
【即插即用模块】SCI1区 | CNN为什么不能捕获长距离特征?双坐标注意力牛在哪:平均+最大池化并行,涨点必备,SCI保二区争一区!彻底疯狂!!! - 指南
0 论文信息
- 论文标题: Flora-NET: Integrating dual coordinate attention with adaptive kernel based convolution network for medicinal flower identification
- 中文标题:Flora-NET:融合双坐标注意力与自适应核卷积网络的药用花卉识别
- 论文链接
- 论文代码
- 论文出处:Computers and Electronicsin Agriculture
1 论文概述
药用花卉在医疗、制药、化妆品等领域具有重点价值,且对保护生物多样性至关重要,但野外环境下的精准分类面临类内差异大、类间相似性高、背景艰难等挑战。现有深度学习手段(如 CNN、Transformer)难以有效捕捉花瓣纹理、花部结构等复杂特征,且存在局部依赖过强、位置信息丢失等问题。
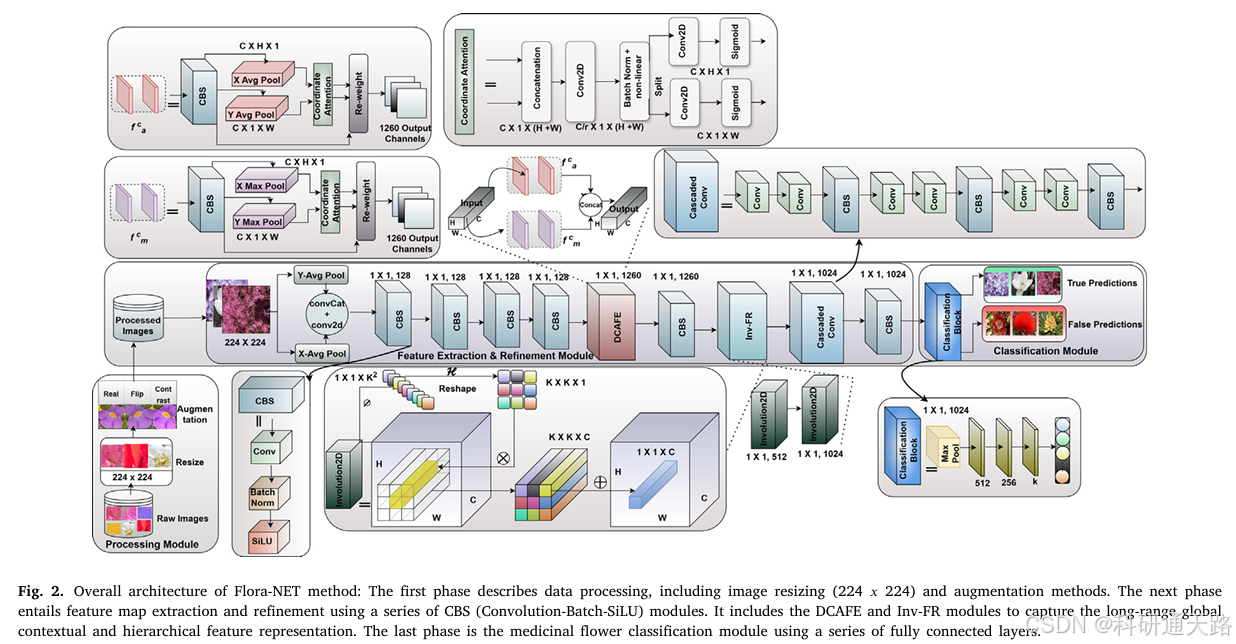
本文提出 Flora-NET 网络,通过两个核心模块实现特征提取与细化:1)双坐标注意力特征提取(DCAFE)模块,采用并行平均池化与最大池化捕捉长距离依赖和位置信息;2)内卷特征细化(Inv-FR)模块,通过串行内卷层自适应调整核权重,强化空间上下文特征。
实验在 Urban Street(17 类、24415 张图像)和 Medicinal Blossom(12 类、18593 张图像)材料集上验证,Flora-NET 在准确率、精确率等 6 项指标上均超越 AlexNet、ResNet 等 SOTA 方法,并通过 5 折交叉验证、消融实验、第三方数据集(IMFI)测试验证了模型的鲁棒性和泛化能力。
2 实验动机
实际需求迫切:药用花卉是传统医学和现代制药的重要原料,80% 发展中国家人口依赖传统草药,但 25% 药用花卉面临灭绝风险,精准识别对资源保护和医疗安全至关重要。
现有方法缺陷:
- CNN 依赖静态核,难以捕捉药用花卉的复杂结构和动态特征,易受背景干扰;
- 注意力机制(如 SE、CBAM)忽视位置信息或通道与空间交互不足,无法建模长距离依赖;
- Transformer 虽能捕捉全局特征,但计算成本高,且丢失局部细节。
技术缺口填补:坐标注意力(CA)擅长位置信息保留,卷积(convolution)擅长自适应空间特征提取,但两者尚未结合应用于药用花卉分类任务,需设计高效融合架构应对领域痛点。
3 创新之处
首次融合双坐标注意力与内卷网络:将坐标注意力与内卷机制结合,同时解除 “位置信息丢失” 和 “静态核适应性差” 的障碍,为药用花卉分类提供新思路。
双坐标注意力特征提取(DCAFE)模块:
并行采用平均池化(捕捉全局上下文)和最大池化(保留关键细节),避免单一池化的信息冗余或丢失;沿水平和垂直方向分解通道注意力图,强化方向敏感性和长距离依赖建模。串行内卷特征细化(Inv-FR)模块:
两层串行内卷层,自适应生成空间依赖的核权重,逐步细化从低维到高维的特征表示;
共享通道间的内卷核,平衡计算复杂度与特征表达能力。强泛化性设计:经过数据增强、超参数调优和跨数据集测试,确保模型在野外复杂环境、不同花卉类别中的适应性。
4 模块介绍
双坐标注意力特征提取模块(Dual Coordinate Attention Feature Extraction, DCAFE)
- 实际意义:①麻烦和噪声背景的影响:实时花卉识别受复杂背景和噪声干扰的影响,导致模型捕获的区分特征较少,分类准确率低下。②现有注意力机制无法捕获长距离和敏感特征:传统注意力机制仅关注通道间信息,忽略位置信息;使用池化操作仅捕获局部相关性,而无法捕获长距离特征。③现有注意力机制的局限性:平均池化会使得最重要特征变得模糊(因取平均值,导致模糊信息聚合),而最大池化能保留显著特征和锐度。
- 实现方式:沿特征图的水平与垂直方向分别进行池化,作为位置信息并建立长程空间依赖;分别基于平均池化与最大池化构建两条并行的坐标注意力分支,捕获全局上下文信息与局部显著判别特征。最终进行拼接,得到方向增强的特征表示。
import torch # 导入PyTorch库
import torch.nn as nn # 导入PyTorch神经网络模块
import math # 导入数学库
import torch.nn.functional as F # 导入PyTorch函数式API
class CoordAttMeanMax(nn.Module):
# 初始化函数,定义模型参数
# inp: 输入通道数
# oup: 输出通道数
# groups: 分组数,用于计算中间通道数
def __init__(self, inp, oup, groups=32):
super(CoordAttMeanMax, self).__init__() # 调用父类初始化函数
# 定义高度方向的均值池化层,输出形状为 [N, C, H, 1]
self.pool_h_mean = nn.AdaptiveAvgPool2d((None, 1))
# 定义宽度方向的均值池化层,输出形状为 [N, C, 1, W]
self.pool_w_mean = nn.AdaptiveAvgPool2d((1, None))
# 定义高度方向的最大值池化层,输出形状为 [N, C, H, 1]
self.pool_h_max = nn.AdaptiveMaxPool2d((None, 1))
# 定义宽度方向的最大值池化层,输出形状为 [N, C, 1, W]
self.pool_w_max = nn.AdaptiveMaxPool2d((1, None))
# 计算中间通道数,确保不小于8
mip = max(8, inp // groups)
# 定义均值池化分支的第一个卷积层,降维操作
self.conv1_mean = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
# 定义均值池化分支的批归一化层
self.bn1_mean = nn.BatchNorm2d(mip)
# 定义均值池化分支的第二个卷积层,升维操作
self.conv2_mean = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
# 定义最大值池化分支的第一个卷积层,降维操作
self.conv1_max = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
# 定义最大值池化分支的批归一化层
self.bn1_max = nn.BatchNorm2d(mip)
# 定义最大值池化分支的第二个卷积层,升维操作
self.conv2_max = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
# 定义ReLU激活函数
self.relu = nn.ReLU(inplace=True)
# 前向传播函数
def forward(self, x):
identity = x # 保存输入特征图,用于残差连接
n, c, h, w = x.size() # 获取输入特征图的形状:[N, C, H, W]
# 均值池化分支
x_h_mean = self.pool_h_mean(x) # 高度方向均值池化,形状变为 [N, C, H, 1]
x_w_mean = self.pool_w_mean(x).permute(0, 1, 3, 2) # 宽度方向均值池化并转置,形状变为 [N, C, W, 1]
y_mean = torch.cat([x_h_mean, x_w_mean], dim=2) # 在高度维度拼接,形状变为 [N, C, H+W, 1]
y_mean = self.conv1_mean(y_mean) # 卷积降维,形状变为 [N, mip, H+W, 1]
y_mean = self.bn1_mean(y_mean) # 批归一化
y_mean = self.relu(y_mean) # ReLU激活
x_h_mean, x_w_mean = torch.split(y_mean, [h, w], dim=2) # 拆分回高度和宽度方向的特征
x_w_mean = x_w_mean.permute(0, 1, 3, 2) # 转置宽度特征,恢复形状 [N, mip, 1, W]
# 最大值池化分支
x_h_max = self.pool_h_max(x) # 高度方向最大值池化,形状变为 [N, C, H, 1]
x_w_max = self.pool_w_max(x).permute(0, 1, 3, 2) # 宽度方向最大值池化并转置,形状变为 [N, C, W, 1]
y_max = torch.cat([x_h_max, x_w_max], dim=2) # 在高度维度拼接,形状变为 [N, C, H+W, 1]
y_max = self.conv1_max(y_max) # 卷积降维,形状变为 [N, mip, H+W, 1]
y_max = self.bn1_max(y_max) # 批归一化
y_max = self.relu(y_max) # ReLU激活
x_h_max, x_w_max = torch.split(y_max, [h, w], dim=2) # 拆分回高度和宽度方向的特征
x_w_max = x_w_max.permute(0, 1, 3, 2) # 转置宽度特征,恢复形状 [N, mip, 1, W]
# 生成注意力权重
x_h_mean = self.conv2_mean(x_h_mean).sigmoid() # 高度方向均值注意力权重,形状 [N, oup, H, 1]
x_w_mean = self.conv2_mean(x_w_mean).sigmoid() # 宽度方向均值注意力权重,形状 [N, oup, 1, W]
x_h_max = self.conv2_max(x_h_max).sigmoid() # 高度方向最大值注意力权重,形状 [N, oup, H, 1]
x_w_max = self.conv2_max(x_w_max).sigmoid() # 宽度方向最大值注意力权重,形状 [N, oup, 1, W]
# 扩展注意力权重到原始特征图大小
x_h_mean = x_h_mean.expand(-1, -1, h, w) # 扩展高度均值注意力权重,形状 [N, oup, H, W]
x_w_mean = x_w_mean.expand(-1, -1, h, w) # 扩展宽度均值注意力权重,形状 [N, oup, H, W]
x_h_max = x_h_max.expand(-1, -1, h, w) # 扩展高度最大值注意力权重,形状 [N, oup, H, W]
x_w_max = x_w_max.expand(-1, -1, h, w) # 扩展宽度最大值注意力权重,形状 [N, oup, H, W]
# 应用注意力权重到原始特征图
attention_mean = identity * x_w_mean * x_h_mean # 均值池化分支的注意力输出
attention_max = identity * x_w_max * x_h_max # 最大值池化分支的注意力输出
# 融合两个分支的输出并返回
return attention_mean + attention_max
if __name__ == "__main__":
x = torch.randn(1, 32, 640, 640)
coord_att = CoordAttMeanMax(32, 32)
output = coord_att(x)
print(output.shape)
print(f"输入张量形状:{x.shape}")
print(f"输出张量形状:{output.shape}")
print("科研通天路提醒您:正确代码无误!")
print("祝您科研之路畅通无阻~~~~")5 写作思路
目标检测//小目标检测:①实际问题:①小目标在特征图中,空间占比极低;③深层特征容易被低频背景主导;②目标与背景在颜色、纹理上高度相似。解决方案:引入上述模块,坐标注意力(H/W 分解)沿水平方向与垂直方向建模长程依赖有利于捕捉目标在整行/整列上的结构线索;Avg与Max的并行池化来保留整体上下文,强化小目标的局部强响应;通道拼接得到判别性通道权重。【研究对象可任意替换】
语义分割任务//医学影像分割:①实际问题:在医疗图像领域,常面临复杂背景(如器官重叠、噪声干扰)的挑战,通常涉及长距离依赖关系(如目标边界与周围组织的关联)、位置敏感信息(如病变的具体坐标)、传统注意力机制(如通道注意力),这些问题导致分割准确率低下。解决方案:引入上述模块,借助并行坐标注意力捕获方向和位置敏感的长距离依赖,同时保留噪声鲁棒的上下文信息,使得模型能更好地处理医疗图像的特异性特征,提高分割精度。【研究对象可任意替换】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号