

【干货】一文学完 Hive:库表运行、分区分桶、资料压缩与调优技巧全汇总
引言
在大数据开发中,Hive 几乎是每个数仓工程师绕不开的核心组件。
它是构建在 Hadoop 之上的数据仓库工具,可以让我们用熟悉的 SQL 语法(HQL)对海量数据进行分析处理,而无需直接编写复杂的 MapReduce 程序。本文将系统讲解 Hive 的核心知识点与常用技巧,从 数据库与表操作(DDL ) 到 分区、分桶设计,再到 文件格式、压缩方式、排序机制与性能调优,一步步带你理清 Hive 的使用逻辑和优化思路。
如果你正准备深入学习 Hive、搭建离线数仓或面试数仓岗位,这篇文章将帮助你从“能用”到“用得好”,一次掌握 Hive 的核心技能。
一、Hive概述
1.1、什么是Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
本质是将SQL转换为MapReduce程序。
主要用途:用来做离线数据分析,比直接用MapReduce开发效率更高。
Hive 是基于 Hadoop 的数据仓库工具,由 Facebook 开发,主要用于处理大规模结构化 / 半结构化数据。
它允许用户通过类 SQL 语言(HQL,Hive Query Language)查询和分析数据,底层将 HQL 自动转换为 MapReduce、Tez 或 Spark 等计算引擎的任务,简化了 Hadoop 的使用门槛。
1.2、Hive与Hadoop的关系
Hive利用HDFS存储数据,利用MapReduce查询分析数据
1.3、Hive与传统数据库对比
hive用于海量数据的离线数据分析。
hive具有sql数据库的外表,但应用场景完全不同,hive适合用来做批量数据统计分析。
更直观的对比请看下面这幅图:
| 对比项目 | Hive | 传统数据库 |
| 设计目标 | 设计用于海量数据的批处理分析,注重吞吐量 | 设计用于事务处理和实时查询,注重响应时间 |
| 数据规模 | 可处理PB级别的数据,适合大数据场景 | 通常处理GB或TB级别的数据,超大规模性能下降明显 |
| 查询延迟 | 查询延迟通常在分钟或小时级别 | 查询延迟通常在毫秒或秒级别 |
| 数据更新 | 主要支持批量数据导入,不适合频繁的小批量更新 | 支持高频率的插入、更新和删除操作 |
| 事务支持 | 有限的事务支持(较新版本支持ACID特性,但有限制) | 完整的ACID事务支持 |
| 数据存储 | 数据存储在分布式文件系统(如HDFS)中 | 数据存储在专有的存储格式中,通常在本地文件系统 |
| 架构模式 | 计算与存储分离 | 计算与存储紧密耦合 |
| 索引支持 | 索引支持有限,且使用较少 | 丰富的索引类型和优化技术 |
| 扩展性 | 水平扩展能力强,可通过增加节点线性扩展 | 垂直扩展为主,水平扩展相对复杂 |
| 数据类型和函数 | 支持的数据类型和函数相对有限 | 丰富的数据类型和内置函数 |
| 使用场景 | 大规模数据仓库、批量ETL处理、历史数据分析、离线报表生成 | 在线事务处理(OLTP)、实时查询和分析、需要高并发的应用、需要严格事务保证的场景 |
| 成本 | 基于开源软件,硬件成本相对较低(使用普通商用硬件) | 商业数据库许可成本高,通常需要专用硬件 |
二、Hive基础操作
2.1数据库(库)操作
2.1.1建库
create database if not exists 库名
comment 注释名
location hdfs_path --指定hdfs地址
with dbproperties property_name=property_value, ...) --自定义属性location:指定hdfs存储路径
(默认路径:hdfs://<集群地址>/user/hive/warehouse/库名)
with dboroperties:添加自定义属性(如创建时间、负责人等)
2.1.2查库
查看所有库的库名:show databases
展示含有db_hive的库:show databases like 'db_hive*'
like '逻辑或' :show databases like 'db_hive1 | db_hive2'
查看库的详细信息
查看库的基本信息:desc database 库名
查看库的扩展信息:desc database extended 库名
2.1.3改库
修改自定义属性 dbproperties
alter database 库名 set dbproperties('要修改的属性名’ = ‘要修改的属性值')2.1.4删库
drop database if exists 库名 [restrict | casecade]restrict :严格模式,若数据库非空则报错
casecade : 级联模式,强制删除数据库及内部所有表
drop database if exists 库名 --删除空数据库
2.1.5切换库
use 库名
2.2表结构操作(DDL)
2.2.1临时表
--建表
create temporary table if not exists 表名(
类名 类型,
... ...)
--插入数据
insert into 表名 values ();
--查表内容
select * from 库名.表名;临时表:只在当前会话中能查看,其他会话窗口查不到,会话结束,表自动删除
2.2.2指定分隔符的表
字段类型
| 类型 | 长度特性 | 存储空间 |
| string | 可变长度 | 按需分配 |
| varchar | 固定最大长度 | 实际长度+少量开销 |
| char | 固定长度 | 固定空间(浪费可能大) |
create table if not exists 表名(
列名 类型,
... ...)
row format delimited
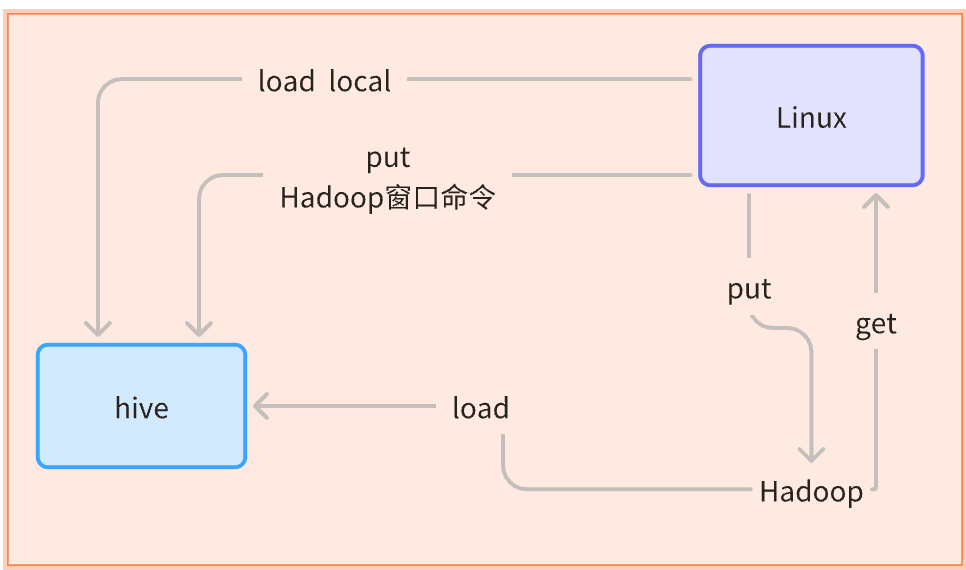
fields terminated by '分隔符符号'; -- 指定分隔符文件---表中(local 是从Linux中复制,没有local 是从hdfs中剪切)
1.put导入 -hadoop窗口 linux-->hadoop/hive
hdfs dfs -put 文件路径 存储路径(存储默认:/user/hive/warehouse/库名.表名)
2.load 加载 --Linux中 linux-->hadoop/hive
load data local(--本地) inpath '文件路径' into table 库名.表名
2.2.3ctas建表
根据select结果创表,,包含数据和结构
create table if not exists 库名.表名 as
select * from 源表名2.2.4复制表
create table 库名.表名 like 复制的表名
2.2.5查看表
查看表的详细信息
desc extended 表名 --显示详细元数据(如存储路径、属性等)
desc formatted 表名 --格式化展示字段注释等信息(更详细)
查看表的属性
show tblproperties 库名.表名
2.2.6改表
重命名
alter table 表名 rename to 新表名
修改列信息
--增加列:
alter table 表名 add colums (列名 类型 comment 注释)--更新列:
alter table表名 change 原列名 新列名 新类型
[after 表里列名]; -- 可选:指定新字段在表中的位置(放在某个字段之后)
删表
drop table if exists 表名
注意:外部表删除时只删除元数据,hdfs数据需要手动删除
清表
trucate table 表名
注意:适用于内部表,外部表无法通过trucate清空数据
2.2.7内部表和外部表
内部表(默认)table_type:manager_table
create table 表名()
row format delimited fields terminated by '分隔符'外部表table_type:external_table
create external table 表名()
row format delimited fields terminated by '分隔符'内外表转换
alter table 库.表名(内/外)
set tblproperties('EXTERNAL'='TRUE/FALSE')--括号必须是大写;
EXTERNAL'='TRUE’ 外部表
EXTERNAL'='FALSE’ 内部表内外表区别
内部表
数据存储在默认的warehouse目录下
删表后,相关表文件全部消失,重建表,表数据不在,适合etl过程中的中间表或结果表
外部表
可以指定数据的hdfs路径
删了重建表,表内容还在(只删元数据,不删实际数据),安全级别高,适合多部门办公和原始数据表
2.2.8复杂类型操作
Array类型--数组
Array是数组类型,Array中存放相同类型的数据
Array应用场景
- 存储用户标签列表
- 存储商品类别列表
- 存储地理位置信息(如工作地点列表)
- 存储用户行为序列
建表:
create external 表名(
列名 string,
列名 array --数组类型
)
row format delimited fields terminated by '\t'--指定列分隔符
collection items terminated by ',' --指定数组元素分隔符
; 列名 sring --长字符串类型
--转化为数组
split (列名 , ',')
常用查询
查看上述表中数组中的第n个元素
select 数组列名[ n-1 ] --下标从0开始 from 表名查看数组元素个数
select size(数组名) from 表名查看数组中含有某元素的信息
select * from 表名 where array_contains(数组名,‘元素名’)
Hive查询:爆炸,拼接,聚合,切片用法
爆炸explode
侧视图:在爆炸分行前增加对应列--一对多 select explode(爆炸字段名)/* from 表名 lateral view explode (爆炸字段名) 别名 as 爆炸后命名的字段名侧视图+位置(下标) select 别名.pos, 别名.爆炸后的字段名 from 表名 lateral view posexplode (爆炸字段名) 爆炸表别名 as pos-下标号 爆炸后命名的字段名
多行聚合函数collect list/set
collect_list(列名) - 将一列的所有值收集到一个数组中 - 保留所有值,包括重复值 - 性能较好,不需要去重操作collect_set(列名) - 将一列的所有值收集到一个数组中,并去除重复值 - 数据量大时性能较低,因为需要额外的去重操作最后是数组类型
拼接concat_ws
用法: concate(分隔符,string1,string2 ... ...)concat_ws 与 concat的区别
concat_ws 第一个参数是分隔符,后边可传入多个参数 concat_ws 可以过滤空值,concat不会 concat_ws可以配合数组函数一起使用- concat_ws 参数类型必须一致,concat参数类型可以不一致把数组类型,按照分隔符分开转为字符串类型
split
将cioncat_ws字符串转为数组
split(长字符串,'分隔符')
map类型--映射
map就是描述key-value数据
存储键值对形式的数据
map应用场景
- 存储属性-值对(如商品属性)
- 存储家庭成员关系
- 存储多语言版本的文本
- 存储配置信息
建表:
creat table 表名(
列名 类型,
列名 map<键类型,值类型>
.... ...)
row format delimited field terminated by '分隔符号'
collection items terminated by '键值对的分隔符号'
map keys terminated by '键和值的分隔符号'常用查询
1.根据键找对应的值
select 列名1, 列名2, map列名[’键1‘], map列名[’键n‘] from 表名2.获取所有键
select map__keys(map列名) from 表名3.获取所有的值
select map_values(map列名) from 表名4.获取键值对个数
select size(map列名) from 表名5.获取有指定key的数据
select * from 表名 where array_contains(map_keys(map列名),'key')
struct类型--结构体
自定义结构类型
存储不同数据类型的字段集合
struck应用场景
- 存储复合信息(如用户基本信息)
- 存储嵌套结构的数据
- 存储具有固定结构的复杂对象
- 存储日志信息的详细结构
建表:
create table 表名(
列名,类型,
列名, struct<固定内容1:类型,固定内容2:类型,... ...>
... ...)
from 表名常用查询
根据struct 来获取指定内容的值
select 列名, struct列名.固定内容 from 表名
注意事项
复杂类型的分隔符不能与字段分隔符相同
对复杂类型的过滤操作通常比简单类型慢
某些函数不支持复杂类型作为参数字符串函数 length():array 的长度(需用 size())、map 的键值对数量(需用 size())或 struct 的字段数 concat):不能直接拼接 array 元素或 map 的键值对(需先通过 explode() 拆解或 to_json() 转换)聚合函数 比较函数 日期函数 等 都需要先对处理的字段单分出来 通过explode map_keys()/map_values等方式分区键不能使用复杂数据类型
json
一种文本格式的轻量级数据交换语言,独立于编程语言,用于存储和传输数据。
格式:{" ":" ", " " : " " ... ....}
示例:
{"name":"张三", "age":20, "address":{"city":"北京"}}
相关函数
提取字段内容
get_json_object(json字符串,’$.数组元素‘/’$数组元素[下标]‘)-- 提取一级字段 SELECT get_json_object('{"name":"张三","age":20}', '$.name'); -- 结果:"张三" -- 提取嵌套字段 SELECT get_json_object('{"user":{"id":1,"info":{"city":"北京"}}}', '$.user.info.city'); -- 结果:"北京" -- 提取数组元素 SELECT get_json_object('{"hobbies":["读书","跑步"]}', '$.hobbies[0]'); -- 结果:"读书"转化为json字符串格式
to_json(struct/array/map类型名)键值对集合用{}
数组(有序的元素集合)用[ ]-- struct 转 JSON SELECT to_json(named_struct('name', '张三', 'age', 20)); -- 结果:{"name":"张三","age":20} -- array 转 JSON SELECT to_json(array('a', 'b', 'c')); -- 结果:["a","b","c"] -- map 转 JSON SELECT to_json(map('k1', 'v1', 'k2', 'v2')); -- 结果:{"k1":"v1","k2":"v2"}解析 JSON 数组为多行
json_tuple(json_str, key1, key2, ...)explode(split(get_json_object(json_str, path), delimiter))
SELECT json_tuple('{"name":"张三","age":20,"city":"北京"}', 'name', 'age', 'city'); -- 结果:张三 | 20 | 北京SELECT explode(split(get_json_object('{"hobbies":["读书","跑步"]}', '$.hobbies'), '","')) AS hobby FROM table_name; --结果: 读书 跑步

2.3数据库查询操作(DQL)
用于从数据库表中查询数据,是 SQL 中最常用的操作之一
核心命令:SELECT(配合 FROM、WHERE、GROUP BY、ORDER BY 等子句)。
三、Hive表设计与高级特性
3.1分区表
3.1.1Oracle分区
范围分区
要求连续
列表分区
适合固定分类的
散列分区
例如哈希分区,均匀分布数据,适合无法按照范围或列表划分的
组合分区
主分区partition
子分区 subpartition
时间+区域维度:范围+列表
时间+高频访问数据:范围+哈希
日志数据(按日期范围分区,再按日志类型哈希分散存储)用户行为数据(按周分区,再按用户 ID 哈希均衡负载)物联网设备数据(按小时分区,再按设备 ID 哈希分散查询压力)
分类+子分类维度:列表+哈希
商品库存数据(按商品类别列表分区,再按仓库 ID 哈希分区)社交媒体内容(按内容类型列表分区,再按用户 ID 哈希分区)
3.1.2HIve分区
通过将表数据按照指定列(分区键)的值进行物理分割,实现数据的分类存储和快速过滤,特别适合处理 PB 级别的海量数据。
概述:分区表是分目录储存数据
分类
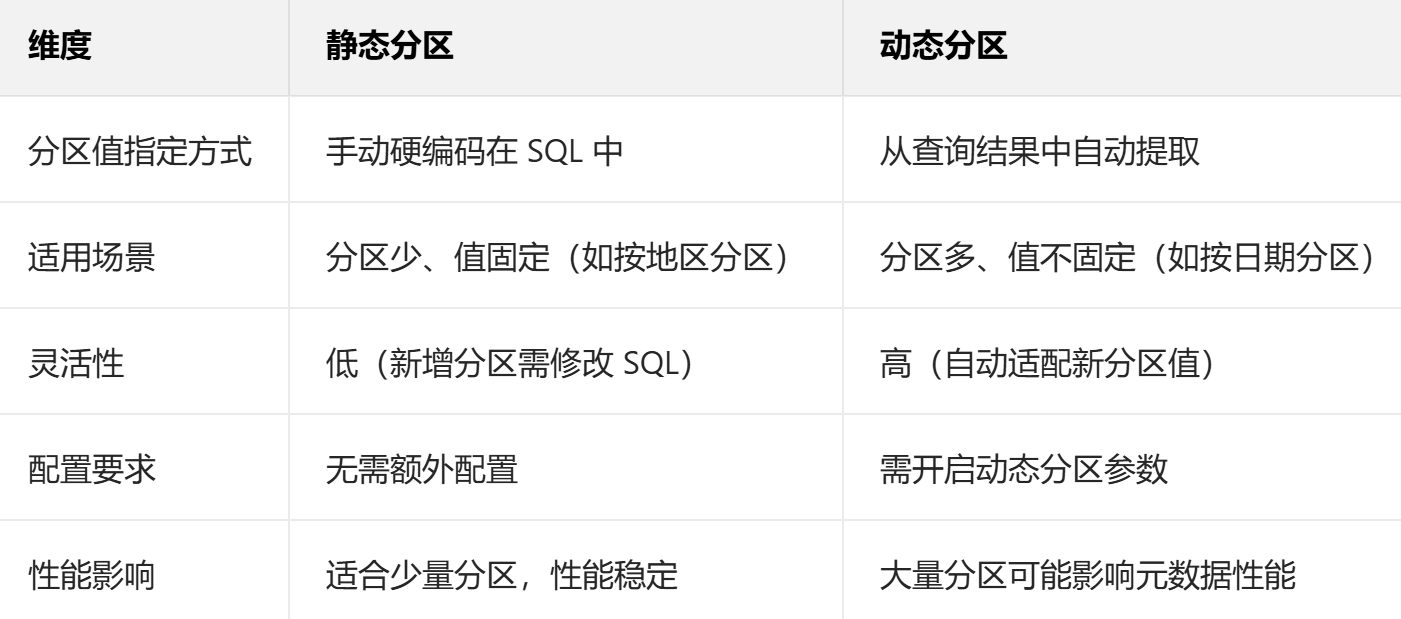
静态分区
动态分区
适合批量写入多个分区
SET hive.exec.dynamic.partition=true; -- 开启动态分区功能(默认开启) SET hive.exec.dynamic.partition.mode=nonstrict; -- 非严格模式(允许全动态分区)-必须打开 -- 可选 SET hive.exec.max.dynamic.partitions=1000; -- 最大分区数(默认1000) SET hive.exec.max.dynamic.partitions.pernode=100; -- 单节点最大分区数(默认100)
建表分区
patitioned by (分区列名1 类型,分区列名2 类型,... ...) 需要指定: 分割符号 row format delimited field terminated by '' 存储方式 stoted as orc 压缩方式 tblproperties("orc.compress" = "snappy")
从表中加载数据分区
insert into 表名 partition(分区列1,分区列2, ... ...) select *, 分区列1, 分区列2, ... ... from 源数据表; 从文件中加载数据到分区 load data local 'Linux文件路径' into table 表名;
区别
静态分区是指在 SQL 语句中明确指定分区字段的值,分区值在编译时就已确定。
动态分区是指分区值由查询结果自动推断,不需要手动指定,分区值在运行时动态确定。
分区表的基本操作
创建数据 vim 文件 插入内容
创建分区
create table 表名( 列名 类型, ... ...) partitioned by (分区字段名 类型) --自动生成目录 row format delimited fields terminated by '分隔符号'
将文件数据导入到分区
从Linux中加载数据到分区表
复制方式
覆盖导入: load data local inpath 'linux中文件路径' overwrite into table 表名 partition (分区字段='分区目录名')追加导入: load data local inpath 'linux中文件路径' into table 表名 partition (分区字段='分区目录名')剪切方式
put hdfs dfs -put 'linux中文件路径' 'hive储存路径' 1.先建目录 2.put 3.赋予目录分区身份(add/msck repair) hive储存路径可在desc表中查看 一般默认为:user/hive/warehouse/......后边加上分区目录名
查询表分区信息:show partitions 分区所在表名
迁移分区表(将表数据导入分区)
追加 insert into 表名 partition (分区字段名=‘分区目录名’) select 非分区字段名 from 分区表所在的名 where 分区字段名=‘另一个分区目录名’覆盖 insert overwrite table 表名 partition (分区字段名=‘分区目录名’) select 非分区字段名 from 分区表所在的名 where 分区字段名=‘另一个分区目录名’
增加分区,可增加多个
alter table 表名 add partition (分区字段名=‘分区目录名’)alter table 表名 add partition (分区字段名1=‘分区目录名1’ ,分区字段名2=‘分区目录名2’ ... ...)
删除分区
alter table 表名 drp partition (分区字段名=‘分区目录名’)修复分区表
msck repair table 表名
多级分区表的基本操作
创建多级分区
partitioned by (一级分区 类型,二级分区 类型 ... ...) 例如:partitioned by (year string,month string,day string)
删除分区
alter table 表名 drop partition (一级分区=‘一级目录’, 二级分区=‘二级目录’ , 三级分区=‘三级目录’ ... ...)
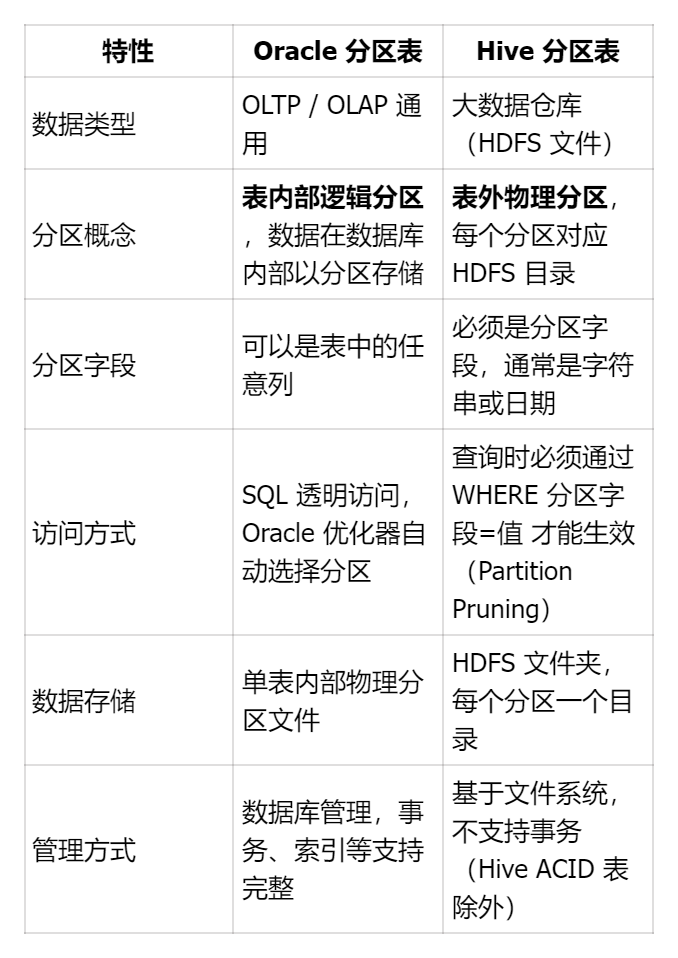
3.1.3Oracle分区与HIve分区区别
3.2分桶表
作用
方便抽样
提高查询销量
规则
将指定列按照一定规则 分文件存储数据
计算规律:类比MR分区逻辑/Oracle哈希分区
常见类型
不带排序的分桶表
建表:
create table 表名(
列名 类型)
clustered by (需要分桶的列名) into 桶数 buckets
row format delimited field terminated by ''
例:
create table dwd_story(
id int,
name string
)
clustered by (id) into 3 buckets
row format delimited fields terminated by ','
;加载数据
insert into 表名 select * from 源表 --数据自动分桶
查看桶:
hdfs dfs -ls /user/hive/warehouse/库名.表名查看分桶数据
hdfs dfs -ls /user/hive/warehouse/库名.表名/第一个桶
hdfs dfs -ls /user/hive/warehouse/库名.表名/第二个桶
hdfs dfs -ls /user/hive/warehouse/库名.表名/第三个桶
分桶表查询:
select * from 库名.表名
where 需要分桶的列名=值例:
select * from db_dwd.dwd_story
where id = 12;
带排序的分桶表
在不带排序分桶上+sorted by排序
建表 create table 表名( 列名 类型) clustered by (需要分桶的列名即分桶键) sorted by ((列名 desc/asc) into 桶数 buckets row format delimited field terminated by ''注意:
分桶(CLUSTERED BY)是按照指定字段(分桶键)对数据进行哈希分区,决定数据分到哪个桶;而排序(SORTED BY)是对每个桶内的数据按指定字段进行排序,排序字段可以是分桶键,也可以是其他字段。
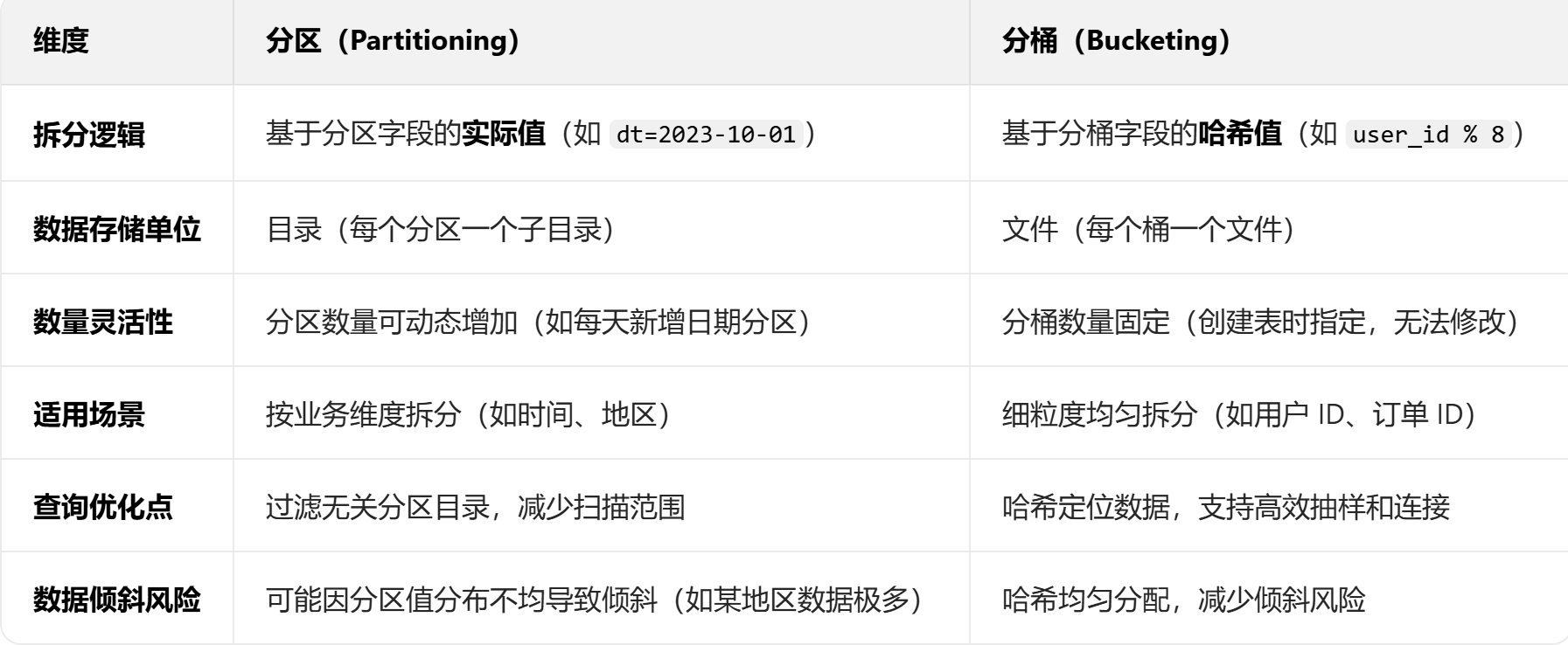
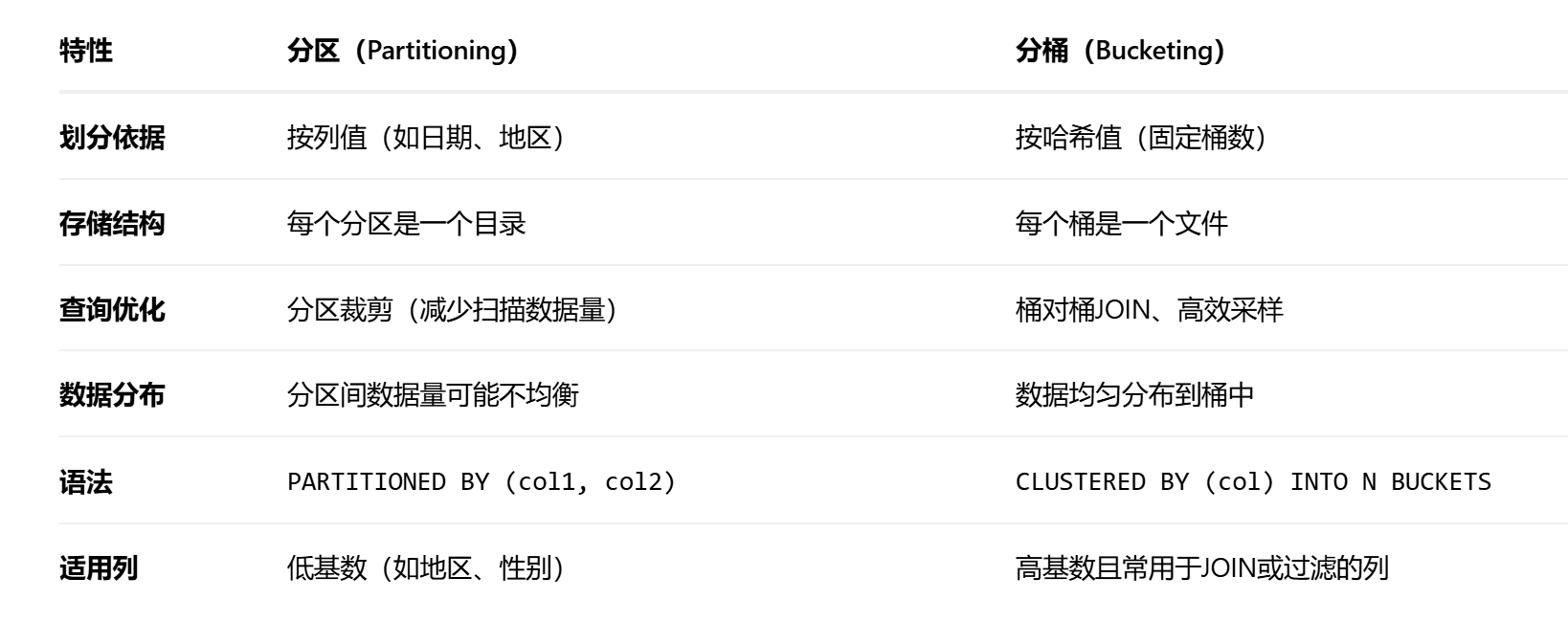
3.3分区表和分桶表区别
四、Hive文件格式与压缩方式
4.1hive中的默认
默认文件格式:TextFile(文本文件)
对数据的压缩行为默认是 不开启压缩 的,即数据以原始文本形式存储,不进行压缩处理。
4.2压缩方式选择
ODS层通常选用文本格式
避免因格式转换导致的数据丢失或错误
其他层优先 选用的格式: ORC 压缩策略 snap
ORC 的列存储和索引特性显著提升聚合、过滤等操作的性能。
4.3orc的特点
列式存储
高效压缩
内置索引
包含三级索引(文件级、 stripe 级、行组级
支持复杂类型
原生支持 Hive 中的复杂类型(array、map、struct 等)
ACID 事务支持
Hive 3.0+ 中,ORC 格式支持 ACID 事务(插入、更新、删除),适合需要数据实时更新的场景
4.4orc的数据结构
文件(File):整个 ORC 数据文件
Stripe:文件内的大数据块(默认大小 256MB),包含索引、数据和尾部信息,可独立被读取
Row Group:Stripe 内的行组(默认 10000 行),每个列在 Row Group 中单独存储
列数据(Column Data):按列存储的实际数据,附带编码和压缩信息。
4.5在Hive中使用orc格式
创建orc表
-- 创建表 create table 表名( 列名 类型, ... ... )row format delimited fields terminated by ',' -- stored as textfile -- 默认文本类型 stored as ORC -- 存储格式 TBLPROPERTIES ("orc.compress" = "SNAPPY"); -- 压缩方式
将其他格式数据转换为 ORC
-- 从 textfile 表向 orc 表插入数据 insert into orc表 select 列名1,类名2, ... ... from textfile格式表;
查询orc表
select 列名1,列名2 ... ... from orc表 where id > 100; -- 利用 orc 索引快速定位符合条件的行
注意:
Hive 查询:使用 Hive 读取 ORC 表时,数据会被正确解析,而直接查看文件内容会显示乱码。
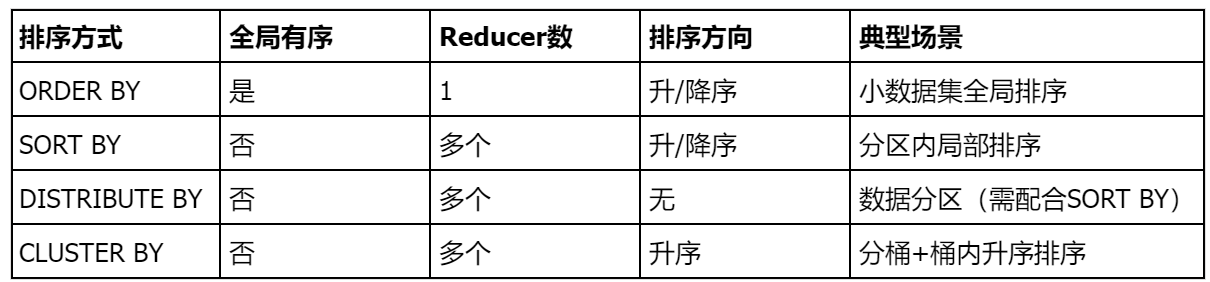
五、Hive的四种排序
5.1全局排序order by
执行逻辑
对查询结果进行全局排序,最终结果只有一个reduce 处理,确保完全有序
5.2分区排序sort by
执行逻辑
对每个reduce处理的数据进行局部排序,全局结果集不保证有序需设置reduce值
set mapreduce.job.reduce=数用法: select * from 表名 sort by 列 decs/asc
5.3自定义分区排序distribute by |sort by
distribute by:按指定列将数据分发到不同的reduce(类似mapreduce分区),分区规则为hash分区
sort by :在每个reduce 内对数据进行排序,需要与distribute by 配合使用
用法: select ... ... distribute by 分区列 sort by 排序列 asc/desc注意事项:
distribute by 必须在sort by 之前
事后需要重置reduce 数=-1,避免影响其他任务
5.4分桶排序cluster by
等价写法: = distribute by + sort by限制:
仅支持单字段排序,且排序方向固定为升序
六、Hive使用技巧
6.1Hive常用交互命令
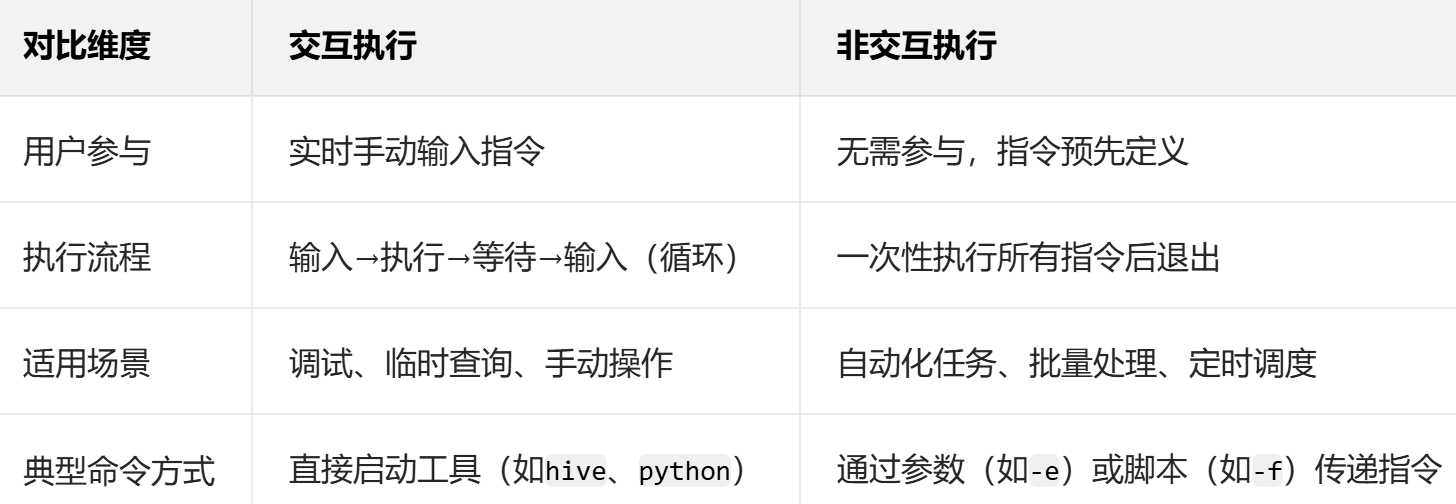
交互执行命令
进入交互界面:
${HIVE_HOME}/bin/hive退出交互界面:
quit
在hive界面命令行输入执行命令
例如:
hive (default)> select * from student;
交互界面 执行命令
非交互执行命令hql语言
完整的执行命令
${HIVE_HOME}/bin/hive [可选参数] -e "SQL语句1; SQL语句2; ..." [输出选项]${HIVE_HOME}/bin/hive:Hive 的可执行文件路径(若已配置环境变量,可直接用 hive);
[可选参数]:如指定数据库、设置参数等(见示例);
指定数据库(避免每次写库名) # 切换到test_db数据库,再执行查询(等效于 use test_db; select ...) hive -e "select * from student;" -database test_db设置 Hive 参数(如压缩、并行度) # 执行查询时启用本地模式,加快小数据处理 hive -hiveconf hive.exec.mode.local.auto=true -e "select count(*) from student;"
-e "...":引号内为要执行的 Hive SQL 语句(支持多条,用分号分隔);
[输出选项]:如将结果输出到文件、格式化显示等。
将结果输出到文件(避免控制台刷屏) # 执行查询并将结果写入result.txt(覆盖写入) hive -e "select id, name from student;" > result.txt格式化输出结果(去除冗余信息) # 只保留查询结果,过滤警告和冗余日志 hive -e "select id, name from student;" 2>&1 | grep -v 'WARN'
在命令行中(shell命令行)执行SQL
${HIVE_HOME}/bin/ --如果配置环境变量可以省略不写
hive -e "命令语句(增删改查等)"mysql -u 用户名 -p 密码(不输入)库名 -e '命令语句(增删改查等)' password:输入密码
把执行的sql放在文件中(.sh/ .sql等)执行SQL
hive -f 路径/文件名 文件里边放命令语句
七、Hive调优与性能优化
7.1SMB(Sort Merge Bucket Map Join)
表连接
Sort Merge Bucket map Join 优化前提:
1 开启强制排序
set hive.enforce.sorting=true;2 开启 SMB map join
set hive.auto.convert.sortmerge.join=true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;3 是否开启自动尝试 SMB
set hive.optimize.bucketmapjoin.sortedmerge = true;- 开启map join
- 分桶列 = 关联列
- 两个表分桶的数一致/整数倍关系
- 排序
7.2桶优化BUCKET MAP JOIN
前提:
1. 开启了mapjoin
set hive.optimize.bucketmapjoin = true;
2. 一个表的bucket数是另一个表bucket数的整数倍.比如我们的例子 人物表和小说表
3. bucket列 == join列(数值类型) 分桶的列=关联列/分桶键
4. 必须是应用在map join的场景中 必须开启mapjoin2个前提条件; 即开启mapjoin和设置阈值;
5. 注意:如果表不是bucket的,则只是做普通join。 2个表必须都是分桶表;
7.3map优化MAP JOIN
--前提开启自动转换参数/开启map 优化
set hive.auto.convert.join=true;--设置表大小阈值
set hive.auto.convert.join.noconditionaltask.size=512000000; (约512MB)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号