
完整教程:【算法】深度优先遍历/搜索(递归、回溯、剪枝)
目录
递归、回溯、剪枝概念
为什么会用到递归?
在解决主问题时,产生了与主问题相同的子问题。解决主问题和子问题的方法相同。如果函数 f 可以解决主问题,那么在函数 f 内部必定再次调用函数 f 解决子问题,即递归。
如何写好一个递归?
首先要看出主问题可以分成若干个相同的子问题。还要明确知道解决子问题所需要的材料,目的是设计好函数头。仅仅关心子问题是如何解决的,目的是设计好函数体,在设计递归函数时:
在能够 1、画好递归展开图和 2、理解二叉树的相关递归题目的基础之上:
1、不要在意递归展开图
2、把递归函数当成一个黑盒
3、相信这个黑盒一定可以完成任务
4、注意函数的出口(最小子问题)
递归 VS 循环
为什么有时候写递归比较舒服,有时候写循环比较舒服?关键在于如果递归展开图是”一颗多叉树“的情况,写递归比较舒服,如果递归展开图是”链表“的情况,写循环比较舒服。以遍历数组为例:
// 循环
for(int i = 0; i < num.size(); i++)
{
cout << num[i] << " ";
}
// 递归
void dfs(vector num,int i)
{
if(i == num.size()) return;
cout << num[i] << " ";
dfs(num,i + 1);
}
int main()
{
vector num = {1 , 2 , 3 };
dfs(num,i);
return 0;
} 因为遍历数组的递归展开图是”链表“,所以它不管是循环还是递归都比较舒服。
什么是回溯?
其实回溯就是函数递归时,返回到上一层,就叫回溯
什么是剪枝?
当一个分支已经不满足条件或者没有必要遍历时,遇到这个分支直接跳过
解析:要完成把 A 柱的 n 个盘子借助 B 柱放在 C 柱的主问题,就要先完成把 A 柱的 n - 1 个盘子借助 C 柱放在 B 柱,再把 A 柱的一个盘子放在 C 柱,再把 B 柱的 n - 1 个盘子借助 A 柱放在 C 柱,相同的子问题:把某个柱子的几个盘子借助某个柱子放在另一个柱子。
class Solution {
public:
void hanota(vector& A, vector& B, vector& C) {
_hanota(A,B,C,A.size());
}
void _hanota(vector& x,vector& y,vector& z,int n)
{
if(n == 1)
{
z.push_back(x.back());
x.pop_back();
return;
}
_hanota(x,z,y,n - 1);
z.push_back(x.back());
x.pop_back();
_hanota(y,x,z,n - 1);
}
}; 
解析:每次从两个链表的头结点选出较小的结点作为头结点,链接其余结点合并后的结果,而 “其余结点合并” 又可以是 “每次从两个链表的头结点选出较小的结点作为头结点,链接其余结点合并后的结果”
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
if(list1 == nullptr) return list2;
if(list2 == nullptr) return list1;
ListNode* head = list1->val <= list2->val ? list1 : list2;
if(list1->val <= list2->val) head->next = mergeTwoLists(list1->next,list2);
else head->next = mergeTwoLists(list1,list2->next);
return head;
}
};
解析:如果要求 x 的 n 次方,可以 x*x*x*x*x*x...x*x*x*x*x,这样太慢了,如果知道 x 的 n/2 次方,就可以快速求出 x 的 n 次方:x 的 n 次方 = x 的 n/2 次方 * x 的 n/2 次方,只需要乘一次。而要求 x 的 n/2 次方,就要知道 x 的 n/4 次方... 直到 x 的 0 次方即 1,返回。
class Solution {
public:
double myPow(double x, int n) {
long long N = n;
if(x == 1 || n == 0) return 1.0;
if(n < 0) return 1.0 / _myPow(x,-N);
return _myPow(x,n);
}
double _myPow(double x, long long n)
{
if(n == 1) return x;
double tmp = _myPow(x,n / 2);
return n % 2 == 0 ? tmp * tmp : tmp * tmp * x;
}
};
解析:先画出决策树,再把决策树转换为代码,考虑要使用哪些全局变量,设计好 dfs 函数的函数头以及函数体,再注意细节问题:是否可以剪枝,回溯时如何恢复现场。这道题为了做到不重不漏,用一个 bool 类型的数组标记元素是否以及被选择过,
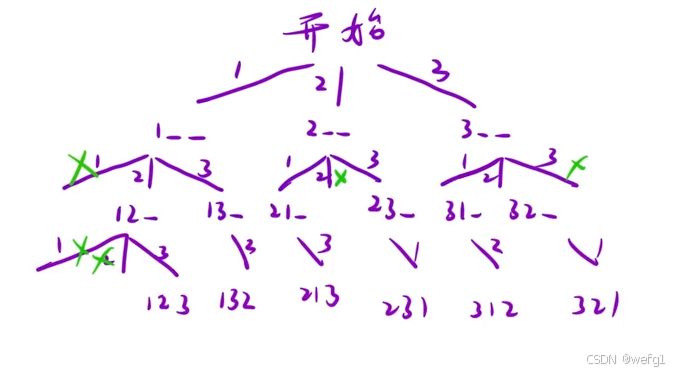
class Solution {
public:
vector> ret;
vector path;
bool vis[7];
vector> permute(vector& nums) {
_permute(nums);
return ret;
}
void _permute(vector& nums)
{
if(path.size() == nums.size())
{
ret.push_back(path);
return;
}
for(int i = 0; i < nums.size(); i++)
{
if(!vis[i])
{
path.push_back(nums[i]);
vis[i] = true;
_permute(nums);
// 恢复现场
path.pop_back();
vis[i] = false;
}
}
}
}; 
解析:方法1:遍历数组,对数组每个元素决定是“选”还是不“选”
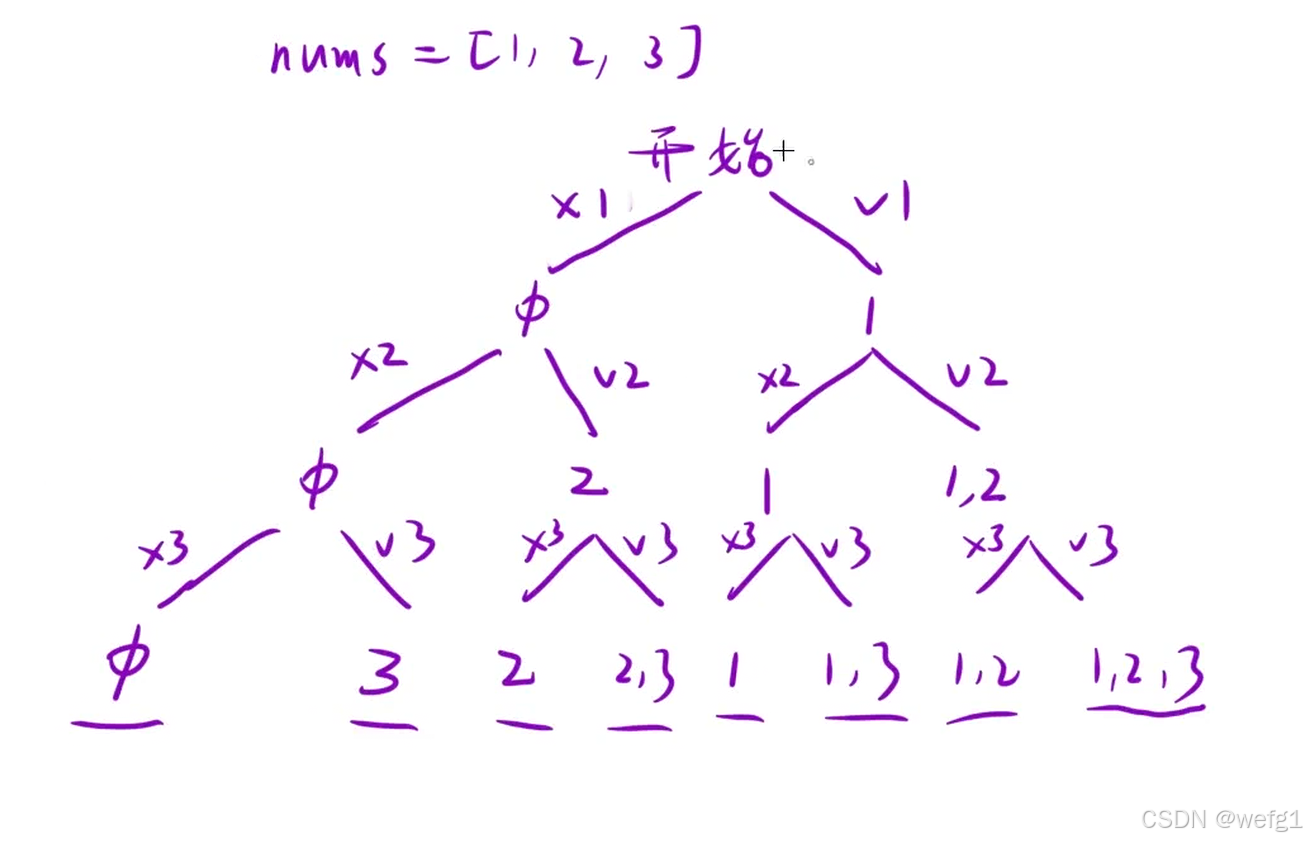
class Solution {
public:
vector> ret;
vector path;
vector> subsets(vector& nums) {
_subsets(nums,0);
return ret;
}
void _subsets(vector& nums,int i)
{
if(i == nums.size())
{
ret.push_back(path);
return;
}
path.push_back(nums[i]);
_subsets(nums,i + 1);
path.pop_back();
_subsets(nums,i + 1);
}
}; 方法2(更优):从子集有多少个元素的角度考虑,把子集分为有 0 个元素的子集、1个元素的子集......有 nums.size() 个元素的子集。在考虑有 n 个元素的子集时,在有 n - 1 个元素的子集的基础之上添加元素,添加的元素必须是上次添加的元素之后的元素。
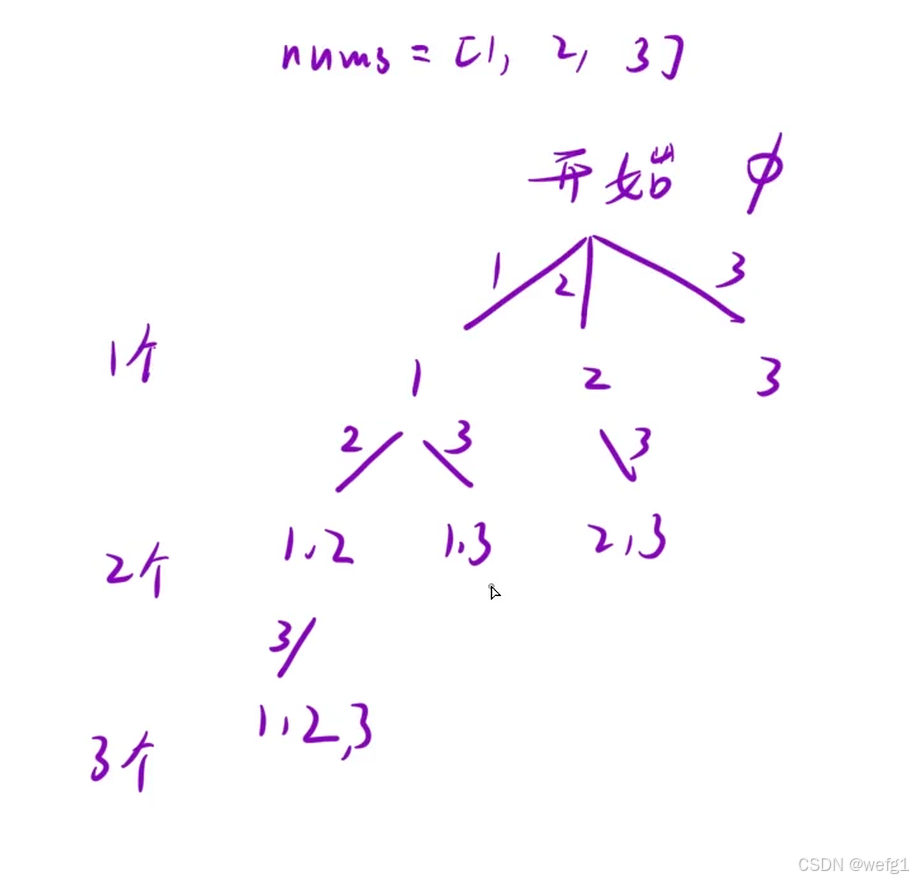
class Solution {
public:
vector> ret;
vector path;
vector> subsets(vector& nums) {
_subsets(nums,0);
return ret;
}
void _subsets(vector& nums,int pos)
{
ret.push_back(path);
for(int i = pos; i < nums.size(); i++)
{
path.push_back(nums[i]);
_subsets(nums, i + 1);
path.pop_back();
}
}
}; 
一组括号是否匹配:
1、左括号数量 == 右括号数量
2、从头开始的任意一个子串,左括号数量 >= 右括号数量
class Solution {
public:
vector ret;
string path;
int l = 0;
int r = 0;
vector generateParenthesis(int n) {
_generateParenthesis(n);
return ret;
}
void _generateParenthesis(int n)
{
if(path.size() == 2 * n)
{
ret.push_back(path);
return;
}
path += '('; l++;
if(l >= r && l <= n && r <= n) _generateParenthesis(n);
path.pop_back(); l--;
path +=')'; r++;
if(l >= r && l <= n && r <= n) _generateParenthesis(n);
path.pop_back(); r--;
}
}; 
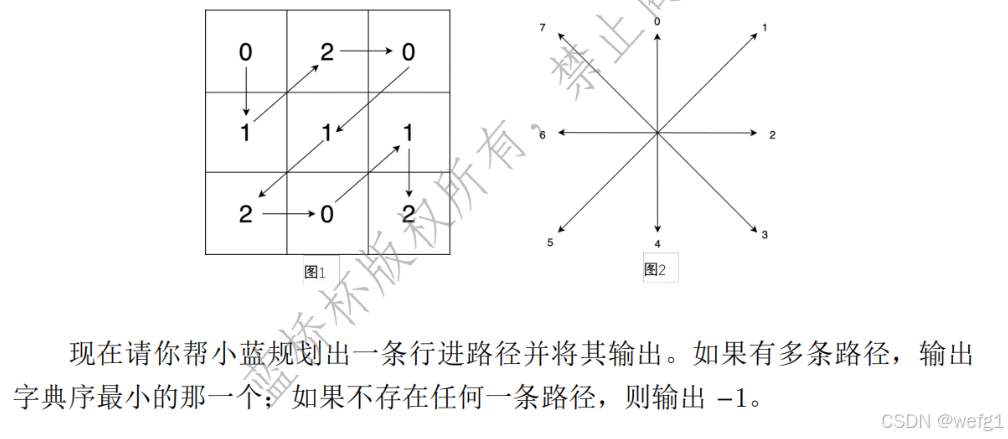
解析:搜索时,从 0 方向开始顺时针搜索,第一次得到的路径一定是字典序最小的。注意剪枝的操作:只要结果数组被更新过,就一直返回。
#include
#include
#include
#include
#include
using namespace std;
vector> map(20, vector(20,0));
vector> vis(20, vector(20,false));
vector path;
int n, k;
int dx[8] = { -1,-1,0,1,1,1,0,-1 };
int dy[8] = { 0 ,1,1,1,0,-1,-1,-1};
pair pos = { 0,0 };
vector ret;
void dfs(vector>& map, vector>& vis, vector& path, pair pos)
{
if (path.size() == n * n - 1 && pos.first == n - 1 && pos.second == n - 1)
{
ret = path;
return;
}
int a = pos.first;
int b = pos.second;
for (int i = 0; i < 8; i++)
{
int x = a + dx[i];
int y = b + dy[i];
if (x >= 0 && x < n && y >= 0 && y < n && !vis[x][y] && (map[x][y] == (map[a][b] + 1) % k))
{
if (i == 1 && vis[a - 1][b] && vis[a][b + 1]) continue;
if (i == 3 && vis[a][b + 1] && vis[a + 1][b]) continue;
if (i == 5 && vis[a + 1][b] && vis[a][b - 1]) continue;
if (i == 7 && vis[a][b - 1] && vis[a - 1][b]) continue;
path.push_back(i);
vis[a][b] = true;
dfs(map, vis, path, { x,y });
if (!ret.empty()) return;
path.pop_back();
vis[a][b] = false;
}
}
}
int main() {
cin >> n >> k;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++) cin >> map[i][j];
}
dfs(map, vis, path,pos);
if (!ret.empty())
{
for (int i = 0; i < ret.size(); i++) cout << ret[i];
}
else cout << -1;
return 0;
} 
解析:每次考虑一行的哪些位置可以放置皇后,这样可以排除皇后在同一横行攻击。在某个位置成功放置皇后之后,将该位置所在的竖列标记为 true,在下一横行考虑哪些位置可以放置皇后时,不考虑在标记为 true 的竖列放置,这样可以排除皇后在同一竖列攻击。接下来要解决皇后在斜线相互攻击,观察发现:数组在同一斜线的元素,它们的下标之和或差是一个定值(斜率为正的,下标之差为定值,但可能为负,要用一个 vis 数组存储斜率为正的斜线的映射,就必须保证那个定值为正,可以将定值加上 n),在成功放置皇后时,可以将该斜线映射的定值标记为 true,在下一横行考虑哪些位置可以放置皇后时,不考虑在标记为 true 的斜线放置,这样可以排除皇后在同一斜线攻击。
class Solution {
public:
vector> ret;
vector board;
bool vis1[12];
bool vis2[24];
bool vis3[24];
int _n;
vector> solveNQueens(int n) {
_n = n;
board.resize(n);
for(int i = 0; i < n; i++)
{
for(int j = 0; j < n; j++)
{
board[i].push_back('.');
}
}
_solveNQueens(0);
return ret;
}
void _solveNQueens(int row)
{
if(row == _n)
{
ret.push_back(board);
return;
}
for(int i = 0; i < _n; i++)
{
if(check(row,i))
{
board[row][i] = 'Q';
vis1[i] = true;
vis2[row - i + _n] = true; // row - i 可能为负数
vis3[row + i] = true;
_solveNQueens(row+1);
board[row][i] = '.';
vis1[i] = false;
vis2[row - i + _n] = false;
vis3[row + i] = false;
}
}
}
bool check(int row,int col)
{
return !vis1[col] && !vis2[row - col + _n] && !vis3[row + col];
}
}; 
class Solution {
public:
bool row[9][10];
bool col[9][10];
bool grid[3][3][10];
bool done;
void solveSudoku(vector>& board) {
// 初始化,记录题目给出的数
for(int i = 0; i < 9; i++)
{
for(int j = 0; j < 9; j++)
{
if(board[i][j] != '.')
{
int num = board[i][j] - '0';
row[i][num] = true;
col[j][num] = true;
grid[i / 3][j / 3][num] = true;
}
}
}
_solveSudoku(board,0,0);
}
void _solveSudoku(vector>& board,int r,int l)
{
if(r == 9) // 所有格子都已经填完了
{
done = true;
return;
}
if(l == 9)
{
_solveSudoku(board,r+1,0);
// 该行填完了,转到下一行的第一个元素
return;
}
// 这个格子是待填格子
if(board[r][l] == '.')
{
// 尝试 1 到 9 的数字是否可以填
for(int n = 1; n <= 9; n++)
{
if(!row[r][n] && !col[l][n] && !grid[r / 3][l / 3][n])
{
// 找到了
board[r][l] = '0' + n; // 填入
row[r][n] = true;
col[l][n] = true;
grid[r / 3][l / 3][n] = true;
// 填下一个格子
_solveSudoku(board,r,l+1);
// 可能下一个格子什么数都填不了,也可能已经填完了
if(done) return; // 已经填完了,一路向上一个格子返回
// 下一个格子什么数都填不了,恢复现场,这个格子换一个数填
board[r][l] = '.';
row[r][n] = false;
col[l][n] = false;
grid[r / 3][l / 3][n] = false;
}
}
// 这个格子什么数都填不了,返回到上一个格子,done == false 说明我还没有填完
if(board[r][l] == '.') return;
}
// 这个格子是题目给出的数,不能填,看看下一个格子
_solveSudoku(board,r,l+1);
// 已经填完了,一路向上一个格子返回
if(done) return;
}
}; 记忆化搜索

如果采用递归的方式解决这道问题,会发现有很多重复的计算:
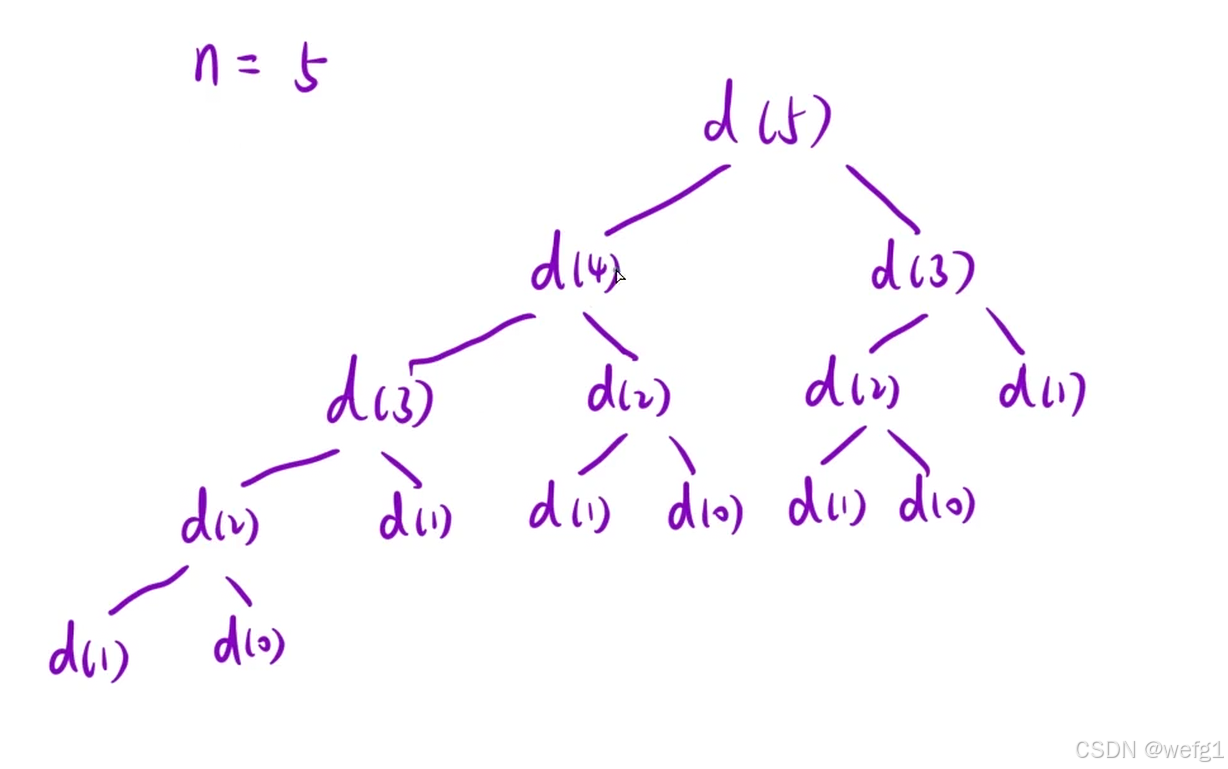
任何解决这个问题?采用记忆化搜索:比如返回 d(3) 时,在备忘录里面记下 d(3) 的结果,下次如果要计算 d(3),就直接使用 d(3) 的结果。
class Solution {
public:
int memo[31];
int fib(int n) {
memset(memo,-1,sizeof(memo));
return dfs(n);
}
int dfs(int n)
{
if(memo[n] != -1) return memo[n];
if(n == 0 || n == 1)
{
memo[n] = n;
return n;
}
memo[n] = dfs(n - 1) + dfs(n - 2);
return memo[n];
}
};
解析:要知道 (m,n) 到 (1,1) 有多少条路径,可以先求 (m-1,n) 和 (m,n-1) 到 (1,1) 有多少条路径, (m,n) 到 (1,1) 的路径数就是 (m-1,n) 和 (m,n-1) 到 (1,1) 的路径之和。而通过递归展开图可以发现有很多重复的计算,所以可以使用记忆化搜索,把 dfs(m,n) 的结果储存在 二维数组memo[m][n]
class Solution {
public:
int memo[101][101];
int uniquePaths(int m, int n) {
memset(memo,-1,sizeof(memo));
return dfs(m,n);
}
int dfs(int m, int n)
{
if(memo[m][n] != -1) return memo[m][n];
if(m == 1 || n == 1)
{
memo[m][n] = 1;
return 1;
}
memo[m][n] = dfs(m - 1, n) + dfs(m,n - 1);
return memo[m][n];
}
};
 浙公网安备 33010602011771号
浙公网安备 33010602011771号