

Redis数据类型及使用场景
Redis使用场景
1、高并发热点数据缓存
对于高并发,读多写少的场景。通常将热点数据加载到Redis中缓存起来,减少数据库的压力,并提高响应速度
2、分布式缓存
在分布式的系统架构中,多个服务之间需要共享缓存交换数据,将缓存存储在各自机器的内存中显然不行,这就需要Redis的分布式缓存使服务间共享
3、分布式锁
在高并发的情况下,我们需要一个锁来防止并发带来的脏数据,Java自带的锁机制显然对多服务间的并发并不好使,此时可以利用Redis的单线程的特性来实现分布式锁
4、session存储/共享
Redis可以将Session持久化到存储中,这样可以避免由于机器宕机而丢失用户会话信息
5、发布/订阅
在一个channel发布消息后,所有订阅此channel的客户端都会收到此消息通知,这一功能可用作实时消息系统
6、任务队列
Redis 的 lpush+brpop 命令组合即可实现阻塞队列,生产者客户端使用 lrpush 从列表左侧插入元素,多个消费者客户端使用 brpop 命令阻塞式的”抢”列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性。
7、限速,接口访问频率限制
比如发送短信验证码的接口,通常为了防止别人恶意频刷,会限制用户每分钟获取验证码的频率。
Redis数据类型及其数据结构
Redis有五种数据类型。分别为
1、string(字符串)
Redis的字符串是简单动态字符串SDS(Simple Dynamic String),是可以修改的字符串,内部结构的实现类似于Java的ArrayList,是一个带长度信息的字节数组,采用预分配冗余空间的方式来减少内存的频繁分配;
实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1MB时,扩容都是加倍现有的空间。如果字符串的长度超过1MB,扩容时一次只会多扩1MB的空间。需要注意的是字符串的最大长度为512MB
计数:如果value是一个整数,还可以对它进行自增操作。不过自增是有范围的,它的范围在signed long的最大值和最小值之间(0-2^63-1),超过这个范围,Redis会报错
2、list(列表)
Redis中的列表相当于Java语言中的LinkedList,注意它是链表而不是数组。这意味着list的插入和删除很快,时间复杂度为 O(1),但是查询很慢,时间复杂度为O(n),但是深入了解的话,Redis底层存储的并不是一个简单的LinkedList,而是称为一个快速链表的结构。在列表元素较少的情况下,会使用一块连续的内存存储,这个结构是ziplist,即压缩列表,当数据量比较多的时候才会改成quicklist,因为普通的链表需要的附加指针空间太大,会浪费空间,还会加重内存的碎片化,Redis将多个ziplist使用双向指针串起来使用组成了quicklist,既满足了快速的插入删除性能,又不会出现太大的空间冗余。
Redis的列表常用来做异步队列使用。将需要延后的任务结构体序列化字符串,塞进Redis中的列表,另一个线程从这个列表中轮询数据进行处理。
3、hash(字典)
Redis的字典相当于Java语言中的HashMap,它是无序字典,内部存储了很多键值对。实际结构和Java中的HashMap也是一样的,都是数组+链表的结构,第一维hash的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。
但是Redis的字典的值只能是字符串,另外它们rehash的方式也不同,Java需要一次性rehash,Redis为了追求性能,采用了渐进式rehash策略:在rehash时会保留新旧两个hash结构,查询时会同时查询两个hash结构,然后在后续的定时任务以及hash操作指令中,循序渐进的将旧的hash内容一点点的迁移到新的hash结构中,当全部迁移完成了就会使用的新的hash完全替代。
hash也有缺点,hash结构的存储消耗要高于单个字符串。hash结构中的单个子key也可以单独进行计数,对应的指令是hincrby,和incr基本一样
4、set(集合)
Redis的集合相当于Java语言中的HashSet,它内部的键值对是无序,唯一的,它的内部实现相当于一个特殊的字典,字典中所有的Value都是一个值NULL。
当集合中最后一个元素被移除之后,数据结构被自动删除,内存被回收。set结构可以用来存储在某活动中中奖用户的ID,因为有去重功能,可以保证一个用户不会中奖两次。
5、zset(Sorted Set,有序集合)
它类似与Java中的SortedSet和HashMap的结合体,一方面它是一个set,保证了内部value的唯一性,另一方面可以为每个value赋予一个score,代表这个value的排序权重。它的内部实现的数据结构是跳跃列表。
zset可以存储学生的成绩,value是学生的ID,score是他的考试成绩,我们对成绩按分数进行排序就能得到名次。
跳跃列表:
zset内部的排序功能是通过跳跃列表来实现的。因为zset要支持随机的插入和删除,所以不宜使用数组来表示。
跳表可以理解为一个加了多级索引的链表。对一个单链表来讲,即使链表中存储的数据是有序的,如果我们要想在
其中查找某个数据,也只能从头到尾遍历链表,效率很低,时间复杂度是 O(n),如何提高查询效率呢,我们可以
通过给链表加索引的方式。如:
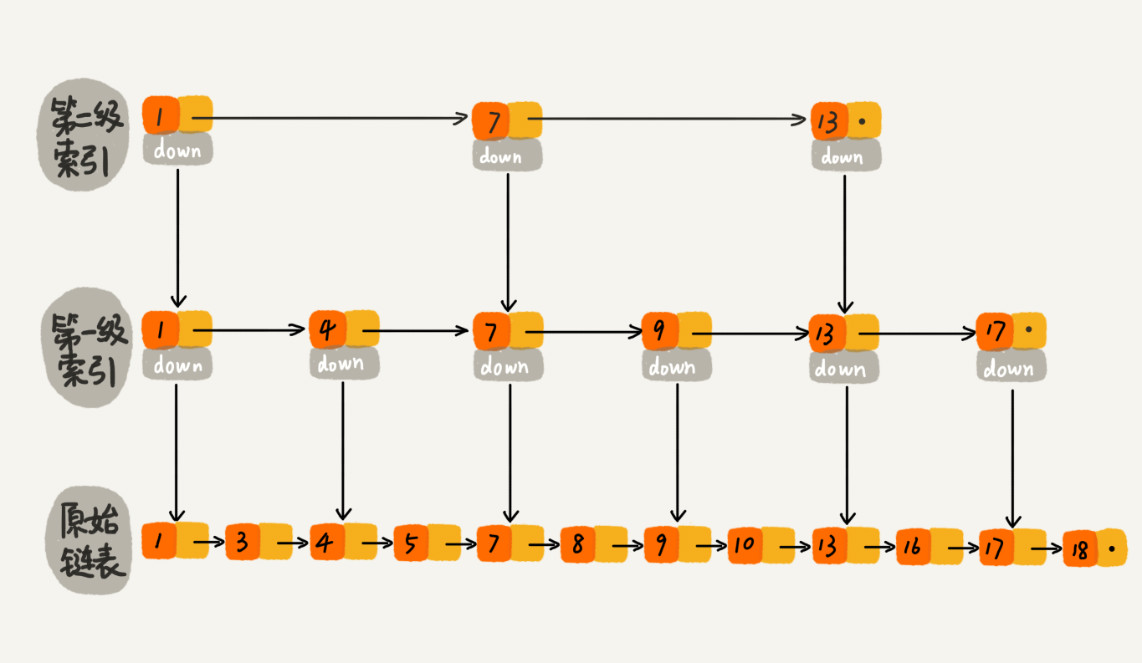
如果要查找元素16,现在索引层遍历,找到第二索引层中13的结点时,向下到第一层索引,发现其下一个元素是17,大于16,因此通过索引层结点的down
指针,下降到原始链表这一层,继续遍历,这个时候只需要再遍历2个结点,就可以找到16这个结点了。这样有了索引层之后原本需要遍历10个结点,现在
只需要遍历6个结点了。链表元素越多,索引层越多查询优势越加明显。所以在跳表中查询任意数据的时间复杂度就是 O(logn),和二分查找的时间复杂度是
一样的。但是相比于单链表,跳表需要存储多级索引,因此要消耗更多的存储空间。如一个长度为n的链表,第一级索引大约有n/2个结点,第二级大约有n/4
个结点,每上升 一级结点就减少一半,直到剩下2个结点。因此共有约2+4+...+n/4+n/2是一个等比数列和为n-2(公式a1-an*q/1-q),因此跳表的空间复杂度为O(n).
要想降低跳表的空间复杂度,可以考虑3个或更多的结点建立一个索引。
跳表的索引动态更新:当不断的往跳表中插入数据时,如果不更新索引就会出现某2个索引结点之间数据非常多的情况,极端条件下甚至会退化成单链表。因此
当往跳表中插入数据时,应该选择性的将这个数据插入到部分索引层中,通过随机函数的方式生成值k,将结点添加到第k级索引层中。
Redis为什么用跳表实现有序列表而不是红黑树?
Redis中有序集合支持的核心操作主要有下面几个:
插入数据,删除数据,查找数据,按照区间查找数据(比如查找score在[100-250]的数据),迭代输出有序序列等
其中,插入,删除,查找以及迭代输出有序序列这几个操作,红黑树也能实现,时间复杂度也是O(logn),但是按照区间来查找数据这个操作,红黑树的效率没有
跳表高。对于按照区间查找数据这个操作,跳表可以做到O(logn)的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了,效率很高。还有一个
原因就是跳表更容易代码实现。
容器型数据结构的通用规则
list、set、hash、zset这四种数据结构是容器型数据结构,有下面两个通用规则
1、create if not exists:如果容器不存在就创建一个,再进行操作
2、drop if no elements:如果容器里的元素没有了,那么立即删除容器,释放内存
过期时间
Redis所有的数据结构都可以设置过期时间,时间到了之后会执行Redis的删除策略,但是有一个需要特别注意的地方,如果一个字符串已经设置了过期时间,然后调用set命令修改了它,那么它的过期时间会消失。
消息队列
Redis可以实现轻量级的消息队列。对于那些只有一组消费者的消息队列,使用Redis就可以轻松搞定。
但是Redis不是专业的消息队列,没有ack保证,因此对消息可靠性有极高要求的话就不适合使用。
1、异步消息队列
Redis的list(列表)数据结构常用来作为异步消息队列使用,使用rpush(右入队)和lpush(左入队)操作入队列,用lpop(左出队)和rpop(右出队)操作出队。
它支持多个生产者和消费这并发进出消息,每个消费者拿到的消息都是不同的列表元素。
如果队列空了:pop获取数据的话会不停的pop空轮询,会导致拉高客户端的CPU消耗和QPS导致慢查询增多。因此遇到空队列可让当前线程先sleep 1s。
阻塞读:让线程休眠1s可导致消息队列的延迟增大,可使用blpop/brpop替代lpop/rpop,阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则
立即醒过来,消息的延迟几乎为0.
空闲连接:如果线程阻塞时间太长,Redis的客户端就变成了闲置连接,闲置过久,服务器一般会断开连接,减少闲置资源占用,这个时候brpop/blpop会抛出异常,
所以在编写消费者时要扑获异常,然后重试。
2、延时队列
延时队列可以使用Redis的zset(有序列表)来实现。将消息序列化成一个字符串作为zset的value,这个消息的到期处理时间作为score,然后利用多个线程轮询
zset获取到期的任务进行处理。
Redis高级数据结构
位图
bitmap
平时的开发中,有些布尔型的数据需要存取,如用户一年的签到记录,签了是1,不签是0.要记录365天,当用户量很大的时候,需要的存储空间是很大的。为了
解决这个问题,Redis提供了位图数据结构,这样每条数据只占据一个位,如365条记录只占据365个位,46字节。大大节省了存储空间。位图的最小单位是bit。
每个bit的取值只能是0或者1。位图其实就是byte数组。可以使用get/set直接获取和设置整个位图的内容,也可以使用位图操作getbit/setbit来把byte数组当成位
数组来处理。
HyperLogLog
HyperLogLog用来解决去重的统计问题,提供了不精确的计数方案,标准误差为0.81%。例如统计页面的UV,用set的话如果有千万级的UV,set集合会非常大
非常浪费空间。这种情况就适合用HyperLogLog。
HyperLogLog提供了两个指令pfadd和pfcount,pfadd用来增加计数,pfcount用来获取计数。另一个指令pfmerge,用于将多个pf计数值累加在一起形成一个新
的pf值。
布隆过滤器
HyperLogLog虽然能去重,但是不能判断是否包含一个值的情况。这就需要布隆过滤器来判断是否包含某个值了。
Bloom Filter,专门用来解决大数据量的去重问题。而且比set要节省90%以上的空间,不过稍微有点不精确,有一定的误判概率。当布隆过滤器说某个值存在时,可能不存在,当说不存在时就一定不存在。
用法:两个基本指令,bf.add和bf.exists 添加一个元素和判断一个元素是否存在。 bf.madd和bf.mexists添加多个元素和查询多个元素是否存在。
通过在add之前bf.reserve指令显式创建,在bf.reserve指令的三个参数中自定义布隆过滤器。这三个参数分别是 key、error_rate(错误率)和initial_size,error_rate越低,需要的空间越大
initial_size表示预计放入元素的数量,当实际数量超出这个数值时,误判率会上升,所以需要提前设置一个较大的数值避免超出导致误判率升高。但也不能太
大,会浪费内存空间。所以在使用之前要尽可能的精确估计元素数量,还要加上一定的冗余空间避免实际的元素比预估高出很多。
原理:布隆过滤器的数据结构是一个大型的位数组和几个不一样的无偏hash函数。所谓无偏就是能够把元素的hash值算的比较均匀,让元素被hash映射到位数组
的位置比较随机。 过程:当向布隆过滤器中添加key时,会使用多个hash函数对key进行hash,算得一个整数索引值,然后对位数组长度进行取模运算得到
一个位置,每个hash函数都会得到一个位置。再把位位置的这几个位置都置为1,完成add操作。 查找key时,用多个hash函数对key进行hash,再根据长度算
得对应的几个位置,看这几个位置对应的值是否都是1,有一个位置为0,则说明key不存在。都为1也可能是其他的key哈希冲突导致,也可能不存在。所以如
果数组比较稀疏,则判断正确的概率就很大。
应用:避免缓存穿透将所有有可能存在的key放进布隆过滤器中,查询时过滤掉一个一定不存在数据的查询,减轻数据库的压力。
Redis实现限流
漏斗限流:模块Redis-Cell,用法
cl.throttle key capacity times seconds 1
参数:key 是用户+行为
capacity:漏斗的初始容量,不受限流控制的次数
times :多少次
seconds:多少时间内,单位秒
1:默认值1,表示剩余空间的最小单位
结果为5个Integer值,从上到下依次表示
1、0表示允许,1表示禁止
2、漏斗容量capacity
3、漏斗剩余空间
4、如果被拒绝了需要多长时间进行重试,单位秒,没决绝的话值为-1
5、多长时间后漏斗完全空出来
地理位置Geo模块
可以用来查找附近的单车,餐馆类似功能。地理元素的位置使用二维的经纬度表示,京都范围 [-180,180],纬度范围 [-90,90],纬度正负以赤道为界,北正南负。
经度正负以本初子午线(英国格林尼治天文台)为界,东正西负。
业界比较通用的地理位置距离排序算法是GeoHash算法,Redis也使用GeoHash算法。GeoHash算法将二维的经纬度数据映射到一维的整数,这样所有的元素
都挂载到一条线上,距离靠近的二维坐标映射到一维后的点之间距离也会很接近。如我们要计算附近的人时,首先将目标位置映射到这条线上,然后在这个一
维的 线上获取附近的点就行了。
scan
Redis提供了一个简单粗暴的keys指令用来列出所有满足特定正则字符串规则的key。使用时只需要再keys 后面提供一个简单的正则匹配字符串即可。但是有两
个致命缺点:
1、没有offset、limit参数,会一次性列出所有符合条件的key,即使有成千上万个key,也会一一列出
2、keys算法是遍历算法,时间复杂度为O(n),如果符合条件的key有千万级别以上就会导致Redis服务卡顿,由于Redis是单线程操作,所有读写Redis的其他
指令都会延后甚至会超时报错。
scan指令:2.8版本提供
1、复杂度为O(n),但它是通过游标分步进行的,不会阻塞线程
2、提供limit参数,可以控制每次返回结果的最大条数,limit只是一个hint,返回的结果可多可少
3、同keys一样,也提供模式匹配功能
4、服务器不需要为游标保持状态,游标唯一的状态就是scan返回给客户端的游标整数
5、返回的结果可能会有重复,需要客户端去重
6、遍历的过程如果有数据修改,改动后的数据能不能遍历是不确定的
7、单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为0
在Redis中所有的key都存储在一个很大的字典中,这个字典和Java中的HashMap一样。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号