

完整教程:大数据计算引擎-全阶段代码生成(Whole-stage Code Generation)与火山模型(Volcano)对比
Whole-stage Code Generation(全阶段代码生成)是计算引擎(如 Spark、Flink、StarRocks)为减少算子交互开销、提升执行效率而设计的核心优化技术,核心逻辑是:将一段连续的、无数据 Shuffle 的算子(如 “过滤→投影→聚合”)逻辑合并成单一的、优化的机器码,替代传统 “算子逐个调用、数据在算子间频繁拷贝” 的执行方式,从而消除函数调用、数据缓冲等冗余开销。
目录
2. Whole-stage Code Generation 方式
4.1、Whole-stage Code Generation源码实现
以 SQL 查询 SELECT name FROM user WHERE age > 30(筛选年龄 > 30 的用户姓名)为例,对比传统算子调用与 Whole-stage Code Generation 的执行过程:
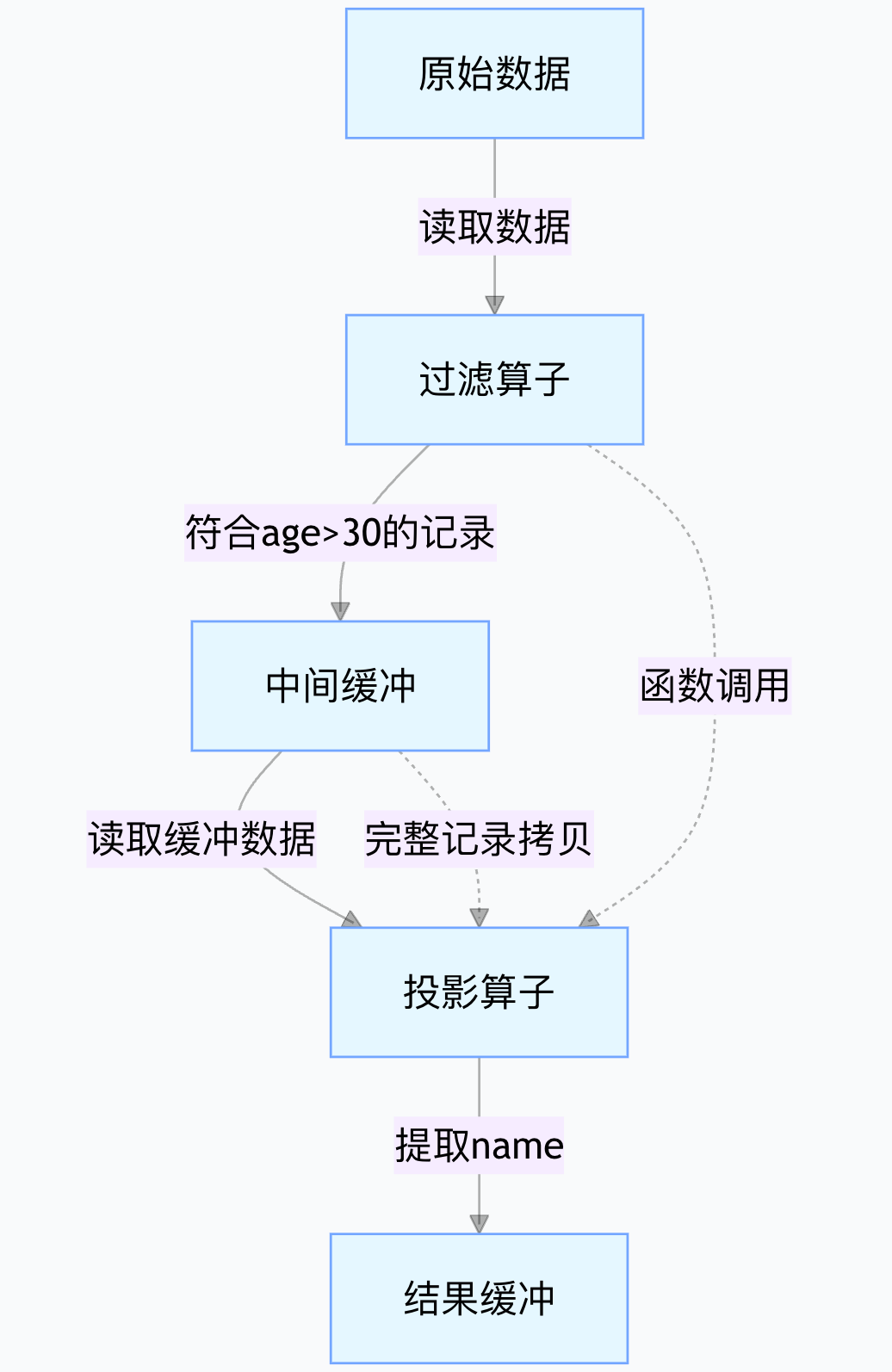
1. 传统算子调用方式(valcano)
执行流程拆分为 “过滤算子” 和 “投影算子” 两个独立步骤,中间通过缓冲传递数据:
步骤 1:过滤算子处理
- 从存储读取原始数据(每条记录包含
age、name等字段); - 逐个判断
age > 30:- 若符合条件,将整条记录(包括
age、name等)写入中间缓冲(如内存数组); - 若不符合,跳过。
- 若符合条件,将整条记录(包括
- 过滤完成后,调用 “投影算子” 的入口函数,传递缓冲地址。
- 从存储读取原始数据(每条记录包含
步骤 2:投影算子处理
- 从中间缓冲读取过滤后的整条记录;
- 从记录中提取
name字段,写入结果缓冲; - 重复上述步骤,直到缓冲中所有记录处理完毕。
核心开销:
- 2 次函数调用(过滤→投影);
- 1 次完整记录的中间拷贝(从过滤缓冲到投影算子);
- 缓冲管理开销(申请 / 释放内存、判断缓冲边界)。
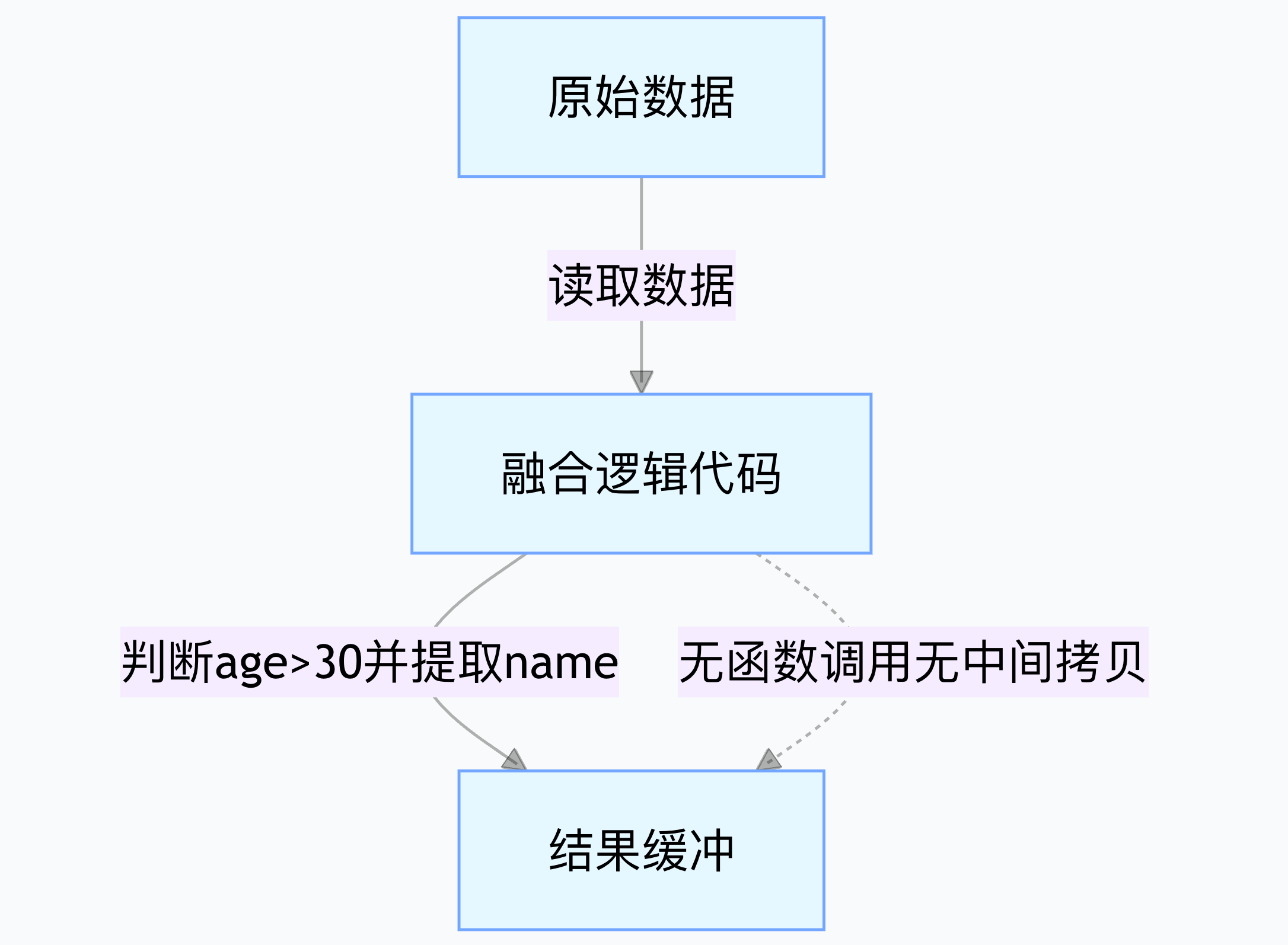
2. Whole-stage Code Generation 方式
将 “过滤 + 投影” 逻辑融合为一段代码,直接编译执行:
步骤 1:生成融合代码引擎分析算子逻辑后,自动生成一段合并逻辑的代码(类似伪代码):
// 直接遍历原始数据,同时完成过滤和投影 for (int i = 0; i < 原始数据长度; i++) { 原始记录 = 原始数据[i]; if (原始记录.age > 30) { // 过滤逻辑 结果缓冲.add(原始记录.name); // 投影逻辑 } }步骤 2:编译执行这段代码被直接编译为机器码(如 x86 指令),CPU 直接执行:
- 遍历原始数据时,同时完成过滤和投影,无需中间缓冲;
- 数据从原始存储读取后,直接提取
name写入结果,无冗余拷贝。
核心开销:
- 0 次算子间函数调用(逻辑合并为单循环);
- 0 次中间数据拷贝(直接从原始数据取
name); - 仅一次循环遍历,无缓冲管理开销。
3. 直观差异总结
| 执行方式 | 数据流动路径 | 关键开销点 | 效率对比(假设 10 万条数据) |
|---|---|---|---|
| 传统算子调用(valcano) | 原始数据→过滤缓冲→投影缓冲 | 2 次函数调用 + 1 次完整记录拷贝 | 耗时约 10ms |
| Whole-stage Code Generation | 原始数据→结果缓冲 | 0 函数调用 + 0 中间拷贝 | 耗时约 2ms(提速 5 倍) |
传统执行方式的痛点是 “算子间交互开销 > 计算本身开销”(如函数调用、数据拷贝、缓冲管理占比超 60%);全阶段代码生成通过 “逻辑融合 + 直接编译”,将这些冗余开销降至接近 0,尤其在 “数据量小但计算密集”(如复杂聚合、多算子串联)场景下,性能可提升 2-10 倍。
4. 实现对比-spark源码
下面是Spark SQL源码中 Whole-stage Code Generation 和 Volcano(传统迭代器模型)实现的关键源码片段,并附了详细对比说明。
4.1、Whole-stage Code Generation源码实现
Whole-stage Code Generation 的核心类是 WholeStageCodegenExec,它会为可以融合的子算子生成一大段 Java 代码。
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scalav1
/**
* SparkPlan A should override `doProduce()` and `doConsume()`.
*
* `doCodeGen()` will create a `CodeGenContext`, which will hold a list of variables for input,
* used to generated code for [[BoundReference]].
*/生成代码的关键流程
- 每个可融合算子实现
doProduce和doConsume,拼接代码。 doCodeGen方法会把所有融合算子的代码生成出来,最后用 Janino 编译。
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scalav2
val duration = System.nanoTime() - startTime
WholeStageCodegenExec.increaseCodeGenTime(duration)
logDebug(s"\n${CodeFormatter.format(cleanedSource)}")
(ctx, cleanedSource)4.2、Volcano执行模型源码实现
Volcano(传统迭代器模型)每个算子实现自己的 doExecute 方法,返回一个 RDD[InternalRow],本质上是迭代器链式调用。
sql/core/src/main/scala/org/apache/spark/sql/execution/objects.scala
override protected def doExecute(): RDD[InternalRow] = {
child.execute().mapPartitionsInternal { iter =>
// ...
iter.map { row =>
// 这里就是传统的每条数据逐条处理
}每个算子的 doExecute 都是类似的模式,上一层的 Iterator.next() 调用下一层的 Iterator.next(),形成嵌套结构。
4.3、源码对比与执行流程
| 执行模型 | 关键类/方法 | 处理流程 | 优化点 |
|---|---|---|---|
| Whole-stage Codegen | WholeStageCodegenExec.doCodeGen/doProduce/doConsume | 代码生成:将多个算子的逻辑融合为一个批处理 Java 方法 | 批量处理、极少对象和函数调用、易于JVM优化 |
| Volcano | SparkPlan.doExecute + Iterator链 | 每个算子单独实现 RDD/Iterator,层层嵌套 next | 逐条处理、对象和函数调用多、GC压力大 |
物理计划举例(代码生成与Volcano)
1. Whole-stage Codegen 的物理计划
sql/core/src/test/scala/org/apache/spark/sql/execution/WholeStageCodegenSuite.scalav2
val df = spark.range(10).filter("id = 1").selectExpr("id + 1")
val plan = df.queryExecution.executedPlan
assert(plan.exists(_.isInstanceOf[WholeStageCodegenExec]))
assert(df.collect() === Array(Row(2)))说明: filter + project 两个算子融合在同一个 WholeStageCodegenExec 内。
2. Volcano 的物理计划
对于不支持代码生成的算子(如UDF),Spark会退回传统执行模型,每个算子都是独立的 doExecute+Iterator。
4.4 spark实际实现总结
- Whole-stage Code Generation:算子链融合、批量代码生成、性能极高。适用于 Filter、Project、Map、无分组聚合等算子,且中间没有 Exchange(shuffle)/join等阻断节点。
- Volcano模式:每个算子个别处理、对象和函数调用多,适用于不能代码生成的场景(如UDF、复杂算子)。
- 源码实现:SparkPlan 体系下,WSCG的
doCodeGen/doProduce/doConsume对比 Volcano 的doExecute+ Iterator链,是两套核心执行框架。
| 执行方式 | Volcano(传统) | Whole-stage Code Generation |
|---|---|---|
| 处理粒度 | 单条记录(Iterator next) | 批处理(for/while循环) |
| 函数调用/对象开销 | 多层嵌套、频繁调用 | 一次性完成,极少函数/对象开销 |
| JVM优化空间 | 受限 | 极大,可内联、展开、寄存器优化 |
| 性能 | 较低 | 极高 |
(欢迎关注,欢迎订阅 -)
推荐阅读 :

 浙公网安备 33010602011771号
浙公网安备 33010602011771号