

从零构建高性能KV存储服务器:架构设计与实现细节 - 指南
目录
a commandExecutor.h/commandExecutor.cc
一 项目背景
kv存储是一种数据存储模型,广泛用于缓存,配置,计数器,队列,锁等。如Redis就被广泛用于网络缓存。
本项目使用的环境与技术栈
编程环境:
2G2核 Linux 云服务器,Xshell + VScode远程连接编码。makefile构建项目
技术栈:
C/C++基础,C++11新特性(智能指针,lambda表达式,函数包装器function等),Socket编程,epoll + ET模型 + Reactor模式,策略模式,数组/哈希表/红黑树/链表等基础数据结构
二 项目设计
本项目采用高内聚,低耦合将代码分为多个模块:
网络模块:
主要用于管理网络并发连接,读取客户端请求发送给解析模块处理,将最后的处理结果发送给客户端。采用 epoll ET模型 + Reactor模式管理并发连接。并且通过注册fd相对应的回调方法进行快速响应。
协议与数据解析模块:
本模块根据自定义协议处理来自网络模块的数据。对网络请求进行验证和检查,将符合协议的请求序列化为完整请求发送给数据存储模块。然后将存储模块返回的结果发送给网络模块。
数据存储引擎模块:
本模块根据解析模块发送的请求执行对应的回调方法。存储引擎包含,数组,哈希表,红黑树,LRUCache。通过策略模式,服务器启动时候能够自行选择存储引擎以面对不同的场景需求。
支持的方法如下:
SET key value :将key-value键值对插入服务器中,key不存在直接插入,key存在就更新
GET key :获取key所对应的value,key不存在返回NO EXIST
DEL key :删除key和key对应的value,key不存在返回NO EXIST
MOD key value:修改key所对应的value,key不存在返回NO EXIST
SIZE :获取存储数据的数量
数据流程图如下:

代码模块图如下:

三 核心模块说明⭐
3.1 网络模块
a Socket.hpp
首先将Socket编程提供的接口进行简单封装,这样方便我们编写服务器代码。封装的接口有socket,bind,listen,accept。代码如下:
#pragma once
#include
#include
#include
#include
#include
#include
const int gbacklog = 128;
class mySocket
{
public:
// 1.构建tcp socketfd
static int creatSockfd()
{
// 创建socketfd
int sockfd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, 0);
return sockfd;
}
// 2.bind绑定端口
static void Bind(int sockfd, int port)
{
struct sockaddr_in serveraddr;
memset(&serveraddr, 0, sizeof(serveraddr));
// 设置地址的信息(协议,ip,端口)
serveraddr.sin_family = AF_INET;
serveraddr.sin_addr.s_addr = htonl(INADDR_ANY); // 绑定任意网卡ip,通常我们访问某一个IP地址是这个服务器的公网网卡IP地址
serveraddr.sin_port = htons(port); // 注意端口16位,2字节需要使用htons。不可使用htonl
if (bind(sockfd, (const sockaddr *)(&serveraddr), sizeof(serveraddr)) < 0)
{
perror("sock bind err");
exit(-1);
}
std::cout << "sock bind success" << std::endl;
}
// 3. listen监听,让打开的sock这个"文件"去监听来自网络的请求。用于获取新的网络连接
static void Listen(int sockfd, int maxaccept)
{
if (listen(sockfd, maxaccept) == -1)
{
perror("sock listen err");
exit(-1);
}
std::cout << "sock listen success" << std::endl;
}
// 4 accept创建sockfd用于传输数据
static int Accept(int listenfd, std::string &clientIp, uint16_t &clientPort, int &err)
{
// 获取新fd用于通信
struct sockaddr_in clientaddr;
memset(&clientaddr, 0, sizeof(clientaddr));
socklen_t len = sizeof(clientaddr);
// std::cout << "accept start " << listenfd << std::endl;
int sockfd = accept(listenfd, (struct sockaddr *)&clientaddr, &len);
// 需要处理错误 EAGAIN 和 EINTER
err = errno;
clientIp = inet_ntoa(clientaddr.sin_addr);
clientPort = ntohs(clientaddr.sin_port);
return sockfd;
}
}; 代码细节:
由于本项目使用epoll + 边缘触发ET模式,所有在创建listenfd时候需要将其设置为 SOCK_NONBLOCK。即设置为非阻塞,减少epoll wait唤醒。
同上,ET模式需要处理错误码EAGAIN/EINTER,所以需要在accept时候给Acceper返回一个错误码用于处理
b connItem.hpp
这部分代码主要用于管理 fd 和对应的回调函数,以及每一个连接的收发用户缓冲区。这样在某一个fd就绪后,就能根据注册的回调函数执行对应的方法(reader/sender/accpeter)。
#pragma once
#include
#include
// 管理网络连接信息和缓冲区的结构体
class tcpServer;
struct connItem;
using func_t = std::function; // 使用函数包装器,当然也可以使用函数指针
// typedef void (*func_t)(connItem *);
struct connItem
{
// 构造函数
connItem(int sockfd = -1, tcpServer *tcsvptr = nullptr)
: _sockfd(sockfd), _tcsvptr(tcsvptr) {}
// 用于注册该连接的对应的读写异常回调方法
void Register(func_t recver = nullptr, func_t sender = nullptr, func_t execpter = nullptr)
{
_recver = recver;
_sender = sender;
_execpter = execpter;
}
// 文件描述符和读写缓冲区
std::string _inbuffer;
std::string _outbuffer;
// 这个连接对应的读写异常方法
func_t _recver;
func_t _sender;
func_t _execpter;
// 执行服务器的回调指针
tcpServer *_tcsvptr;
int _sockfd;
}; 注意:在connItem中有着用户级缓冲区 inbuffer/outbuffer。所以该结构体是网络层和数据协议解析层的桥梁。
c TcpServer.hpp
这部分代码是服务器的主体代码。
首先看看成员变量:
// 如果要同时监听多个端口,就需要维护每一个sockfd与对应端口的信息
std::unordered_map _listensock_fds;
int _epfd; // epollfd
epoll_event *_revents; // 返回事件的列表
std::unordered_map _connlist{}; // 用于快速查找fd和对于的连接结构体conn
func_t _service = kvstoreTask; // 处理kv请求和响应的函数 _listensock_fds是一个哈希表,用于维护fd和其对应的端口。为什么要这个?因为有时候一个端口并没能满足我们的要求。比如 一个端口连接数过多服务器处理不过来,一个端口的最大连接数是限定的,使用不同的端口去执行不同的任务等.....
_epfd,_revents 这个不用多说吧?使用epoll必须要的,后者其实使用vector管理更好,使用vector就能动态增长了。
_connfdlist,这个是用于管理所有的fd和对应的连接管理对象conn的。这样在事件响应的时候我们可以根据fd快速找到对应的conn然后执行注册的方法
kvstoreTask,是连接解析模块的桥梁,当接收数据后就使用这个回调函数去处理数据。
然后是这两个初始化函数:addListenPort init
// 增加监听的端口
void addListenPort(int port)
{
// 服务器初始化,在creat中已经设置为非阻塞了
int listensock = mySocket::creatSockfd();
// 设置端口复用,保证服务器退出后能够快速bind
int opt = 1;
setsockopt(listensock, SOL_SOCKET, SO_REUSEPORT, &opt, sizeof(opt));
mySocket::Bind(listensock, port);
mySocket::Listen(listensock, gbacklog);
// 将listensock 与 对应端口添加到哈希表中
_listensock_fds.insert(std::make_pair(listensock, port));
}
// 初始化到监听即可
void init()
{
// epoll初始化,返回事件集合初始化
_epfd = epoll_create(1);
_revents = new struct epoll_event[fdnums];
// 遍历哈希表,将所有的listenfd 与 port进行 关心
if (_listensock_fds.empty())
{
std::cerr << "没有设置监听端口!" << std::endl;
exit(-1);
}
for (auto &kv : _listensock_fds)
{
AddConnList(kv.first, EPOLLIN | EPOLLET, [this](connItem *conn)
{ this->Accepter(conn); }, nullptr, nullptr);
}
}前者就是用于增加监听的端口的,注意用setsockopt设置端口复用,这样即便服务器关闭后处于TimeWait,也能快速启动服务器
后者就是epoll的初始化和和设置listensock的回调方法,注意设置EPOLLET使用ET模式
事件派发器
// 事件派发器
void Dispatcher()
{
printf("Dispatcher start\n");
while (true)
{
int n = epoll_wait(_epfd, _revents, fdnums, -1);
// 遍历就绪队列,epoll只会返回真的就绪的事件。不会返回无效事件,减少遍历
for (int i = 0; i < n; i++)
{
int connfd = _revents[i].data.fd;
uint32_t events = _revents[i].events;
// 哈希表中该连接没有删除
if (_connlist.count(connfd))
{
// 不要使用if elseif else,因为同一个事件有可能读写事件都就绪了
if ((events & EPOLLIN) && _connlist[connfd]->_recver != nullptr) // 回调执行fd对应读事件
_connlist[connfd]->_recver(_connlist[connfd]);
if ((events & EPOLLOUT) && _connlist[connfd]->_sender != nullptr) // 回调执行fd对应写事件
_connlist[connfd]->_sender(_connlist[connfd]);
}
}
}
printf("Dispatcher over\n");
}这是服务器的主循环,不断根据epollwait返回的就绪fd。在哈希表中判断有无这个fd,存在的话去除调用fd对应conn中的方法。
Accepter/Recver/Sender。分别是listensock的读方法(获取链接),普通fd的读写方法。
注意
每一个方法都要处理 EAGAIN和EINTER异常,前者直接break,后者需要continue
在我们的Reader方法,读取数据后需要执行 _service(conn); 由数据解析层处理数据
执行完send后,需要重新关心该事件的读写方法,读是一定的,要不要写需要根据缓冲区有没有数据。
// listenfd 触发EOILLIN执行
void Accepter(connItem *conn)
{
// 1.获取新连接的fd,注意ET模式下,需要死循环一次性将所有数据读取完毕。否则会出现问题
// printf("Accepter start\n");
while (true)
{
std::string clientip;
uint16_t clientport;
int err = 0;
int clientsock = mySocket::Accept(conn->_sockfd, clientip, clientport, err);
// 2.构建新连接的信息表,让epoll关心该事件同时并通过哈希表进行管理。需要使用lambda进行处理类内回调函数
if (clientsock > 0)
{
AddConnList(clientsock, EPOLLIN | EPOLLET, [this](connItem *conn)
{ this->Reader(conn); }, [this](connItem *conn)
{ this->Sender(conn); }, nullptr); // 这里暂时不处理异常事件
// 这里可以给每一个连接客户端发送一份使用说明
printf("Get a new link, info [%s:%d] clientsock[%d]\n", clientip.data(), clientport, clientsock);
}
else
{
// 处理EAGAIN等异常信号
if (err == EAGAIN || err == EWOULDBLOCK)
{
// 没有连接了
// printf("DEBUG Accepter EAGAIN 没有更多连接,此次获取连接结束\n");
break;
}
else if (err == EINTR)
{
// printf("DEBUG Accepter EINTR 还有更多连接需要处理\n");
continue;
}
else
{
// printf("ERRNO Accepter 建立连接失败\n");
break;
}
}
}
// printf("Accepter over\n");
}
// clientfd触发EOILLIN执行
void Reader(connItem *conn)
{
char buffer[1024];
while (true)
{
int count = recv(conn->_sockfd, buffer, sizeof(buffer) - 1, 0);
if (count > 0)
{
buffer[count] = 0;
conn->_inbuffer += buffer;
}
else if (count == 0)
{
// printf("DEBUG Reader recv over\n");
RemoveConn(conn->_sockfd);
return;
}
else
{
// 同理需要处理EAGAIN和EINTER
if (errno == EAGAIN || errno == EWOULDBLOCK)
{
// 无数据可读
// printf("DEBUG Reader EAGAIN\n");
break;
}
else if (errno == EINTR)
{
// printf("DEBUG Reader EINTR\n");
continue;
}
else
{
// printf("ERRNO Reader 建立连接失败\n");
// 关闭套接字和取消epoll关心,然后退出
RemoveConn(conn->_sockfd);
return;
}
}
}
// 接收数据之后,进行解析处理。这里目前只是简单处理,还能进一步优化
// printf("处理客户端请求开始\n");
_service(conn);
// printf("处理客户端请求结束\n");
}
// clientfd触发EOILLOUT执行
void Sender(connItem *conn)
{
while (true)
{
int count = send(conn->_sockfd, conn->_outbuffer.c_str(), conn->_outbuffer.size(), 0);
if (count > 0)
{
// 清空发送的数据,可以进一步优化
conn->_outbuffer.erase(0, count);
// 数据发送完毕
if (conn->_outbuffer.empty())
{
// 此时不可以直接更改事件的关系,因为数据可能还在内核,没有发送到网络
// printf("DEBUG Senderr send over\n");
break;
}
}
else if (count == 0)
{
// 没有数据发送
RemoveConn(conn->_sockfd);
return;
}
else
{
// 同理需要处理EAGAIN和EINTER
if (errno == EAGAIN || errno == EWOULDBLOCK)
break;
else if (errno == EINTR)
continue;
else
{
// 关闭套接字和取消epoll关心,然后退出
RemoveConn(conn->_sockfd);
return;
}
}
}
// 到这里,事件结束了,数据才是真的发送出去了通重新关心该事件的读写
if (conn->_outbuffer.empty())
SetEvent(conn->_sockfd, EPOLLIN | EPOLLET, EVENT_MOD);
else
SetEvent(conn->_sockfd, EPOLLET | EPOLLIN | EPOLLOUT, EVENT_MOD);
}AddConnList:用于初始化conn,注册方法,插入哈希表进行管理conn
SetEvent:epoll_ctl去关心/修改/删除某一方fd对应的事件(EPOLLIN/EPOLLOUT)
RemoveConn:销毁一个Conn所对应的数据,close,delete
// 初始化连接信息和方法,注册到epoll关心列表中,并放入连接信息哈希表中
void AddConnList(int sockfd, uint32_t event, func_t reader, func_t sender, func_t execpter)
{
// ET模式下,将fd设置为非阻塞
int n = SetNonBlock(sockfd);
if (n < 0)
{
printf("SetNonBlock 失败!\n");
exit(-1);
}
// 1.构建连接信息,并注册方法
connItem *conn = new connItem(sockfd, this);
conn->Register(reader, sender, execpter);
// 2.让epoll关心该事件
SetEvent(sockfd, event, EVENT_ADD);
// 3.放入连接信息哈希表中
_connlist.insert(std::make_pair(sockfd, conn));
}
void SetEvent(int sockfd, uint32_t event, int flag)
{
struct epoll_event ev;
ev.data.fd = sockfd;
ev.events = event;
if (flag == EVENT_ADD) // 新增
epoll_ctl(_epfd, EPOLL_CTL_ADD, sockfd, &ev);
else if (flag == EVENT_MOD) // 修改
epoll_ctl(_epfd, EPOLL_CTL_MOD, sockfd, &ev);
else if (flag == EVENT_DEL) // 删除
epoll_ctl(_epfd, EPOLL_CTL_DEL, sockfd, 0);
}
void RemoveConn(int sockfd)
{
auto it = _connlist.find(sockfd);
if (it != _connlist.end())
{
// 从epoll中删除
SetEvent(sockfd, 0, EVENT_DEL);
// 关闭socket
close(sockfd);
// 释放内存
delete it->second;
// 从哈希表删除
_connlist.erase(it);
// printf("连接关闭: fd=%d, 剩余连接数: %zu\n", sockfd, _connlist.size());
}
}d serverEntry.cc
这个代码是服务器的入口,如果我们采用其他网络框架(比如协程/异步IO),只需要将我们的项目入口更改为对应框架的入口即可
3.2 数据解析协议模块
a Task.h/Task.cc
#pragma once
// 这里使用自定制协议
// 处理请求,发送响应
class connItem;
void kvstoreTask(connItem *conn);#include "Task.h"
#include "Protocol.h"
#include "../reactorTcpServer/connItem.hpp" //解析模块与网络模块的交互
#include "../storage/commandExecutor.h" //解析模块与存储模块的交互
// 这里使用自定制协议
// 处理请求,发送响应
void kvstoreTask(connItem *conn)
{
printf("recv :%s\n", conn->_inbuffer.c_str());
// 接收并解析数据,构建请求完整报文。对于非法数据,啥处理都不做
std::string onePackage;
while (ParseOnePackage(conn->_inbuffer, onePackage))
{
// TCP数据会有粘包,所以要解析出一个报文进行处理
// 序列化建请求报文
kvstoreRequest req;
std::string ans;
if (!req.deserialize(onePackage))
{
// 数据错误,解析失败
ans = "ERROR please input:\nSET KEY VALUE\nGET KEY\nDEL KEY\nMOD KEY VALUE\nSIZE\n";
// 发送错误应答,解析下一个报文
conn->_outbuffer = ans;
conn->_sender(conn);
continue;
}
// 可以成功处理请求,解析层保证传入的数据是对的
ans = globalExecutor.execute(req);
// 根据请求,构建响应报文
// printf("ans : %s\n", ans);
// 发送响应
conn->_outbuffer = ans;
conn->_sender(conn);
}
}这部分代码是三个模块交互的地方。网络层通过kvstoreTask处理数据,解析层解析数据后交给存储层的globalExecutor执行对应方法,最后返回桉树交给网络层发送回客户端
b protocol.h/protocol.cc
.h文件
#pragma once
#include
// 解析一份报文
bool ParseOnePackage(std::string &inbuffer, std::string &rcv_text);
// 判断报文是否合法
bool isValidCommand(const std::string &cmd);
// kvstroe请求报文
class kvstoreRequest
{
public:
// 序列化请求报文
void serialize();
// 反序列化请求报文,将一个报文数据反序string列化
bool deserialize(const std::string &onePacPage);
// 判断字符串是否非法,最好在创建时候验证,减少检测消耗
bool isValid();
public:
const std::string &getop() const;
const std::string &getkey() const;
const std::string &getvalue() const;
private:
std::string op;
std::string key;
std::string value;
};
// kvstroe响应报文
class kvstroeResponse
{
public:
// 序列化请求报文
void serialize();
// 反序列化请求报文
void deserialize();
private:
}; 主要是响应与请求结构体的定义,包含序列化和反序列化。以及ParseOnePackage用于获取一份完整报文。
这里并没有过多关注响应报文。因为本项目的返回数据就是简单字符串如OK/ERROR
NO EXIST。
portocol.cc
#include "Protocol.h"
#include
#include
#include
// 解析报文
// 将收到的数据inbuffer中解析为一个个报文
// client -> server
// set key value
// get key
// del key
// mody key value
bool ParseOnePackage(std::string &inbuffer, std::string &rcv_text)
{
#if 1
// 接收数据为空,直接返回
if (inbuffer.empty())
return false;
// 清空上一次的报文
rcv_text.clear();
// 开始解析报文,这里先直接简单处理
rcv_text = inbuffer;
inbuffer.clear();
return true;
#else
// 找到一个报文的\r\n
auto pos = inbuffer.find("\r\n");
if (pos == std::string::npos)
return false;
// 清空之前报文,获取一份新报文
rcv_text.clear();
rcv_text = inbuffer.substr(0, pos);
// 删除缓冲区取出的数据
inbuffer.erase(0, pos + 2);
// 检测报文是否合法
return isValidCommand(rcv_text);
#endif
}
// 判断接收的报文是否合法
bool isValidCommand(const std::string &cmd)
{
// 检测报文是否为空
if (cmd.empty())
return false;
return cmd.find("SET ") == 0 ||
cmd.find("GET ") == 0 ||
cmd.find("DEL ") == 0 ||
cmd.find("MOD ") == 0 ||
cmd.find("SIZE") == 0;
}
//--------------------------------------------Request--------------------------------------------
//--------------------------------------------Request--------------------------------------------
// 序列化请求报文
void kvstoreRequest::serialize() {}
// 反序列化请求报文,将一个报文数据反序string列化
bool kvstoreRequest::deserialize(const std::string &onePacPage)
{
std::vector tokens;
std::string token;
// set key value
std::stringstream ss(onePacPage);
while (ss >> token)
tokens.emplace_back(token);
if (tokens.size() > 3)
return false;
op = tokens[0];
key = tokens.size() > 1 ? tokens[1] : "";
value = tokens.size() > 2 ? tokens[2] : "";
// std::cout << "序列化数据为:" << op << " " << key << " " << value << std::endl;
return isValid();
}
// 判断字符串是否非法,最好在创建时候验证,减少检测消耗
bool kvstoreRequest::isValid()
{
if (op == "SIZE" && key.empty() && value.empty())
return true;
if (key.empty())
return false;
if (op == "SET" || op == "MOD")
return !value.empty();
else if (op == "GET" || op == "DEL")
return value.empty(); // 防止 命令 GET key value 和 DEL key value
return false;
}
const std::string &kvstoreRequest::getop() const { return op; }
const std::string &kvstoreRequest::getkey() const { return key; }
const std::string &kvstoreRequest::getvalue() const { return value; }
//--------------------------------------------Request--------------------------------------------
//--------------------------------------------Request--------------------------------------------
//--------------------------------------------Response--------------------------------------------
//--------------------------------------------Response--------------------------------------------
// 序列化响应报文
void kvstroeResponse::serialize()
{
}
// 反序列化响应报文
void kvstroeResponse::deserialize()
{
}
//--------------------------------------------Response--------------------------------------------
//--------------------------------------------Response-------------------------------------------- 这里我我们主要关注ParseOnePackage解析一个报文,目前有两种方式,一个是直接不处理,另外一个是通过一个分隔符\r\n来区别每一个报文。
使用分隔符来区分报文可以有效处理TCP粘包问题,当然也有更好的方式。比如在每一个报文前面增加一个报文长度+分隔符。
请求的反序列化函数,就是根据每一个请求获取对应的op key value。然后提交给存储层执行对应的方法,注意需要处理错误的请求,如果是错误的请求直接返回false交给函数kvstoretask
3.3 数据存储模块
a commandExecutor.h/commandExecutor.cc
这个代码是用于接收解析模块的请求req,然后执行对应SET/DEL/GET/MOD/SIZE。
#pragma once
#include "../protocol/Protocol.h"
#include "kvStorages.h"
#include
#include
#include
class commandExecutor
{
public:
// 构造函数,用于注册方法
commandExecutor();
// 设置存储引擎
void setStorage(std::unique_ptr kvStoragePtr);
// 执行函数,根据传入的数据执行方法表相应的方法
std::string execute(const kvstoreRequest &req);
private:
// 注册方法表
void registerCommands();
private:
std::unique_ptr _kvStoragePtr;
std::unordered_map> _cmds;
};
// 声明全局的存储引擎和执行器
extern commandExecutor globalExecutor; 这里说明一个各个成员:
_kvStoragePtr:一个智能指针,用于管理存储类的基类。通过多态方式执行不同存储类型所对应的SET/GET等方法
_cmds:一个哈希表,包含了方法名称和对应的回调函数。用于快速查找和执行对应方法
setStorage:用于设置存储引擎,通过基类指针进行修改。使用了多态
registerCommands:用于进一步封装各个存储引擎的SET/GET等方法,这样就能统一的视角看待不同的引擎,方便新增新引擎
execute:用于接收来自解析层的req,然后根据序列化数据执行对应的方法
#include "commandExecutor.h"
// 定义全局存储引擎
commandExecutor globalExecutor;
// 构造函数,用于注册方法,默认使用哈希
commandExecutor::commandExecutor()
: _kvStoragePtr(new HashStorage())
{
registerCommands();
}
// 设置存储引擎
void commandExecutor::setStorage(std::unique_ptr kvStoragePtr)
{
// 注意 unique_ptr是独占智能指针,转移管理权必须使用 std::move
_kvStoragePtr = std::move(kvStoragePtr);
}
void commandExecutor::registerCommands()
{
// 注册方法列表
_cmds["SET"] = [this](const kvstoreRequest &req)
{ return _kvStoragePtr->SET(req.getkey(), req.getvalue()) ? "OK" : "SET FAILED"; };
_cmds["GET"] = [this](const kvstoreRequest &req)
{
const std::string &value = _kvStoragePtr->GET(req.getkey());
return value.empty() ? "NO EXIST" : value;
};
_cmds["DEL"] = [this](const kvstoreRequest &req)
{ return _kvStoragePtr->DEL(req.getkey()) ? "OK" : "NO EXIST"; };
_cmds["MOD"] = [this](const kvstoreRequest &req)
{ return _kvStoragePtr->MOD(req.getkey(), req.getvalue()) ? "OK" : "NO EXIST"; };
_cmds["SIZE"] = [this](const kvstoreRequest &req)
{ return std::to_string(_kvStoragePtr->SIZE()); };
}
// 执行函数,根据传入的数据执行相应的方法
std::string commandExecutor::execute(const kvstoreRequest &req)
{
auto it = _cmds.find(req.getop());
// 解析模块保证传输数据是有效的
// if (it == _cmds.end())
// return "cmd error please input SET GET MOD DEL";
return it->second(req);
} b storage.h/storage.cc
这部分是真正的存储引擎,采用策略模式。创建一个基类storage,其他类型(array,hash,rbtree,lrucache)都继承这个类,并通过虚函数构建属于自己的方法。
#pragma once
#include
#include
#include
storage.cc文件:就是基础的数据操作,没啥好讲的。可以直接去仓库看逻辑
3.4 kvstore.cc
主函数所在,主要是设置存储引擎和启动服务器
#include "storage/commandExecutor.h"
#include
int serverEntry();
// 初始化存储引擎
void initEgineKvstore(const std::string &storage)
{
if (storage == "array")
globalExecutor.setStorage(std::make_unique());
else if (storage == "rbtree")
globalExecutor.setStorage(std::make_unique());
else if (storage == "lru")
globalExecutor.setStorage(std::make_unique());
else
{
printf("未选择或者错误选择存储引擎, 默认使用hash\n");
}
}
int main(int argc, char *argv[])
{
std::string storageType = "hash";
// 初始化存储引擎
for (int i = 1; i < argc; ++i)
{
if ((strcmp(argv[i], "--storage") == 0) && i + 1 < argc)
storageType = argv[++i];
else if (strcmp(argv[i], "--help") == 0)
{
printf("\r\n%s [--storage hash|rbtree|array|lru] [--help]\r\n\r\n", argv[0]);
printf("Default storage engine: hash\r\n\r\n");
return 0;
}
else
{
printf("\r\nUnknown option\r\n\r\n");
printf("KVStore Usage:\r\n%s [--storage hash|rbtree|array|lru] [--help]\r\n\r\n", argv[0]);
return -1;
}
}
printf("初始化存储引擎\n");
initEgineKvstore(storageType);
// 启动服务器,在这里可以选择不同的网络框架。
// 如果想要使用协程网络框架,直接调用Task.h中的kvstoreTask,然后执行相应的交互即可
printf("初始化服务器\n");
serverEntry();
} 四. 项目测试与性能分析
测试的云服务器配置为 2核2G,centos 8
项目构建好后,我们需要对项目进行测试,测试的内容如下:
1 一次完整的流程测试,保证功能正确:
SET name yzc 正常返回 OK
SET key value 正常返回 OK
SIZE 正常返回 2
GET name 正常返回 yzc
MOD name czy 正常返回 OK
GET name 正常返回 czy
DEL name 正常返回 OK
GET name 正常返回 NO EXIST
2 测试项目的QPS平均可以到达多少
3 测试项目的最大并发连接数量
4.1 流程测试
先进行基础测试:
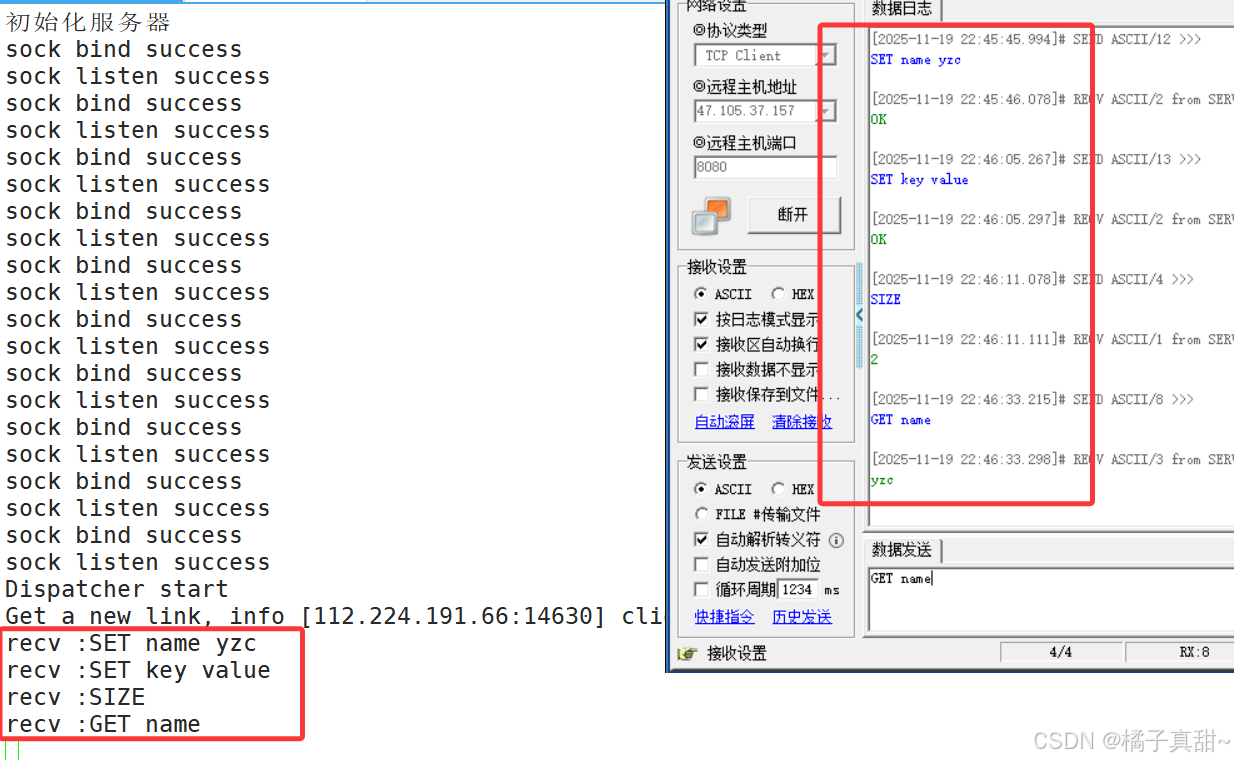
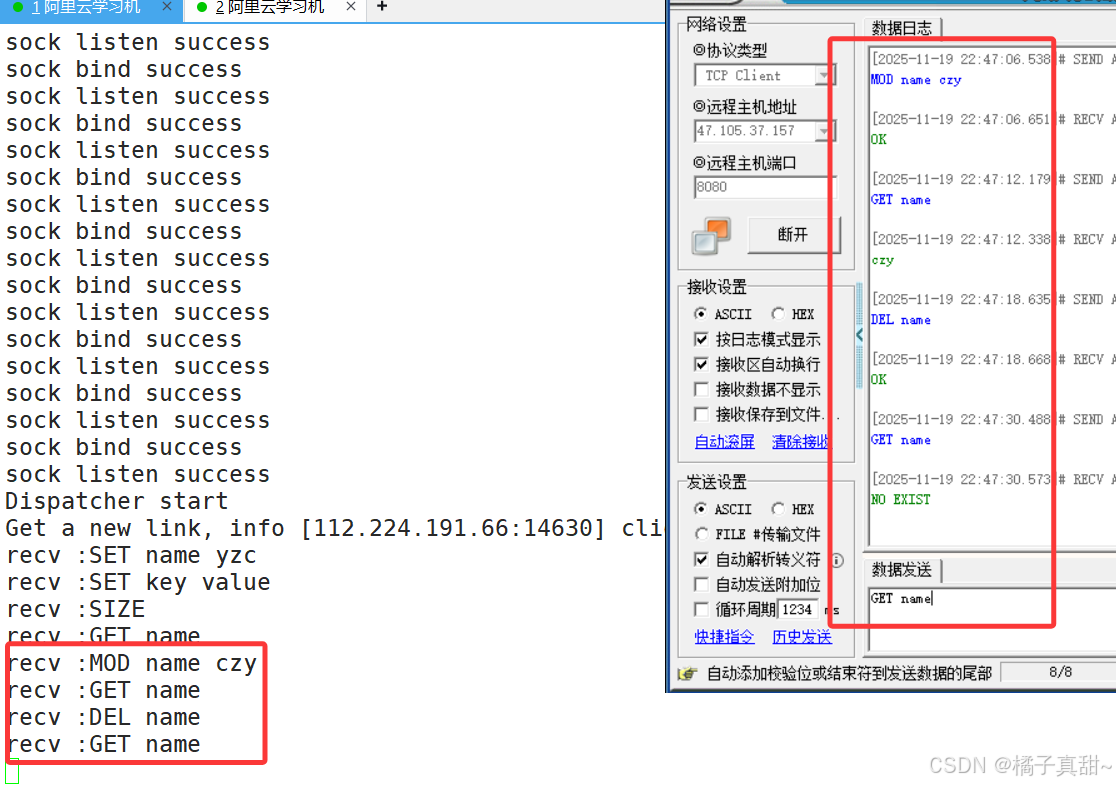
可以看到,一次完整的测试流程并没有问题。
4.2 QPS测试
直接使用仓库Prestandatest中的qpsTest.cc来测试即可。我们存储引擎选择Hash多测试几下取平均值。测试条件为:并发连接数量 * 每连接发送请求数量(SET/GET混合发送)。
基础功能测试: 全部通过
=== 性能测试 ===
并发数: 100
每线程请求数: 5000 (SET+GET)
总请求数: 1000000
测试结果:
总耗时: 29423 ms
总请求: 1000000
成功请求: 1000000
失败请求: 0
成功率: 100%
QPS: 33987
基础功能测试: 全部通过
=== 性能测试 ===
并发数: 100
每线程请求数: 5000 (SET+GET)
总请求数: 1000000
测试结果:
总耗时: 28154 ms
总请求: 1000000
成功请求: 1000000
失败请求: 0
成功率: 100%
QPS: 35518.9
基础功能测试: 全部通过
=== 性能测试 ===
并发数: 200
每线程请求数: 2500 (SET+GET)
总请求数: 1000000
测试结果:
总耗时: 29177 ms
总请求: 1000000
成功请求: 1000000
失败请求: 0
成功率: 100%
QPS: 34273.6
=== 性能测试 ===
并发数: 50
每线程请求数: 10000 (SET+GET)
总请求数: 1000000
测试结果:
总耗时: 27165 ms
总请求: 1000000
成功请求: 1000000
失败请求: 0
成功率: 100%
QPS: 36812.1
=== 性能测试 ===
并发数: 100
每线程请求数: 50000 (SET+GET)
总请求数: 10000000
测试结果:
总耗时: 423004 ms
总请求: 10000000
成功请求: 10000000
失败请求: 0
成功率: 100%
QPS: 23640.4可以看到当请求量为 100w时候,QPS均值在35000。当请求量到1000w时候,QPS降低为 20000+。推测为大量数据导致哈希冲突增多,每一次插入查询消耗变大。
总结如下:
| 测试编号 | 并发数 | 每线程请求数 | 总请求数 | 总耗时(ms) | QPS | 成功率 | 备注 |
|---|---|---|---|---|---|---|---|
| 测试1 | 100 | 5,000 | 1,000,000 | 29,423 | 33,987 | 100% | 基准测试 |
| 测试2 | 100 | 5,000 | 1,000,000 | 28,154 | 35,518 | 100% | 基准测试 |
| 测试3 | 200 | 2,500 | 1,000,000 | 29,177 | 34,274 | 100% | 基准测试 |
| 测试4 | 50 | 10,000 | 1,000,000 | 27,165 | 36,812 | 100% | 最佳性能 |
| 测试5 | 100 | 50,000 | 10,000,000 | 423,004 | 23,640 | 100% | 压力测试 |
4.3 最大并发连接测试
直接使用仓库中的stressConnectionTest进行测试即可。这里我之前测试过很多次,直接使用刚好越过服务器的最大的压力测试。
启动连接压力测试...
存储引擎模式: Hash
=== 真实连接压力测试 ===
目标最大连接数: 30000
测试持续时间: 100 秒
服务器: 127.0.0.1:8080
测试模式: 建立连接 + 持续数据交互 (70% GET, 30% SET)
工作线程数: 50
每线程连接数: 600
[0s] 连接数: 0 | 成功: 0 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[2s] 连接数: 9821 | 成功: 9821 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[4s] 连接数: 14533 | 成功: 14533 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[6s] 连接数: 15257 | 成功: 15257 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[8s] 连接数: 15915 | 成功: 15915 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[10s] 连接数: 16599 | 成功: 16599 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[12s] 连接数: 17253 | 成功: 17253 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[14s] 连接数: 17899 | 成功: 17899 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[16s] 连接数: 18513 | 成功: 18513 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[18s] 连接数: 19130 | 成功: 19130 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[20s] 连接数: 19734 | 成功: 19734 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[22s] 连接数: 20313 | 成功: 20313 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[24s] 连接数: 20870 | 成功: 20870 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[26s] 连接数: 21446 | 成功: 21446 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[28s] 连接数: 22007 | 成功: 22007 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[30s] 连接数: 22521 | 成功: 22521 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[32s] 连接数: 23032 | 成功: 23032 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[34s] 连接数: 23542 | 成功: 23542 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[36s] 连接数: 24044 | 成功: 24044 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[38s] 连接数: 24538 | 成功: 24538 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[40s] 连接数: 25046 | 成功: 25046 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[42s] 连接数: 25519 | 成功: 25519 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[44s] 连接数: 26009 | 成功: 26009 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[46s] 连接数: 26509 | 成功: 26509 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[48s] 连接数: 26963 | 成功: 26963 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[50s] 连接数: 27417 | 成功: 27417 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[52s] 连接数: 27862 | 成功: 27862 | 失败: 0 | 请求: 0 | 请求成功率: 0%
[54s] 连接数: 28232 | 成功: 28232 | 失败: 7 | 请求: 0 | 请求成功率: 0%
[56s] 连接数: 28232 | 成功: 28232 | 失败: 283 | 请求: 0 | 请求成功率: 0%
[58s] 连接数: 28232 | 成功: 28232 | 失败: 558 | 请求: 0 | 请求成功率: 0%
[60s] 连接数: 28232 | 成功: 28232 | 失败: 833 | 请求: 0 | 请求成功率: 0%
[62s] 连接数: 28232 | 成功: 28232 | 失败: 1102 | 请求: 0 | 请求成功率: 0%
[64s] 连接数: 28232 | 成功: 28232 | 失败: 1390 | 请求: 0 | 请求成功率: 0%
[66s] 连接数: 28232 | 成功: 28232 | 失败: 1666 | 请求: 9 | 请求成功率: 100%
[68s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 799 | 请求成功率: 100%
[70s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 1792 | 请求成功率: 100%
[72s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 2792 | 请求成功率: 100%
[74s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 3792 | 请求成功率: 100%
[76s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 4792 | 请求成功率: 100%
[78s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 5792 | 请求成功率: 100%
[80s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 6778 | 请求成功率: 100%
[82s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 7778 | 请求成功率: 100%
[84s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 8778 | 请求成功率: 100%
[86s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 9771 | 请求成功率: 100%
[88s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 10771 | 请求成功率: 100%
[90s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 11771 | 请求成功率: 100%
[92s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 12771 | 请求成功率: 100%
[94s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 13771 | 请求成功率: 100%
[96s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 14767 | 请求成功率: 100%
[98s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 15767 | 请求成功率: 100%
[100s] 连接数: 28232 | 成功: 28232 | 失败: 1768 | 请求: 16752 | 请求成功率: 100%
=== 压力测试结果 ===
总耗时: 102293 ms
最大并发连接数: 28232
失败连接数: 1768
连接成功率: 94.1067%
总请求数: 17752
请求成功率: 100%
平均连接建立速度: 275.992 连接/秒
平均请求QPS: 173.541 请求/秒
=== 结果分析 ===
服务器表现良好 - 接近承载极限单个端口能够维持的最大并发连接上限就是28232,考虑是系统限定导致的。一个连接是一个四元组(源ip,源端口,目的ip,目的端口)。由于我的测试程序和服务器程序都在一台机器上运行,打开的端口是有限制的。然后所有成功的连接稳定性都不错,
如果需要增加测试最大连接数有以下几种方式
1 增加服务器监听的端口,我都服务器就监听了10个端口。(上面测试就一个端口)
2 修改内核中的最文件句柄的最大值,使用ulimit -n 修改能够打开的fd数量
3 使用更多的不同ip地址客户端
五. 项目难点与解决方案
1 网络模块如何有效管理连接进行数据收发和与协议模块交互?
通过自定义连接对象connItem,采用哈希表管理<fd,conn*>能够方便解决这个问题
2 数据解析模块如何有效解析数据,TCP粘包问题如何解决?
通过自定义Respose和Request结构体进行数据的序列化和反序列化,方便有效处理数据的传递。通过分隔符可以有效解决粘包问题
3 存储模块如何将不同的存储引擎适配在一起?
采用策略模式,让所有不同的引擎去继承一个基类。然后在命令执行器cmd中通过依赖注入和函数注册来执行不同存储引擎的对应方法。
六. 收获与反思
技术收获
网络编程:深入理解epoll、Reactor模式
系统设计:从单机到分布式的架构思维
C++进阶:现代C++特性、RAII、智能指针
调试能力:复杂系统的问题定位技巧
工程实践
模块化设计的重要性
文档和代码规范的价值
不足:
缺乏数据持久化
监控指标不够完善
配置化程度可以更高
网络模块能有更高效方式
解析模块的请求与响应,报文解析并不是很完善
这个项目理解了高并发系统设计的复杂性。通过亲手实现每个模块,我对网络编程、内存管理、并发控制有了更深的理解。这不仅是技术的提升,更是工程思维的锻炼。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号