

详细介绍:tensorflow+yolo图片训练和图片识别系统
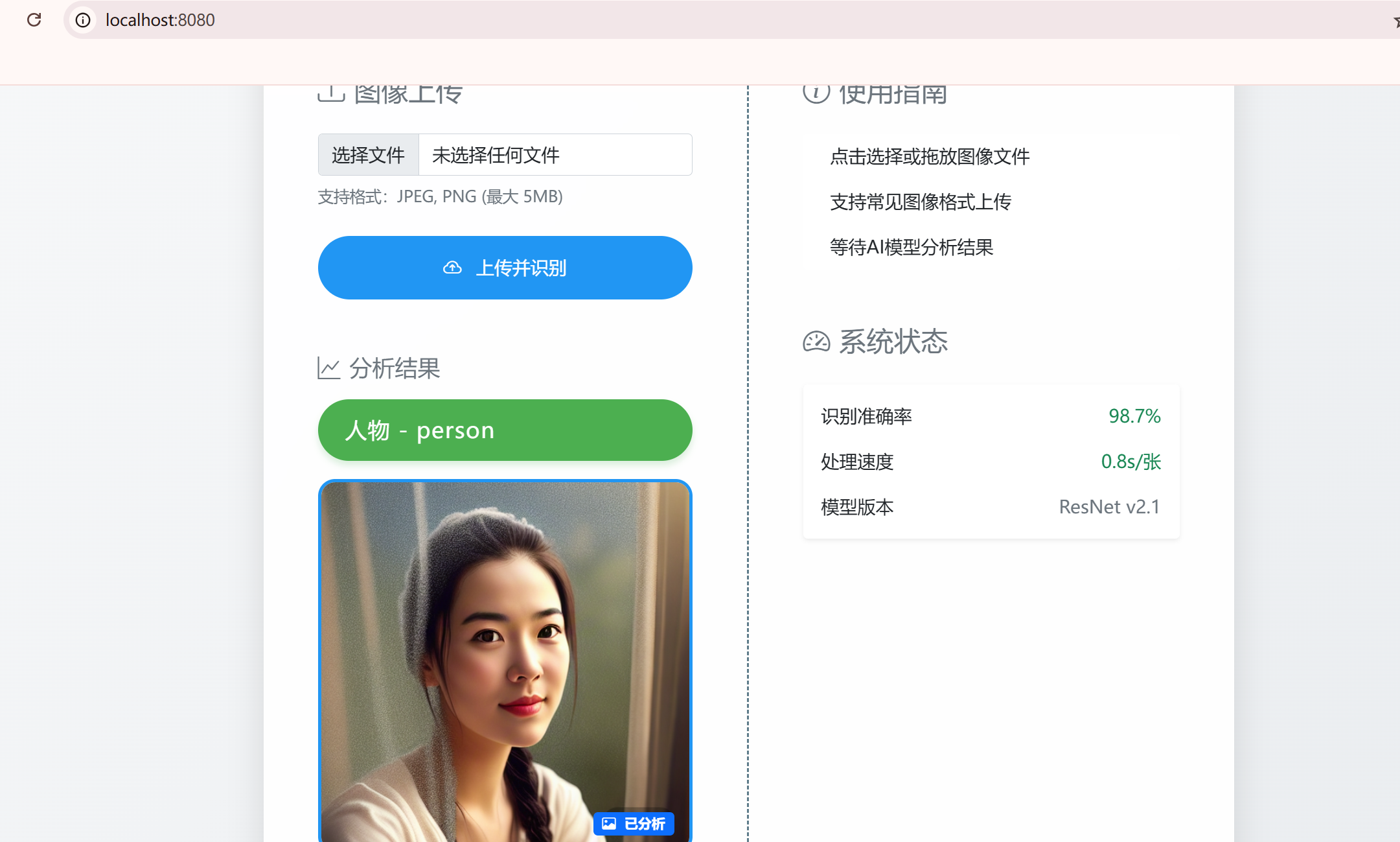
下面我为你介绍如何结合 web、TensorFlow 和 YOLO 构建一个完整的图像训练和识别系统。这套系统能让你通过浏览器上传图片并实时看到识别结果。
系统核心组件与工作原理
这套系统首要包含三个核心部分,它们协同工作的流程可以参考下面的图示:
YOLO目标检测模型:采用YOLOv5或YOLOv8等版本,它们基于PyTorch或TensorFlow实现,能够快捷准确地识别图像中的物体。在系统中,它负责接收处理后的图像并返回检测到的目标类别、位置及置信度。
TensorFlow/PyTorch深度学习框架:给予基础的张量运算和神经网络协助。哪怕YOLOv5基于PyTorch,但可以转换为TensorFlow格式,或在TensorFlow中实现类似功能。
️ 实现步骤与关键代码
1. 环境设置
开始安装所需的依赖库:
pip install tensorflow-cpu torch torchvision opencv-python pillow numpy
# 如果需要GPU支持,安装tensorflow-gpu版本并配置CUDA2. 核心Flask应用与YOLO集成
以下是一个简化的系统核心代码,展示了Flask如何与YOLO模型集成:
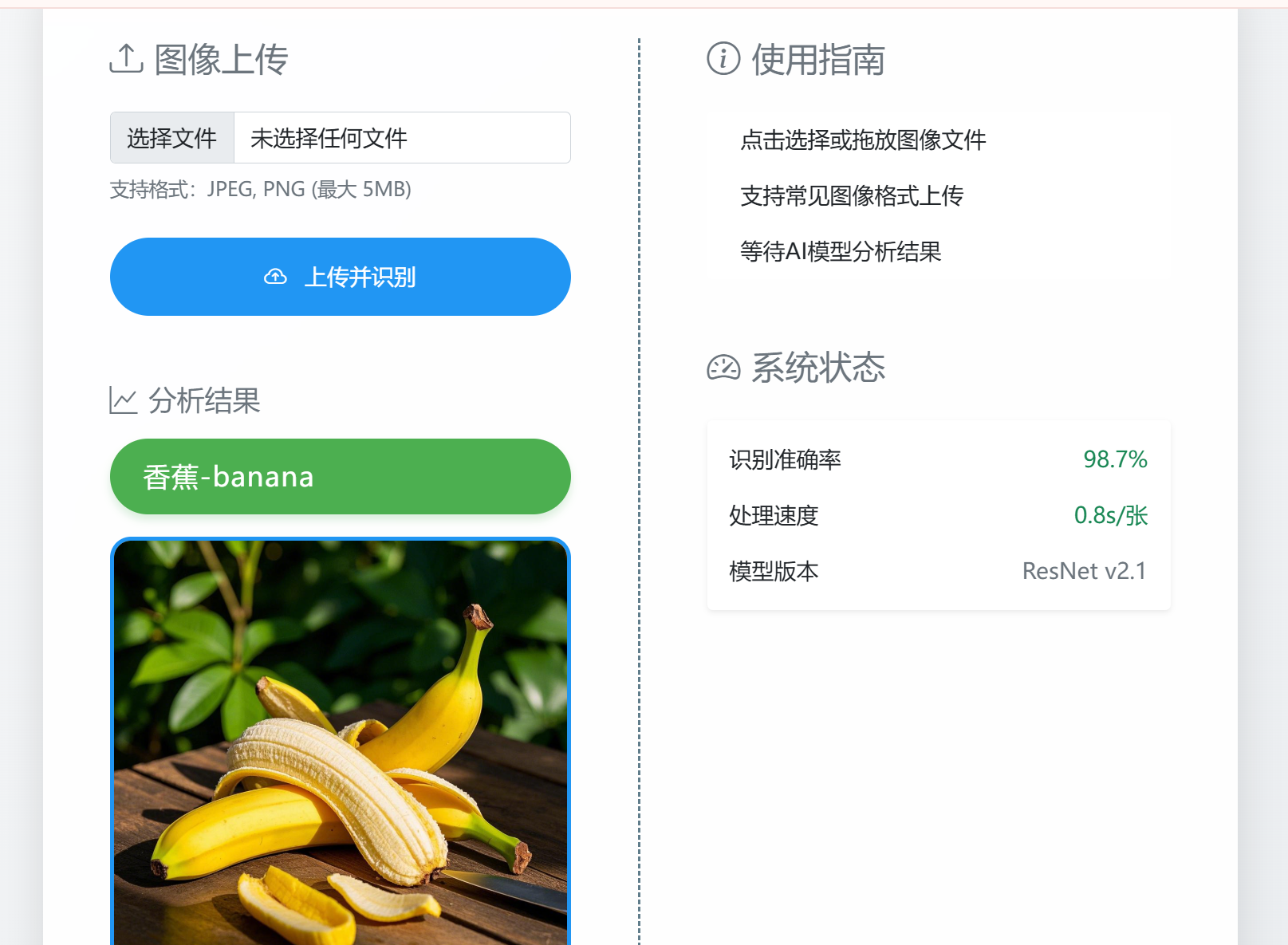
模型训练与优化建议
要训练一个高质量的YOLO模型,需关注以下几个环节:
数据准备
收集与你的应用场景相关的图像数据
使用LabelImg等程序标注图像,生成YOLO格式的标签文件
按8:1:1的比例划分训练集、验证集和测试集
模型训练
从预训练权重开始训练,以加速收敛
根据你的数据集调整模型参数,特别是锚点框(anchor boxes)和类别数
监控训练和验证损失,避免过拟合
性能优化
模型量化:将FP32精度转换为FP16或INT8,减少模型大小和推理时间
异步处理:对于高并发场景,使用Celery等工具异步处理检测任务
硬件加速:在有GPU的服务器上,确保TensorFlow/PyTorch使用了CUDA
部署考虑
在生产环境中部署时,需要考虑以下几点:
启用Gunicorn或uWSGI代替Flask内置服务器
通过Docker容器化应用,确保环境一致性
设置Nginx作为反向代理,处理静态文件和提高并发能力
实施安全措施,如文件类型验证、上传限制和API限流
总结
通过将Flask的灵活Web框架与YOLO强大的目标检测能力相结合,你可以构建一个功能完整的图像识别系统。这套系统不仅能够处理用户上传的图片并实时返回识别结果,还可以根据具体需求进行定制和扩展。
希望这个介绍对你有所协助!如果你有关于特定部分(如模型训练细节、框架性能优化或前端界面美化)的进一步问题,我很乐意供应更详细的指导。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号