
1.优化哲学
1.为什么优化?
为了获得成就感?
为了证实比系统设计者更懂数据库?
为了从优化成果来证实优化者更有价值?
不,这些都不是!!!!!!!!!!!1
通常事实证实的结果往往会和你期待的相反!
优化有风险,涉足需谨慎!!!!
2.优化风险
(1)优化不总是对一个单纯的环境进行!还有很多可能是一个复杂的已投产的系统。
(2)优化手段本来就有很大的风险,只不过你没能力意识到和预见到
(3)任何技术可以解决一个问题,但必然存在带来一个问题的风险!
(4)对于优化来说,解决问题而带来的问题在可接受的范围内才是有成果。
(5)保持现状或出现更差的情况都是失败!
注意:
(1) 稳定性和业务可持续性通常比性能更重要!
(2) 优化不可避免涉及到变更,变更就会有风险!
(3) 优化使性能变好,维持和变差都是同等概率的!
(4) 优化不能只是数据库管理员担当风险,但会所有人分享优化成果!
(5) 所以,优化工作使由业务需要驱使的!!!!
3.谁参与优化
数据库管理员
业务部门代表
应用程序架构师
应用程序设计人员
应用程序开发人员
硬件及系统给管理员
存储管理员
- 优化方向
安全优化(保证业务的持续性)
性能优化(保证业务的高效性)
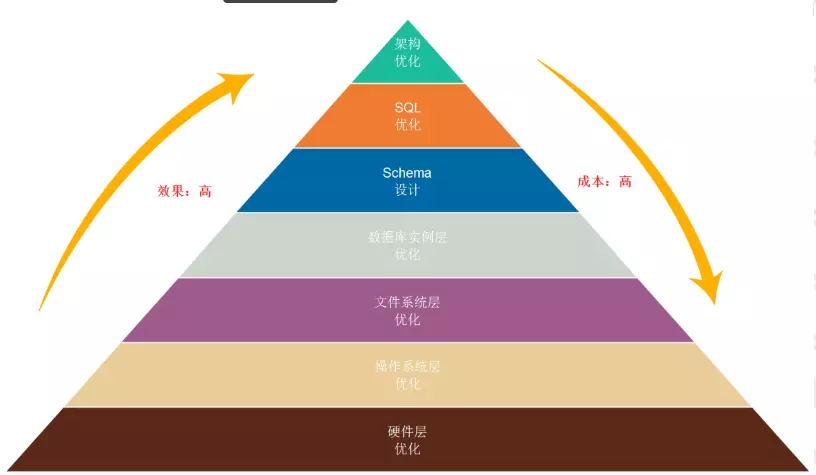
- 优化范围及思路
优化范围:
硬件层优化: 主机、存储、网络等设备
操作系统层: OS核心参数、配置、系统参数
文件系统层: 文件系统的类型对数据的影响,选择合适的
数据库实例层: 数据库实例参数、配置等
Schema层: 主要是库和表的设计是否合理,是否规范
SQL 层: SQL 语句的规范
架构优化
2.优化工具的使用
1.系统层面
1.CPU
top -H 查看线程
top -H -p pid #查看当前进程的线程状态信息
CPU 使用情况
us:用户进程占用CPU时间占比
只要不达到90% ,越高越好,这代表我们的CPU正在被应用程序使用
sy:系统本身和内核工作CPU时间占比
主要是 资源管理,维护,分配,回收等(并发连接过高的时候,此值会变高)
id: 空闲
wa : 等待时CPU时间占比
造成wa 过高的原因可能是:
IO吞吐 有问题: 硬件、链路、RAID
IO/PS 达到峰值 : 大量的随机IO、索引设计不合理、多表查询优化不到位、大量子查询、大事务、锁争用;
2.MEM 内存
1.名称介绍
total: 总内存大小
free: 空闲的
used: 在使用的
buff/cache: 缓冲区和缓存
3.iostat 命令
dd if=/dev/zero of=/tmp/bigfile bs=1M count=4096
使用iostat -dm 1 查看
1.IO高 CPU us 也高,属于正常现象
2.CPU us高 IO 很低,MySQL不再做增删改查,有可能是存储过程,函数,排序,分钟,多表连接
3.Wait,SYS 高, IO 低: IO出问题了,锁等待过多的几率比较大。
IOPS:每秒磁盘做多能发生的IO次数,这个是定值
繁忙小事务,IOPS很高,达到阈值,可能IO吞吐量没超过IO最大吞吐量。没有新的IO
存储规划有问题
4.数据库优化工具
show status
show variables
show index
show processlist
show slave status
show engine innodb status
desc /explain
slowlog
扩展类深度优化:
pt系列
mysqlslap
sysbench
information_schema
performance_schema
sys
5.优化思路分解
1.硬件优化
(1)真实的硬件(PC Server): DELL R系列 ,华为,浪潮,HP,联想
(2)云产品:ECS、数据库RDS、DRDS
(3)IBM 小型机 P6 570 595 P7 720 750 780 P8
CPU根据数据库类型
OLTP 在线事务处理系统
OLAP 数据分析处理
IO密集类型: 线上系统,OLTP主要是IO密集型的业务,高并发
CPU密集型: 数据分析数据处理,OLAP,CPU密集类型的,需要CPU高计算能力(i系列,IBM power系列)
内存
建议2-8倍CPU核心数量(ECC)
磁盘选择
SATA-III SAS Fc SSD(sata) pci-e ssd Flash
主机 RAID卡的BBU(Battery Backup Unit)关闭
存储
根据存储数据种类的不同,选择不同的存储设备
配置合理的RAID级别(raid5、raid10、热备盘)
r0 :条带化 ,性能高
r1 :镜像,安全
r5 :校验+条带化,安全较高+性能较高(读),写性能较低 (适合于读多写少)
r10:安全+性能都很高,最少四块盘,浪费一半的空间(高IO要求)
网络
1、硬件买好的(单卡单口)
2、网卡绑定(bonding),交换机堆叠
以上问题,提前规避掉。
操作系统优化
1.Swap调整
echo 0 >/proc/sys/vm/swappiness的内容改成0(临时),
/etc/sysctl.conf
上添加vm.swappiness=0(永久)
sysctl -p
这个参数决定了Linux是倾向于使用swap,还是倾向于释放文件系统cache。在内存紧张的情况下,数值越低越倾向于释放文件系统cache。
当然,这个参数只能减少使用swap的概率,并不能避免Linux使用swap。
修改MySQL的配置参数innodb_flush_method,开启O_DIRECT模式
这种情况下,InnoDB的buffer pool会直接绕过文件系统cache来访问磁盘,但是redo log依旧会使用文件系统cache。值得注意的是,Redo log是覆写模式的,即使使用了文件系统的cache,也不会占用太多
扩展
扩展:内存管理
1. 三个区域 :
常驻内存集: 程序运行服务的
页缓存page cache:
FREE list
LRU list
匿名页:
2. Slab Allocator
将 page cache 划分成了好多条链状结构.
类型一:
Free list(空闲的)
==================================================
| |
o o
类型二 :
LRU list (正在被使用的)
冷================================================热
i i
0 0
3. buddy system (内存伙伴系统)
内存回收和重利用
cat /proc/sys/vm/swappiness ====> 0
free list 上为 0;
buddy system 进行内存回收和重利用
1. 优先释放 Cache(负责查询类的内存结构),从冷到热进行释放.
2. Cache没法释放时,会根据buffer从冷导热,进行回收和重用内存
3. 所有可被释放 buffer 或cache,已经全部被回收重用了,还是内存紧缺的话
此时,swap还是会被使用.
内存泄露问题:
8G 使用率达到了 95%以上
innodb_buffer_pool_size=2G
redo_buffer_size=256M
其他内存总共: 1G 左右
innodb_flush_log_at_trx_commit=1
innodb_flush_method=O_DIRECT
IO调度策略
在centos7中 默认是 deadline(最后期限)
查看命令
cat /sys.block/sda/queue/scheduler
#临时修改为deadline (centos 6)
echo deadline > /sys/block/sda/queue/scheduler
vi /boot/grub/grub.conf
kernel /boot/vmlinuz-2.6.18-8.e15 ro root=LABEL=/ elevator=deadline rhgb quiet
其他和IO相关的:
raid:最好使用read10
不要使用lvm
最好使用xfs或者ext4文件系统
使用性能比较高的硬盘
IO调度策略
提前规划好以上所有的问题,减轻MySQL优化难度。
3.3 应用层
1.开发过程规范,标准
2.减少烂SQL:就是不走索引,逻辑复杂,大事务等
like '%aa%'
!= not in
limit >500w
DDL ---> show processlist ; ---> kill ---> Online DDL ,pt-osc
delete 大量数据. ----> pt-archive
update : 索引 , 锁.
3.避免业务逻辑错误,避免锁争用
这个阶段,需要我们DBA深入业务,或是要和开发人员、业务人员配合实现
优化,最根本是‘优化人’
-- oldguo

 浙公网安备 33010602011771号
浙公网安备 33010602011771号