
Flink源码阅读:如何生成StreamGraph - 详解
Flink 中有四种执行图,分别是 StreamGraph、JobGraph、ExecutionGraph 和 Physical Graph。今天我们来看下我们编写的 Flink 程序代码是如何生成 StreamGraph 的。
在开始读代码之前,我们先来简单介绍一下四种图之间的关系和区别。
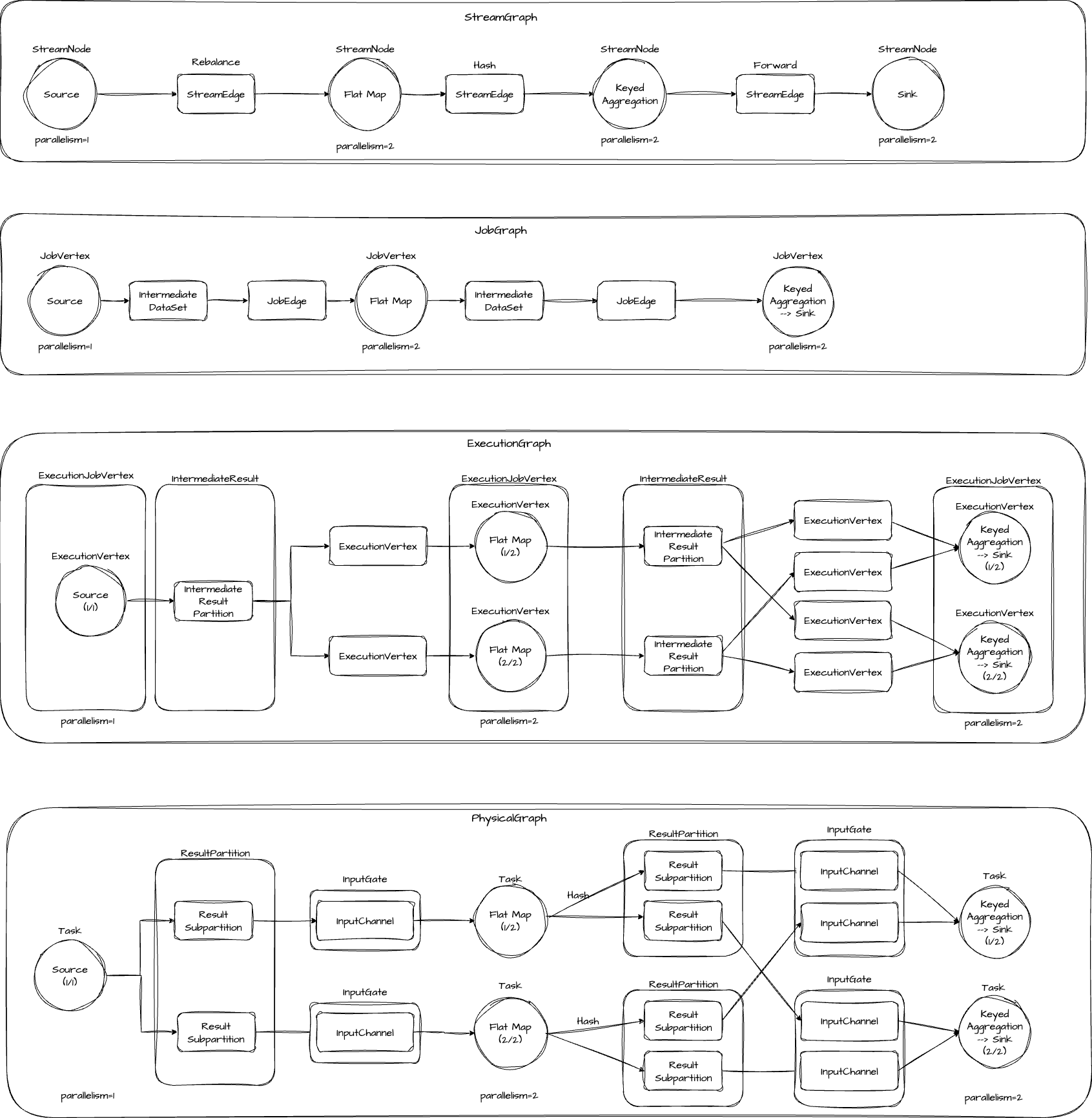
StreamGraph 是根据用户用 Stream API 编写的代码生成的图,用来表示整个程序的拓扑结构。
JobGraph 是由 StreamGraph 生成的,它在 StreamGraph 的基础上,对链化了部分算子,将其合并成为一个节点,减少数据在节点之间传输时序列化和反序列化这些消耗。
ExecutionGraph 是由 JobGraph 生成的,它的主要特点是并行,将多并发的节点拆分。
PhysicalGraph 是 ExecutionGraph 实际部署后的图,它并不是一种数据结构。
StreamExecutionEnvironment
OK,了解了 Flink 四种执行图之后,我们就正式开始源码探索了。首先从 StreamExecutionEnvironment 入手,在编写 Flink 程序时,它是必不可少的一个类。它提供了一系列方法来配置流处理程序的执行环境(如并行度、Checkpoint 配置、时间属性等)。
本文我们主要关注 StreamGraph 的生成,首先是数据流的入口,即 Source 节点。在 StreamExecutionEnvironment 中有 addSource 和 fromSource 等方法,它们用来定义从哪个数据源读取数据,然后返回一个 DataStreamSource (继承自 DataStream),得到 DataStream 之后,它会在各个算子之间流转,最终到 Sink 端输出。
我们从 addSource 方法入手,addSource 方法中主要做了三件事:
1、处理数据类型,优先使用用户执行的数据类型,也可以自动推断
2、闭包清理,使用户传入的 function 能被序列化并发布到分布式环境执行
3、创建 DataStreamSource 并返回
private <OUT> DataStreamSource<OUT> addSource(
final SourceFunction<OUT> function,
final String sourceName,
@Nullable final TypeInformation<OUT> typeInfo,
final Boundedness boundedness) {
checkNotNull(function);
checkNotNull(sourceName);
checkNotNull(boundedness);
TypeInformation<OUT> resolvedTypeInfo =
getTypeInfo(function, sourceName, SourceFunction.class, typeInfo);
boolean isParallel = function instanceof ParallelSourceFunction;
clean(function);
final StreamSource<OUT, ?> sourceOperator = new StreamSource<>(function);
return new DataStreamSource<>(
this, resolvedTypeInfo, sourceOperator, isParallel, sourceName, boundedness);
}现在我们有了 DataStream 了,那如何知道后续要进行哪些转换逻辑呢?答案在 transformations 这个变量中,它保存了后续所有的转换。
protected final List<Transformation<?>> transformations = new ArrayList<>();Transformation
我们来看 Transformation 是如何生成和描述 DataStream 的转换流程的。以最常见的 map 方法为例。
public <R> SingleOutputStreamOperator<R> map(
MapFunction<T, R> mapper, TypeInformation<R> outputType) {
return transform("Map", outputType, new StreamMap<>(clean(mapper)));
}它调用了 transform 方法,transform 又调用了 doTransform 方法。
protected <R> SingleOutputStreamOperator<R> doTransform(
String operatorName,
TypeInformation<R> outTypeInfo,
StreamOperatorFactory<R> operatorFactory) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
OneInputTransformation<T, R> resultTransform =
new OneInputTransformation<>(
this.transformation,
operatorName,
operatorFactory,
outTypeInfo,
environment.getParallelism(),
false);
@SuppressWarnings({"unchecked", "rawtypes"})
SingleOutputStreamOperator<R> returnStream =
new SingleOutputStreamOperator(environment, resultTransform);
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}在 doTransform 方法中,就是创建 Transformation 和 SingleOutputStreamOperator(DataStream 的一个子类),然后调用 addOperator 方法将 transform 存到 StreamExecutionEnviroment 中的 transformations 变量中。
每个 Transformation 都有 id、name、parallelism 和 slotSharingGroup 等信息。其子类也记录有输入信息,如 OneInputTransformation 和 TwoInputTransformation。
StreamOperator
我们在调用 map 方法时,会传入一个自定义的处理函数,它也会保存在 Transformation 中。在 Flink 中定义了 StreamOperator 方法来抽象这类处理函数。在 map 方法中,它将我们传入的函数转成了 StreamMap,它继承了 AbstractUdfStreamOperator,同时实现了 OneInputStreamOperator 接口。
StreamOperator 定义了对算子生命周期管理的函数。
void open() throws Exception;
void finish() throws Exception;
void close() throws Exception;
OperatorSnapshotFutures snapshotState(
long checkpointId,
long timestamp,
CheckpointOptions checkpointOptions,
CheckpointStreamFactory storageLocation)
throws Exception;
void initializeState(StreamTaskStateInitializer streamTaskStateManager) throws Exception;OneInputStreamOperator 是 StreamOperator 的子接口。在其基础上增加了对具体元素的处理,主要是对 key 的提取。
default void setKeyContextElement(StreamRecord<IN> record) throws Exception {
setKeyContextElement1(record);
}AbstractUdfStreamOperator 则是提供了对自定义函数生命周期管理的实现。
@Override
public void open() throws Exception {
super.open();
FunctionUtils.openFunction(userFunction, DefaultOpenContext.INSTANCE);
}
@Override
public void finish() throws Exception {
super.finish();
if (userFunction instanceof SinkFunction) {
((SinkFunction<?>) userFunction).finish();
}
}
@Override
public void close() throws Exception {
super.close();
FunctionUtils.closeFunction(userFunction);
}到这里,我们就知道了 Flink 中 DataStream 是如何转换的。处理逻辑保存在 Transformation 中。下面我们来看一组 Transformation 是如何生成 StreamGraph 的。
StreamGraph
生成 StreamGraph 的入口在 org.apache.flink.streaming.api.environment.StreamExecutionEnvironment#generateStreamGraph 。
在 generate 方法中,会遍历所有 Transformation 并调用 transform 方法。在调用节点的 transform 方法之前,会先确保它的输入节点都已经转换成功。
目前定义了以下 Transformation:
static {
@SuppressWarnings("rawtypes")
Map<Class<? extends Transformation>, TransformationTranslator<?, ? extends Transformation>>
tmp = new HashMap<>();
tmp.put(OneInputTransformation.class, new OneInputTransformationTranslator<>());
tmp.put(TwoInputTransformation.class, new TwoInputTransformationTranslator<>());
tmp.put(MultipleInputTransformation.class, new MultiInputTransformationTranslator<>());
tmp.put(KeyedMultipleInputTransformation.class, new MultiInputTransformationTranslator<>());
tmp.put(SourceTransformation.class, new SourceTransformationTranslator<>());
tmp.put(SinkTransformation.class, new SinkTransformationTranslator<>());
tmp.put(GlobalCommitterTransform.class, new GlobalCommitterTransformationTranslator<>());
tmp.put(LegacySinkTransformation.class, new LegacySinkTransformationTranslator<>());
tmp.put(LegacySourceTransformation.class, new LegacySourceTransformationTranslator<>());
tmp.put(UnionTransformation.class, new UnionTransformationTranslator<>());
tmp.put(StubTransformation.class, new StubTransformationTranslator<>());
tmp.put(PartitionTransformation.class, new PartitionTransformationTranslator<>());
tmp.put(SideOutputTransformation.class, new SideOutputTransformationTranslator<>());
tmp.put(ReduceTransformation.class, new ReduceTransformationTranslator<>());
tmp.put(
TimestampsAndWatermarksTransformation.class,
new TimestampsAndWatermarksTransformationTranslator<>());
tmp.put(BroadcastStateTransformation.class, new BroadcastStateTransformationTranslator<>());
tmp.put(
KeyedBroadcastStateTransformation.class,
new KeyedBroadcastStateTransformationTranslator<>());
tmp.put(CacheTransformation.class, new CacheTransformationTranslator<>());
translatorMap = Collections.unmodifiableMap(tmp);
}Flink 会根据不同的 Transformation 类调用其 translateInternal 方法。在 translateInternal 方法中就会去添加节点和边。
streamGraph.addOperator(
transformationId,
slotSharingGroup,
transformation.getCoLocationGroupKey(),
operatorFactory,
inputType,
transformation.getOutputType(),
transformation.getName());
for (Integer inputId : context.getStreamNodeIds(parentTransformations.get(0))) {
streamGraph.addEdge(inputId, transformationId, 0);
}在 addOperator 方法中,它通过调用 addNode 来创建 StreamNode。
protected StreamNode addNode(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
Class<? extends TaskInvokable> vertexClass,
@Nullable StreamOperatorFactory<?> operatorFactory,
String operatorName) {
if (streamNodes.containsKey(vertexID)) {
throw new RuntimeException("Duplicate vertexID " + vertexID);
}
StreamNode vertex =
new StreamNode(
vertexID,
slotSharingGroup,
coLocationGroup,
operatorFactory,
operatorName,
vertexClass);
streamNodes.put(vertexID, vertex);
isEmpty = false;
return vertex;
}在 addEdgeInternal 方法中,对于 sideOutput 和 partition 这类虚拟节点,会先解析出原始节点,再建立实际的边。
private void addEdgeInternal(
Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?> partitioner,
List<String> outputNames,
OutputTag outputTag,
StreamExchangeMode exchangeMode,
IntermediateDataSetID intermediateDataSetId) {
if (virtualSideOutputNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSideOutputNodes.get(virtualId).f0;
if (outputTag == null) {
outputTag = virtualSideOutputNodes.get(virtualId).f1;
}
addEdgeInternal(
upStreamVertexID,
downStreamVertexID,
typeNumber,
partitioner,
null,
outputTag,
exchangeMode,
intermediateDataSetId);
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
exchangeMode = virtualPartitionNodes.get(virtualId).f2;
addEdgeInternal(
upStreamVertexID,
downStreamVertexID,
typeNumber,
partitioner,
outputNames,
outputTag,
exchangeMode,
intermediateDataSetId);
} else {
createActualEdge(
upStreamVertexID,
downStreamVertexID,
typeNumber,
partitioner,
outputTag,
exchangeMode,
intermediateDataSetId);
}
}最后根据两个物理节点创建 StreamEdge 进行连接。
private void createActualEdge(
Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?> partitioner,
OutputTag outputTag,
StreamExchangeMode exchangeMode,
IntermediateDataSetID intermediateDataSetId) {
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
// If no partitioner was specified and the parallelism of upstream and downstream
// operator matches use forward partitioning, use rebalance otherwise.
if (partitioner == null
&& upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner =
dynamic ? new ForwardForUnspecifiedPartitioner<>() : new ForwardPartitioner<>();
} else if (partitioner == null) {
partitioner = new RebalancePartitioner<Object>();
}
if (partitioner instanceof ForwardPartitioner) {
if (upstreamNode.getParallelism() != downstreamNode.getParallelism()) {
if (partitioner instanceof ForwardForConsecutiveHashPartitioner) {
partitioner =
((ForwardForConsecutiveHashPartitioner<?>) partitioner)
.getHashPartitioner();
} else {
throw new UnsupportedOperationException(
"Forward partitioning does not allow "
+ "change of parallelism. Upstream operation: "
+ upstreamNode
+ " parallelism: "
+ upstreamNode.getParallelism()
+ ", downstream operation: "
+ downstreamNode
+ " parallelism: "
+ downstreamNode.getParallelism()
+ " You must use another partitioning strategy, such as broadcast, rebalance, shuffle or global.");
}
}
}
if (exchangeMode == null) {
exchangeMode = StreamExchangeMode.UNDEFINED;
}
/**
* Just make sure that {@link StreamEdge} connecting same nodes (for example as a result of
* self unioning a {@link DataStream}) are distinct and unique. Otherwise it would be
* difficult on the {@link StreamTask} to assign {@link RecordWriter}s to correct {@link
* StreamEdge}.
*/
int uniqueId = getStreamEdges(upstreamNode.getId(), downstreamNode.getId()).size();
StreamEdge edge =
new StreamEdge(
upstreamNode,
downstreamNode,
typeNumber,
partitioner,
outputTag,
exchangeMode,
uniqueId,
intermediateDataSetId);
getStreamNode(edge.getSourceId()).addOutEdge(edge);
getStreamNode(edge.getTargetId()).addInEdge(edge);
}通过 StreamNode 和 StreamEdge,就可以得到所有的节点和边,也就是我们的 StreamGraph 就创建完成了。
总结
本文先介绍了 Flink 的四种执行图以及它们之间的关系。接着又通过源码探索了 StreamGraph 的生成逻辑,Flink 将处理 逻辑保存在 Transformation 中,又由 Transformation 生成了 StreamGraph。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号