
⑰.nginx会话保持sticky模块 upstream_healthy健康检查模块
一. 会话保持sticky模块
情景: nginx的调度算法为rr wrr least_conn url_hash时,每次的访问不能沾滞到同一台服务器上
任务: 每次的请求都沾滞到同一台服务器上 不采用ip_hash调度算法 nginx负载均衡服务器前边如果是CDN会造成流量的倾斜
经过: 通过资料查找,发现Sticky模块能达到需求 它的工作原理是在server返回给client的cookie时 也向client段返回key为route的cookie cookie是后端的某台服务器
结果: 经过测试符合要求 如果采用rr wrr least_conn url_hash调度算法时,请求和沾滞到后端的同一台服务器
在多台后台服务器的环境下,我们为了确保一个客户只和一台服务器通信,我们势必使用长连接。使用什么方式来实现这种连接呢,常见的有使用nginx自带的ip_hash来做,我想这绝对不是一个好的办法,如果前端是CDN,或者说一个局域网的客户同时访问服务器,导致出现服务器分配不均衡,以及不能保证每次访问都粘滞在同一台服务器。如果基于cookie会是一种什么情形,想想看, 每台电脑都会有不同的cookie,在保持长连接的同时还保证了服务器的压力均衡,nginx sticky值得推荐。
如果浏览器不支持cookie,那么sticky不生效,毕竟整个模块是给予cookie实现的.
Nginx 基于nginx-sticky-module模块进行会话保持
sticky介绍
Sticky模块与Ip_hash都是与负载均衡算法相关,但又有差别,差别是ip hash,根据客户端的IP,将请求分配到不同的服务器上 sticky,根据服务器给客户端的cookie,客户端再次请求时会带上此cookie,nginx会把有此cookie的请求转发到颁发cookie的服务器上
sticky原理
Sticky是基于cookie的一种负载均衡解决方案,通过分发和识别cookie,使来自同一个客户端的请求落在同一台服务器上,默认cookie标识名为route :
客户端首次发起访问请求,nginx接收后,发现请求头没有cookie,则以轮询方式将请求分发给后端服务器。 后端服务器处理完请求,将响应数据返回给nginx。 此时nginx生成带route的cookie,返回给客户端。route的值与后端服务器对应,可能是明文,也可能是md5、sha1等Hash值。 客户端接收请求,并保存带route的cookie。 当客户端下一次发送请求时,会带上route,nginx根据接收到的cookie中的route值,转发给对应的后端服务器。
sticky官网
官方地址:https://bitbucket.org/nginx-goodies/nginx-sticky-module-ng/src 下载地址:https://bitbucket.org/nginx-goodies/nginx-sticky-module-ng/get/master.tar.gz
注意点
同一客户端,如果启动时同时发起多个请求,有可能落在不同的后端服务器上。 由于cookie最初由服务器端下发,如果客户端禁用cookie,则cookie不会生效。 客户端可能不带cookie,Android客户端发送请求时,一般不会带上所有的cookie,需要明确指定哪些cookie会带上。如果希望用sticky做负载均衡,请对Android开发说加上cookie。 cookie名称不要和业务使用的cookie重名。Sticky默认的cookie名称是route,可以改成任何值 客户端发的第一个请求是不带cookie的。服务器下发的cookie,在客户端下一次请求时才能生效。 Nginx sticky模块不能与ip_hash同时使用
Nginx安装Sticky模块
如果你还没有部署Nginx,那么就在部署Nginx的时候进行 --add-module 添加上此模块就行了,我这里是Nginx已经安装过了,需要再把此模块加载进NGINX
1.1下载nginx及sticky
wget http://nginx.org/download/nginx-1.20.0.tar.gz
wget https://bitbucket.org/nginx-goodies/nginx-sticky-module-ng/get/master.tar.gz
tar xf master.tar.gz
cd master
把此模块放进nginx/module目录下,名称太长,重命名一下
mkdir /usr/local/nginx-1.20.0/module
mv nginx-goodies-nginx-sticky-module-ng-08a395c66e42 /usr/local/nginx-1.20.0/module/nginx-sticky-module
1.2.重新编译NGINX 下载一个NGINX后重新解压,然后看之前NGINX编译了那些模块,这里都给加上,在最后加上 --add-module载入sticky模块
cd /usr/local/nginx-1.20.0
./configure --prefix=/usr/local/nginx \
--sbin-path=/usr/local/nginx/sbin/nginx \
--conf-path=/usr/local/nginx/conf/nginx.conf \
--pid-path=/usr/local/nginx/run/nginx.pid \
--error-log-path=/usr/local/nginx/logs/error.log \
--http-log-path=/usr/local/nginx/logs/access.log \
--with-pcre \
--user=nginx \
--group=nginx \
--with-stream \
--with-threads \
--with-file-aio \
--with-http_v2_module \
--with-http_ssl_module \
--with-http_realip_module \
--with-http_gzip_static_module \
--with-http_stub_status_module \
--add-module=/usr/local/nginx-1.20.0/module/nginx-sticky-module #在此载入sticky模块
./configure完后进行编译,然后更换 nginx 程序
make
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old
cp -rf objs/nginx /usr/local/nginx/sbin/
最后再 make upgrade 进行更新检测
[root@nginx_proxy02 nginx-1.20.0]# make upgrade
/usr/local/nginx/sbin/nginx -t
nginx: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /usr/local/nginx/conf/nginx.conf test is successful
kill -USR2 `cat /usr/local/nginx/run/nginx.pid`
sleep 1
test -f /usr/local/nginx/run/nginx.pid.oldbin
kill -QUIT `cat /usr/local/nginx/run/nginx.pid.oldbin`
以上就完成了Nginx载入第三方模块,使用 nginx -V 来查看是否载入成功
1.3.修改NGINX配置文件 修改NGINX配置文件来启用sticky
upstream backend {
sticky name=ngx_cookie expires=6h;
server 192.168.31.240:8080 weight=3 max_fails=3 fail_timeout=10s;
server 192.168.31.241:8080 weight=3 max_fails=3 fail_timeout=10s;
server 192.168.31.242:8080 weight=6 max_fails=3 fail_timeout=10s;
server 192.168.31.243:8080;
server 192.168.31.244:8080 down;
}
mkdir /usr/local/nginx/ngx_cookie
1.4.sticky语法解析
指令 描述 name 设置记录cookie的名称(可自定义),默认为route domain 设置cookie要使用的域名 path 设置cookie作用的URL路径,默认根目录 expires 设置cookie的生存期 hash 值为 index、md5、sha1,对应明文、md5、和sha1,默认md5,测试sha1后端服务器会变 no_fallback 当sticky的后端机器挂了以后,nginx返回502,而不转发到其他服务器,不建议设置 secure 设置启用安全的cookie,需要HTTPS支持 httponly 允许cookie不通过JS泄漏
1.5.重启NGINX
/usr/local/nginx/sbin/nginx -s reload
测试访问NGINX
第一次访问的时候是没有Cookie的,访问完成后NGINX才会把Cookie包含在返回的数据中,在下次请求数据的时候就会出现Cookie。 所以刷新一下后才能看到Cookie。
二、nginx_upstream_check_module模块
除了自带的上述模块,还有一个更专业的模块,来专门提供负载均衡器内节点的健康检查的。这个就是淘宝技术团队开发的 nginx 模块 nginx_upstream_check_module,通过它可以用来检测后端 realserver 的健康状态。如果后端 realserver 不可用,则所以的请求就不会转发到该节点上。
在淘宝自己的 tengine 上是自带了该模块的,大家可以访问淘宝tengine的官网来获取该版本的nginx,官方地址:http://tengine.taobao.org/ 。
如果我们没有使用淘宝的 tengine 的话,可以通过补丁的方式来添加该模块到我们自己的 nginx 中。我们业务线上就是采用该方式进行添加的。
下面是部署流程!
2.1、下载 nginx_upstream_check_module模块
[root@localhost ~]# cd /usr/local/nginx-src-1.22.0
[root@localhost /usr/local/nginx-src-1.22.0]# git clone https://github.com/yaoweibin/nginx_upstream_check_module.gi
2.2、为nginx打补丁
[root@localhost /usr/local/nginx-src-1.22.0]# patch -p1 < ./nginx_upstream_check_module/check_1.20.1+.patch
[root@localhost /usr/local/nginx-src-1.22.0]# ./configure --prefix=/usr/local/nginx-1.22 --user=www --group=www --with-http_ssl_module --with-http_stub_status_module --add-module=./nginx_upstream_check_module
[root@localhost /usr/local/nginx-src-1.22.0]# make (注意:此处只make,编译参数需要和之前的一样)
[root@localhost /usr/local/nginx-src-1.22.0]# mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx-1.22.0.bak
[root@localhost /usr/local/nginx-src-1.22.0]# cp ./objs/nginx /usr/local/nginx/sbin/
[root@localhost /usr/local/nginx-src-1.22.0]# /usr/local/nginx/sbin/nginx -t # 检查下是否有问题
[root@localhost /usr/local/nginx-src-1.22.0]# kill -USR2 `cat /usr/local/nginx/logs/nginx.pid`
2.3、在nginx.conf配置文件里面的upstream加入健康检查,如下:
upstream name {
server 192.168.0.21:80;
server 192.168.0.22:80;
check interval=3000 rise=2 fall=5 timeout=1000 type=http;
}
上面 配置的意思是,对name这个负载均衡条目中的所有节点,每个3秒检测一次,请求2次正常则标记 realserver状态为up,如果检测 5 次都失败,则标记 realserver的状态为down,超时时间为1秒。
这里列出 nginx_upstream_check_module 模块所支持的指令意思:
Syntax: check interval=milliseconds [fall=count] [rise=count] [timeout=milliseconds] [default_down=true|false] [type=tcp|http|ssl_hello|mysql|ajp] [port=check_port]
Default: 如果没有配置参数,默认值是:interval=30000 fall=5 rise=2 timeout=1000 default_down=true type=tcp
Context: upstream
该指令可以打开后端服务器的健康检查功能。
指令后面的参数意义是:
- interval:向后端发送的健康检查包的间隔。
- fall(fall_count): 如果连续失败次数达到fall_count,服务器就被认为是down。
- rise(rise_count): 如果连续成功次数达到rise_count,服务器就被认为是up。
- timeout: 后端健康请求的超时时间。
- default_down: 设定初始时服务器的状态,如果是true,就说明默认是down的,如果是false,就是up的。默认值是true,也就是一开始服务器认为是不可用,要等健康检查包达到一定成功次数以后才会被认为是健康的。
- type:健康检查包的类型,现在支持以下多种类型
- tcp:简单的tcp连接,如果连接成功,就说明后端正常。
- ssl_hello:发送一个初始的SSL hello包并接受服务器的SSL hello包。
- http:发送HTTP请求,通过后端的回复包的状态来判断后端是否存活。
- mysql: 向mysql服务器连接,通过接收服务器的greeting包来判断后端是否存活。
- ajp:向后端发送AJP协议的Cping包,通过接收Cpong包来判断后端是否存活。
- port: 指定后端服务器的检查端口。你可以指定不同于真实服务的后端服务器的端口,比如后端提供的是443端口的应用,你可以去检查80端口的状态来判断后端健康状况。默认是0,表示跟后端server提供真实服务的端口一样。该选项出现于Tengine-1.4.0。
Syntax: check_keepalive_requests request_num
Default: 1
Context: upstream
该指令可以配置一个连接发送的请求数,其默认值为1,表示Tengine完成1次请求后即关闭连接。
Syntax: check_http_send http_packet
Default: "GET / HTTP/1.0\r\n\r\n"
Context: upstream
该指令可以配置http健康检查包发送的请求内容。为了减少传输数据量,推荐采用"HEAD"方法。
当采用长连接进行健康检查时,需在该指令中添加keep-alive请求头,如:"HEAD / HTTP/1.1\r\nConnection: keep-alive\r\n\r\n"。 同时,在采用"GET"方法的情况下,请求uri的size不宜过大,确保可以在1个interval内传输完成,否则会被健康检查模块视为后端服务器或网络异常。
Syntax: check_http_expect_alive [ http_2xx | http_3xx | http_4xx | http_5xx ]
Default: http_2xx | http_3xx
Context: upstream
该指令指定HTTP回复的成功状态,默认认为2XX和3XX的状态是健康的。
Syntax: check_shm_size size
Default: 1M
Context: http
所有的后端服务器健康检查状态都存于共享内存中,该指令可以设置共享内存的大小。默认是1M,如果你有1千台以上的服务器并在配置的时候出现了错误,就可能需要扩大该内存的大小。
Syntax: check_status [html|csv|json]
Default: check_status html
Context: location
显示服务器的健康状态页面。该指令需要在http块中配置。
在Tengine-1.4.0以后,你可以配置显示页面的格式。支持的格式有: html、csv、 json。默认类型是html。
你也可以通过请求的参数来指定格式,假设‘/status’是你状态页面的URL, format参数改变页面的格式,比如:
/status?format=html
/status?format=csv
/status?format=json
同时你也可以通过status参数来获取相同服务器状态的列表,比如:
/status?format=html&status=down
/status?format=csv&status=up
下面是一个状态也配置的范例:
upstream healthy_nginx {
server 127.0.0.1:81 weight=5;
server 127.0.0.1:82 weight=5;
#以10s为一个周期,每隔10snginx会自动向上游服务器发送一次请求,如果超过5s超时且达到3次,则该服务器标记为不可用;
#如果请求次数有一次以上没有超时,这标记为可用
check interval=6000 rise=1 fall=3 timeout=2000 type=tcp default_down=true;
check_http_send "HEAD / HTTP/1.1\r\nConnection: keep-alive\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}
server {
listen 80;
server_name healthy.yangtao.com;
keepalive_timeout 60;
location / {
proxy_connect_timeout 60;#与上游服务器的连接超时时间
proxy_read_timeout 60;#与上游服务器的读取超时时间
proxy_send_timeout 60;#与上游服务器的发送超时时间
proxy_pass http://healthy_nginx;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host:$server_port;
}
#健康监控页面
location /status {
check_status ;
access_log off;
}
}
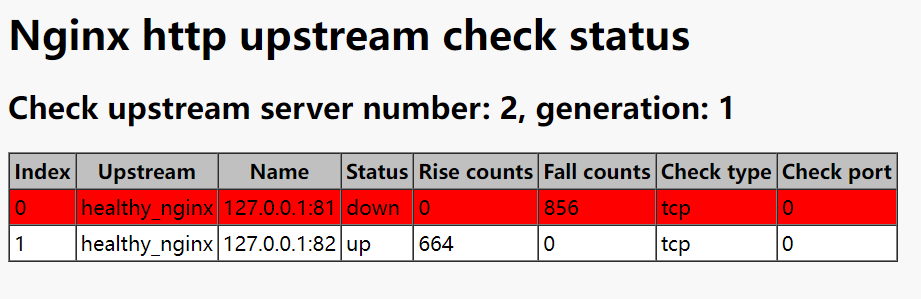
配置完毕后,重启nginx。此时通过访问定义好的路径,就可以看到当前 realserver 实时的健康状态啦。效果如下图:
realserver 都正常的状态:

一台 realserver 故障的状态:
OK,以上nginx_upstream_check_module模块的相关信息,更多的信息大家可以去该模块的淘宝tengine页面和github上该项目页面去查看,下面是访问地址:
http://tengine.taobao.org/document_cn/http_upstream_check_cn.html
https://github.com/yaoweibin/nginx_upstream_check_module
在生产环境的实施应用中,需要注意的有 2 点:
1、主要定义好type。由于默认的type是tcp类型,因此假设你服务启动,不管是否初始化完毕,它的端口都会起来,所以此时前段负载均衡器为认为该服务已经可用,其实是不可用状态。
2、注意check_http_send值的设定。由于它的默认值是"GET / HTTP/1.0\r\n\r\n"。假设你的应用是通过http://ip/name访问的,那么这里你的 check_http_send值就需要更改为 "GET /name HTTP/1.0\r\n\r\n"才可以。针对采用长连接进行检查的, 这里增加 keep-alive请求 头,即"HEAD /name HTTP/1.1\r\nConnection: keep-alive\r\n\r\n"。如果你后端的tomcat是基于域名的多虚拟机,此时你需要通过 check_http_send定义host,不然每次访问都是失败,范例:check_http_send "GET /mobileapi HTTP/1.0\r\n HOST www.redhat.sx\r\n\r\n";
三、 ngx_http_healthcheck_module模块
除了上面两个模块,nginx官方在早期的时候还提供了一个 ngx_http_healthcheck_module 模块用来进行 nginx后端节点的健康检查。 nginx_upstream_check_module模块就是参照 该模块的设计理念进行开发的,因此在使用和效果上都大同小异。但是需要注意的是, ngx_http_healthcheck_module 模块仅仅支持nginx的1.0.0版本,1.1.0版本以后都不支持了!因此,对于目前常见的生产环境上都不会去用了,这里仅仅留个纪念,给大家介绍下这个模块!
具体的使用方法,这里可以贴出几篇靠谱的博文地址以及官方地址:
http://wiki.nginx.org/HttpHealthcheckModule
https://github.com/cep21/healthcheck_nginx_upstreams/blob/master/README

 浙公网安备 33010602011771号
浙公网安备 33010602011771号