到年底了,想着总结下所有知识点好了~今年应用的知识点还是很多的~
![]()
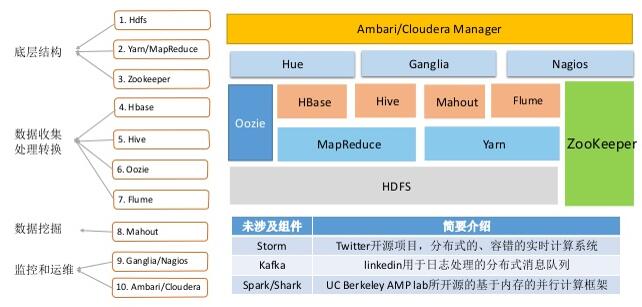
Hadoop生态圈:
1、文件存储当然是选择Hadoop的分布式文件系统HDFS,当然因为硬件的告诉发展,已经出现了内存分布式系统Tachyon,不论是Hadoop的MapReduce,Spark的内存计算、hive的MapReuduce分布式查询等等都可以集成在上面,然后通过定时器再写入HDFS,以保证计算的效率,但是毕竟还没有完全成熟。
2、那么HDFS的文件存储类型为SequenceFile,那么为什么用SequenceFile呢,因为SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件,能够加速MapReduce文件的读写。但是有个问题,SequenceFile文件并不保证其存储的key-value数据是按照key的某个顺序呢存储的,同时不支持append操作。
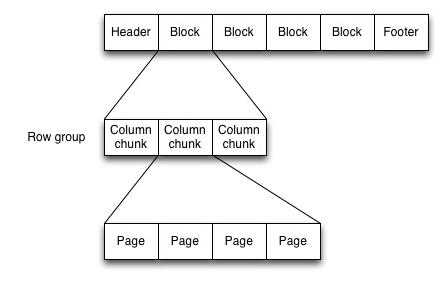
当然,如果选择Spark的话,文件存储格式首选为列式存储parquet,因为一个Parquet文件是由一个header以及一个或多个block块组成,以一个footer结尾。header中只包含一个4个字节的数字PAR1用来识别整个Parquet文件格式。文件中所有的metadata都存在于footer中。footer中的metadata包含了格式的版本信息,schema信息、key-value paris以及所有block中的metadata信息。footer中最后两个字段为一个以4个字节长度的footer的metadata,以及同header中包含的一样的PAR1。不像sequence files以及Avro数据格式文件的header以及sync markers是用来分割blocks。Parquet格式文件不需要sync markers,因此block的边界存储与footer的meatada中,查询效率非常快。
![]()
3、zookeeper的作用帮助Yarn实现HA机制,它的主要作用是:
(1)创建锁节点,创建成功的ResourceManager节点会变成Active节点,其他的切换为StandBy.
(2)主备切换,当Active的ResourceManager节点出现异常或挂掉时,在zookeeper上创建的临时节点也会被删除,standy的ResourceManager节点检测到该节点发生变化时,会重新发起竞争,直到产生一个Active节点。(这里会有个脑裂问题,后续说明),那么zookeeper的参数包含在zoo.cfg中(具体参考本博客中的zookeeper配置)
4、Yarn组件:这个可就大了,运行在独立的节点上的ResourceManager和NodeManager一起组成了yarn的核心,构建了整个资源管理平台。ResourceManager提供应用程序的调度,每个应用程序由一个ApplicationMaster管理,以Container的形式请求每个任务的计算资源。Container由ResourceMangaer调度,由每个节点的NodeManager上进行本地的管理。 所有MapReduce以及Spark的Job都是提交给Yarn进行资源申请。(具体参考博客Hadoop on Yarn各组件详细原理),那么权限与资源控制主要依赖于Yarn的标签机制,可以控制比如Spark作业在Spark的资源队列,Hadoop作业在Hadoop的资源队列。
5、Hive组件:Hive的ETL主要用于数据的清洗与结构化,可从每日将传统数据库中导出的文件,创建一个Web工程用来读入文件,使用JDBC的方式连接HiveServer2,进行数据的结构化处理。这里有一些加快效率但是会占用更多资源的参数,比如set hive.exec.parallel=true,该参数会让那些存在并发job的sql运行的更快,但同时消耗更多的资源,或者set hive.exec.parallel.thread.number,加大并行度,但会占用更多的map和reduce的资源。
6、Hbase组件:HBase的服务器体系结构遵从简单的主从服务器架构,它由HRegion服务器(HRegion Service)群和HBase Master服务器(HBase Master Server)构成。Hbase Master服务器负责管理所有的HRegion服务器,而Hbase中所有的服务器是通过Zookeeper来进行协调,并处理HBase服务器运行期间可能遇到的错误的。那么从应用上来说,hbase使用的场景更适用于,例如流处理中的日志记录的单条记录追加,或是单条结果的查询,但对于需要表关联的操作,hbase就变得力不从心了,当然可以集成于hive,但查询效率嘛。。。
Hbase最重要的是rowkey的设计,怎样预分区能够让数据均匀散列在各个节点。同时,要注意的是使用hbase过滤器的话,依旧会scan全表。
7、Hue组件:主要是前台的查询,它支持很多可视化的展示啊,sql查询啊。方便一般的数据分析人员使用。
8、Ambari组件:各个组件都可以集成于它,属于一个统一的监控软件,包括安装部署,参数调整都可以在Ambari界面完成。
Spark的生态圈组件:
我们选用的是集成于Hadoop的spark on Yarn模式:
下面一一介绍Spark On Yarn的各组件:
1、SparkSql组件:从Spark 1.0版本起,Spark开始支持Spark SQL,它最主要的用途之一就是能够直接从Spark平台上面获取数据。并且Spark SQL提供比较流行的Parquet列式存储格式以及从Hive表中直接读取数据的支持。
之后,Spark SQL还增加了对JSON等其他格式的支持。到了Spark 1.3 版本Spark还可以使用SQL的方式进行DataFrames的操作。我们通过JDBC的方式通过前台业务逻辑执行相关sql的增删改查,通过远程连接linux对文件进行导入处理,使项目能够初步支持Spark平台,现如今已支持Spark2.0.2版本。
它拥有自己的sql解析引擎Catalyst,提供了提供了解析(一个非常简单的用Scala语言编写的SQL解析器)、执行(Spark Planner,生成基于RDD的物理计划)和绑定(数据完全存放于内存中)。使用ThriftServer连接后台SparkSQL,它是一个JDBC/ODBC接口,通过配置Hive-site.xml,就可以使前台用JDBC/ODBC连接ThriftServer来访问SparkSQL的数据。ThriftServer通过调用hive元数据信息找到表或文件信息在hdfs上的具体位置,并通过Spark的RDD实现了hive的接口。加快前台的查询或者限制后台ETL数据清洗时所占用的资源与内存数量。
2、SparkStreaming组件:SparkStreaming接收实时输入数据流并将它们按批次划分,然后交给Spark引擎处理生成按照批次划分的结果流。SparkStreaming提供了表示连续数据流的、高度抽象的被称为离散流的Dstream,可以使用kafka、Flume和Kiness这些数据源的输入数据流创建Dstream,也可以在其他Dstream上使用map、reduce、join、window等操作创建Dsteram。Dstream本质上呢,是表示RDD的序列。 那么它的适用场景在于准实时的日志分析,或数据接入处理。
3、SparkR: 我表示。。没用过~~~~啊哈哈哈~(后续学习)
4、SparkML:包含用于机器学习或数据分析的算法包。在Spark后台批处理代码中,或SparkStreaming中都可以集成,用于更多的数据分析。(后续学习)
总结:
整个Hadoop生态圈与Spark生态圈的批处理应用流程就可以整理出来了:
1、首先由每日从传统数据库中导出的数据文件,由Spark后台处理代码进行数据的处理,或由用Java编写的前台代码连接thrift进行数据的结构化。
2、通过Spark连接mysql数据表,进行后台数据处理生成各平台需要的数据类型与种类导入Hbase、Redis或生成Hive表等等。
3、由数据分析人员运用R或ive或SparkR、ML进行数据分析。
4、sparkStreaming通过接受kafka的数据,进行数据处理或分析,也可以通过监听HDFS文件目录来进行数据的定时处理。
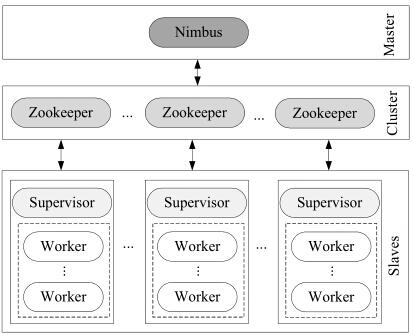
实时项目组件:
实时项目呢,主要包含的组件有Storm、Redis、Kafka、Jetty、Netty,keepalive,nignx等。(图木有画哈哈),那么下来一一进行说明。
1、Redis: Redis包括集群模式、哨兵模式、由Twemproxy实现的代理模式。主要服务于实时系统的数据加载,并且将大部分系统配置信息都存入Redis,,走全内存可以使每条消息的延迟降低。因为Redis没有分布式锁,可以使用setnx标志位来实现分布式锁的功能。
2、jetty:轻量级的servlet,可部署多份,每份里面接入网管发送的数据,数据的存储可存储与BlockingQueue中,由多个线程拉取数据,进行数据的预处理。
3、ngnix与keepalive:keepalive的作用主要用于设置虚拟IP,ngnix进行消息的负载均衡,发送至各服务器的jetty。
4、kafka: Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。
kafka和JMS(Java Message Service)实现(activeMQ)不同的是:即使消息被消费,消息仍然不会被立即删除.日志文件将会根据broker中的配置要求,保留一定的时间之后删除;比如log文件保留2天,那么两天后,文件会被清除,无论其中的消息是否被消费.kafka通过这种简单的手段,来释放磁盘空间,以及减少消息消费之后对文件内容改动的磁盘IO开支.
那么继续我们的流程,又Jetty接入的消息,发送至不同的kafka主题,供下面storm进行消费。
5、Storm:主要的编程概念:spout、blot和topology,我们需要根据数据的并发量来决定启动多少个worker和calc,首先由Spout进行消息的接入,进行数据预处理与加载,刚才我们说了,走全内存,直接走Redis,但是如果Redis挂掉了怎么办呢,那么就备选用hbase~blot中实现主要的业务逻辑,消息的封装啊。 这里需要注意的是,我们不要把所有类型的事件都写入一个topo,那么消息延迟的概率会很大,对于不同的事件进行不同消息的封装处理。
总结:
对于整个实时项目需要注意的就是数据的封装与解析,怎样提高效率,怎样能够让各个模块儿解耦,走全内存、日志收集及问题等等。
辅助组件:
1、Ansible:ansible是新出现的自动化运维工具,基于Python开发,集合了众多运维工具(puppet、cfengine、chef、func、fabric)的优点,实现了批量系统配置、批量程序部署、批量运行命令等功能。
2、ganglia:Ganglia是UC Berkeley发起的一个开源集群监视项目,设计用于测量数以千计的节点。Ganglia的核心包含gmond、gmetad以及一个Web前端。主要是用来监控系统性能,如:cpu 、mem、硬盘利用率, I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性能起到重要作用。






 浙公网安备 33010602011771号
浙公网安备 33010602011771号