

scrapy框架爬取豆瓣读书(1)
1.scrapy框架
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
主要组件:

2.快速开始
scrapy startproject douban
cd到douban根目录下执行 scrapy genspider Douban book.douban.com
原网页结构
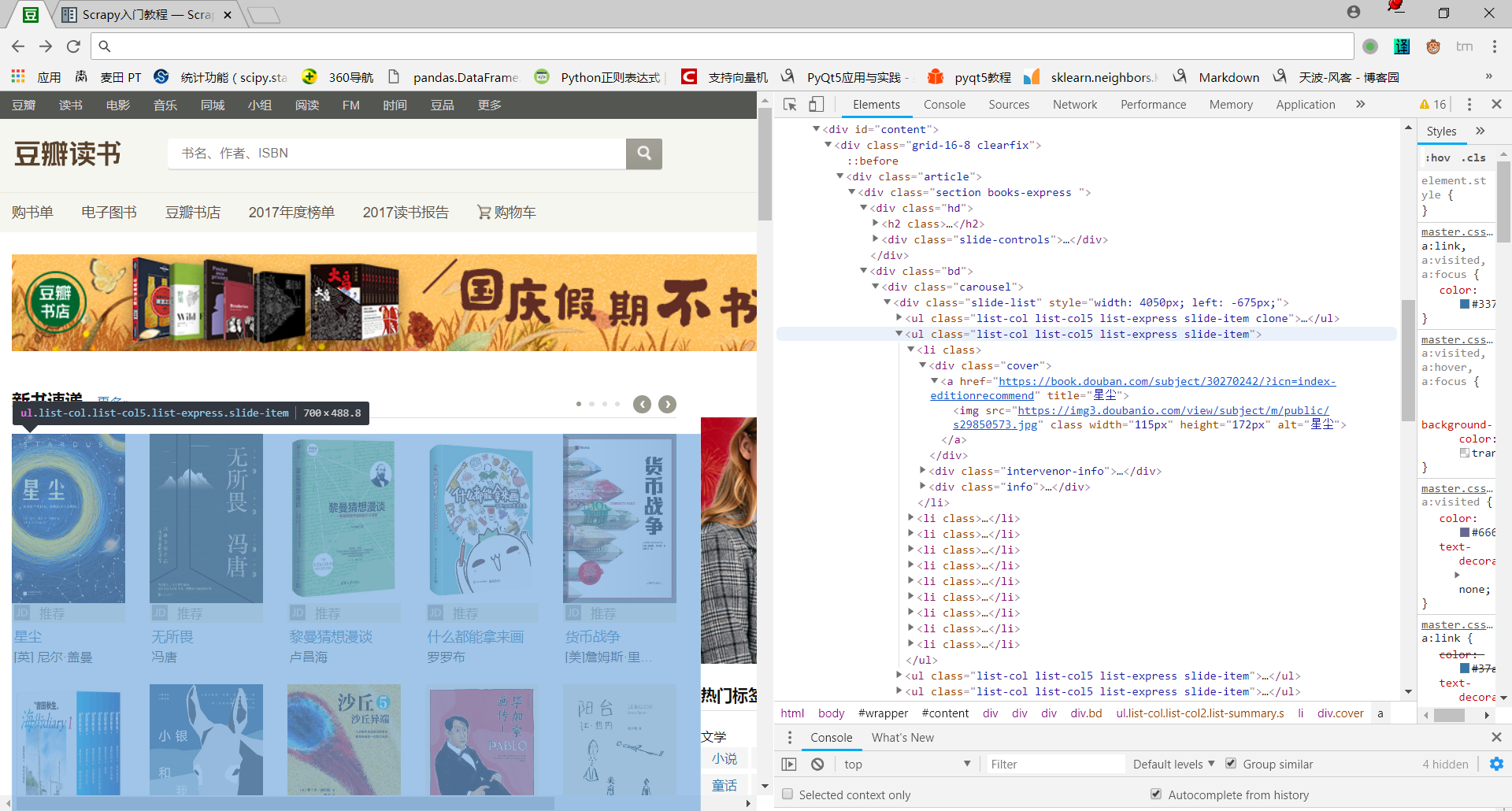
3.xpath提取
xpath是基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力。
xpath初探:
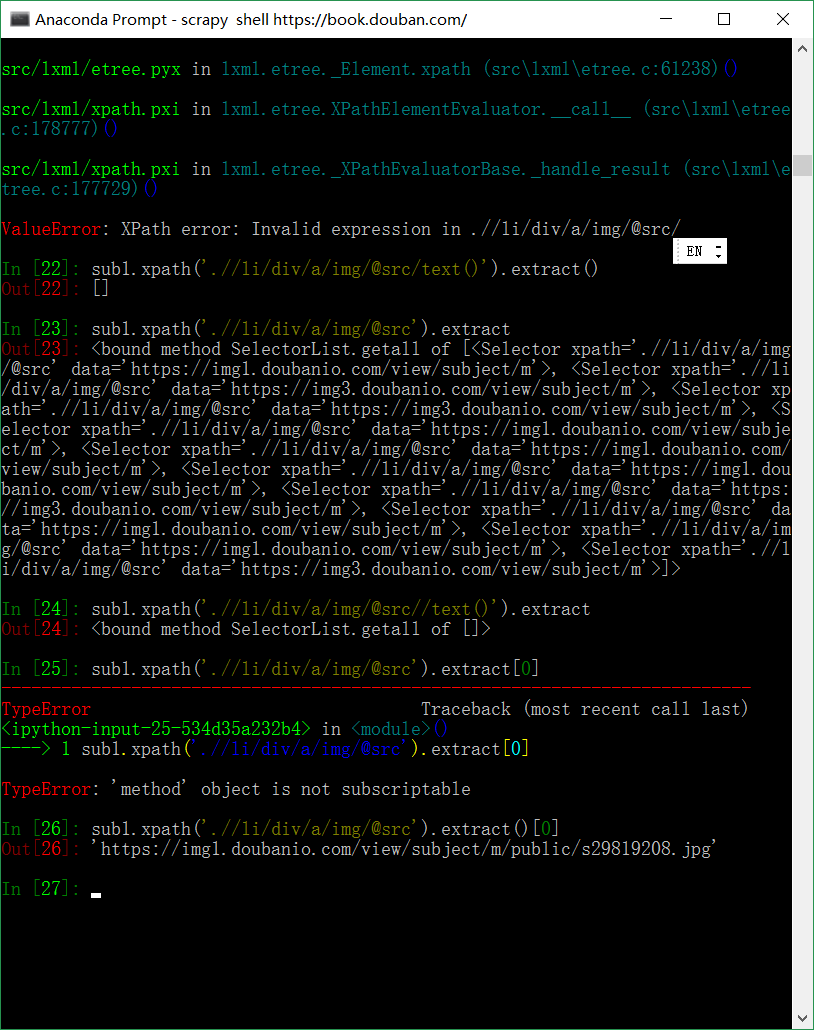
提取书籍排行榜图片链接,以备后续保存
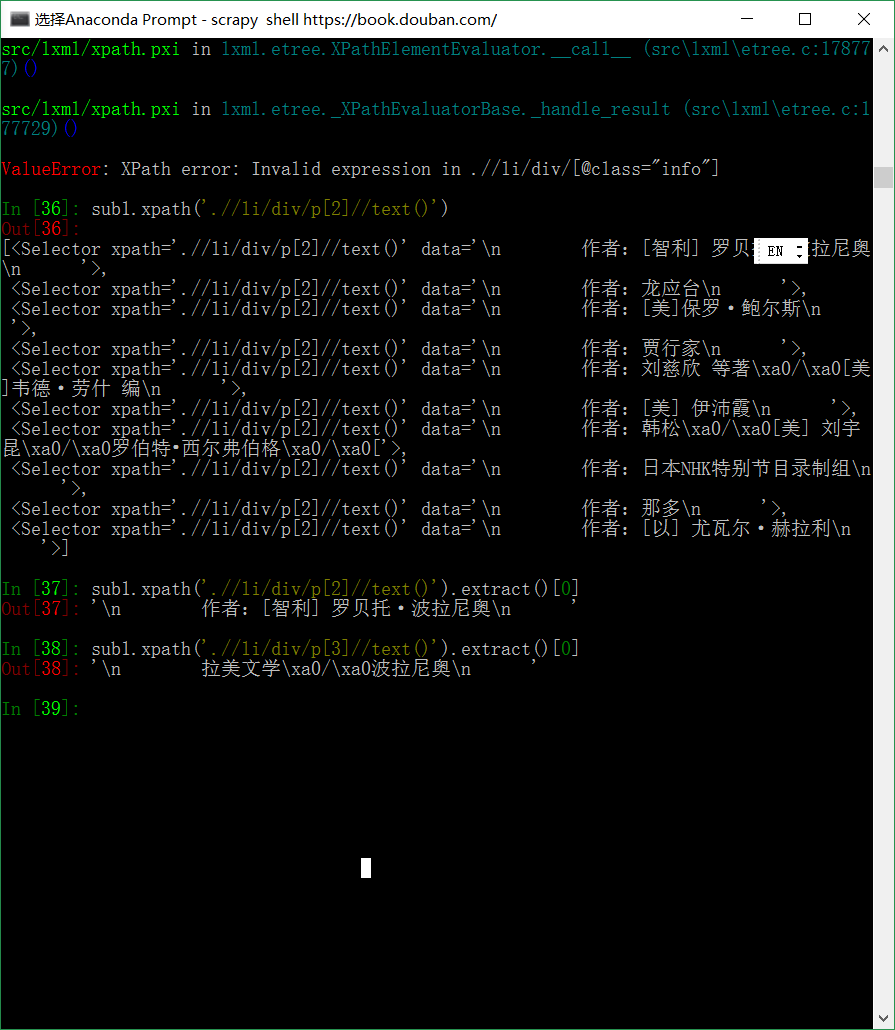
提取作者,所在地区
4.Douban.py代码
import scrapy
from douban.items import DoubanBookItem
class BookSpider(scrapy.Spider):
name = 'douban-book'
allowed_domains = ['douban.com']
start_urls = [
'https://book.douban.com'
]
def parse(self, response):
# 请求第一页
yield scrapy.Request(response.url, callback=self.parse_next)
#爬取其他页面
for page in response.xpath('//div[@class="paginator"]/a'):
link = page.xpath('@href').extract()[0]
yield scrapy.Request(link, callback=self.parse_next)
def parse_next(self, response):
for item in response.xpath('//tr[@class="item"]'):
book = DoubanBookItem()
book['name'] = item.xpath('td[2]/div[1]/a/@title').extract()[0]
book['content'] = item.xpath('td[2]/p/text()').extract()[0]
book['ratings'] = item.xpath('td[2]/div[2]/span[2]/text()').extract()[0]
yield book
5.明天继续更新items.py、pipelines(管道数据流)、middlewaares(中间件)编写


 浙公网安备 33010602011771号
浙公网安备 33010602011771号










