Pytorch 4.3 多层感知机的框架实现
多层感知机的框架实现(同Softmax框架实现一毛一样,只是添加一个仿射函数变换(隐藏层)而已)
step1.引入框架
import torch
from torch import nn
from d2l import torch as d2l
step2.设计模型和初始化参数
# 假定我们设置的 hidden layer 有256个单元
net = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=784 ,out_features=256),
nn.ReLU(),
nn.Linear(in_features=256,out_features=10)
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(tensor= m.weight, mean=0,std=0.01)
net.apply(init_weights)
出现如下的配置信息说明我们的模型初始化成功,我们执行训练的时候会按照这个循序进行循环
Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=256, bias=True)
(2): ReLU()
(3): Linear(in_features=256, out_features=10, bias=True)
)
ster3.设置学习率等参数进行学习
batch_size, lr, num_epochs = 256,0.1,10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
等待片刻候得到:
之前我们说过了,不同的激活函数在使用的时候会有不同,那么这一种不同到底体现在什么地方呢?
Task1:添加一个隐藏层观察有何不同。
# 只需要修改下模型的结构即可,其他东西都是一样的
num_input ,num_output= 784,10
num_hidden01,num_hidden02 = 128,128
net = nn.Sequential(
nn.Flatten(), # 展平层,降维
nn.Linear(num_input,num_hidden01),
nn.ReLU(),
nn.Linear(num_hidden01,num_hidden02),
nn.ReLU(),
nn.Linear(num_hidden02,num_output),
)
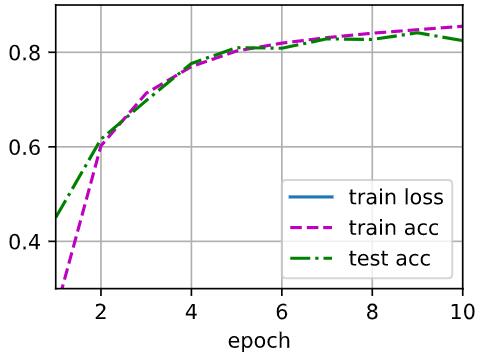
我们通过给模型net添加一层Liner变换来添加隐藏层,通过增加隐藏层,开始的时候或许拟合的比较慢,但是拟合效果很好,增加了隐藏层,那么就需要通过更多的迭代次数来获得更好的拟合效果。
Task2:将激活函数换成 Sigmoid ,tanh,Softmax观察有何不同。
# Sigmoid 激活函数
net = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=784 ,out_features=256),
nn.Sigmoid(),
nn.Linear(in_features=256,out_features=10)
)
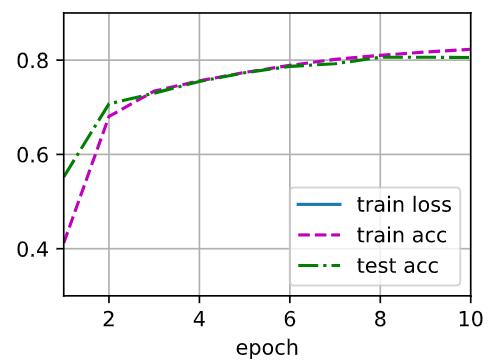
net = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=784 ,out_features=256),
nn.Tanh(),
nn.Linear(in_features=256,out_features=10)
)
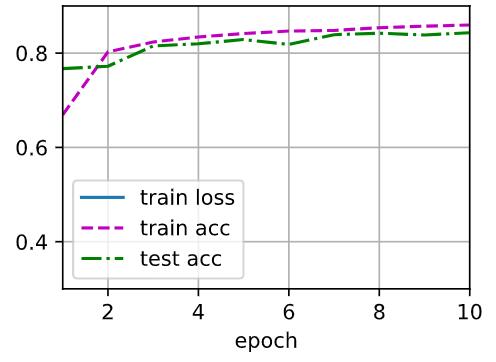
综合下来比较的话(单层256个单元的隐藏层训练),ReLU最为简单,也是最为常用的激活函数,虽然最后能够取得不错的拟合效果,但是精度波动幅度较大。Sigmoid波动小,但是最后的精度好像不是那么可观,tanh最后精度,训练的精度的波动都很小,是一个比较不错的Active Function。最后就是双层均为128个单元的使用ReLU激活函数隐藏层,不论是精度还是最后的精度,都属于第一水准。就是训练的时候可能拟合会比较慢,需要更多的迭代次数和资源。
posted on 2022-01-02 21:00 YangShusen' 阅读(212) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号