
1.介绍
相当于一本书中的目录,方便我们找到想要的页码
索引的作用:优化查询
2.MySQL索引的类型
按照算法:
BTREE ******
HASH
FULLTEXT
RTREE
GIS
3,索引算法的演变
BTREE讲究的是查找数据的平衡
BTREE的目的:快速锁定范围
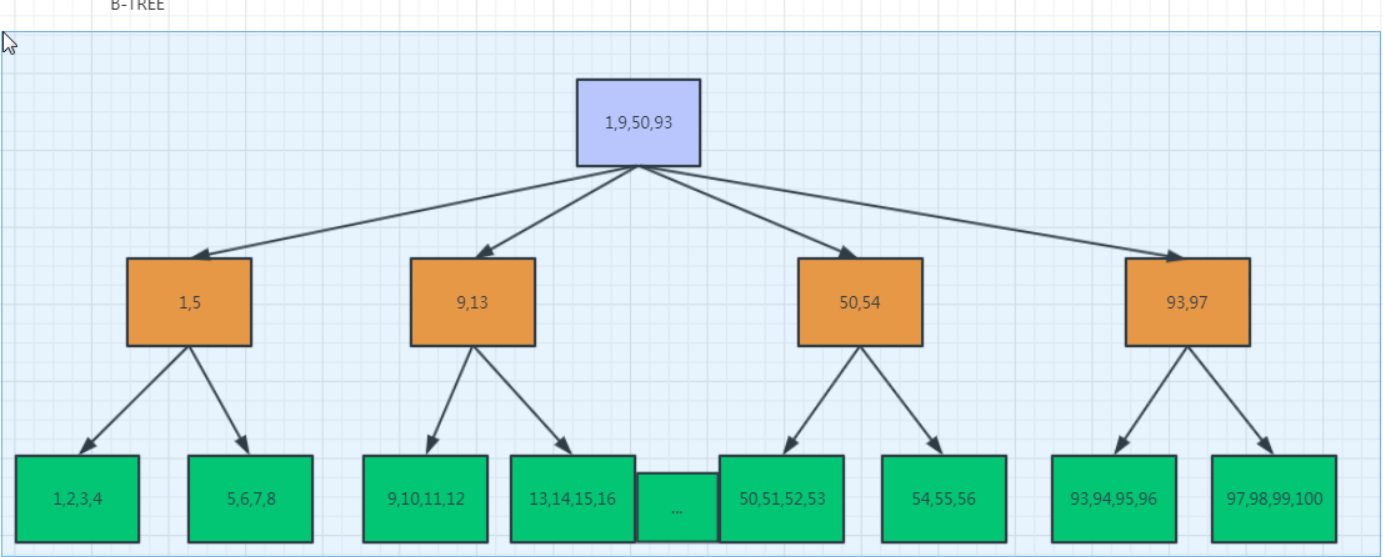
B+TREE:范围查询
大于等于;小于等于
BTREE的增强之路
B-TREE -----------> 叶子节点双向指针---------------------->直接增加双向指针-------------->B+TREE
3.BTREE 数据结构构建过程 *****
1.数据排序(默认从小到大)
2.将数据有序的存储到数据页上(16KB),生成叶子节点(leaf node)
3.通过叶子节点范围(最小值,到下个叶子节点的最小值),+ 每个叶子节点的指针生成non-leaf节点(16KB,枝节点)
4.通过non-leaf节点的范围(最小值到下一个non-leaf节点最小值)+每个 non-leaf指针生成root(根节点)
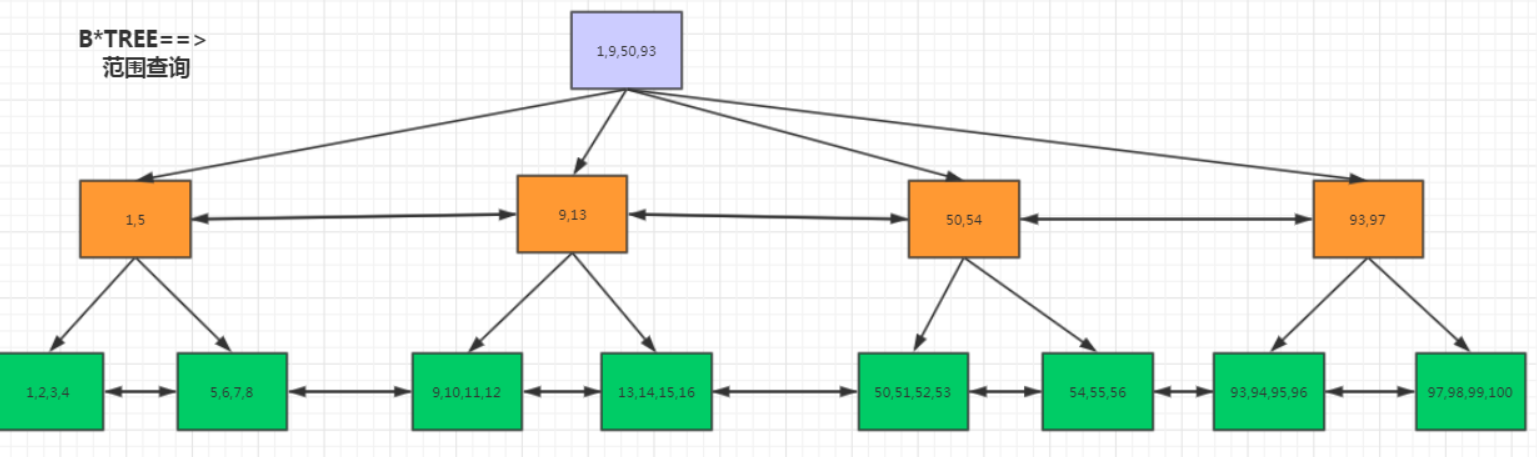
5.B*TREE中,为了进一步优化范围查询,加入了leaf双向指针,non-leaf双向指针
1.减少索引IO次数,有效的减少IOPS每秒的定值
2.减少了随机IO的数量
3.减少了IO的量级
4.MySQL的索引组织表 (InnoDB引擎)******
1. Clusterd Index: 聚簇索引(聚集,集群)
前提:
1. MySQL默认选择主键列构建聚簇索引 BTREE。
2. 如果没有主键,自动选择第一个唯一值的列,构建BTREE结构。
3. 没有主键,没有唯一列,会自动按照rowid生成聚簇索引。
说明:
1. 聚簇索引,叶子节点,保存的是原始的数据页,保存的是表的整行数据
2. 为了保证我们的索引是“矮胖结构”,我们的枝节点和根节点,只保存ID的列值范围+下层指针
2. Secondary Index: 辅佐索引(二级)
构建过程: alter table t1 add index idx(name);
1. 提取name+id列的所有值
2. 按照name自动排序,有序的存储到连续的数据页上,生成叶子节点
3. 只提取叶子节点name范围 + 指针,生成枝节点和根节点
3. 针对 name 列的查询,是如何优化?
select * from t1 where name='bgx';
1. 按照查询条件bgx,来到基于 name 列构建的辅助索引进行遍历
理论上读取page为3次,找到主键值
2.根据ID值(主键),回倒聚簇索引树,继续遍历,进而找到数据行。
理论读取额数据页为3次。
5.辅助索引细分
1.单列索引
最普通的就是单列索引
2.联合索引
作用:
1.理论上可以有效地避免回表的次数。
3.唯一索引
手机号,身份证号类似的列。理论上通过唯一索引作为遍历条件,理论上读取6个 page 即可获取数据行。
6.索引树高度问题,影响索引数高度的原因
1. 数据量级大,行数多
解决方法:
分区表(用的较少,对锁有影响)
归档表
分库分表
2. 选取的索引列值过长
解决方法:
前缀索引
3. varchar(64) char(64) enum()等数据类型的影响
使用varchar而不是char的原因:二八原则,char在插入的时候比较合适,但是查询就不方便,建议使用varchar
使用enum的原因:计算机对数字比较敏感,而且,数字占用空间少。
7索引管理操作
1.查询索引
desc table;
key:
PRI : 主键
UNI : 唯一索引
MUL : 普通索引
2. 创建索引
例子:
--- 1. 单例索引的例子
select * from city where population > 100000 为这条语句创建索引
索引设计
alter table city add index idx_popu(population);
说明:
1. 作为查询条件比较多的列
2. 经常作为 group by , order by ,distint(去重复),union的列 创建索引。
--- 2. 联合索引例子
select * from city where district='shandong' and name='jinan';
索引设计
alter table city add index idx_dis_name(district,name);
说明:
对于联合索引排列顺序,从左到右,重复值少的列,优先放在最左边。
--- 3.前缀索引应用(一定是字符串列)
alter table city add index idx_name(name(5)); 以前5个字符作为索引
--- 4.唯一索引(在普通索引上加入 unique)
alter table student add unique index idx_tel(xtel);
查看表中的索引
show index table city;
8.删除索引
alter table city drop index idx_name;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号