

B树与B+树
一、先了解二叉查找树和平衡二叉树
1、二叉查找树(binary Tree)
定义:
(1):每个节点最多只能有两棵子树(节点的度不大于2),且有左右之分
(2):左子树的键值小于根的键值,右子树的键值大于根的键值
特殊类型的二叉树:
满二叉树:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树
完全二叉树:一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树
2、 平衡二叉搜索树(AVL Tree)
定义:在符合二叉查找树的条件下,还满足任何节点的两个子树的高度差最大为1.
二、B树:
1、什么是B树
B树(Balance Tree),由平衡二叉树(AVLTree)演化而来的,为磁盘等直接存取的辅助设备而设计的一种平衡多路查找树。
B树类似于红黑树但是B树的节点可以由很多个孩子,也就是B树的分支因子可以相当大。B树与红黑树的每棵含有n个节点的树的高度为O(logn)。
一个B树的节点x含有n个关键字,那么这个节点就会有n+1个孩子。节点中的每个关键字就是分隔点。所以n个关键字被分隔成了n+1个子域。每个域对应一个孩子。当在一棵B树中查找一个关键字时,基于存储在x中的n个关键字的比较,找到对应的域和子节点。
B树的任何和节点中的关键字相联系的数据都与关键字一样存放在同一个结点中。也可能在关键字中存放一个指针存放该关联数据的磁盘页。当关键字从一个结点移动到另一个结点时,无论是与关键字相关联的数据还是指向关联数据的指针都会随着关键字一起移动。
2、一个m路B树的特征
(1):每个节点最多有m个孩子
(2):除了根节点和叶子节点外,其他每个节点至少有m/2个孩子,最多有m个孩子
(3):若根节点不是叶子节点,则至少有2个孩子
(4):每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
(5):所有叶子节点在同一层,且不包含其他关键字信息
3、B树的特点
1、每个结点x有个属性x.n表示当前存储在结点x中的关键字个数。
2、x.n个关键字以x.key1,x.key2...x.keyn 以升序存放,x.key1<x.key2<...<x.keyn
3、x.leaf,一个布尔值,如果x是叶子结点则为true,如果x为内部结点,则为false。
4、每个内部结点x还包含x.n+1个指向其孩子的指针x.c1,x.c2,...,x.cn,x.cn+1。叶子结点没有孩子,所以他们的ci属性没有定义。
5、关键字x.keyi对存储在各子树中的关键字范围加以分割;如果ki为任意一个存储在以x.ci为根的子树中的关键字,那么
k1<x.key1<k2<x.key2<.k3..<x.keyn<kn+1
6、每个叶子结点都有相同的深度,也就是树的高度h。
7、B树大部分的操作所需的磁盘空间存取次数与B树的高度是成正比的。B树以红黑树的高度都已O(logn)的速度增长但是B树的底比红黑树大很多倍。因此,要检查的结点数在B树中要比在红黑树中少大约lgt的因子,B树中每个结点至少含有t-1个关键字。由于在一棵树的搜索中对任意一个结点都需要一次磁盘访问,所以B树避免了大量的磁盘访问。
8、B树的根节点始终在主存中,查找时无需对根做DISK-READ操作,但当根节点被改变时需要对根结点做一次DISK-WRITE操作。
9、搜索一棵B树对每个结点x,做的是一个x.n+1路的分支选择。
10、B树的结点不仅存储关键字还存储关键字对应的记录的data值。而磁盘每一页的存储空间是有限的,16k,如果data数据较大时将会导致每个结点能存储的key数量很小,当存储的数据量很大时同样会导致B树的高度很大,增大查询是的磁盘IO次数,进而影响查询效率(主存和磁盘以页为单位交换数据,B+树将每个节点的大小设置和页大小一样,都为16K,因此读取一个节点,只需要一次IO)。
B+树中,所有的数据记录都按照键值大小顺序存放在同一层的叶子结点上,非叶子结点上只存储关键字key信息,不存储key关联的数据记录数据,所以可以大大加大每个结点存储的key关键字的数量,降低B+树的高度。
三、B+树
B+树是B树的一个变种,它把所有的关联数据都存储在叶子结点中,内部结点只存放关键字和孩子指针,因此最大化了内部结点的分支因子。使其更适合实现外存储索引结构。
由于B树中每一个节点占用一个磁盘块的空间。而操作系统从磁盘读取数据到内存中是以磁盘块为单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么读取什么。
InnoDB存储引擎中有页(page)的概念,页是其磁盘管理的最小单位,在InnoDB存储引擎中默认每个页的大小为16K,B+树将每个节点的大小设置和页大小一样,都为16K,因此读取一个节点,只需要一次IO。
而B树中每个节点中不仅包含数据的key值,还会包含除了key值外的所有data值。而每一页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度很大,增大查询时的磁盘IO次数,进而影响查询效率。而B+树中,所有数据节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息, 这样可以大大加大每个节点存储的key值数量, 降低B+树的高度,减少查询时的IO次数。
四、B+树与B树的区别
B-Tree和B+Tree的区别
| B-Tree | B+Tree |
| 没有指向下一个叶子节点的指针 | 每个叶子节点都包含指向下一个叶子节点的指针,从而方便叶子节点的范围遍历 |
| 所有节点都带有指向指向实际记录的指针(ROWID) |
只在叶节点存储记录(带有指向实际记录的指针(ROWID)),内部节点存储关键码值,这些关键码值只是用于引导索引检索位符 由于是数据索引,因此可能存在同一个键值,即出现在内部节点,又出现在叶子节点中的情况 |
B+树相对B树有几点不同:
1、非叶子结点只存储键值信息
2、存在同一个键值,即出现在内部节点,又出现在叶子节点中的情况
3、所有的叶子结点之间都有指向下一个叶子结点的指针
4、数据记录都存放在叶子结点中,非叶子结点中不存储数据记录信息。
5、B+树存放相同的数据记录时高度大大低于B树,查询时的IO操作远比B树少,效率更高。
做一个推理:InnoDb表的存储引擎中一页的大小为16k,一般表的主键类型占用8个字节,指针占用8个字节,那么一页可以存放16kb/(8b*8b)=1000个键值(关键字),所以一个高度为3的B+树可以存储1000^3即10亿条记录。查询时只需要两次IO操作就可找到要查找的记录。大大节约了查询时间。
B树
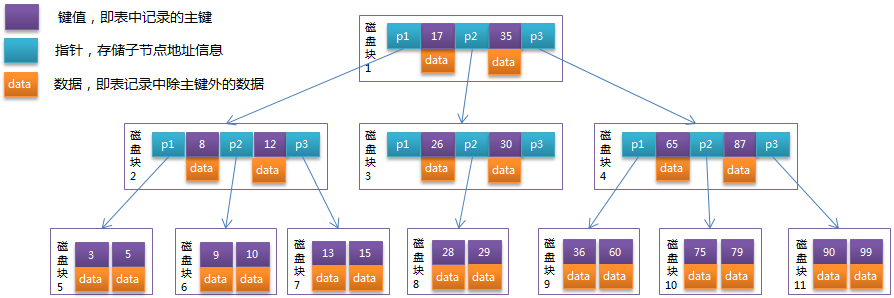
B+树
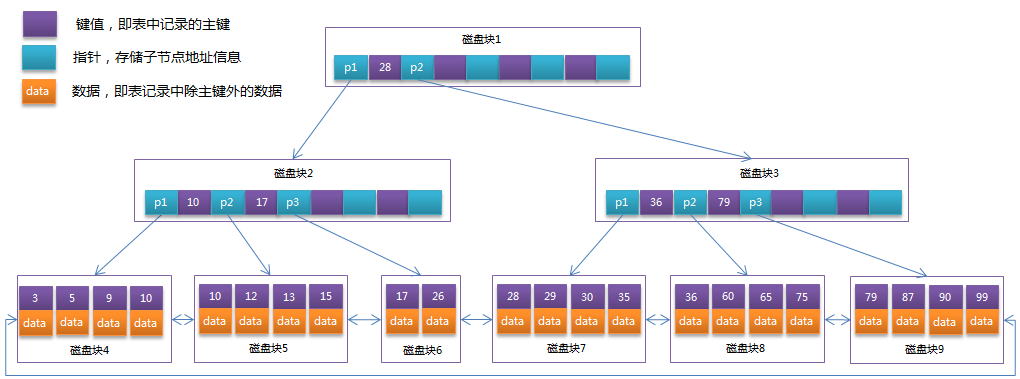
图来自:https://www.cnblogs.com/vianzhang/p/7922426.html
动态数据结构演示: https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
示例:
(1)一个度最大为5的B树
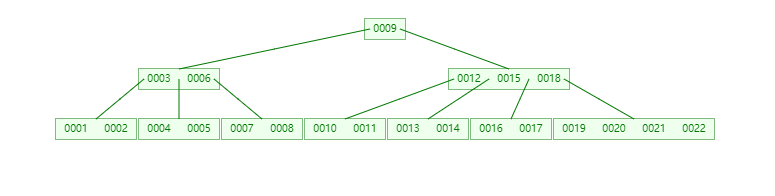
(2)一个度最大为5的B+树


 浙公网安备 33010602011771号
浙公网安备 33010602011771号