

完整教程:Redsi(十)——缓存双写
第一我们先来说一下什么是缓存双写,就是我们利用redis的情况下一定会利用一个持久化的数据库,最典型的就是redis+mysql的组合,使用他们俩就一定会存在数据不一致的情况,我们为了业务要求必须保证最终一致性,因而得我们解决的就是使用什么方法让他们之间的数据尽可能的在最短的时间、最大的吞吐量、最安全的方式下保证数据的一致性。
关于策略就有同步和异步的方式,同步的方式处理速度、并发性能肯定就会受到影响。就是:新增/查询的情况下,假如redis没有就操作数据库,数据库操控做完后再写入redis,之后再把数据返回客户端,修改/删除的情况下,若是redis有就先更新redis,然后再操作数据库再返回客户端,倘若没有就先操作数据库,然后再写入redis,再返回客户端。该就是同步,材料都是一条线上操作的,所以最大的保证了数据的一致性,但异步的方式:新增的情况下,假如没有则先写入redis,然后异步操作数据库,直接返回成功,如果是查询的情况下,redis没有查数据库后,异步写入redis,直接返回客户端,假如是修改的情况下,假如redis有就直接改,接着异步操控数据库,直接返回客户端,如果redis没有的情况下,就操作数据库,然后异步操作redis,直接返回客户端,删除以此类推。异步的方式虽然可以让请求更快,但是容易出现异步操作的难题,这个时候就要求消息队列等操作进行异步重试,这种方式一遍是对数据一致性不高的情况下才使用,不然可能因为数据库的约束导致数据根本无法更新的情况。
缓存击穿、缓存穿透、缓存雪崩
缓存击穿:是指某个热点数据在缓存失效的瞬间,大量并发请求同时访问该信息,导致所有请求打到数据库。
缓存穿透:指查询的数据在缓存和数据库中都不存在,导致每次请求都直接打到数据库。
缓存雪崩:是指大量缓存数据在同一时间失效,导致大量请求直接打到数据库,造成数据库压力骤增甚至宕机。
以上这三种情况都可以给我们的数据库造成毁灭性打击(当然要数据量上去才行,mysql还是很能打的),同时也对我们缓存双写造成了影响。就比如新增一条数据发了100w个请求,而且新增的内容都是一样的,不管是同步还是异步都会有这个问题,这个时候redis肯定是没有的,那么都会去操作数据库,那么就会有100w个请求mysql,其实新增操作只有一个,但mysql的性能压力却被放大了100w倍,这个是十分严重的问题,而且,同步方式操作完数据库后又会重复更改redis,这也会导致redis压力增加。异步倒是没有这种情况,因为异步是先更新reids的,而且redis读写线程是原子的、阻塞的。
双检加锁
那为了解决该挑战我们行采用双检加锁的方法来防止上面提到的问题,保证redis和mysql不会因为大量请求而导致的压力过大。
这个双检就是指的就是检查两次,这个加锁指的就是对数据库操作加锁,还是以我们的新增为例子,假设100w条请求同时访问,那么第一遍查询redis都没有,然后需要操作数据库,但是不同的就是这个数据库是上锁的,不管你多少个人肯定有一个人先拿到,再操作数据库之前再检查一遍redis如果有就直接返回了,没有再执行数据库,操作数据库搞定后写入redis,释放这个锁。等到下一个人持有这个锁的时候,先查redis发现有了,直接返回了同时释放了这个锁。
这样就克服了缓存双写的问题,而且对于处理的时间并没有慢多少,最耗时间的就是运行数据库,但是这个执行只有一次,所以还是毫秒级的,性能影响不大。
缓存双写数据一致性策略
先更新数据库,再更新缓存错的。就是:一般情况下我们都是以数据库的资料为准,redis为辅的,但是这种策略并不能保证redis的一致性,比如我们的多线程情况下,大家都知道我们的cpu是一个轮询处理的,故而并不能保证前后顺序,假如A修改了数据库值为100成功了,这个时候B修改数据为80,然后B更新了redis80,A再更新redis100,那么这个数据就
先更新redis,再更新数据库:错误的。就是假如A修改了redis为100,B修改redis为80,B修改数据库80,A修改数据库为100,那么该时候内容也是错的。redis数据是80
先删除缓存,再更新数据库:redis旧数据就是假如A删除了rediskey,接着B请求了key发现没有去mysql查,然后A修改数据库,B更新redis,这个时候数据也是错的,还
我们的第二次删除可能失败,那么我们怎么保证一定成功呢?要么使用消息队列进行持久化并重试,要么利用看门狗机制。就是我们行运用延迟双删这个机制来预防这种情况,其实很好理解就是删除2次,A先删除一次,然后操作数据库成功后,等待一会,然后再删除一次,这样就能保证数据的正确了,这个等待谁呢?就是等待B线程写入redis,因为这个B写入的是旧数据,所以我们只要把他删除了,就能保证我们下一次查询会走数据库,保证数据的正确性,而且我们的第二次删除一般都是视野异步的方式,因为这样不会影响线程的吞吐量。那怎么知道我们需要延迟多久呢?有几种办法,一种就是经过实际测量业务操作的耗时来确定延迟时间,比如我们部署测试库进行压力测试,随后得到合理的等待时间,还有就是动态监测的方法,比如我们写一个定时任务,定时执行监测技巧然后写入到静态文件或者数据库中。另外就
先更新数据库,再删除缓存:假如A在操作数据库,B读取了redis中的素材/或者读取了mysql中的旧资料写入redis,A操作成功,A删除redis数据,这样即使也有部分数据是错误的,也就是在A没有成功修改删除的情况下其他线程读的都是旧内容,但是相对于上三种来说对程序的影响是最小的,因为起码保证了后续的数据都是正确的。该就是最终一致性,没办法保证redis和mysql的强一致性的,除非我们牺牲吞吐量那么这个系统就太卡啦也不现实。
canal
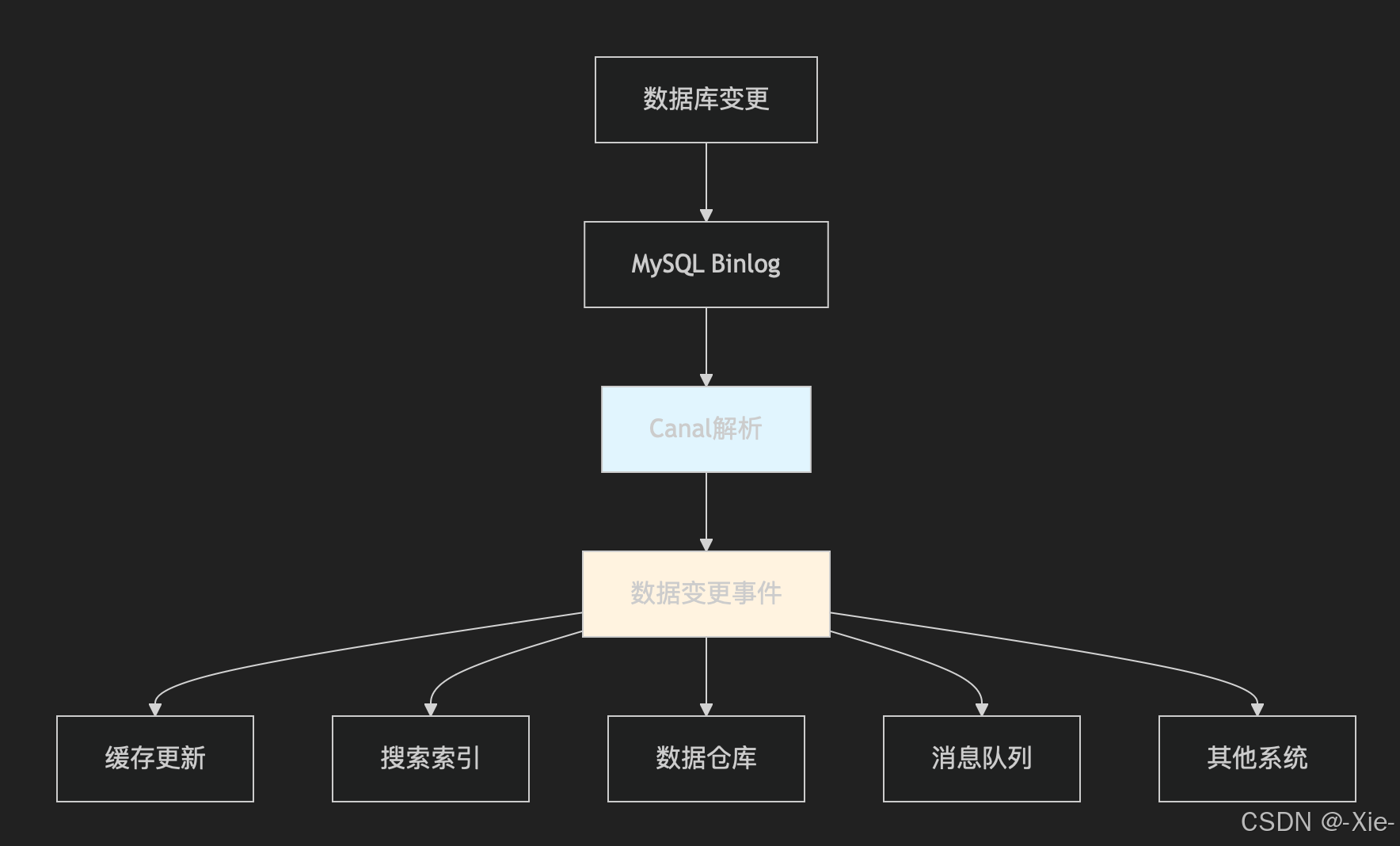
实时监听数据库变更,并将数据变更事件推送给下游系统,实现数据同步解耦和环境架构优化。就拿我们上面的先更新数据库,再删除缓存的方式来说,我们删除redis不一定成功,所以要么就是采用消息队列进行错误重试,要么就回滚事务,让客户端重试,而我们的canal就是把这一块能力进行解耦。
canal的就是基于mysql的主从复制架构,伪装成一个从机,然后监听主机的binlog文件,要是文件修改了,那么就把修改的内容推送到其他从机,然后再解析binlog中修改的内容,去删除redis缓存,随后失败了就放入消息队列就行重试,这样既允许把功能模块进行解耦也可以保证redis的数据成功删除,当然canal的功能还有很多,这里就不多说了,怎么使用怎么设置也不是本篇的内容了,想知道的小伙伴自行查找吧。
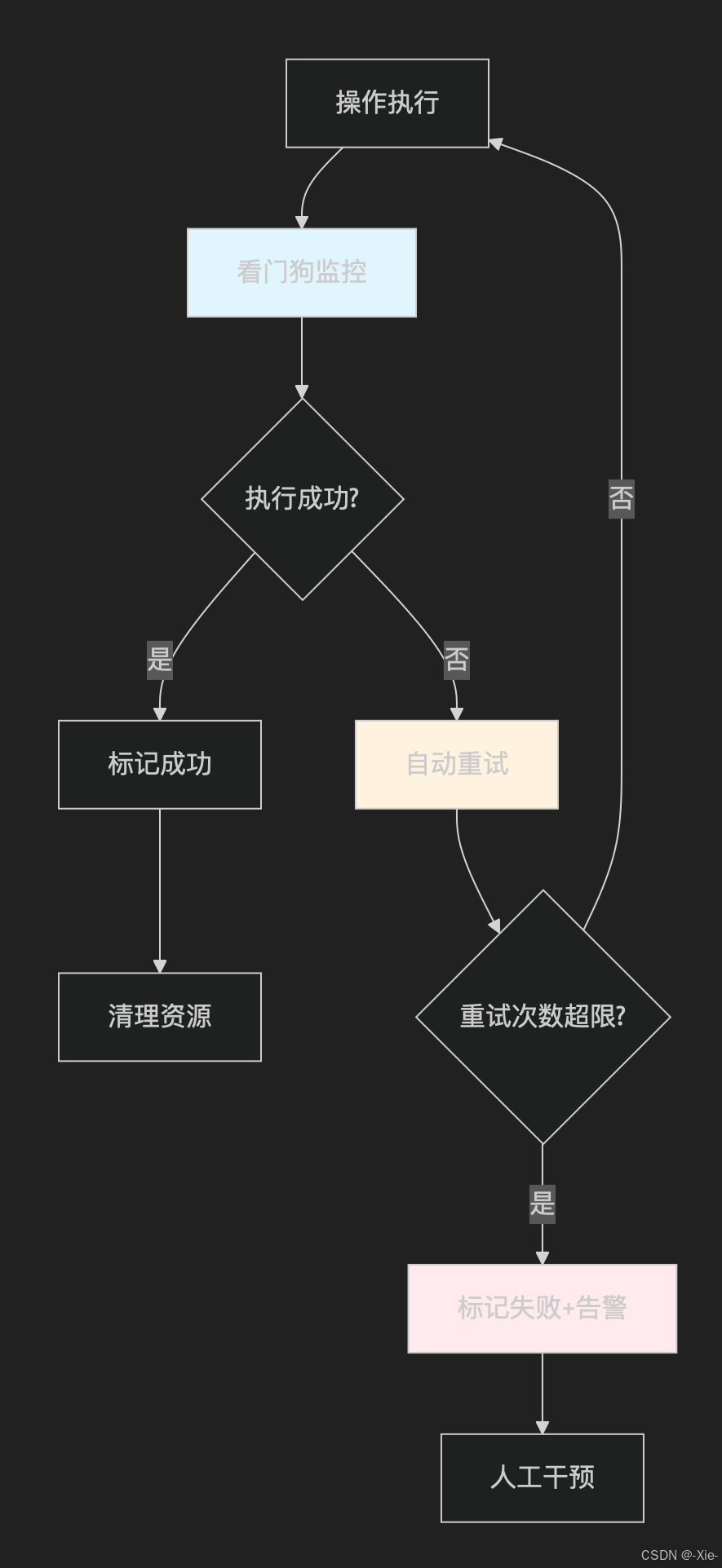
看门狗(Watchdog)
看门狗是一种可靠性保障机制适用场景对比:就是,借助监控、重试、超时控制等手段,确保关键操作的执行成功。他其实和canal有点类似,区别就是看门狗是只看任务执行成功没有,而canal只看binlog更新没有,看门狗用到的地方不止延迟双删,而且把延迟双删的第一次删除去掉,不就是我们的第4种双写方案,也就是说延迟双删也行使用cana,下面
场景 | 看门狗更适合 | Canal更适合 | 理由 |
|---|---|---|---|
简单业务 | ✅ 推荐 | ❌ 过度设计 | 架构简单,快速实现 |
大型系统 | ⚠️ 可用的 | ✅ 推荐 | 解耦架构,易于维护 |
高一致性要求 | ⚠️ 需要复杂实现 | ✅ 天然支持 | 基于事务日志 |
实时性要求高 | ✅ 延迟低 | ⚠️ 有解析延迟 | 直接操作更快 |
技术团队强 | ✅ 都可选 | ✅ 更推荐 | 长期收益大 |
现有系统改造 | ✅ 侵入小 | ⚠️ 改造大 | 逐步迁移容易 |
看门狗的执行机制:就是这个
总结
本篇首要针对缓存双写的解释以及缓存双写的策略和方法进行介绍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号