

告别CRUD Boy!Java缓存精要,是你突破技术天花板的“第一课”! - 详解
一、Java 缓存精要
实现更低延迟、降低成本并赋能智能体架构
缓存技术在系统中的作用日益重要,对于大规模解锁众多用例至关重要。几十年来,缓存已实现低成本、可扩展地访问会话状态和数据存储等信息。更现代的缓存用例正在实现低成本、可扩展的工具链,并在智能体架构中实现嵌入生成,这正在解锁下一代系统创新。
本参考资料卡介绍了使用 Java 的 JCache(Java 临时缓存 API)将缓存融入系统的方法。文中首先讨论了缓存的基础知识,然后通过代码示例简要介绍了 JCache API,最后总结了缓存部署架构。
二、缓存概述
缓存是先前计算结果的一个存储,以便可以省略后续计算。理解缓存最简单的方式是将其视为键值存储:对于给定的输入(键),输出(值)代表先前基于该输入计算出的结果。
缓存命中表示特定数据存在于缓存中,这种情况下可以使用其值。否则,就会发生缓存未命中,此时需要执行相关计算并将其输出放入缓存。缓存未命中的代价可能除了昂贵的计算操作外,还涉及网络通信。
图 1:简化的缓存命中/未命中流程
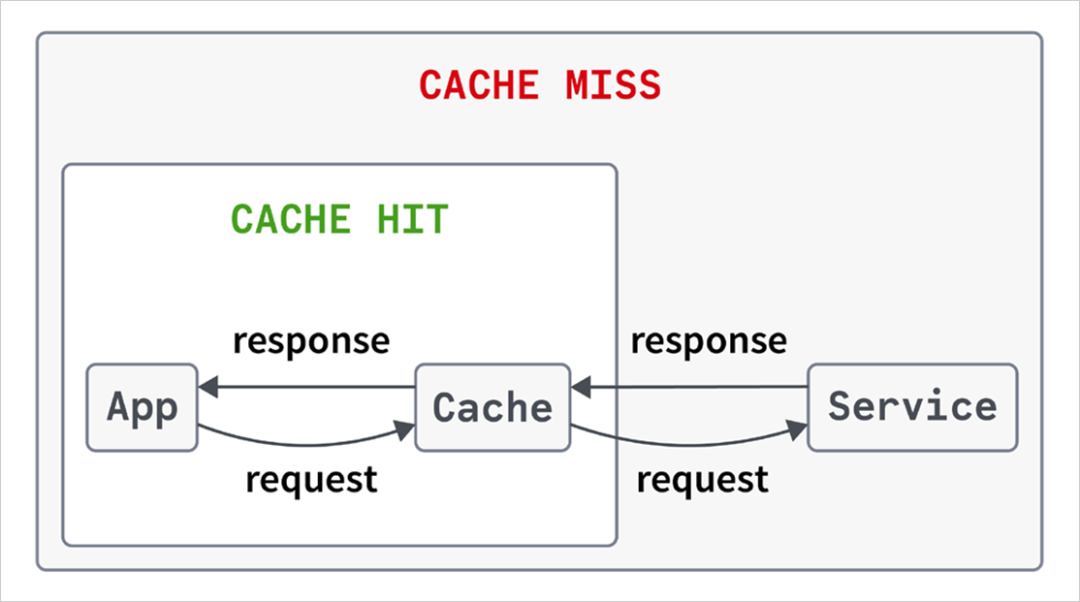
采用缓存是为了减少延迟并降低运营成本,几十年来对于实现众多类别的应用程序至关重要。缓存数据的例子包括 Web 应用程序的会话状态、数据库查询结果、网页渲染结果,以及来自通用网络和计算成本高昂的操作的结果。
缓存的一个更现代的用途是在 AI 领域。在这里,缓存的使用减少了昂贵的 API 调用(例如,嵌入生成),并最大限度地减少了智能体架构中智能体之间的对话断续(例如,由于工具调用和网络通信所致),从而解锁了新一波的解决方案和用户体验。
缓存可以驻留在进程内,作为客户端-服务器架构的一部分存在于服务中,或者是两者的结合。此外,缓存的部署通常可以组合。例如,应用程序可能与位于同一数据中心的缓存服务通信,而数据中心的本地缓存又是跨越多个数据中心的缓存的缓存。这种灵活性,加上缓存所支持的应用类别,使得缓存在过去几十年中成为一种主导的抽象概念。
本参考资料卡的剩余部分将讨论 JCache——Java 用于将缓存融入应用程序的抽象——首先简要概述您将经常使用的类,然后深入探讨 JCache 更广泛功能所提供的特性。最后,我们将总结缓存部署策略。
三、JCACHE 精要
JCache 在 Java 规范请求(JSR)107 中引入,并提供了一套关于缓存的抽象。JCache 有两个突出的特性:
JCache 是一个规范。
JSR 是由专家组设计和提交,并最终由 Java 社区过程执行委员会批准的规范。因为 JCache 是一个规范,所以它与那些 API 频繁变化的实现隔离开来。
JCache 是提供商独立的。
JCache 作为规范的一个副作用是,缓存解决方案提供商可以通过实现其暴露的服务提供程序接口(SPI)来与 JCache 集成。这为系统设计者提供了灵活性并避免了供应商锁定。
以下是一个简单的 JCache 示例,以便理解其使用方式。javax.cache 依赖项的获取方式可以在此处找到。
importjava.util.Map;importjavax.cache.Cache;importjavax.cache.CacheManager;importjavax.cache.Caching;importjavax.cache.configuration.MutableConfiguration;importjavax.cache.spi.CachingProvider;publicclassApp{publicstaticvoidmain(String[]args){CachingProvidercachingProvider=Caching.getCachingProvider();// (1)CacheManagercacheManager=cachingProvider.getCacheManager();// (2)MutableConfigurationcacheConfig=newMutableConfiguration();// (3)Cachecache=cacheManager.createCache("dzone-cache",cacheConfig);// (4)cache.put("England","London");// (5)cache.putAll(Map.of("France","Paris","Ireland","Dublin"));// (6)assertcache.get("England").equals("London");// (7)assertcache.get("Italy")==null;// (8)}} 对上述示例的简要说明: (1) 获取底层缓存提供程序的句柄 (2) 管理缓存的生命周期(例如,创建和销毁缓存) (3) 允许启用/禁用缓存的特定功能(例如,统计信息、条目监听器) (4) 创建由缓存提供程序支持的缓存 (5) 在缓存中放入单个键值条目 (6) 将键值条目放入缓存 (7) 断言缓存条目的存在 (8) 断言某个条目不在缓存中
本节的剩余部分将更详细地讨论上述示例中引入的抽象,以及您将经常遇到的相关类的其他方法。
javax.cache.spi.CachingProvider 构成了 JCache SPI,缓存提供者可以与之集成。您将使用的最常见功能是获取对 CacheManager 的引用。我们稍后将讨论 Caching。
getCacheManager 是 getCacheManager 变体中最简单的一个。这将根据提供者的默认设置获取一个 CacheManager。可以使用 javax.cache.CacheManager 创建和销毁缓存:
createCache创建一个具有给定名称和配置的缓存。
destroyCache销毁具有给定名称的缓存。
javax.cache.Cache 是对提供者缓存的抽象,并暴露了少量用于查询和变更缓存项的操作:
put和
putAll将条目放入缓存。请注意,这些方法不返回与正在放入的键先前关联的任何值。containsKey测试键是否存在于缓存中。
get和
getAll返回与指定键关联的值。remove和
removeAll从缓存中移除项。
1.JCACHE 包
在本节中,我们将快速概述 javax.cache 更广泛包结构中的一些重要接口,并提供常用功能的示例。我们可以参考文档来浏览其内容的详尽列表。
图 2:javax.cache 的组成包
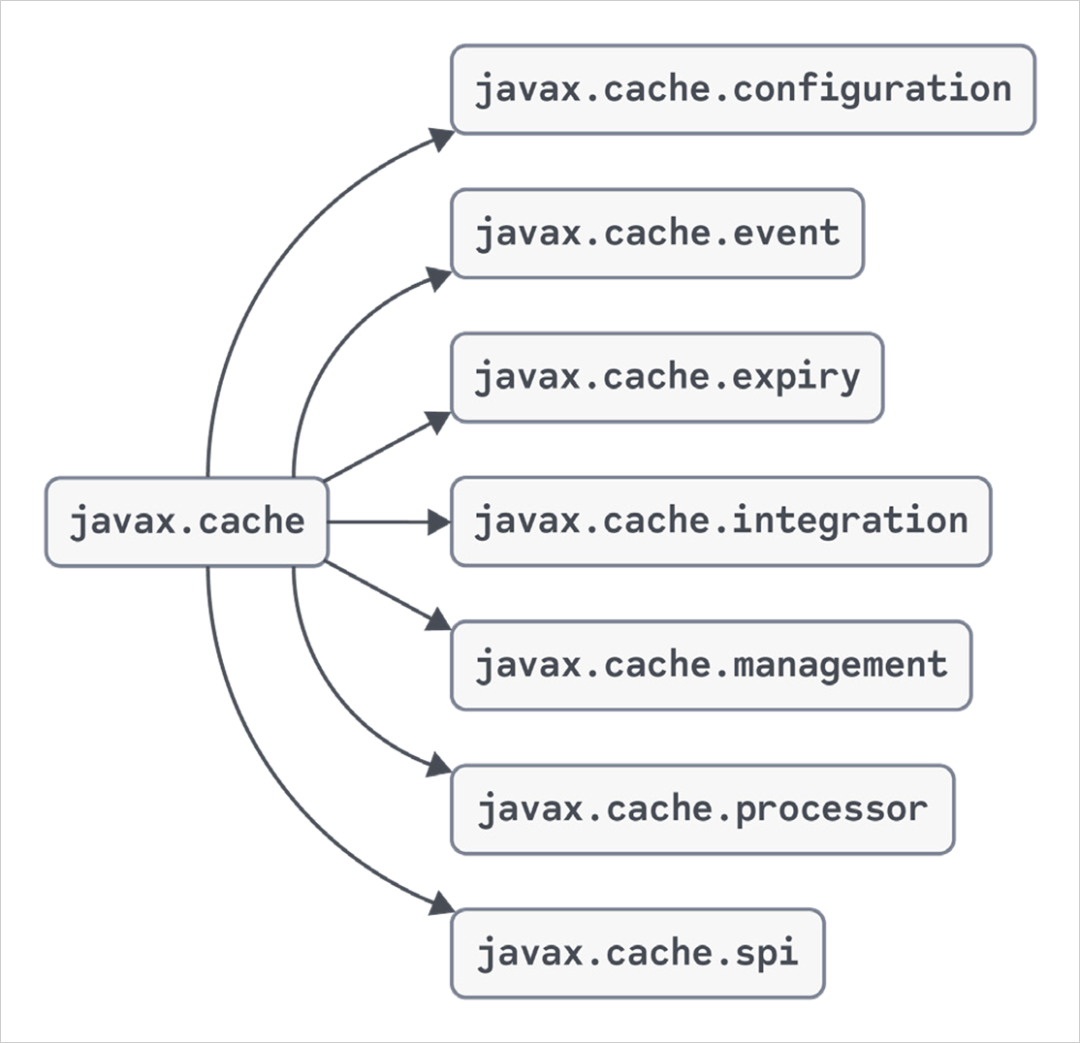
2.JAVAX.CACHE
通用管理(CacheManager)和与缓存交互(Cache)的设施位于 javax.cache 包内。除了初始配置之外,除非您想为缓存添加额外功能,否则仅使用此包中的类型就可以完成很多工作。例如,”JCache 精要”部分介绍中的示例用法主要使用了 javax.cache 中定义的接口。
3.JAVAX.CACHE.CONFIGURATION
在创建缓存期间,您可能希望添加功能,例如启用统计信息或通读缓存。此包提供了一个 Configuration 接口和一个实现 MutableConfiguration,可用于此类目的。
// ...MutableConfigurationcacheConfig=newMutableConfiguration();cacheConfig.setManagementEnabled(true).setStatisticsEnabled(true);Cachecache=cacheManager.createCache("dzone-cache",cacheConfig); 4.JAVAX.CACHE.EXPIRY
有时您希望驻留在缓存中的项过期。例如,我们可能有一个家庭保险报价的缓存,有效期为 24 小时。在这种情况下,我们可以使用过期策略如下:
// ...MutableConfigurationcacheConfig=newMutableConfiguration();cacheConfig.setExpiryPolicyFactory(CreatedExpiryPolicy.factoryOf(Duration.ONE_DAY));Cachecache=cacheManager.createCache("insurance-home-quotes",cacheConfig);cache.put(quote.getId(),quote.getValue()); javax.cache.expiry 包提供了额外的过期策略,可能对其他场景有用。例如,AccessedExpiryPolicy 允许基于缓存条目的最后访问时间附加过期设置。
5.JAVAX.CACHE.EVENT
JCache 的一个强大功能是能够订阅缓存事件。例如,我们可能希望在创建或删除缓存条目后运行某些领域逻辑。javax.cache.event 包提供了实现此功能的抽象,特别是订阅缓存创建、更新、过期和移除的能力。以下基本示例在缓存条目创建后运行某些领域逻辑:
// ...CacheEntryCreatedListenercreatedListener=newCacheEntryCreatedListener(){@OverridepublicvoidonCreated(Iterable>events)throwsCacheEntryListenerException{for(varc:events){performDomainLogic(c);}}};MutableConfigurationcacheConfig=newMutableConfiguration();MutableCacheEntryListenerConfigurationlistenerConfig=newMutableCacheEntryListenerConfiguration<>(()->createdListener,null,false,true);// 请参阅文档cacheConfig.addCacheEntryListenerConfiguration(listenerConfig);Cachecache=cacheManager.createCache("events",cacheConfig);cache.put("key","value");//调用创建监听器 6.JAVAX.CACHE.PROCESSOR
JCache 的一个强大组件是能够使用 EntryProcessor 将计算移至数据所在处,然后以编程方式调用该计算。当使用在分布式系统(例如,Hazelcast)内托管其缓存的提供者时,这尤其强大,因为它以很少的投入为分布式计算提供了一个简单的入口点。以下是一个 EntryProcessor 的简单示例,它将 UUID 附加到缓存条目:
// ...classAppendUuidEntryProcessorimplementsEntryProcessor{@OverridepublicStringprocess(MutableEntryentry,Object...arguments)throwsEntryProcessorException{if(entry.exists()){StringnewValue=entry.getValue()+"-"+UUID.randomUUID();entry.setValue(newValue);returnnewValue;}returnnull;}}// ...cache.invoke(key,newAppendUuidEntryProcessor()) 7.JAVAX.CACHE.MANAGEMENT
JCache 提供的管理钩子非常强大且易于启用。例如,下面的小代码片段暴露了由 Java 管理扩展(JMX)规范定义的托管 Bean。这使得诸如 jconsole 和 JDK Mission Control 之类的 JMX 客户端能够查看缓存配置和统计信息(例如,命中和未命中百分比、平均获取和放置时间)。
// ...MutableConfigurationcacheConfig=newMutableConfiguration();cacheConfig.setManagementEnabled(true).setStatisticsEnabled(true);Cachecache=cacheManager.createCache("management",cacheConfig);//... 8.JAVAX.CACHE.SPI
“JCache 精要”部分提供的示例省略了我们如何注册缓存提供者,即使用 JCache API 与我们的应用程序交互的缓存宿主服务。这就是 JCache 的 SPI 组件发挥作用的地方。
实现这一点有两个组成部分:
- 将我们的缓存提供者添加到类路径中
- 告诉 JCache 使用该提供者
第一步很简单:只需添加对任何符合 JSR 107 标准的提供者的依赖。
第二步有几种通用的方法:
- 我们可以通过调用
Caching#getCachingProvider(...)的某个变体(以及其他方法)来告诉 JCache。 - 我们可以提供一个
META-INF/services/javax.cache.spi.CachingProvider文件,并让其指定提供者实现。指定的提供者是您的提供者的缓存提供者实现的完全限定名称。 - 我们可以使用
Caching#getCachingProvider();但是,最好明确限定要使用的提供者,因为您的类路径上可能有多个提供者,这会抛出javax.cache.CacheException。
例如,以下代码使用 CachingProvider Caching.getCachingProvider(String) 指定 Hazelcast 为提供者:
CachingProvidercachingProvider=Caching.getCachingProvider("com.hazelcast.cache.HazelcastCachingProvider");CacheManagercacheManager=cachingProvider.getCacheManager();MutableConfigurationcacheConfig=newMutableConfiguration();Cachecache=cacheManager.createCache("spi-example",cacheConfig);cache.put("k","v"); 9.JAVAX.CACHE.ANNOTATION
JCache 定义了许多注解,用于集成到上下文和依赖注入环境中。Spring Framework 原生支持 JCache 注解。我们可以参考 JCache 文档以获取更多信息。
10.JAVAX.CACHE.INTEGRATION
javax.cache.integration 包提供了 CacheLoader(需要通读)和 CacheWriter(需要通写)。CacheLoader 在将数据读入缓存时使用——例如 Cache#loadAll(...)。CacheWriter 可以作为一个集成点,将缓存变更(例如,写入、删除)传播到外部存储服务。
11.缓存部署
JCache 没有缓存部署策略的概念;它仅仅是缓存提供者之上的一个 API。然而,不同的提供者支持不同类型的缓存部署。请考虑哪种缓存部署对您的应用程序有意义,并由此反向确定合适的缓存提供者。
图 3: 缓存部署示例
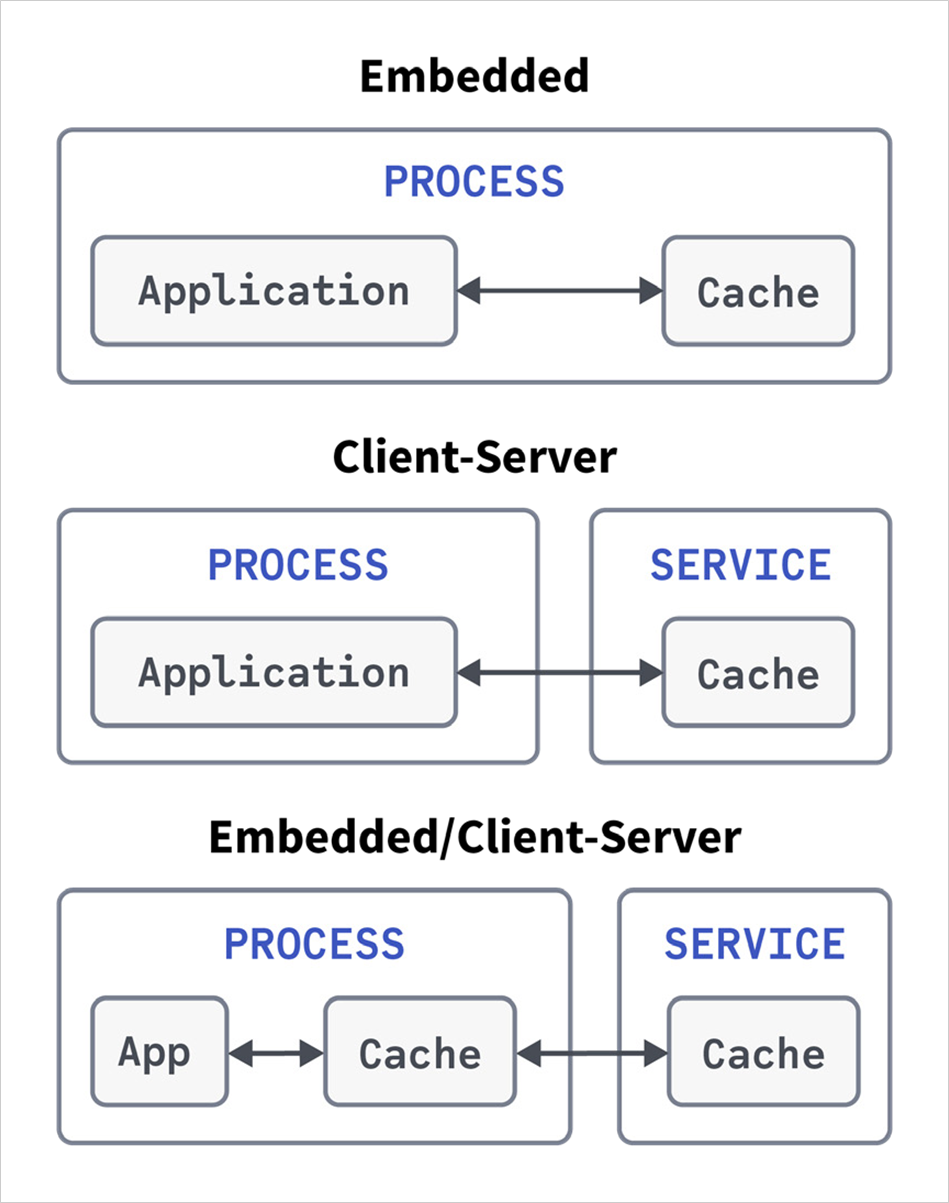
请注意,一些缓存提供者可能支持所有这三种缓存部署,而其他提供者可能不支持。
本节的剩余部分讨论图 2 中所示的常见缓存部署:
嵌入式
– 缓存与应用程序位于同一进程中。
客户端-服务器
– 缓存托管在独立的服务中,客户端与该服务通信以确定缓存驻留。
嵌入式/客户端-服务器
– 这是一种混合模式,整个缓存托管在不同的服务上,但客户端在同一进程中拥有一个较小的本地缓存。
重要的是要注意,上述缓存部署并非互斥的;它们可以通过多种方式组合以满足应用程序需求。
最简单的缓存部署是让缓存与应用程序驻留在同一进程中,这样做的好处是提供低延迟的缓存访问。嵌入式缓存不能在应用程序之间共享,并且在应用程序重启或故障时,其托管(它们所需的资源)和重建成本可能很高。
客户端-服务器缓存部署将缓存托管在与客户端不同的服务中。缓存服务允许通过跨服务复制来满足容错需求,提供更大的容量、更多的可扩展性选项,以及跨应用程序共享缓存的能力。客户端-服务器模型的主要缺点在于客户端缓存查询期间网络通信的成本。
混合嵌入式/客户端-服务器部署是指我们拥有一个嵌入式缓存,它包含来自服务缓存条目的一个子集,作为应用程序缓存请求的副作用被填充。在这里,客户端可以对频繁访问的数据(或表现出特定访问模式的数据)实现低延迟的缓存命中,并省去与缓存服务通信所带来的网络通信开销。如果嵌入式缓存过期,一些提供者会负责使用服务托管的缓存来更新它们。
四、结论
本参考资料卡介绍了缓存以及如何将其与 Java 的 JCache API 一起使用。JCache API 直观、强大,并且由于其是一个规范而避免了供应商锁定,为架构师和系统设计者提供了他们所需的灵活性。这种灵活性在我们进入基于智能体架构的新一代创新时尤为重要,其中缓存对于工具链和嵌入生成至关重要。
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号