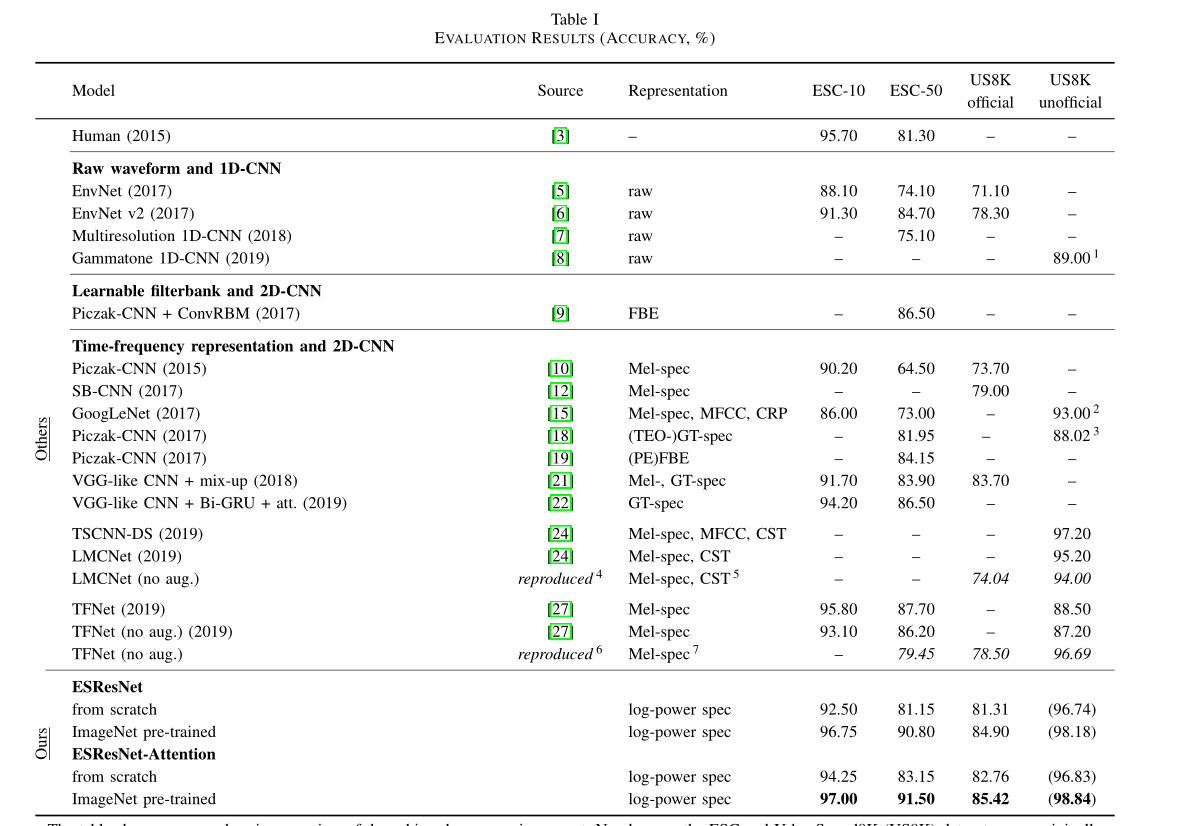
上表显示了以百分比表示的已实现精度的全面概述。ESC和UrbanSound8K(US8K)数据集上的数字与源中最初报告的数字相同。如果没有特别说明,我们将根据我们的调查结果分为US8K官方或非官方栏目。缩写:FBE:滤波器组能量[9];spec:频谱图;MFCC:Mel频率倒谱系数[25];CRP:交叉递推图[16];TEO:蒂格能量算符[17];GT:伽玛酮[20];(PE)FBE:(相位编码)滤波器组能量[19];CST:色度图、光谱对比度和吨数[24]。
注释:1.“音频文件被分割成16000个样本,连续帧有50%的重叠。10%的数据集用作验证集,10%的数据集也用作测试集。使用80%的数据集“[8]”对每个网络进行训练;2.“我们使用了5倍交叉验证”[15];3.由[21]确定;4.完全重新实现(基于[24]中的描述);5.根据[24]计算;6.部分重新实现(基于[27]中的临时可用代码(不完整));7.使用[27]中的代码。
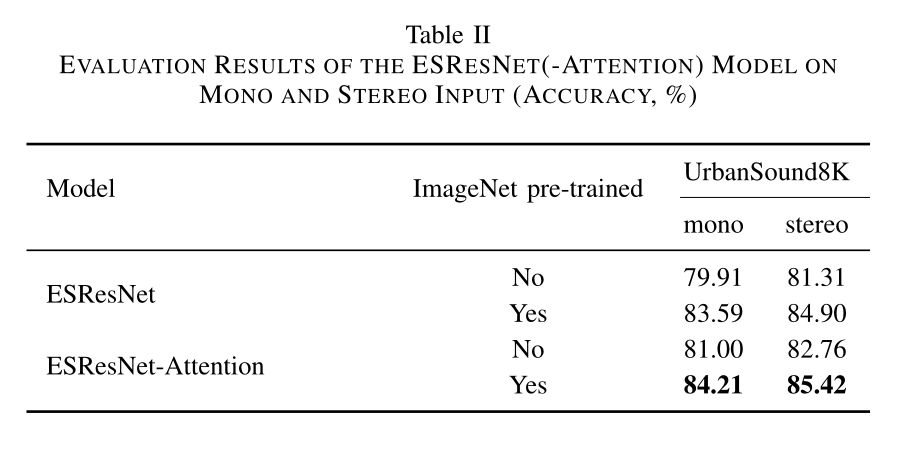
B 立体声与单声道
此外,尽管US8K提供立体声录音,我们发现,以前的竞争机型只考虑单声道音频。如上所述,我们对ResNet-50网络的普通输入处理使用了一个类似连体体的扩展,以便使我们的ESResNet架构能够在可能的情况下处理多通道输入(表I中的US8K)。此外,表2给出了我们的模型在单声道和立体声输入上实现的结果的比较。结果表明,通道间的差异提供了有用的信息,即使不使用额外的注意块,也可以在US8K数据集上比以前的最新结果更好地执行。例如,在US8K数据集上,使用单声道音频作为输入,从零开始训练的ESResNet模型能够达到79.91%的准确率,然而,使用立体声输入可以对81.31%的测试样本进行正确分类,而注意力块扩展(ESResNet attention)在仅使用单声道输入时提供较小的性能增益(81.00%)。类似的情况可以在我们的ESResNet模型中观察到,该模型是在ImageNet数据集上预先训练的[35]。ESResNet模型中立体声输入的使用率(84.90%)高于单声道输入的香草模型(83.59%)和单声道输入的注意力增强模型(84.21%)。
C 注意力机制
结合一个强大的可视化模型和描述性时频表示(ESResNet)已经允许我们比以前的结果更好。但是,通过包含注意,可以进一步改进(ESResNet attention,图1)。注意块的使用使我们能够在所有三个数据集(ESC-50/-10和US8K)上执行先前的最新结果,分别达到91.50%、97.00%和84.21%。此外,立体声输入和注意力块的结合进一步提高了US8K的精确度,使ESResNet注意力模型达到了85.42%的最高精确度。
D 官方和非官方的分裂和再现性问题
如第4-C节所述,我们复制了[24]和[27]中提出的方法。重新实现的LMCNet模型在US8K上所取得的性能(表一)允许我们将[24]的结果归因于那些没有对官方分割进行评估的结果。对于TFNet,我们为ESC-50数据集重新运行了临时可用的代码(没有数据扩充)。然后,我们稍微修改了代码,使其也能在US8K上运行。在这两种情况下,我们意外地获得了比作者所说的要低得多的精确度[27]。然而,当在完全随机的非官方US8K分裂上运行他们的代码时,我们获得了比之前报道的更高的结果。我们由此得出结论,要么共享代码缺乏报告结果可再现性的关键步骤,要么作者既没有在官方或完全随机的非官方US8K分裂上进行实验。为了粗略地量化非官方(随机)拆分策略对我们结果的影响,我们还将其列在表一中。为了指出,这些非常高的数字不构成公平比较的基础,我们将它们放在括号中。
6 结论
在这项工作中,我们展示了如何一个著名的视觉领域模型可以成功地应用于环境声音分类。与常规对数功率谱图结合使用,我们的ESResNet模型能够实现与人类的竞争(ESC-50),而ImageNet数据集的预训练已经允许我们超越所有当前最先进的方法。我们还表明,在输入信号中存在多个通道可以在UrbanSound8K数据集上获得额外的性能增益,而只需进行较小的架构更改(类似暹罗的处理)。借助于支持网络的注意块,在时域和频域(ESResNet attention)中将注意力集中在其输入的相关部分,进一步的改进是可能的。在ESC-50和UrbanSound8K数据集的公平比较中,这样的配置达到了最高的精度,并显著优于所有以前的最先进模型。
最后,我们强调了严格遵守评估程序的重要性,论证了随机分割策略对UrbanSound8K数据集评估结果的影响,并将先前报告的结果区分为官方和非官方分割。为了再现性,我们提供了所有的代码,还包括我们的模型的重新实现,不幸的是,以前没有代码发布。
在未来,我们将研究学习时频表示,而不是使用目前固定的特征提取。另外,正如我们已经看到ImageNet有助于我们的模型的初始化,我们想调查哪些类从域传输中获益更多,哪些受益更少。
鸣谢
这项工作得到了TU Kaiserslautern CS博士奖学金项目、BMBF DeFuseNN项目(赠款01IW17002)和NVIDIA AI实验室(NV AIL)项目的支持。此外,我们感谢DFKI深度学习能力中心的所有成员的意见和支持。
参考文献
[1] Q. Jin and J. Liang, “Video description generation using audio and visual cues,” in Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, ser. ICMR 16. New Y ork, NY ,USA: Association for Computing Machinery, 2016, p. 239242. [Online].Available: https://doi.org/10.1145/2911996.2912043
[2] M. Raimbault and D. Dubois, “Urban soundscapes: Experiences and knowledge,” Cities, vol. 22, no. 5, pp. 339–350, 2005.
[3] K. J. Piczak, “Esc: Dataset for environmental sound classification,” in Proceedings of the 23rd ACM International Conference on Multimedia, ser. MM 15. New Y ork, NY , USA: Association for Computing Machinery, 2015, p. 10151018. [Online]. Available: https://doi.org/10.1145/2733373.2806390
[4] J. Salamon, C. Jacoby, and J. P . Bello, “A dataset and taxonomy for urban sound research,” in Proceedings of the 22nd ACM International Conference on Multimedia, ser. MM 14. New Y ork, NY , USA: Association for Computing Machinery, 2014, p. 10411044. [Online]. Available: https://doi.org/10.1145/2647868.2655045
[5] Y . Tokozume and T. Harada, “Learning environmental sounds with end-to-end convolutional neural network,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), March 2017, pp. 2721–2725.
[6] Y . Tokozume, Y . Ushiku, and T. Harada, “Learning from between-class examples for deep sound recognition,”2017[Online].Available: https://arxiv.org/abs/1711.10282.
[7] B. Zhu, K. Xu, D. Wang, L. Zhang, B. Li, and Y . Peng, “Environmental sound classification based on multi-temporal resolution convolutional neural network combining with multi-level features,” in Pacific Rim Conference on Multimedia. Springer, 2018, pp. 528–537.[8] S. Abdoli, P . Cardinal, and A. L. Koerich, “End-to-end environmental sound classification using a 1d convolutional neural network,” Expert Systems with Applications, vol. 136, pp. 252–263, 2019.
[9] H. B. Sailor, D. M. Agrawal, and H. A. Patil, “Unsupervised filterbank learning using convolutional restricted boltzmann machine for environmental sound classification.” in INTERSPEECH, 2017, pp. 3107–3111.
[10] K. J. Piczak, “Environmental sound classification with convolutional neural networks,” in 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Sep. 2015, pp. 1–6.
[11] J. V olkmann, S. S. Stevens, and E. B. Newman, “A scale for the measurement of the psychological magnitude pitch,” The Journal of the Acoustical Society of America, vol. 8, no. 3, pp. 208–208, 1937. [Online]. Available: https://doi.org/10.1121/1.1901990
[12] J. Salamon and J. P . Bello, “Deep convolutional neural networks and data augmentation for environmental sound classification,” IEEE Signal Processing Letters, vol. 24, no. 3, pp. 279–283, 2017.
[13] J. Allen, “Short term spectral analysis, synthesis, and modification by discrete fourier transform,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 25, no. 3, pp. 235–238, June 1977.
[14] B. Logan et al., “Mel frequency cepstral coefficients for music modeling.” in Proceeding of the International Symposium on Music Information Retrieval (ISMIR), Plymouth, USA, October 2000.
[15] V . Boddapati, A. Petef, J. Rasmusson, and L. Lundberg, “Classifying environmental sounds using image recognition networks,” Procedia computer science, vol. 112, pp. 2048–2056, 2017.
[16] N. Marwan, N. Wessel, U. Meyerfeldt, A. Schirdewan, and J. Kurths, “Recurrence-plot-based measures of complexity and their application to heart-rate-variability data,” Physical review E, vol. 66, no. 2, p. 026702,2002.
[17] J. F. Kaiser, “Some useful properties of teager’s energy operators,” in 1993 IEEE International Conference on Acoustics, Speech, and Signal Processing, vol. 3, 1993, pp. 149–152 vol.3.
[18] D. M. Agrawal, H. B. Sailor, M. H. Soni, and H. A. Patil, “Novel teo-based gammatone features for environmental sound classification,” in 2017 25th European Signal Processing Conference (EUSIPCO). IEEE, 2017, pp. 1809–1813.
[19] R. N. Tak, D. M. Agrawal, and H. A. Patil, “Novel phase encoded mel filterbank energies for environmental sound classification,” in International Conference on Pattern Recognition and Machine Intelligence. Springer,2017, pp. 317–325.
[20] M. Slaney et al., “An efficient implementation of the patterson-holdsworth auditory filter bank,” Apple Computer , Perception Group, Tech. Rep, vol. 35, no. 8, 1993.
[21] Z. Zhang, S. Xu, S. Cao, and S. Zhang, “Deep convolutional neural network with mixup for environmental sound classification,” in Chinese Conference on Pattern Recognition and Computer Vision (PRCV). Springer, 2018, pp. 356–367.
[22] Z. Zhang, S. Xu, S. Zhang, T. Qiao, and S. Cao, “Learning attentive representations for environmental sound classification,” IEEE Access, vol. 7, pp. 130 327–130 339, 2019.
[23] R. N. Shepard, “Circularity in judgments of relative pitch,” The Journal of the Acoustical Society of America, vol. 36, no. 12, pp. 2346–2353, 1964. [Online]. Available: https://doi.org/10.1121/1.1919362
[24] Y . Su, K. Zhang, J. Wang, and K. Madani, “Environment sound classification using a two-stream cnn based on decision-level fusion,” Sensors, vol. 19, no. 7, p. 1733, Apr 2019. [Online]. Available: http://dx.doi.org/10.3390/s19071733
[25] D.-N. Jiang, L. Lu, H.-J. Zhang, J.-H. Tao, and L.-H. Cai, “Music type classification by spectral contrast feature,” in Proceedings. IEEE International Conference on Multimedia and Expo, vol. 1. IEEE, 2002, pp. 113–116.
[26] C. Harte, M. Sandler, and M. Gasser, “Detecting harmonic change in musical audio,” in Proceedings of the 1st ACM workshop on Audio and music computing multimedia, 2006, pp. 21–26.
[27] H. Wang, Y . Zou, D. Chong, and W. Wang, “Learning discriminative and robust time-frequency representations for environmental sound classification,” arXiv preprint arXiv:1912.06808, 2019. [Online]. Available: https://arxiv.org/abs/1912.06808
[28] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
[29] A. V aswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in neural information processing systems, 2017, pp. 5998–6008.
[30] F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1251–1258.
[31] J. W. Cooley and J. W. Tukey, “An algorithm for the machine calculation of complex fourier series,” Mathematics of computation, vol. 19, no. 90, pp. 297–301, 1965.
[32] F. J. Harris, “On the use of windows for harmonic analysis with the discrete fourier transform,” Proceedings of the IEEE, vol. 66, no. 1, pp.51–83, 1978.
[33] G. Heinzel, A. Rüdiger, and R. Schilling, “Spectrum and spectral density estimation by the discrete fourier transform (dft), including a comprehensive list of window functions and some new flat-top windows,” Max-Planck-Institut fr Gravitationsphysik, Tech. Rep., 2002.
[34] G. Koch, R. Zemel, and R. Salakhutdinov, “Siamese neural networks for one-shot image recognition,” in ICML deep learning workshop, vol. 2. Lille, 2015.
[35] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A Large-Scale Hierarchical Image Database,” in CVPR09, 2009.
[36] F. Font, G. Roma, and X. Serra, “Freesound technical demo,” in ACM International Conference on Multimedia (MM’13), ACM. Barcelona, Spain: ACM, 21/10/2013 2013, pp. 411–412.
[37] B. McFee, V . Lostanlen, M. McVicar, A. Metsai, S. Balke, C. Thome,C. Raffel, A. Malek, D. Lee, F. Zalkow, K. Lee, O. Nieto, J. Mason, D. Ellis, R. Yamamoto, S. Seyfarth, E. Battenberg, V . Morozov,R. Bittner, K. Choi, J. Moore, Z. Wei, S. Hidaka, nullmightybofo,P . Friesch, F.-R. Stoter, D. Herenu, T. Kim, M. V ollrath, and A. Weiss, “librosa/librosa: 0.7.2,” Jan. 2020. [Online]. Available: https://doi.org/10.5281/zenodo.3606573
[38] D. P . Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014. [Online]. Available: https://arxiv.org/abs/1412.6980
[39] P . Goyal, P . Dollár, R. Girshick, P . Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y . Jia, and K. He, “Accurate, large minibatch sgd: Training imagenet in 1 hour,” arXiv preprint arXiv:1706.02677, 2017. [Online]. Available: https://arxiv.org/abs/1706.02677
[40] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems, 2012, pp. 1097–1105.
[41] F. Pedregosa, G. V aroquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P . Prettenhofer, R. Weiss, V . Dubourg, J. V anderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号