并发编程-多线程,GIL锁
本章内容:
1.什么是GIL
2.GIL带来的问题
3.为什么需要GIL
4.关于GIL的性能讨论
5.自定义的线程互斥锁与GIL的区别
6.线程池与进程池
7.同步异步,阻塞非阻塞
一.什么是GIL
官方解释:
'''
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
'''
释义:
在CPython中,这个全局解释器锁,也称为GIL,是一个互斥锁,防止多个线程在同一时间执行Python字节码,这个锁是非常重要的,因为CPython的内存管理非线程安全的,很多其他的特性依赖于GIL,所以即使它影响了程序效率也无法将其直接去除
总结:
在CPython中,GIL会把线程的并行变成串行,导致效率降低
需要知道的是,解释器并不只有CPython,还有PyPy,JPython等等。GIL也仅存在与CPython中,这并不是Python这门语言的问题,而是CPython解释器的问题!
二.GIL带来的问题
首先必须明确执行一个py文件,分为三个步骤
- 从硬盘加载Python解释器到内存
- 从硬盘加载py文件到内存
- 解释器解析py文件内容,交给CPU执行
其次需要明确的是每当执行一个py文件,就会立即启动一个python解释器,
当执行test.py时其内存结构如下:
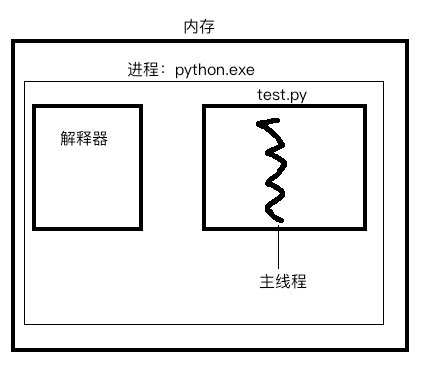
GIL,叫做全局解释器锁,加到了解释器上,并且是一把互斥锁,那么这把锁对应用程序到底有什么影响?
这就需要知道解释器的作用,以及解释器与应用程序代码之间的关系
py文件中的内容本质都是字符串,只有在被解释器解释时,才具备语法意义,解释器会将py代码翻译为当前系统支持的指令交给系统执行。
当进程中仅存在一条线程时,GIL锁的存在没有不会有任何影响,但是如果进程中有多个线程时,GIL锁就开始发挥作用了。如下图:
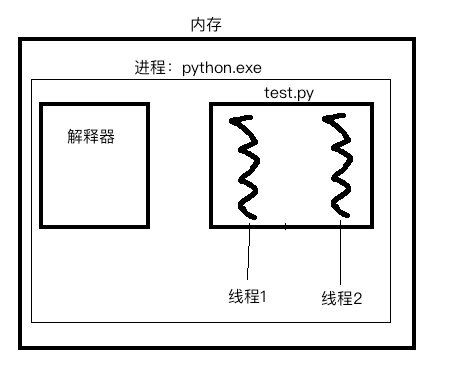
开启子线程时,给子线程指定了一个target表示该子线程要处理的任务即要执行的代码。代码要执行则必须交由解释器,即多个线程之间就需要共享解释器,为了避免共享带来的数据竞争问题,于是就给解释器加上了互斥锁!
由于互斥锁的特性,程序串行,保证数据安全,降低执行效率,GIL将使得程序整体效率降低!
三.为什么需要GIL
GIL与GC的孽缘
在使用Python中进行编程时,程序员无需参与内存的管理工作,这是因为Python有自带的内存管理机制,简称GC。那么GC与GIL有什么关联?
要搞清楚这个问题,需先了解GC的工作原理,Python中内存管理使用的是引用计数,每个数会被加上一个整型的计数器,表示这个数据被引用的次数,当这个整数变为0时则表示该数据已经没有人使用,成了垃圾数据。
当内存占用达到某个阈值时,GC会将其他线程挂起,然后执行垃圾清理操作,垃圾清理也是一串代码,也就需要一条线程来执行。
示例代码:
from threading import Thread
def task():
a = 10
print(a)
# 开启三个子线程执行task函数
Thread(target=task).start()
Thread(target=task).start()
Thread(target=task).start()
上述代码内存结构如下:
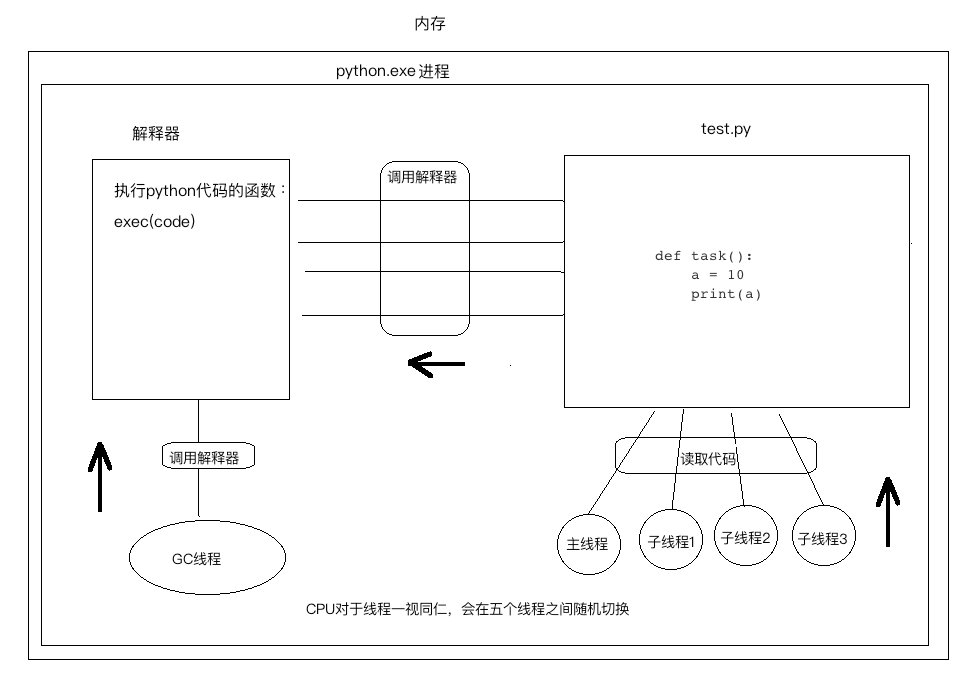
通过上图可以看出,GC与其他线程都在竞争解释器的执行权,而CPU何时切换,以及切换到哪个线程都是无法预支的,这样一来就造成了竞争问题,假设线程1正在定义变量a=10,而定义变量第一步会先到到内存中申请空间把10存进去,第二步将10的内存地址与变量名a进行绑定,如果在执行完第一步后,CPU切换到了GC线程,GC线程发现10的地址引用计数为0则将其当成垃圾进行了清理,等CPU再次切换到线程1时,刚刚保存的数据10已经被清理掉了,导致无法正常定义变量。
当然其他一些涉及到内存的操作同样可能产生问题问题,为了避免GC与其他线程竞争解释器带来的问题,CPython简单粗暴的给解释器加了互斥锁,如下图所示:
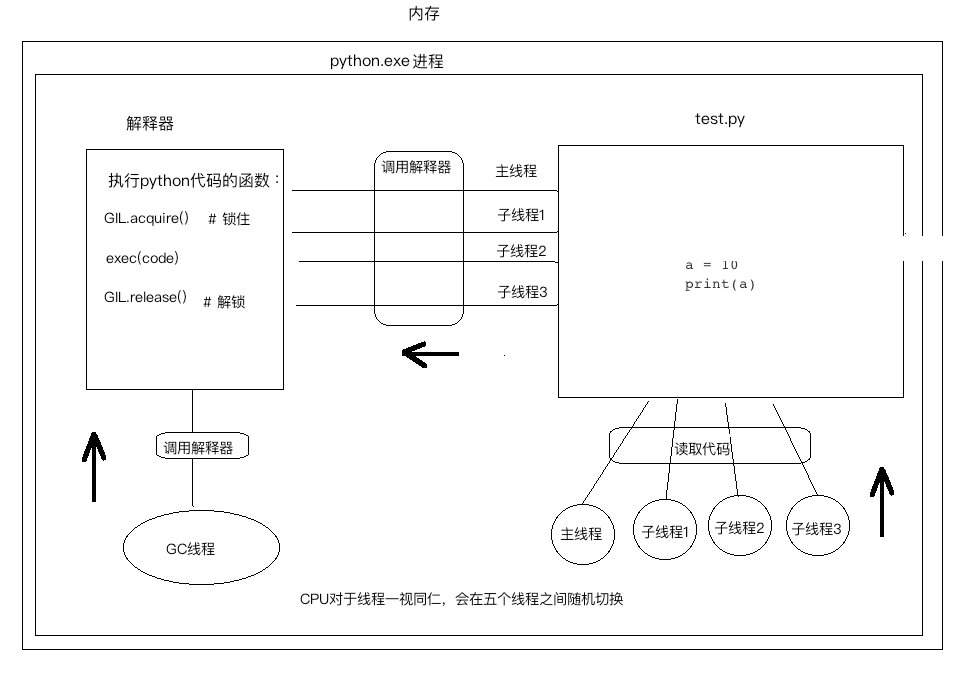
有了GIL后,多个线程将不可能在同一时间使用解释器,从而保证了解释器的数据安全。
GIL的加锁与解锁时机
加锁的时机:在调用解释器时立即加锁
解锁时机:
- 当前线程遇到了IO时释放
- 当前线程执行时间超过设定值时释放
四.关于GIL的性能讨论
GIL的优点:
- 保证了CPython中的内存管理是线程安全的
GIL的缺点:
- 互斥锁的特性使得多线程无法并行
但我们并不能因此就否认Python这门语言,其原因如下:
-
GIL仅仅在CPython解释器中存在,在其他的解释器中没有,并不是Python这门语言的缺点
-
在单核处理器下,多线程之间本来就无法真正的并行执行
-
在多核处理下,运算效率的确是比单核处理器高,但是要知道现代应用程序多数都是基于网络的(qq,微信,爬虫,浏览器等等),CPU的运行效率是无法决定网络速度的,而网络的速度是远远比不上处理器的运算速度,则意味着每次处理器在执行运算前都需要等待网络IO,这样一来多核优势也就没有那么明显了
举个例子:
任务1 从网络上下载一个网页,等待网络IO的时间为1分钟,解析网页数据花费,1秒钟
任务2 将用户输入数据并将其转换为大写,等待用户输入时间为1分钟,转换为大写花费,1秒钟
单核CPU下:1.开启第一个任务后进入等待。2.切换到第二个任务也进入了等待。一分钟后解析网页数据花费1秒解析完成切换到第二个任务,转换为大写花费1秒,那么总耗时为:1分+1秒+1秒 = 1分钟2秒
多核CPU下:1.CPU1处理第一个任务等待1分钟,解析花费1秒钟。1.CPU2处理第二个任务等待1分钟,转换大写花费1秒钟。由于两个任务是并行执行的所以总的执行时间为1分钟+1秒钟 = 1分钟1秒
可以发现,多核CPU对于总的执行时间提升只有1秒,但是这边的1秒实际上是夸张了,转换大写操作不可能需要1秒,时间非常短!
上面的两个任务都是需要大量IO时间的,这样的任务称之为IO密集型,与之对应的是计算密集型即IO操作较少大部分都是计算任务。
对于计算密集型任务,Python多线程的确比不上其他语言!为了解决这个弊端,Python推出了多进程技术,可以良好的利用多核处理器来完成计算密集任务。
总结:
1.单核下无论是IO密集还是计算密集GIL都不会产生任何影响
2.多核下对于IO密集任务,GIL会有细微的影响,基本可以忽略
3.Cpython中IO密集任务应该采用多线程,计算密集型应该采用多进程
另外:之所以广泛采用CPython解释器,就是因为大量的应用程序都是IO密集型的,还有另一个很重要的原因是CPython可以无缝对接各种C语言实现的库,这对于一些数学计算相关的应用程序而言非常的happy,直接就能使用各种现成的算法
计算密集型的效率测试
from multiprocessing import Process
from threading import Thread
import time
def task():
for i in range(10000000):
i += 1
if __name__ == '__main__':
start_time = time.time()
# 多进程
# p1 = Process(target=task)
# p2 = Process(target=task)
# p3 = Process(target=task)
# p4 = Process(target=task)
# 多线程
p1 = Thread(target=task)
p2 = Thread(target=task)
p3 = Thread(target=task)
p4 = Thread(target=task)
p1.start()
p2.start()
p3.start()
p4.start()
p1.join()
p2.join()
p3.join()
p4.join()
print(time.time()-start_time)
IO密集型的效率测试
from multiprocessing import Process
from threading import Thread
import time
def task():
with open("test.txt",encoding="utf-8") as f:
f.read()
if __name__ == '__main__':
start_time = time.time()
# 多进程
# p1 = Process(target=task)
# p2 = Process(target=task)
# p3 = Process(target=task)
# p4 = Process(target=task)
# 多线程
p1 = Thread(target=task)
p2 = Thread(target=task)
p3 = Thread(target=task)
p4 = Thread(target=task)
p1.start()
p2.start()
p3.start()
p4.start()
p1.join()
p2.join()
p3.join()
p4.join()
print(time.time()-start_time)
五.自定义的线程锁与GIL的区别
GIL保护的是解释器级别的数据安全,比如对象的引用计数,垃圾分代数据等等,具体参考垃圾回收机制详解。
对于程序中自己定义的数据则没有任何的保护效果,这一点在没有介绍GIL前我们就已经知道了,所以当程序中出现了共享自定义的数据时就要自己加锁,如下例:
from threading import Thread,Lock
import time
a = 0
def task():
global a
temp = a
time.sleep(0.01)
a = temp + 1
t1 = Thread(target=task)
t2 = Thread(target=task)
t1.start()
t2.start()
t1.join()
t2.join()
print(a)
过程分析:
1.线程1获得CPU执行权,并获取GIL锁执行代码 ,得到a的值为0后进入睡眠,释放CPU并释放GIL
2.线程2获得CPU执行权,并获取GIL锁执行代码 ,得到a的值为0后进入睡眠,释放CPU并释放GIL
3.线程1睡醒后获得CPU执行权,并获取GIL执行代码 ,将temp的值0+1后赋给a,执行完毕释放CPU并释放GIL
4.线程2睡醒后获得CPU执行权,并获取GIL执行代码 ,将temp的值0+1后赋给a,执行完毕释放CPU并释放GIL,最后a的值也就是1
之所以出现问题是因为两个线程在并发的执行同一段代码,解决方案就是加锁!
from threading import Thread,Lock
import time
lock = Lock()
a = 0
def task():
global a
lock.acquire()
temp = a
time.sleep(0.01)
a = temp + 1
lock.release()
t1 = Thread(target=task)
t2 = Thread(target=task)
t1.start()
t2.start()
t1.join()
t2.join()
print(a)
过程分析:
1.线程1获得CPU执行权,并获取GIL锁执行代码 ,得到a的值为0后进入睡眠,释放CPU并释放GIL,不释放lock
2.线程2获得CPU执行权,并获取GIL锁,尝试获取lock失败,无法执行,释放CPU并释放GIL
3.线程1睡醒后获得CPU执行权,并获取GIL继续执行代码 ,将temp的值0+1后赋给a,执行完毕释放CPU释放GIL,释放lock,此时a的值为1
4.线程2获得CPU执行权,获取GIL锁,尝试获取lock成功,执行代码,得到a的值为1后进入睡眠,释放CPU并释放GIL,不释放lock
5.线程2睡醒后获得CPU执行权,获取GIL继续执行代码 ,将temp的值1+1后赋给a,执行完毕释放CPU释放GIL,释放lock,此时a的值为2
六:进程池与线程池
什么是进程/线程池?
池表示一个容器,本质上就是一个存储进程或线程的列表
池子中存储线程还是进程?
如果是IO密集型任务使用线程池,如果是计算密集任务则使用进程池
为什么需要进程/线程池?
在很多情况下需要控制进程或线程的数量在一个合理的范围,例如TCP程序中,一个客户端对应一个线程,虽然线程的开销小,但肯定不能无限的开,否则系统资源迟早被耗尽,解决的办法就是控制线程的数量。
线程/进程池不仅帮我们控制线程/进程的数量,还帮我们完成了线程/进程的创建,销毁,以及任务的分配
进程池的使用:
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import time,os
# 创建进程池,指定最大进程数为3,此时不会创建进程,不指定数量时,默认为CPU和核数
pool = ProcessPoolExecutor(3)
def task():
time.sleep(1)
print(os.getpid(),"working..")
if __name__ == '__main__':
for i in range(10):
pool.submit(task) # 提交任务时立即创建进程
# 任务执行完成后也不会立即销毁进程
time.sleep(2)
for i in range(10):
pool.submit(task) #再有新任务是 直接使用之前已经创建好的进程来执行
线程池的使用:
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
from threading import current_thread,active_count
import time,os
# 创建进程池,指定最大线程数为3,此时不会创建线程,不指定数量时,默认为CPU和核数*5
pool = ThreadPoolExecutor(3)
print(active_count()) # 只有一个主线
def task():
time.sleep(1)
print(current_thread().name,"working..")
if __name__ == '__main__':
for i in range(10):
pool.submit(task) # 第一次提交任务时立即创建线程
# 任务执行完成后也不会立即销毁
time.sleep(2)
for i in range(10):
pool.submit(task) #再有新任务时 直接使用之前已经创建好的线程来执行
案例:TCP中的应用
首先要明确,TCP是IO密集型,应该使用线程池
七.同步异步-阻塞非阻塞
同步异步-阻塞非阻塞,经常会被程序员提及,并且概念非常容易混淆!
阻塞非阻塞指的是程序的运行状态
阻塞:当程序执行过程中遇到了IO操作,在执行IO操作时,程序无法继续执行其他代码,称为阻塞!
非阻塞:程序在正常运行没有遇到IO操作,或者通过某种方式使程序即时遇到了也不会停在原地,还可以执行其他操作,以提高CPU的占用率
同步-异步 指的是提交任务的方式
同步指调用:发起任务后必须在原地等待任务执行完成,才能继续执行
异步指调用:发起任务后必须不用等待任务执行,可以立即开启执行其他操作
同步会有等待的效果但是这和阻塞是完全不同的,阻塞时程序会被剥夺CPU执行权,而同步调用则不会!
很明显异步调用效率更高,但是任务的执行结果如何获取呢?
程序中的异步调用并获取结果方式1:
from concurrent.futures import ThreadPoolExecutor
from threading import current_thread
import time
pool = ThreadPoolExecutor(3)
def task(i):
time.sleep(0.01)
print(current_thread().name,"working..")
return i ** i
if __name__ == '__main__':
objs = []
for i in range(3):
res_obj = pool.submit(task,i) # 异步方式提交任务# 会返回一个对象用于表示任务结果
objs.append(res_obj)
# 该函数默认是阻塞的 会等待池子中所有任务执行结束后执行
pool.shutdown(wait=True)
# 从结果对象中取出执行结果
for res_obj in objs:
print(res_obj.result())
print("over")
程序中的异步调用并获取结果方式2:
from concurrent.futures import ThreadPoolExecutor
from threading import current_thread
import time
pool = ThreadPoolExecutor(3)
def task(i):
time.sleep(0.01)
print(current_thread().name,"working..")
return i ** i
if __name__ == '__main__':
objs = []
for i in range(3):
res_obj = pool.submit(task,i) # 会返回一个对象用于表示任务结果
print(res_obj.result()) #result是同步的一旦调用就必须等待 任务执行完成拿到结果
print("over")
8.异步回调
什么是异步回调
异步回调指的是:在发起一个异步任务的同时指定一个函数,在异步任务完成时会自动的调用这个函数
为什么需要异步回调
之前在使用线程池或进程池提交任务时,如果想要处理任务的执行结果则必须调用result函数或是shutdown函数,而它们都是是阻塞的,会等到任务执行完毕后才能继续执行,这样一来在这个等待过程中就无法执行其他任务,降低了效率,所以需要一种方案,即保证解析结果的线程不用等待,又能保证数据能够及时被解析,该方案就是异步回调
异步回调的使用
先来看一个案例:
在编写爬虫程序时,通常都是两个步骤:
1.从服务器下载一个网页文件
2.读取并且解析文件内容,提取有用的数据
按照以上流程可以编写一个简单的爬虫程序
要请求网页数据则需要使用到第三方的请求库requests可以通过pip或是pycharm来安装,在pycharm中点击settings->解释器->点击+号->搜索requests->安装
import requests,re,os,random,time
from concurrent.futures import ProcessPoolExecutor
def get_data(url):
print("%s 正在请求%s" % (os.getpid(),url))
time.sleep(random.randint(1,2))
response = requests.get(url)
print(os.getpid(),"请求成功 数据长度",len(response.content))
#parser(response) # 3.直接调用解析方法 哪个进程请求完成就那个进程解析数据 强行使两个操作耦合到一起了
return response
def parser(obj):
data = obj.result()
htm = data.content.decode("utf-8")
ls = re.findall("href=.*?com",htm)
print(os.getpid(),"解析成功",len(ls),"个链接")
if __name__ == '__main__':
pool = ProcessPoolExecutor(3)
urls = ["https://www.baidu.com",
"https://www.sina.com",
"https://www.python.org",
"https://www.tmall.com",
"https://www.mysql.com",
"https://www.apple.com.cn"]
# objs = []
for url in urls:
# res = pool.submit(get_data,url).result() # 1.同步的方式获取结果 将导致所有请求任务不能并发
# parser(res)
obj = pool.submit(get_data,url) #
obj.add_done_callback(parser) # 4.使用异步回调,保证了数据可以被及时处理,并且请求和解析解开了耦合
# objs.append(obj)
# pool.shutdown() # 2.等待所有任务执行结束在统一的解析
# for obj in objs:
# res = obj.result()
# parser(res)
# 1.请求任务可以并发 但是结果不能被及时解析 必须等所有请求完成才能解析
# 2.解析任务变成了串行,
总结:异步回调使用方法就是在提交任务后得到一个Futures对象,调用对象的add_done_callback来指定一个回调函数,
如果把任务比喻为烧水,没有回调时就只能守着水壶等待水开,有了回调相当于换了一个会响的水壶,烧水期间可用作其他的事情,等待水开了水壶会自动发出声音,这时候再回来处理。水壶自动发出声音就是回调。
注意:
- 使用进程池时,回调函数都是主进程中执行执行
- 使用线程池时,回调函数的执行线程是不确定的,哪个线程空闲就交给哪个线程
- 回调函数默认接收一个参数就是这个任务对象自己,再通过对象的result函数来获取任务的处理结果
9.线程队列
1.Queue 先进先出队列
与多进程中的Queue使用方式完全相同,区别仅仅是不能被多进程共享。
q = Queue(3)
q.put(1)
q.put(2)
q.put(3)
print(q.get(timeout=1))
print(q.get(timeout=1))
print(q.get(timeout=1))
2.LifoQueue 后进先出队列
该队列可以模拟堆栈,实现先进后出,后进先出
lq = LifoQueue()
lq.put(1)
lq.put(2)
lq.put(3)
print(lq.get())
print(lq.get())
print(lq.get())
3.PriorityQueue 优先级队列
该队列可以为每个元素指定一个优先级,这个优先级可以是数字,字符串或其他类型,但是必须是可以比较大小的类型,取出数据时会按照从小到大的顺序取出
pq = PriorityQueue()
# 数字优先级
pq.put((10,"a"))
pq.put((11,"a"))
pq.put((-11111,"a"))
print(pq.get())
print(pq.get())
print(pq.get())
# 字符串优先级
pq.put(("b","a"))
pq.put(("c","a"))
pq.put(("a","a"))
print(pq.get())
print(pq.get())
print(pq.get())
10.线程事件Event
什么是事件
事件表示在某个时间发生了某个事情的通知信号,用于线程间协同工作。
因为不同线程之间是独立运行的状态不可预测,所以一个线程与另一个线程间的数据是不同步的,当一个线程需要利用另一个线程的状态来确定自己的下一步操作时,就必须保持线程间数据的同步,Event就可以实现线程间同步
Event介绍
Event象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
可用方法:
event.isSet():返回event的状态值;
event.wait():将阻塞线程;知道event的状态为True
event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度;
event.clear():恢复event的状态值为False。
使用案例:
# 在链接mysql服务器前必须保证mysql已经启动,而启动需要花费一些时间,所以客户端不能立即发起链接 需要等待msyql启动完成后立即发起链接
from threading import Event,Thread
import time
boot = False
def start():
global boot
print("正正在启动服务器.....")
time.sleep(5)
print("服务器启动完成!")
boot = True
def connect():
while True:
if boot:
print("链接成功")
break
else:
print("链接失败")
time.sleep(1)
Thread(target=start).start()
Thread(target=connect).start()
Thread(target=connect).start()
使用Event改造后:
from threading import Event,Thread
import time
e = Event()
def start():
global boot
print("正正在启动服务器.....")
time.sleep(3)
print("服务器启动完成!")
e.set()
def connect():
e.wait()
print("链接成功")
Thread(target=start).start()
Thread(target=connect).start()
Thread(target=connect).start()
增加需求,每次尝试链接等待1秒,尝试次数为3次
from threading import Event,Thread
import time
e = Event()
def start():
global boot
print("正正在启动服务器.....")
time.sleep(5)
print("服务器启动完成!")
e.set()
def connect():
for i in range(1,4):
print("第%s次尝试链接" % i)
e.wait(1)
if e.isSet():
print("链接成功")
break
else:
print("第%s次链接失败" % i)
else:
print("服务器未启动!")
Thread(target=start).start()
Thread(target=connect).start()
# Thread(target=connect).start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号