谈谈 JAVA 的对象序列化
所谓的『JAVA 对象序列化』就是指,将一个 JAVA 对象所描述的所有内容以文件 IO 的方式写入二进制文件的一个过程。关于序列化,主要涉及两个流,ObjectInputStream 和 ObjectOutputStream。
很多人关于『序列化』的认知只停留在 readObject 和 writeObject 这两个方法的调用,但却不知道为什么 JAVA 能够从一个二进制文件中「还原」出来一个完整的 JAVA 对象,也不知道一个对象究竟是如何存储在二进制文件中的。
本文会带大家分析二进制文件并结合序列化协议规则,去看看文件中的 JAVA 对象是个什么模样,可能枯燥,但一定会提高你对序列化的认知的。
一种古老的序列化方式
在前面介绍字节流的相关文章中,我们简单提到过 DataInput/OutputStream 这个装饰者流,它允许我们以基本数据类型为输入,向文件进行写入和读出操作。
看个例子:
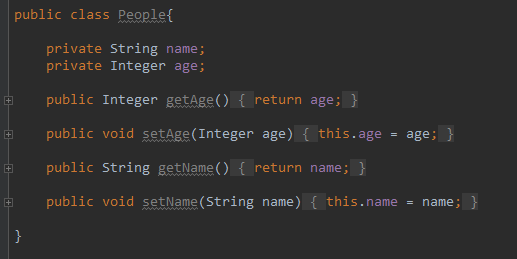
定义一个 People 类型:
稍显复杂的 main 函数:
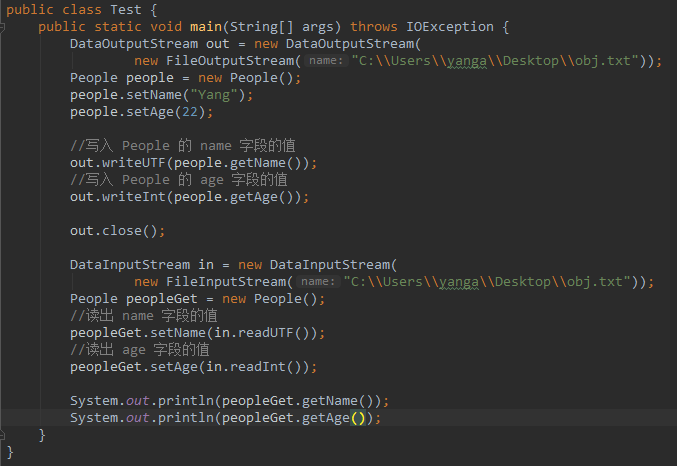
可以看到,这种古老的序列化方式其实就是使用流 DataInput/OutputStream 将对象中字段的值逐个的写入文件,完成所谓的『序列化操作』。
恢复对象的时候也必须按照写入的顺序一个字段一个字段的读取,这种方式可以说非常的反人类了,如果一个类有一百个字段,岂不是得手动写入一百次。
这种方式准确意义上来说并不能算作『序列化』的一种实现,它是一种伪序列化,大家知道一下就好了。
JAVA 标准序列化
之所以需要将一个对象序列化存储到磁盘目录中的一个原因就是,有些对象可能很重要但却占用不小的空间,往往一时半会还用不到,那么将它们放置内存中显然是一种浪费,而丢弃又将导致额外的操作来创建这些对象。
所以,一种折中解决办法就是,先将这些对象序列化保存进文件,用的时候再从磁盘读取,而这就是『序列化』。
想要序列化一个对象,JAVA 要求该类必须继承 「java.io.Serializable」接口,而 serializable 接口内并没有定义任何方法,它是一个「标记接口」。
虚拟机执行序列化指令的时候会检查,要序列化的对象所对应的类型是否继承了 Serializable 接口,如果没有将拒绝执行序列化指令并抛出异常。
java.io.NotSerializableException
而序列化的一般用法如下:
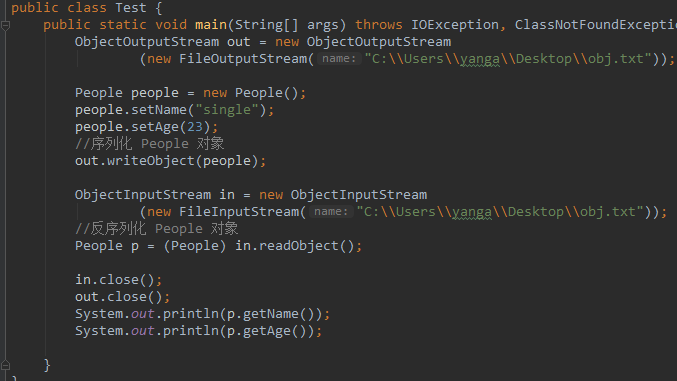
输出结果:
single
23
ObjectOutputStream 某种意义上来看也是一种装饰者流,内部所有的字节流操作都依赖我们构造实例时传入的 OutputStream 实例。
这个类的实现很复杂,光内部类就定义了很多,同时它也封装了我们的 DataOutputStream,所以 DataOutputStream 那一套写基本数据类型的方法,这里也有。除此之外的是,它还提供了 DataOutputStream 没有的 writeObject 方法用于将一个继承 Serializable 接口的 Java 对象直接写入磁盘。
当然,ObjectInputStream 是相反的,它用于从磁盘读取并恢复一个 Java 对象。
writeObject 方法接受一个 Object 参数,并将该参数所代表的 Java 对象序列化进磁盘文件,这里会写入很多东西而不是简简单单的将字段的值写入文件,它是有一个参照格式的,就像我们编译器会按照一定的格式生成字节码文件一样。
遵循同样的规则将会使得恢复起来很方便,下面我们来看看这个规则的具体内容。
序列化的存储规则
上一小节我们序列化了一个 People 的实例对象到文件中,现在我们打开这个二进制文件。
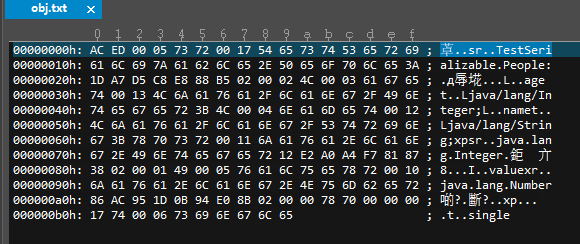
序列化后的对象需要用这么多的二进制位进行存储,这些二进制位都是符合 JAVA 的序列化规则的,每几个字节用来存储什么都是规定好的,下面我们一起来看看。
1、魔数:这个是几乎所有的二进制文件头部都有的,用于标识当前二进制文件的文件类型,我们的对象序列化文件的魔数是 AC ED,占两个字节。
2、序列化协议版本号:这指明 JAVA 采用什么样的序列化规则来生成二进制文件,这里是 00 05,可能还有其他协议,一般都是 5 号协议。
3、一个字节:接下来的一个字节用于描述当前的对象类型,0x73 表示这是一个普通的 Java 对象,其他可选值:
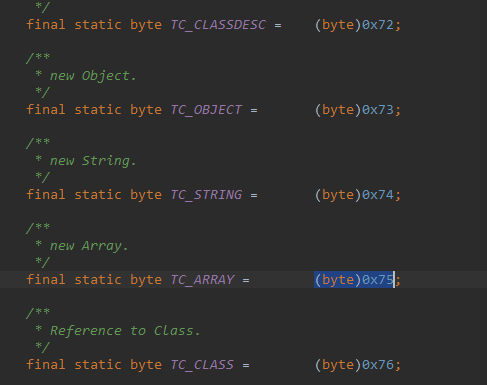
注意,字符串和数组类型并没有划分到普通的 Java 对象这一类中,它们具有不同的数值标志。我们这里的 People 是一个普通的 Java 对象,所以这里是 0x73 。
4、一个字节:这一个字节指明当前的对象所属的数据类型,是一个类或者是一个引用,这里的引用区别于 Java 的引用指针。如果你对于同一个对象进行两次序列化,Java 不会重复写入文件,后者会保存为一个引用类型,有关这一点,待会再详细介绍。这里的 People 是一个类,所以这里的值就是,0x72 。
5、类的全限定名长度:0x0017 这两个字节描述了当前对象的全限定名称长度,所以接下来的 23 个字节是当前对象的全限定名称,经过换算,这 23 个字节表述的值为:TestSerializable.People。
接着看:
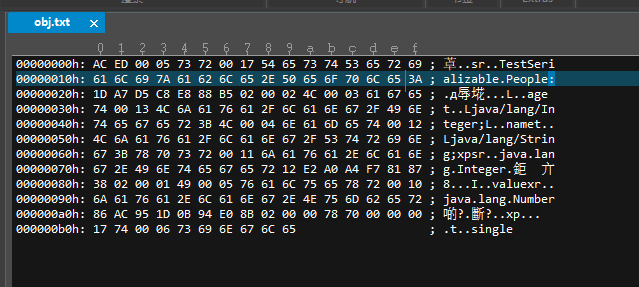
6、序列号版本:接下来的八个字节,3A -> B5 描述的是当前类对象的序列化版本号,这个值由于我们定义的 People 类中没有显式指明,所以编译器会根据 People 类的相关信息以某种算法生成一个 serialVersionUID 占八个字节。
7、序列化类型:一个字节,用于指明当前对象的序列化类型,0x02 即代表当前对象可序列化。
8、字段个数:两个字节,指明当前对象中需要被序列化的字段个数,我们这里是,0x0002,对应的我们 name 和 age 这两个字段。
接下来就是对字段的描述了:
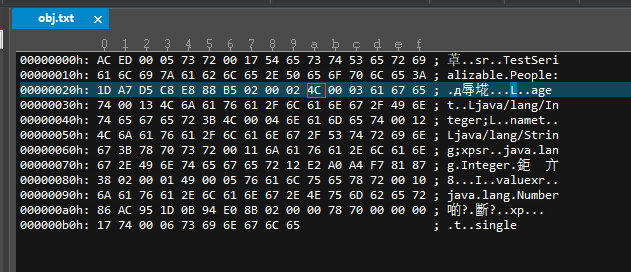
9、字段类型:一个字节,0x4C 对应的 ASCII 值为 L,即表示当前字段的类型是一个普通类类型。
10、字段名长度:两个字节,0x0003 指明接下来的三个字节表述了当前字段的全名称,0x616765 正好对应字符 age。
11、字段类型名:三个字节,0x740013 ,其中 0x74 是一个字段类型开始的标志,即每个描述字段类型名的三个字节里,前一个字节都是 0x74,后面两个字节描述了字段类型名称的长度,0x0013 对应 19。所以接着的 19 个字节表述当前字段的完整类型名称。这里算了一下,正好是,Ljava/lang/Integer;。
接着就是描述我们的第二个字段 name,具体过程是类似,这里不再赘述,我们紧接着 name 字段之后继续介绍。
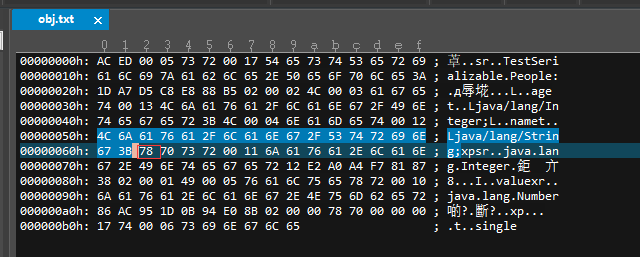
12、字段描述结束符:一个字节,固定值 0x78 标志所有的字段类型信息描述结束。
13、父类类型描述:一个字节,0x70 代表 null,即没有父类,不算 Object 类。
接下来这一段其实是 Java 序列化一个 Integer 对象的过程,然后到 0x7872,即 Integer 类还有父类,于是又去序列化一个父类 Number 实例。为什么这么做,我想你应该清楚,每个子类对象的创建都会对应一个父类对象的创建。
所以,直到
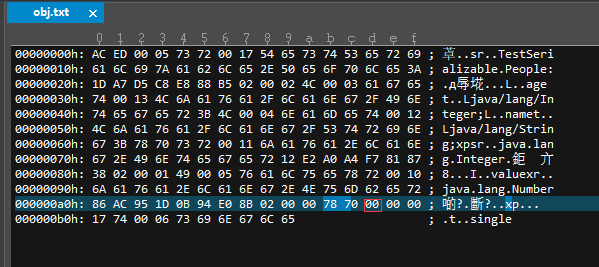
最后一个 0x7870,说明所有的对象信息都已经序列化完成,下面是各个字段的数据部分。
前四个字节,0x00000017 是我们第一个字段 age 的值,也就是 23 。0x74 指明第二个字段的类型是 String 类型,值的长度 0x0006,最后六个字节刚好是字符串 single。
至此,整个序列化文件的格式我们已经全部介绍完成了,总结一下:
整个序列化文件分为两个部分,字段类型描述和字段数据部分。其中,如果字段的类型是普通的 JAVA 类型的话,会继续序列化其父类对象,理解这一点很重要,像我们这个例子中,一共序列化了三个对象,分别是 People,Integer,Number 这三个对象,如果它们的字段有被外部赋值过,这些值也将此排序存储。
序列化的几点高级认识
循环引用的序列化
考虑这样两个类:
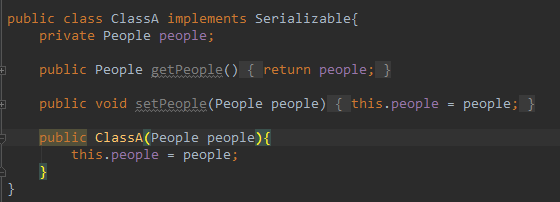
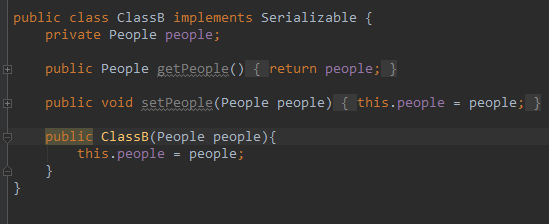
这两个类的定义几乎就是相同的,内部都定义了一个 People 字段。
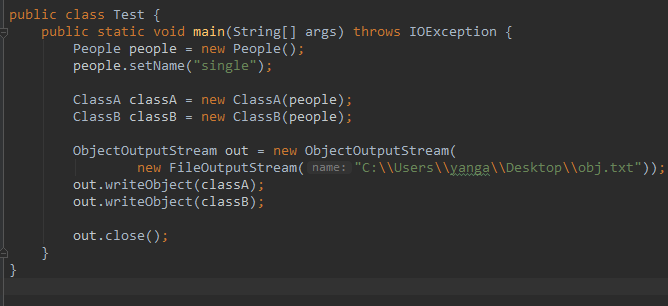
让 ClassA 和 ClassB 的两个对象公用同一个 People 实例,那么有一个问题,我去序列化这两个对象,这个公用的 People 对象会被序列化两次吗?
我们打开二进制文件,这次的二进制文件要复杂一点了:
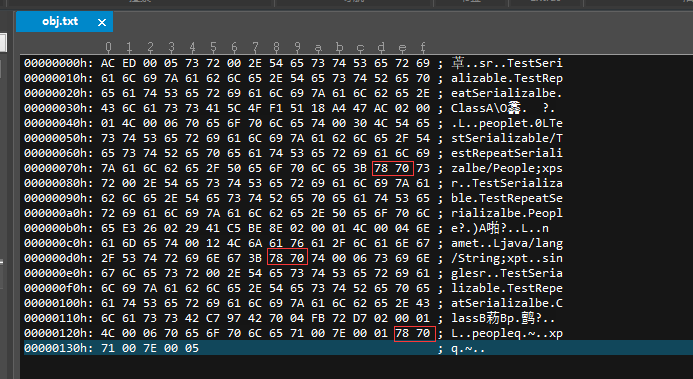
我圈出来了几个 0x7870,它标志着一个对象类型信息的序列化结束,我们简单分析一下,不会详细的说了,具体参照上面的内容。
第一部分其实是在序列化 ClassA 类型,它指明了 ClassA 类型只有一个字段,并且该字段是一个对象类型,记录下字段的类型名称等信息。
第二部分在序列化 People 类型,包括序列化其中的 name 字段,并存储了 name 字段的外部赋的值,字符串:single。
第三部分,序列化 ClassB 类型,ClassB 的类型序列化相对 ClassA 要少一点,虽然它们内部具有相同的定义。
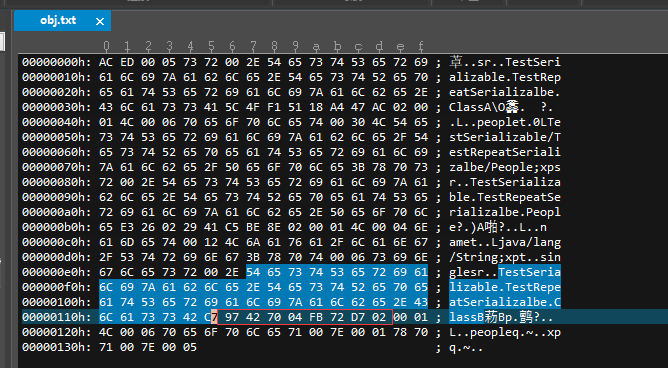
其中,阴影部分是 ClassB 类的全限定名,红线框是该类的版本序列号,由于我们没有显式指定,这是由编译器自动生成的。接着指明具有一个字段,字段类型是对象类型,名称长度六个字节。
0x71 指明这个字段是一个引用,按惯例来说,这部分应该进行该字段的类型名称描述,但是由于这种类型已经序列化过了,所以使用引用直接指向前面已经完成序列化的 People 类型。
最后一部分按惯例应该进行字段数据的描述,描述数据的类型,值的长度,以及值本身。但是由于我们 ClassB 类型的 people 字段值公用的 ClassA 的 people 字段值,所以虚拟机不会傻到重新序列化一遍该 people 对象,而是给出上面该 people 对象的引用编号。
说了这么多,得出的结论是什么呢,如果你要序列化的多个对象中,有相同的类类型,Java 只会描述一次该类型,并且如果一份序列化文件中存在对同一对象的多次序列化,Java 也只会保存一份对象数据,后面的都用引用指向这里。
定制序列化
对于所有继承了 Serializable 接口的类而言,进行序列化时,虚拟机会序列化这些类中所有的字段,无视访问修饰符,但是有时候我们并不需要将所有的字段都进行序列化,而只是选择性的序列化其中的某些字段。
我们只需要在不想序列化的字段前面使用 transient 关键字进行修饰即可。
private transient String name;
即便你给你的对象的 name 字段赋值了,最终也不会被保存进文件中,当你反序列化的时候,这个对象的 name 字段依然是系统默认值 null。
除此之外,JAVA 还允许我们重写 writeObject 或 readObject 来实现我们自己的序列化逻辑。
但是这两个方法的声明必须是固定的。
private void writeObject(java.io.ObjectOutputStream s)
private void readObject(java.io.ObjectInputStream s)
没错,它就是 private 修饰的,在你通过 ObjectOutputStream 的 writeObject 方法对某个对象进行序列化时,虚拟机会自动检测该对象所对应的类是否有以上两种方法的实现,如果有,将转而调用类中我们自定的该方法,放弃 JDK 所实现的相应方法。
我们看个例子:
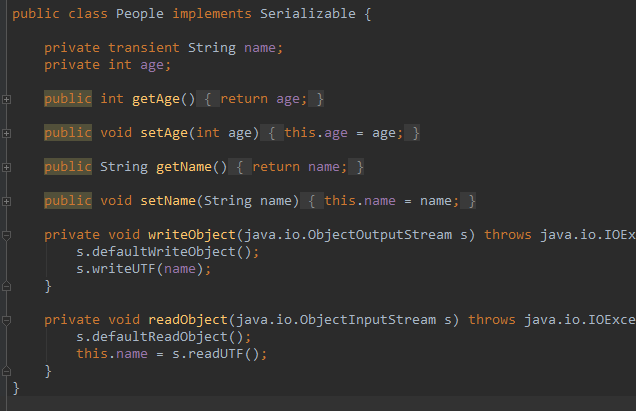
name 被关键字 transient 修饰,即默认的序列化机制不会序列化该字段,并且我们重写了 writeObject 和 readObject,在其中调用了默认的序列化方法之后,我们分别将 name 字段写入和读出。
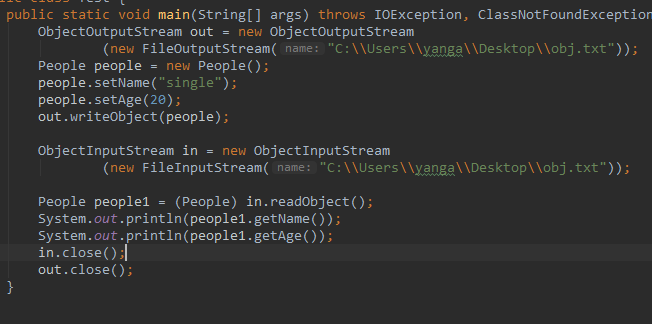
输出结果:
single
20
有兴趣的同学可以自己去看看序列化后的二进制文件,其中是没有关于 name 字段的描述信息的,但是整个 people 对象描述之后,紧随其后的就是我们的字符 「single」。
而反序列化的过程也是类似的,先按照 JDK 的默认反序列化机制反射生成一个 people 对象,再读取文件末尾的字符串赋值给当前 people 对象。
序列化的版本问题
序列化的版本 ID,我们一直都有提到它,但是始终没有说明这个版本 ID 到底有什么用。用得好的可以拿来实现权限管理机制,用不好也可能导致你反序列化失败。
JAVA 建议每个继承 Serializable 接口的类都应当定义一个序列化版本字段。
private static final long serialVersionUID = xxxxL;
这个值可以理解为是当前类型的一个唯一标识,每个对象在序列化时都会写入外部类型的这个版本号,反序列化时首先就会检查二进制文件中的版本号与目标类型中的版本号是否一样,如果不一样将拒绝反序列化。
这个值不是必须的,如果你不提供,那么编译器将根据当前类的基本信息以某种算法生成一个唯一的序列号,可是如果你的类发生了一点点的改动,这个值就变了,已经序列化好的文件将无法反序列化了,因为你也不知道这个值变成什么了。
所以,JAVA 建议我们都自己来定义这么一个版本号,这样你可以控制已经序列化的对象能否反序列化成功。
至此,我们简单的介绍了序列化的相关内容,很多的都是结合着二进制文件进行描述的,可能枯燥,但是看完想必是能够提高你原先对于 JAVA 对象序列化的认知的。有什么问题,可以留言一起探讨交流 !
文章中的所有代码、图片、文件都云存储在我的 GitHub 上:
(https://github.com/SingleYam/overview_java)
欢迎关注微信公众号:OneJavaCoder,所有文章都将同步在公众号上。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号